











Gdy organizacje przechodzą od architektury monolitycznej do mikroserwisów, podejście do modelowania danych często staje się źródłem istotnych sporów. Przez dekady diagram istotności-relacji (ERD) był szablonem projektowania baz danych w systemach centralnych. Precyzyjnie odwzorowywał tabele, kolumny, klucze i relacje. Jednak rozproszona natura mikroserwisów wyzwania te tradycyjne zasady. Przypuszczenie, że pojedynczy, zintegrowany schemat dotyczy całego systemu, to trwała myląca koncepcja, która może prowadzić do silnego powiązania i operacyjnej niestabilności.
Ten przewodnik analizuje powszechne przekonania dotyczące diagramów ER w środowiskach rozproszonych. Oddziela fakt od fikcji, skupiając się na tym, jak powinny być definiowane granice danych, jak zarządzać relacjami bez wspólnych tabel oraz dlaczego wizualna reprezentacja danych musi się zmienić przy przejściu do architektury opartej na usługach. Celem jest zapewnienie jasnego zrozumienia zasad modelowania danych wspierających skalowalność i odporność.
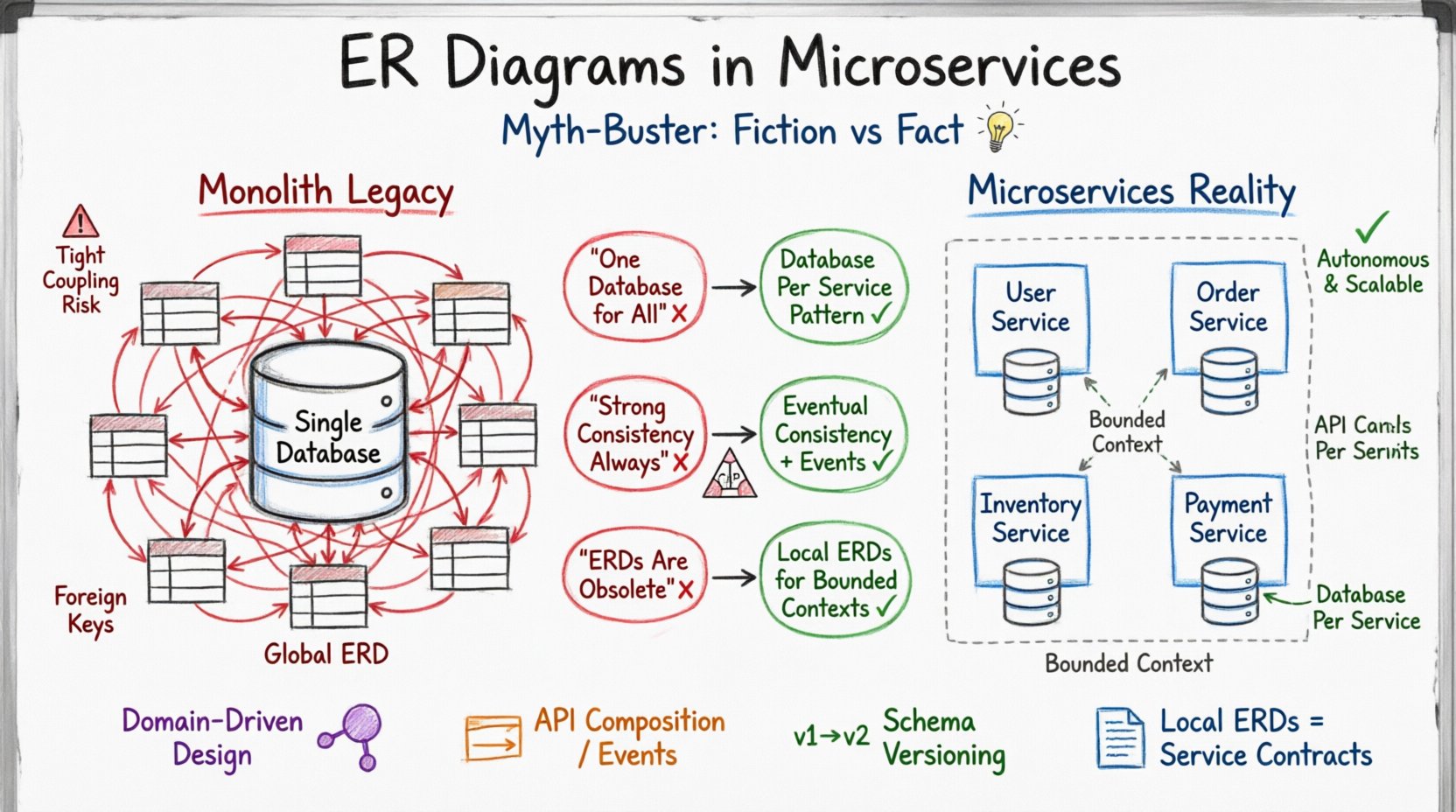
Dziedzictwo monolitu: dlaczego stare diagramy ER nie pasują 🏛️
W tradycyjnej aplikacji monolitycznej baza danych pełni rolę centralnego źródła prawdy. Cała logika aplikacji interaguje z pojedynczym schematem. W takim środowisku korzysta się z kompleksowego diagramu ER, który odwzorowuje każdą encję i relację. Projektanci mogą polegać na kluczach obcych, aby zapewnić integralność referencyjną na całym systemie. Transakcje obejmują wiele tabel w tej samej instancji bazy danych, zapewniając globalne zachowanie właściwości ACID (atomowość, spójność, izolacja, trwałość).
Gdy ten sposób myślenia stosuje się do mikroserwisów, pojawia się napięcie. Mikroserwisy są projektowane jako samodzielne. Każdy serwis zarządza własnym warstwą trwałości danych. Oznacza to, że nie ma wspólnej bazy danych między serwisami. Jeśli serwis posiada dane, inny serwis nie może bezpośrednio ich zapytać za pomocą standardowych złączeń SQL. Diagram ER musi więc przejść od mapy systemowej do zbioru schematów specyficznych dla domeny.
