











Les diagrammes Entité-Relation (ERD) sont souvent rejetés par certains comme des exercices académiques ou des artefacts créés uniquement pour respecter les exigences de documentation. Toutefois, pour les développeurs expérimentés et les architectes, un diagramme ER constitue un plan stratégique qui détermine la stabilité, les performances et la maintenabilité du niveau de données d’une application. Le défi ne réside pas dans le dessin de boîtes et de lignes, mais dans la navigation entre les modèles théoriques de données et les contraintes complexes des environnements de production.
Lors de la construction de systèmes, vous êtes constamment amené à faire des compromis. Un schéma parfaitement normalisé garantit l’intégrité des données, mais peut entraîner des pénalités de performance lors de requêtes complexes. Une structure dénormalisée accélère les lectures, mais introduit de la redondance et des anomalies de mise à jour. L’objectif est de trouver un équilibre où le diagramme reflète fidèlement le domaine métier sans devenir une charge pendant le déploiement.
La nature double des diagrammes Entité-Relation 📐
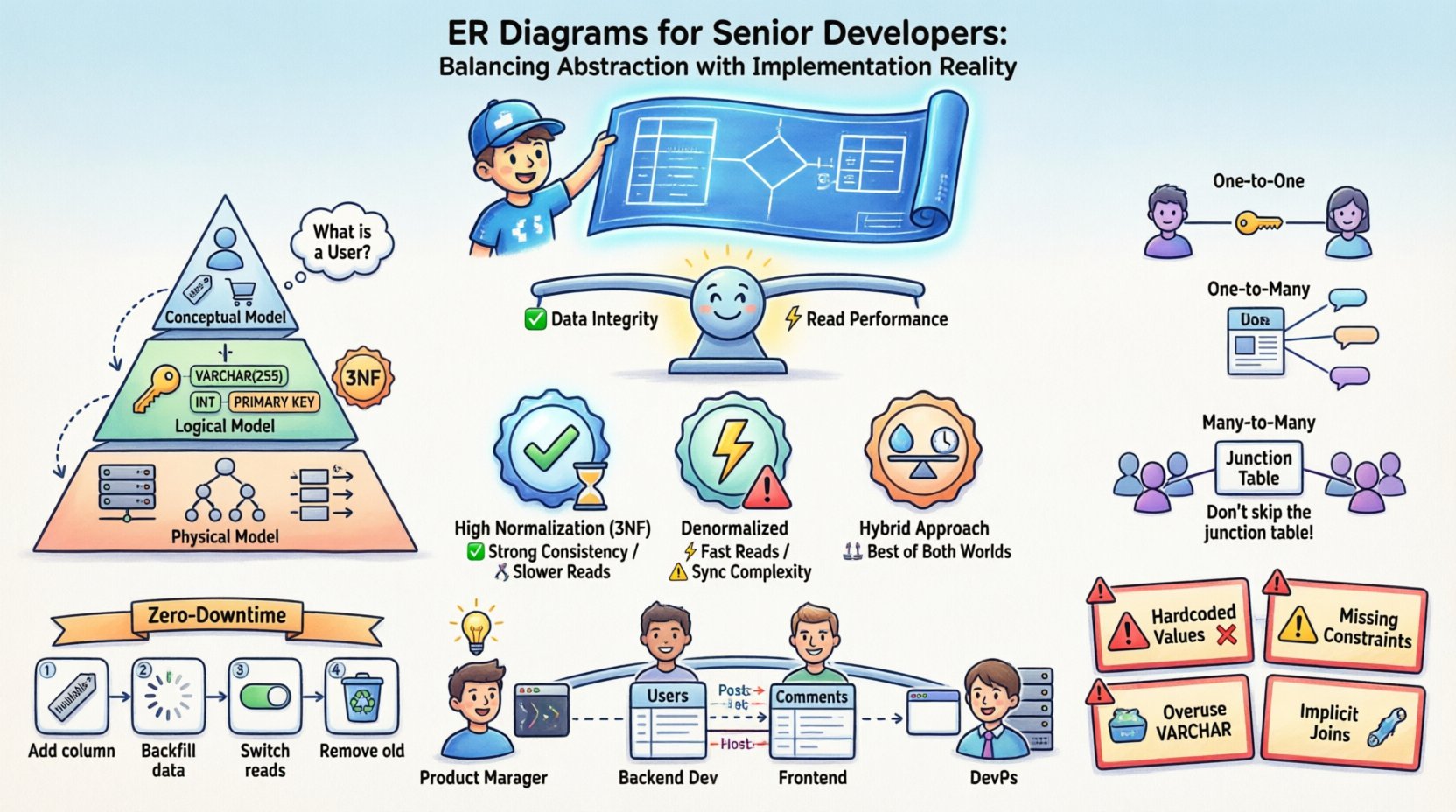
Comprendre le cycle de vie d’un diagramme ER suppose de reconnaître qu’il sert plusieurs maîtres. Ce n’est pas une image statique, mais un document vivant qui évolue parallèlement au logiciel. Il existe trois couches d’abstraction distinctes qui doivent être gérées séparément afin d’éviter toute confusion entre ce que les données devraientdevraient avoir l’air et ce que les données fontont l’air en mémoire.
