











Diagramy relacji encji (ERD) są często odrzucane przez niektórych jako ćwiczenia akademickie lub artefakty stworzone wyłącznie w celu spełnienia wymogów dokumentacji. Jednak dla starszych programistów i architektów diagram ER jest strategicznym projektem, który decyduje o stabilności, wydajności i utrzymalności warstwy danych aplikacji. Wyzwanie nie polega na rysowaniu prostokątów i linii, ale na przezwyciężaniu napięcia między teoretycznym modelowaniem danych a chaotycznymi ograniczeniami środowisk produkcyjnych.
Podczas budowy systemów ciągle dokonujesz kompromisów. Idealnie znormalizowana struktura zapewnia integralność danych, ale może wiązać się z opóźnieniami wydajności podczas złożonych zapytań. Struktura zdenormalizowana przyspiesza odczyty, ale wprowadza nadmiarowość i anomalie aktualizacji. Celem jest znalezienie równowagi, w której diagram dokładnie odzwierciedla domenę biznesową, nie stając się obciążeniem podczas wdrażania.
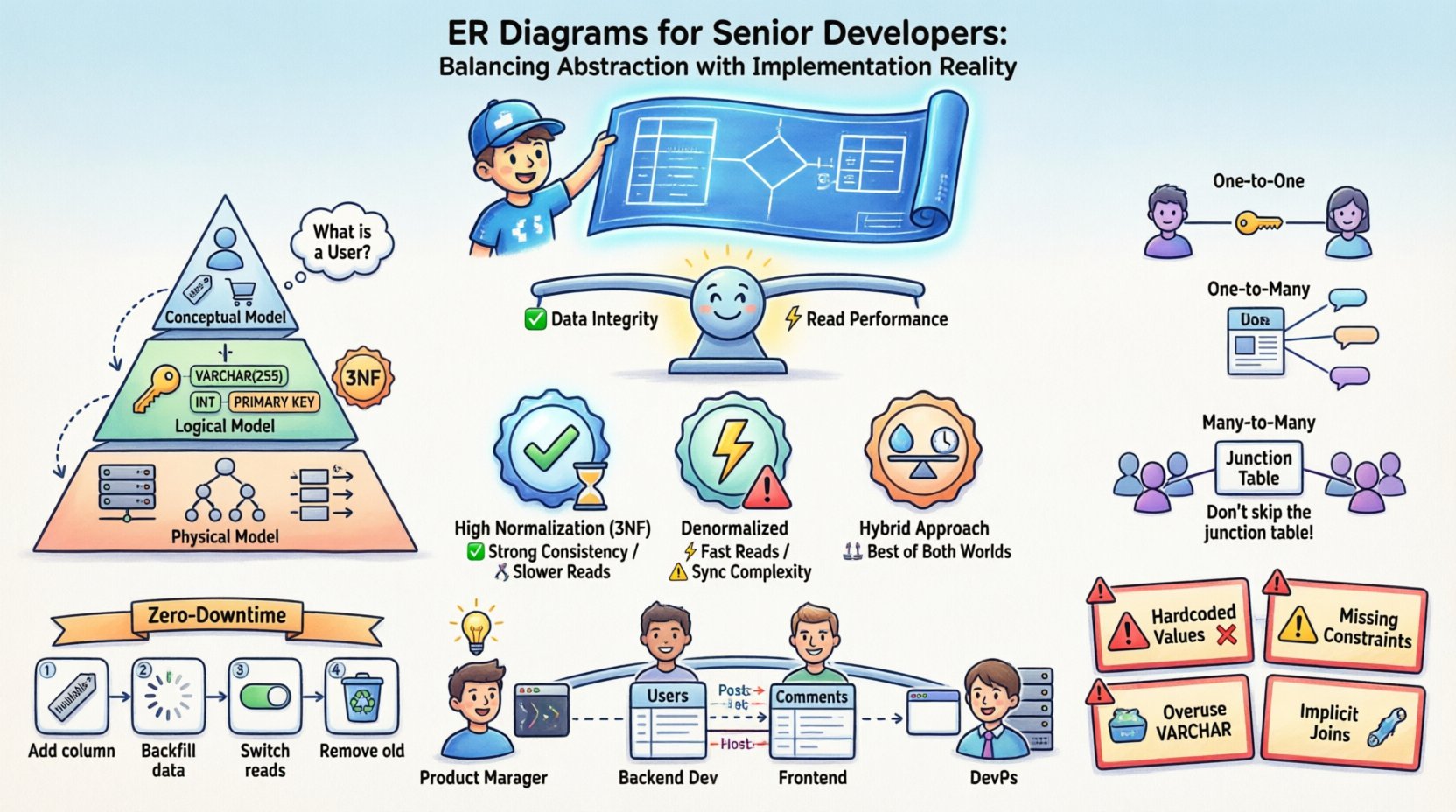
Podwójna natura diagramów relacji encji 📐
Zrozumienie cyklu życia diagramu ER wymaga uznania, że służy wielu właścicielom. Nie jest to statyczny obraz, ale żywy dokument, który ewoluuje razem z oprogramowaniem. Istnieją trzy różne warstwy abstrakcji, które należy zarządzać osobno, aby uniknąć zamieszania między tym, jak dane powinny wyglądać, a tym, jak wyglądały w pamięci.powinnywyglądać, a tym, jak wyglądałyrobiływ pamięci.