- Centralne zarządzanie: Monolity pozwalają administratorowi bazy danych (DBA) zarządzać całym schematem.
- Rozproszone zarządzanie: Mikroserwisy wymagają, by każda drużyna zarządzała definicją własnego schematu.
- Globalne transakcje: Monolity wspierają aktualizacje jedno-transakcyjne na wielu tabelach.
- Transakcje rozproszone: Mikroserwisy wymagają wzorców koordynacji, takich jak Saga lub spójność ostateczna.
Pierwszym krokiem w modernizacji modelowania danych jest przyjęcie, że pojedynczy diagram ER obejmujący całą aplikację nie jest już możliwy ani pożądany. Zamiast tego, skupienie przesuwa się na projektowanie oparte na domenie, w którym model danych odpowiada możliwościom biznesowym każdego serwisu.
Mity 1: Błąd „jednej bazy danych” 🗄️❌
Powszechnym przekonaniem wśród architektów nowych dla systemów rozproszonych jest, że można utrzymywać jedną fizyczną bazę danych, jednocześnie logicznie rozdzielając dane za pomocą prefiksów schematów lub odrębnych tabel. Ten podejście często nazywa się antypatologią „wspólnej bazy danych”. Choć wydaje się upraszczać początkowy projekt, prowadzi do istotnych ryzyk wraz z rozwojem systemu.
Dlaczego wspólne bazy danych zawodzą
Nawet jeśli serwisy nie dzielą kodu, współdzielenie instancji bazy danych tworzy sprzężenie fizyczne. Jeśli jeden serwis wymaga migracji schematu, która wpływa na wydajność lub dostępność, wszystkie inne serwisy współdzielące tę bazę danych są dotknięte. To narusza podstawowy zasadę niezależności w mikroserwisach.
- Blokowanie wdrażania: Ryzykowna migracja dla Serwisu A może uniemożliwić wdrożenie Serwisu B.
- Konflikty zasobów: Ciężkie zapytania z jednego serwisu mogą pogorszyć wydajność dla innych.
- Ryzyka bezpieczeństwa: Jeden uszkodzony serwis może potencjalnie uzyskać dostęp do danych należących do innego serwisu.