- Modèle conceptuel : Cette couche se concentre sur les entités métiers et leurs relations sans détails techniques. Elle répond à des questions telles que « Qu’est-ce qu’un Utilisateur ? » et « Comment un Utilisateur est-il lié à une Commande ? ». Elle est indépendante de la technologie.
- Modèle logique : Ici, vous introduisez les types de données, les clés et les règles de normalisation. Vous définissez les clés primaires et étrangères, mais vous ne vous engagez pas encore sur le moteur de stockage ou la stratégie d’indexation spécifique à un moteur de base de données.
- Modèle physique : Il s’agit de la réalité de l’implémentation. Il inclut les noms de tables, les types de données des colonnes, les stratégies de partitionnement, l’indexation et les contraintes spécifiques au système de base de données cible. C’est ici que tout se joue.
La confusion survient souvent lorsque ces couches sont confondues. Un développeur expérimenté sait que c’est dans le modèle physique que se cachent les bogues. Une relation conceptuelle « plusieurs à plusieurs » doit être résolue en contraintes de clés étrangères spécifiques dans le modèle physique, souvent en nécessitant des tables de jonction qui n’existent pas dans la logique métier initiale.
Couches d’abstraction dans la modélisation des données 🧩
Gérer ces couches exige de la discipline. Lorsqu’un intervenant demande une fonctionnalité, il la décrit en termes métiers. Le développeur doit la traduire en schéma logique, puis en schéma physique. Sauter des étapes ici entraîne une dette technique.
1. Modélisation conceptuelle : Le langage métier
À ce stade, le diagramme est un outil de communication. Il garantit que les équipes ingénierie et produit sont d’accord sur le modèle de domaine. Si le diagramme montre qu’un « Client » peut avoir plusieurs « Adresses », tout le monde est d’accord sur ce point avant qu’une seule ligne de SQL ne soit écrite.
2. Modélisation logique : Les règles d’engagement
C’est ici que vous appliquez les règles de normalisation. Vous déterminez qu’un « Client » ne devrait pas stocker directement son « Adresse » si cette adresse peut changer fréquemment et appartenir à d’autres entités. Vous introduisez la normalisation pour réduire la redondance. Toutefois, vous identifiez également les données qui seront très lues et qui pourraient nécessiter une dénormalisation ultérieurement.
3. Modélisation physique : La réalité de l’implémentation
C’est ici que les limites du moteur de base de données entrent en jeu. Vous pourriez devoir choisir entre une colonne JSON et une table relationnelle séparée pour des attributs flexibles. Vous définissez les stratégies d’indexation en fonction des modèles de requêtes. Vous pourriez décider d’utiliser un moteur de stockage spécifique qui permet des écritures plus rapides mais des lectures plus lentes.
Stratégies de normalisation et compromis de performance ⚖️
La normalisation est un concept fondamental dans la conception des bases de données. Elle organise les données pour réduire la redondance et améliorer l’intégrité des données. Toutefois, dans les systèmes à grande échelle, une application stricte des règles de normalisation peut devenir un goulot d’étranglement. Les développeurs expérimentés doivent comprendre quand il faut briser les règles.
Le coût de la normalisation
Lorsque vous normalisez les données, vous créez souvent plus de tables. Cela signifie plus de jointures lors des requêtes. Dans un système distribué ou une application web à fort trafic, chaque jointure est un point potentiel de latence. Si une table est partitionnée, la jointure entre partitions peut être coûteuse.