- Model koncepcyjny: Ta warstwa skupia się na encjach biznesowych i ich relacjach bez szczegółów technicznych. Odpowiada na pytania takie jak „Co to jest Użytkownik?” i „Jak Użytkownik jest powiązany z Zamówieniem?”. Jest niezależna od technologii.
- Model logiczny: Tutaj wprowadzasz typy danych, klucze i zasady normalizacji. Definiujesz klucze główne i obce, ale jeszcze nie zobowiązujesz się do konkretnej silnika magazynowania bazy danych ani strategii indeksowania.
- Model fizyczny: To jest rzeczywistość implementacji. Zawiera nazwy tabel, typy danych kolumn, strategie partycjonowania, indeksowanie oraz ograniczenia specyficzne dla docelowego systemu baz danych. To właśnie tutaj dzieje się prawdziwa praca.
Zamieszanie często pojawia się, gdy te warstwy są łączone. Starszy programista wie, że w modelu fizycznym kryją się błędy. Relacja koncepcyjna „wiele do wielu” musi zostać rozwiązana w modelu fizycznym poprzez konkretne ograniczenia kluczy obcych, często wymagając tabel pośrednich, które nie istnieją w pierwotnej logice biznesowej.
Warstwy abstrakcji w modelowaniu danych 🧩
Zarządzanie tymi warstwami wymaga dyscypliny. Gdy inwestor prosi o funkcję, opisuje ją w terminach biznesowych. Programista musi przetłumaczyć to na schemat logiczny, a następnie na schemat fizyczny. Pominięcie kroków prowadzi do długu technicznego.
1. Modelowanie koncepcyjne: język biznesowy
Na tym etapie diagram jest narzędziem komunikacji. Zapewnia, że zespół inżynieryjny i zespół produktowy zgadzają się na model domeny. Jeśli diagram pokazuje, że „Klient” może mieć wiele „Adresów”, wszyscy zgadzają się z tym faktem, zanim zostanie napisany pierwszy wiersz SQL.
2. Modelowanie logiczne: zasady współpracy
To jest miejsce, gdzie stosujesz zasady normalizacji. Ustalasz, że „Klient” nie powinien przechowywać swojego „Adresu” bezpośrednio, jeśli ten adres może często się zmieniać i należeć do innych encji. Wprowadzasz normalizację, aby zmniejszyć nadmiarowość. Jednocześnie identyfikujesz dane, które będą często odczytywane i mogą wymagać zdenormalizacji w przyszłości.
3. Modelowanie fizyczne: rzeczywistość implementacji
To jest miejsce, gdzie pojawiają się ograniczenia silnika bazy danych. Możesz musieć wybrać między kolumną JSON a osobną tabelą relacyjną dla elastycznych atrybutów. Decydujesz się na strategie indeksowania na podstawie wzorców zapytań. Możesz zdecydować się na użycie konkretnego silnika magazynowania, który wspiera szybsze zapisy, ale wolniejsze odczyty.
Strategie normalizacji i kompromisy wydajności ⚖️
Normalizacja to podstawowy koncepcja w projektowaniu baz danych. Organizuje dane w celu zmniejszenia nadmiarowości i poprawy integralności danych. Jednak w systemach o dużym zasięgu ścisłe przestrzeganie zasad normalizacji może stać się węzłem szybkości. Starszy programista musi zrozumieć, kiedy warto złamać zasady.
Koszt normalizacji
Gdy normalizujesz dane, często tworzysz więcej tabel. Oznacza to więcej połączeń podczas zapytań. W systemie rozproszonym lub aplikacji internetowej o dużym ruchu każde połączenie może być potencjalnym punktem opóźnienia. Jeśli tabela jest partycjonowana, łączenie między partycjami może być kosztowne.