- Zależność technologiczna: Jeśli Serwis A potrzebuje innego silnika baz danych niż Serwis B, nie mogą współistnieć w środowisku wspólnym.
Rozwiązaniem jest wzorzec „baza danych na serwis”. Każdy serwis zarządza własną bazą danych. Zapewnia to izolację zmian schematu. Diagram ER dla Serwisu A powinien odzwierciedlać tylko encje danych wymagane przez Serwis A, a nie cały system.
Mity 2: Silna spójność jest zawsze wymagana ⚖️
W środowisku monolitycznym zgodność z ACID jest standardem. Deweloperzy oczekują, że po zatwierdzeniu transakcji dane są natychmiast spójne na całym systemie. W mikroserwisach to oczekiwanie często jest nierealistyczne. Twierdzenie CAP mówi, że system rozproszony może zapewnić tylko dwie z trzech właściwości: spójność, dostępność i odporność na rozłączenia.
Zrozumienie spójności rozproszonej
Gdy usługi komunikują się przez sieć, opóźnienia i potencjalne błędy są nieuniknione. Próba wymuszenia silnej spójności przez granice usług często prowadzi do wysokiego opóźnienia lub niedostępności systemu. Zamiast tego wiele systemów stosuje spójność ostateczną. Oznacza to, że dane mogą być tymczasowo niezgodne między usługami, ale z czasem zbiegają się.
- Silna spójność: Dane są aktualizowane natychmiast wszędzie. Dobrze dla bankowości, ale wysokie opóźnienia.
- Spójność ostateczna: Dane rozprzestrzeniają się asynchronicznie. Dobrze dla profili użytkowników, liczb zapasów.
- Podstawowa dostępność: System pozostaje działający nawet podczas podziałów sieciowych.
Diagram ER w mikroserwisie zwykle nie przedstawia relacji wymagających natychmiastowego blokowania. Zamiast tego przedstawia stan danych, które są lokalnie spójne. Relacje między usługami są obsługiwane za pomocą zdarzeń lub wywołań interfejsów API, a nie kluczy obcych w bazie danych.
Mity 3: Diagramy ER są przestarzałe w systemach rozproszonych 📉
Niektórzy praktycy twierdzą, że ponieważ mikroserwisy rozdzielają dane, koncepcja ERD nie jest już potrzebna. To błąd. Choć globalny ERD jest przestarzały, lokalne ERD są dziś ważniejsze niż kiedykolwiek. Bez jasnej dokumentacji struktury danych wewnątrz usługi, ryzyko rozbieżności danych i błędów integracji znacznie rośnie.
Rola lokalnego ERD
ERD w kontekście mikroserwisu pełni inne zadanie niż w systemie monolitycznym. Definiuje kontekst ograniczony. Zapewnia, że usługa dokładnie wie, jakie dane posiada i jak są one zorganizowane wewnętrznie. Nie musi przedstawiać relacji z usługami zewnętrznymi.
- Dokumentacja: Jest umową dotyczącą wewnętrznego modelu danych.
- Komunikacja: Pomaga programistom zrozumieć encje domeny bez konieczności znajomości zależności zewnętrznych.
- Utrzymanie: Upraszczają włączanie nowych członków zespołu do konkretnej usługi.
- Weryfikacja: Pomaga wykrywać zależności cykliczne w fazie projektowania.
Diagram powinien skupiać się na encjach, atrybutach i kluczach głównych. Klucze obce odnoszące się do usług zewnętrznych powinny być usunięte lub abstrakcyjnie przedstawione jako identyfikatory, a nie bezpośrednie linki do tabel.
Najlepsze praktyki modelowania danych w mikroserwisach 🛠️
Aby stworzyć odporny system, zespoły muszą przyjąć konkretne strategie modelowania zgodne z zasadami architektury rozproszonej. Te praktyki zapewniają, że usługi pozostają niezależne, jednocześnie współpracując, aby zapewnić spójne doświadczenie użytkownika.