Quand dénormaliser
La dénormalisation consiste à introduire intentionnellement de la redondance afin d’optimiser les performances de lecture. Ce n’est pas une erreur ; c’est une décision stratégique. Vous devriez envisager la dénormalisation lorsque :
- Les opérations de lecture dominent largement les opérations d’écriture.
- Les jointures complexes provoquent des délais d’attente ou une utilisation élevée du CPU.
- Vous construisez une couche de reporting ou d’analyse où la cohérence en temps réel est moins critique.
- Vous devez dénormaliser les données pour les couches de mise en cache afin de réduire la charge de la base de données.
Matrice de normalisation versus performance
| Stratégie | Intégrité des données | Performance d’écriture | Performance de lecture | Maintenabilité |
|---|---|---|---|---|
| Haute normalisation (3NF) | Élevé | Rapide (moins de redondance) | Plus lent (nécessite des jointures) | Élevé (mises à jour faciles) |
| Dénormalisé | Moins élevé (synchronisation manuelle nécessaire) | Plus lent (plus de données à écrire) | Plus rapide (moins de jointures) | Moins élevé (risque d’incohérence) |
| Approche hybride | Modéré | Modéré | Modéré à rapide | Modéré (nécessite une logique claire) |
Comprendre cette matrice vous permet de prendre des décisions éclairées. Vous ne devez pas simplement « normaliser tout » ou « dénormaliser tout ». Vous analysez les modèles d’accès spécifiques de votre application.
Modélisation des relations complexes 🔗
Les relations sont le cœur d’un diagramme ER. Elles définissent la manière dont les entités de données interagissent. Bien que les relations un-à-un et un-à-plusieurs soient simples, les relations plusieurs-à-plusieurs nécessitent souvent une gestion soigneuse pour assurer l’évolutivité.
Relations un-à-un
Ces relations sont rares en pratique mais existent. Par exemple, un profil utilisateur et une table de paramètres du profil utilisateur. Vous pouvez implémenter cela en plaçant une clé étrangère dans une table ou en divisant les données en deux tables. Le choix dépend des modèles d’accès. Si les paramètres sont fréquemment consultés avec le profil, gardez-les ensemble. Si ils sont rarement consultés, séparez-les pour réduire la taille de la table principale.
Relations un-à-plusieurs
Il s’agit du schéma le plus courant. Un article de blog possède de nombreux commentaires. La clé étrangère se trouve du côté « plusieurs » (commentaires). Cela est efficace pour les requêtes qui récupèrent tous les commentaires d’un article spécifique.
Relations plusieurs-à-plusieurs
Un utilisateur peut suivre de nombreux utilisateurs, et un utilisateur peut être suivi par de nombreux utilisateurs. Cela nécessite une table d’intersection intermédiaire. Cette table contient généralement les clés étrangères des deux côtés, ainsi que tout métadonnées spécifiques à la relation, telles qu’une horodatage indiquant quand la connexion a été établie.
- Ne sautez pas la table d’intersection : Elle vous permet d’indexer la relation et de la requêter de manière efficace.
- Pensez aux clés composées : La clé primaire de la table d’intersection pourrait être une combinaison des deux clés étrangères.
- Faites attention à la cardinalité : Assurez-vous de gérer les cas où la relation est facultative ou obligatoire.
Évolution du schéma et migration 🔄
L’un des aspects les plus difficiles d’être un développeur expérimenté est de réaliser que le diagramme ER n’est jamais terminé. Les exigences évoluent, la logique métier évolue, et les données augmentent. Votre schéma doit évoluer sans briser la fonctionnalité existante.
Versionner le schéma
Ne supposez jamais qu’une migration est un événement ponctuel. Traitez votre schéma comme du code. Utilisez le contrôle de version pour vos scripts de migration. Cela vous permet de revenir en arrière si une nouvelle colonne cause un problème. Cela fournit également une trace d’audit de l’évolution de la structure des données au fil du temps.
Migrations sans temps d’arrêt
Pour les systèmes de production, un temps d’arrêt est souvent inacceptable. Cela exige une approche progressive des modifications de schéma :
- Ajoutez d’abord les colonnes : Ajoutez la nouvelle colonne comme nullable. Déployez le code qui écrit dedans.
- Remplissez les données : Exécutez une tâche en arrière-plan pour remplir la nouvelle colonne.