Kiedy zdenormalizować
Zdenormalizacja to celowe wprowadzanie nadmiarowości w celu optymalizacji wydajności odczytu. To nie błąd, ale decyzja strategiczna. Powinieneś rozważyć zdenormalizację, gdy:
- Operacje odczytu znacznie przewyższają operacje zapisu.
- Złożone łączenia powodują przekroczenie czasu oczekiwania lub wysokie zużycie procesora.
- Tworzysz warstwę raportowania lub analiz, w której spójność w czasie rzeczywistym jest mniej istotna.
- Musisz zdenormalizować dane dla warstw buforowania, aby zmniejszyć obciążenie bazy danych.
Macierz normalizacji wobec wydajności
| Strategia | Integralność danych | Wydajność zapisu | Wydajność odczytu | Utrzymywalność |
|---|---|---|---|---|
| Wysoka normalizacja (3NF) | Wysoka | Szybkie (mniejsza nadmiarowość) | Wolniejsze (wymagają łączeń) | Wysoka (łatwe aktualizacje) |
| Zdenormalizowane | Niższa (wymagana ręczna synchronizacja) | Wolniejsze (więcej danych do zapisania) | Szybsze (mniej łączeń) | Niższa (ryzyko niespójności) |
| Hybrydowa metoda | Umiarkowana | Umiarkowana | Umiarkowana do szybkiej | Umiarkowana (wymaga jasnej logiki) |
Zrozumienie tej macierzy pozwala podejmować świadome decyzje. Nie należy po prostu „normalizować wszystkiego” ani „zdenormalizować wszystkiego”. Analizujesz konkretne wzorce dostępu do aplikacji.
Modelowanie złożonych relacji 🔗
Relacje są jądrem diagramu ER. Definiują, jak ze sobą współdziałają jednostki danych. Choć relacje jeden do jednego i jeden do wielu są proste, relacje wiele do wielu często wymagają starannego traktowania, aby zapewnić skalowalność.
Relacje jeden do jednego
Są one rzadkie w praktyce, ale istnieją. Na przykład profil użytkownika i tabela ustawień profilu użytkownika. Można to zrealizować przez umieszczenie klucza obcego w jednej tabeli lub podzielenie danych na dwie tabele. Decyzja zależy od wzorców dostępu. Jeśli ustawienia są często dostępne razem z profilem, zachowaj je razem. Jeśli są rzadko używane, rozdziel je, aby zmniejszyć rozmiar głównej tabeli.
Relacje jeden do wielu
To najpowszechniejszy wzorzec. Post w blogu ma wiele komentarzy. Klucz obcy znajduje się po stronie „wielu” (komentarze). Jest to wydajne dla zapytań pobierających wszystkie komentarze dla konkretnego posta.
Relacje wiele do wielu
Użytkownik może obserwować wielu użytkowników, a użytkownik może być obserwowany przez wielu użytkowników. Wymaga to tabeli pośredniej. Tabela ta zwykle zawiera klucze obce z obu stron oraz dowolne metadane specyficzne dla relacji, takie jak znacznik czasu, kiedy połączenie zostało utworzone.
- Nie pomijaj tabeli pośredniej: Umożliwia indeksowanie relacji i wykonywanie zapytań efektywnie.
- Rozważ klucze złożone: Klucz główny tabeli pośredniej może być kombinacją dwóch kluczy obcych.
- Zwracaj uwagę na liczność: Upewnij się, że obsługujesz przypadki, gdy relacja jest opcjonalna, a kiedy jest wymagana.
Ewolucja schematu i migracje 🔄
Jednym z trudniejszych aspektów pracy seniora jest zrozumienie, że diagram ER nigdy nie jest gotowy. Wymagania się zmieniają, logika biznesowa się przesuwa, a dane rosną. Twój schemat musi ewoluować bez naruszania istniejącej funkcjonalności.
Wersjonowanie schematu
Nigdy nie zakładaj, że migracja to zdarzenie jednorazowe. Traktuj swój schemat jak kod. Używaj kontroli wersji dla skryptów migracji. Pozwala to cofnąć zmiany, jeśli nowa kolumna spowoduje problem. Daje również ślad audytowy zmian struktury danych w czasie.
Migracje bez przestoju
W systemach produkcyjnych przestoje są często niedopuszczalne. Wymaga to krokowego podejścia do zmian schematu:
- Najpierw dodaj kolumny: Dodaj nową kolumnę jako nullowalną. Wypuść kod, który do niej zapisuje.
- Wypełnij dane: Uruchom zadanie w tle, aby wypełnić nową kolumnę.