1. Projektowanie oparte na domenie (DDD)
Wyrównanie schematu bazy danych z modelem domeny jest kluczowe. Każda usługa powinna reprezentować określoną zdolność biznesową. Na przykład usługa „Użytkownik” nie powinna przechowywać szczegółów zamówienia. Usługa „Zamówienie” nie powinna przechowywać tokenów uwierzytelniania użytkownika. Ta separacja zapewnia, że ERD odzwierciedla logikę biznesową, a nie wygody techniczne.
- Definiuj agregaty na podstawie granic transakcyjnych.
- Zachowaj ERD skupiony na odpowiedzialności usługi.
- Unikaj tworzenia modeli obejmujących wiele domen biznesowych.
2. Obsługa relacji przez granice
Gdy usługa A potrzebuje danych należących do usługi B, nie powinna bezpośrednio zapytać bazy danych usługi B. Zamiast tego powinna użyć jednego z poniższych wzorców:
- Kompozycja interfejsów API: Usługa A wywołuje interfejs API usługi B w celu pobrania niezbędnych danych.
- Ostateczne replikowanie: Usługa A utrzymuje kopię niezbędnych danych w własnej bazie danych, aktualizowaną za pomocą zdarzeń.
- Łączenie poprzez model odczytu: Specjalistyczna usługa odczytu agreguje dane z wielu źródeł w celu zoptymalizowania zapytań.
3. Wersjonowanie schematu
W systemie rozproszonym usługi rozwijają się z różną prędkością. Zmiana schematu jednej usługi nie powinna naruszać konsumera tej usługi. Wprowadzenie wersjonowania schematu umożliwia zgodność wsteczną.
- Używaj wersjonowanych punktów końcowych dla kontraktów interfejsów API.
- Zezwalaj na współistnienie wielu wersji schematu danych podczas migracji.
- Stopniowo wycofuj stare wersje schematu zamiast wymuszać natychmiastowe aktualizacje.
Porównanie: architektura monolityczna vs. architektura mikroserwisów 📊
Aby wyjaśnić różnice, poniższa tabela przedstawia kluczowe różnice między modelowaniem danych w architekturach centralnych a rozproszonych.
| Cecha | Architektura monolityczna | Architektura mikroserwisów |
|---|---|---|
| Przechowywanie danych | Jedna instancja bazy danych | Baza danych na usługę |
| Zakres diagramu ER | Widok całego systemu | Widok specyficzny dla usługi |
| Związki | Klucze obce (łączenia SQL) | Wywołania interfejsów API lub zdarzenia |
| Model spójności | Silna spójność (ACID) | Ostateczna spójność (BASE) |
| Wdrożenie | Wdrożenie monolityczne | Niezależne wdrażanie usługi |
| Zmiany schematu | Centralizowane migracje | Zarządzane przez zespół usługi |
| Zapytania | Bezpośrednie zapytania SQL | Modele odczytu / CQRS |
Obsługa relacji danych przez granice 🔗
Jednym z najtrudniejszych aspektów mikroserwisów jest zarządzanie relacjami danych. W monolicie klucz obcy zapewnia, że zamówienie należy do użytkownika. W mikroserwisach tabela „Użytkownik” znajduje się w usłudze Użytkownik, a tabela „Zamówienie” w usłudze Zamówienie. Usługa Zamówienie nie może zawierać klucza obcego do bazy danych usługi Użytkownik.
Wzorce integralności referencyjnej
Aby zachować integralność referencyjną bez współdzielonych tabel, zespoły mogą stosować określone wzorce:
- Odwołania logiczne: Przechowuj identyfikator użytkownika jako ciąg lub liczbę, ale sprawdzaj jego istnienie za pomocą wywołania API podczas tworzenia.
- Wyzwalacze baz danych: Nie zalecane między usługami, ale poprawne w ramach jednej usługi.
- Zdarzenia weryfikacji: Usługa Użytkownik publikuje zdarzenie „Użytkownik utworzony”. Usługa Zamówienie je odbiera, aby potwierdzić relację.