- Basculez les lectures : Mettez à jour l’application pour lire à partir de la nouvelle colonne.
- Supprimez les anciennes colonnes : Une fois le système stable, supprimez l’ancienne colonne.
Gestion des verrous
L’ajout d’un index ou d’une contrainte sur une grande table peut verrouiller la table, bloquant les écritures. Vous devez utiliser des outils de modification en ligne du schéma ou des stratégies de partitionnement pour minimiser la durée du verrouillage. Comprendre le mécanisme de verrouillage du moteur de base de données sous-jacent est crucial ici.
Péchés courants dans les environnements de production 🚧
Même les développeurs expérimentés commettent des erreurs lors de la traduction des diagrammes ER en SQL. Être conscient des pièges courants vous aide à les éviter avant qu’ils ne deviennent des problèmes critiques.
- Valeurs codées en dur : Évitez d’utiliser des colonnes `INT` pour stocker des indicateurs booléens (0/1) sans contraintes explicites. Utilisez les types `BOOLEAN` ou les types énumérés là où cela est pris en charge.
- Contraintes manquantes :Se fier uniquement à la logique de l’application pour imposer les clés étrangères est risqué. Si un bogue permet une insertion incorrecte, les données sont corrompues. Appliquez les contraintes au niveau de la base de données.
- Surutilisation de VARCHAR :Bien qu’élargi, `VARCHAR` peut être plus lent que les types à longueur fixe comme `CHAR` pour certaines données. Utilisez `CHAR` pour les données de longueur fixe, comme les UUID ou les codes postaux.
- Ignorer les jeux de caractères :Si votre application prend en charge les caractères internationaux, assurez-vous que votre base de données et vos tables sont configurées pour supporter UTF-8 dès le départ. Changer cela plus tard est difficile.
- Jointures implicites :Évitez les requêtes qui joignent des tables sans index explicites. Revoyez toujours le plan d’exécution de la requête.
Communication entre les équipes 🤝
Un diagramme ER est un outil de communication. Il comble le fossé entre les administrateurs de bases de données, les développeurs backend, les développeurs frontend et les gestionnaires de produits. Un diagramme clair évite les hypothèses.
- Pour les gestionnaires de produits :Cela les aide à comprendre les exigences de données liées à une demande de fonctionnalité.
- Pour les développeurs frontend :Cela clarifie la structure des données qu’ils recevront via les API.
- Pour les DevOps :Cela informe la planification de la capacité et les stratégies de sauvegarde.
Si le diagramme est peu clair, l’équipe devinera. Deviner mène à des bogues. Un développeur senior s’assure que le diagramme est précis, à jour et accessible à tous ceux impliqués dans le cycle de vie du projet.
Outils vs. Réflexion 💡
Il existe de nombreux outils pour dessiner des diagrammes ER. Bien qu’ils soient utiles pour la visualisation, ils ne doivent pas remplacer la réflexion critique. Un outil peut générer du SQL à partir d’un diagramme, mais il ne peut pas comprendre la logique métier derrière l’existence d’une relation.
- Concentrez-vous sur la logique :Passez plus de temps au tableau blanc ou dans des éditeurs de texte à discuter du modèle qu’à cliquer sur des boutons dans un outil de dessin.
- Validez avec SQL :Une fois le diagramme dessiné, écrivez le SQL. Si le SQL est confus, le diagramme est probablement défectueux.
- Gardez-le simple :N’over-ingéniez pas le diagramme. Si une relation peut être déduite, ne forcez pas une structure complexe.
Réflexions finales sur la modélisation des données 🏁
Construire une couche de données robuste est un équilibre entre théorie et pratique. Un diagramme ER n’est pas seulement une image ; c’est un contrat entre votre application et vos données. Quand vous respectez les couches d’abstraction, comprenez les compromis entre normalisation et performance, et planifiez l’évolution dès le premier jour, vous créez des systèmes résilients et évolutifs.
Les développeurs seniors les plus efficaces sont ceux qui peuvent regarder un diagramme en boîtes et lignes et immédiatement voir les requêtes potentielles, les goulets d’étranglement probables et le chemin de migration. Ils ne dessinent pas seulement des lignes ; ils conçoivent des systèmes. En vous concentrant sur ces principes, vous assurez que votre architecture des données soutient vos objectifs commerciaux sans devenir une charge.