- Przełącz czytanie: Zaktualizuj aplikację, aby odczytywała z nowej kolumny.
- Usuń stare kolumny: Gdy system będzie stabilny, usuń stary kanał.
Obsługa blokad
Dodanie indeksu lub ograniczenia na dużej tabeli może zablokować tabelę, zatrzymując zapisy. Musisz używać narzędzi do zmiany schematu online lub strategii partycjonowania, aby zmniejszyć czas blokady. Zrozumienie mechanizmu blokad silnika bazy danych jest tutaj kluczowe.
Typowe pułapki w środowiskach produkcyjnych 🚧
Nawet doświadczeni programiści popełniają błędy przy przekształcaniu diagramów ER do SQL. Znajomość typowych pułapek pomaga uniknąć ich, zanim staną się krytycznymi problemami.
- Wartości stałe: Unikaj używania kolumn `INT` do przechowywania flag logicznych (0/1) bez jawnych ograniczeń. Używaj typów `BOOLEAN` lub typów wyliczeniowych tam, gdzie są obsługiwane.
- Brak ograniczeń: Opieranie się wyłącznie na logice aplikacji w celu zapewnienia kluczy obcych jest ryzykowne. Jeśli błąd pozwoli na nieprawidłowe wstawienie danych, dane zostaną uszkodzone. Zapewnij ograniczenia na poziomie bazy danych.
- Zbyt częste używanie VARCHAR: Choć elastyczny, `VARCHAR` może być wolniejszy niż typy o stałej długości, takie jak `CHAR`, dla niektórych danych. Używaj `CHAR` dla danych o stałej długości, takich jak UUID lub kod pocztowy.
- Ignorowanie zestawów znaków: Jeśli Twoja aplikacja obsługuje znaki międzynarodowe, upewnij się, że baza danych i tabele są skonfigurowane w taki sposób, aby wspierać UTF-8 od samego początku. Zmiana tego później jest trudna.
- Niejawne łączenia: Unikaj zapytań łączących tabele bez jawnych indeksów. Zawsze przeglądaj plan wykonania zapytania.
Komunikacja między zespołami 🤝
Diagram ER to narzędzie komunikacyjne. Zamyka przerwę między administratorami baz danych, programistami backendu, programistami frontendu oraz menedżerami produktu. Jasny diagram zapobiega założeniom.
- Dla menedżerów produktu: Pomaga im zrozumieć wymagania dotyczące danych w przypadku żądania funkcji.
- Dla programistów frontendu: Ujednolica strukturę danych, które otrzymają z interfejsów API.
- Dla DevOps: Informuje o planowaniu pojemności i strategiach kopii zapasowych.
Jeśli diagram jest niejasny, zespół będzie zgadywał. Zgadywanie prowadzi do błędów. Starszy programista zapewnia, że diagram jest dokładny, aktualny i dostępny dla wszystkich uczestników cyklu życia projektu.
Narzędzia vs. myślenie 💡
Istnieje wiele narzędzi do rysowania diagramów ER. Choć są one przydatne do wizualizacji, nie powinny zastąpić myślenia krytycznego. Narzędzie może wygenerować SQL na podstawie diagramu, ale nie rozumie logiki biznesowej stojącej za istnieniem relacji.
- Skup się na logice: Poświęć więcej czasu na tablicy lub w edytorach tekstu na dyskusję modelu niż na klikanie przycisków w narzędziu do rysowania.
- Weryfikuj za pomocą SQL: Po narysowaniu diagramu napisz SQL. Jeśli SQL jest niejasny, diagram prawdopodobnie jest błędny.
- Zachowaj prostotę: Nie przesadzaj z projektowaniem diagramu. Jeśli relacja może zostać wywnioskowana, nie wymuszaj skomplikowanej struktury.
Ostateczne rozważania nad modelowaniem danych 🏁
Tworzenie solidnej warstwy danych to równowaga między teorią a praktyką. Diagram ER to nie tylko obrazek; to umowa między Twoją aplikacją a danymi. Kiedy szanujesz warstwy abstrakcji, rozumiesz kompromisy między normalizacją a wydajnością oraz planujesz ewolucję od samego początku, tworzysz systemy odporne i skalowalne.
Najefektywniejszymi starszymi programistami są ci, którzy patrząc na diagram z pudełkami i liniami, od razu widzą potencjalne zapytania, prawdopodobne węzły zatyczki i ścieżkę migracji. Nie rysują tylko linii – projektują systemy. Skupiając się na tych zasadach, zapewnicasz, że architektura danych wspiera cele biznesowe, nie stając się obciążeniem.