Problem łączeń
Łączenia przez granice usług są wąskim gardłem wydajności. Powodują one opóźnienia sieciowe i potencjalne punkty awarii. Jeśli usługa Użytkownik jest niedostępna, usługa Zamówienie nie może pobrać szczegółów zamówienia, jeśli opiera się na łączeniu. Zamiast tego usługa Zamówienie powinna redundancko przechowywać niezbędne dane użytkownika (takie jak Imię) w momencie tworzenia zamówienia. Jest to kompromis między normalizacją a dostępnością.
Ewolucja schematu i wersjonowanie 🔄
Ewolucja schematu jest nieunikniona. Gdy zmieniają się wymagania biznesowe, struktury danych muszą się dostosować. W środowisku mikroserwisów zmiana schematu jest bardziej skomplikowana, ponieważ wiele usług może zależeć od struktury danych innej usługi.
Strategie ewolucji
- Zmiany dodawane: Dodanie nowej kolumny jest zazwyczaj bezpieczne, jeśli aplikacja obsłuży brakujące pola zgodnie z oczekiwaniami.
- Usuwanie pól: Wymaga okresu deprecjacji, w którym pole jest ukrywane, ale nadal istnieje, a następnie usuwane później.
- Zmiany typów: Zmiana typu danych (np. String na Integer) wymaga skoordynowanej strategii migracji.
Używanie rejestru schematów może pomóc w zarządzaniu tymi zmianami. Służy jako centralne źródło prawdy dla struktury danych wymienianych między usługami, zapewniając, że producenci i konsumenty zgadzają się na format.
Typowe pułapki do uniknięcia 🚧
Nawet mając solidne zrozumienie zasad, zespoły często wpadają w pułapki podczas wdrażania. Wczesne wykrycie tych pułapek może zaoszczędzić znaczną długoterminową wadę techniczną.
- Zbyt duża normalizacja: Próba utrzymania jednego źródła prawdy we wszystkich usługach prowadzi do skomplikowanych transakcji rozproszonych. Przyjmij nadmiarowość tam, gdzie jest to konieczne.
- Ignorowanie idempotentności: Wywołania sieciowe mogą się nie powieść lub zostać ponownie wykonane. Operacje na danych muszą być zaprojektowane tak, aby obsługiwać powtarzające się żądania bez tworzenia duplikatów.
- Przeciążenie choreografii: Zależność wyłącznie od zdarzeń w celu zapewnienia spójności danych może stać się niemożliwa do zarządzania. Używaj orchestrationu dla złożonych przepływów pracy.
- Niedoszacowanie opóźnień: Pobieranie danych między usługami dodaje milisekundy do każdego żądania. Zbieraj dane lokalnie tam, gdzie to możliwe.
- Brak dokumentacji: Bez jasnych diagramów ERD dla każdej usługi integracja staje się grą zgadówek.
Ostateczne rozważania na temat przejrzystości architektury 🧠
Przejście od modelowania danych monolitycznego do mikroserwisowego wymaga zmiany nastawienia. Nie chodzi tylko o rozbijanie bazy danych na mniejsze fragmenty. Chodzi o ponowne zdefiniowanie sposobu postrzegania własności danych i relacji między nimi. Diagram ER nadal jest ważnym narzędziem, ale jego zakres ogranicza się do granic usługi.
Unikając mitów dotyczących współdzielonych baz danych i globalnej spójności, architekci mogą budować systemy odpornościowe i skalowalne. Kluczem jest priorytetowanie niezależności usługi nad normalizacją danych. Oznacza to akceptację faktu, że część danych będzie powielona, aby zapewnić niezależne działanie usług. Oznacza to również zrozumienie, że silna spójność to luksus, a nie wymóg dla każdej operacji.
Podczas projektowania architektury danych skup się na domenie. Niech możliwości biznesowe określają granice. Używaj diagramów ERD do wyjaśnienia stanu wewnętrznego każdej usługi. Używaj zdarzeń i interfejsów API do zarządzania połączeniami między nimi. Ten podejście zapewnia, że system może się rozwijać bez naruszania podstawowej integralności danych.
W końcu celem nie jest replikacja monolitu w formie rozproszonej. Chodzi o stworzenie systemu, w którym dane są zarządzane z taką samą elastycznością i szybkością, jak kod, który je przetwarza. To równowaga stanowi fundament pomyślnej strategii mikroserwisów.

