











Los diagramas de entidad-relación (ERD) suelen ser descartados por algunos como ejercicios académicos o artefactos creados únicamente para cumplir con los requisitos de documentación. Sin embargo, para desarrolladores senior y arquitectos, un diagrama ER es un plano estratégico que determina la estabilidad, el rendimiento y la mantenibilidad de la capa de datos de una aplicación. El desafío no consiste en dibujar cuadros y líneas, sino en navegar la fricción entre el modelado teórico de datos y las complejas restricciones de los entornos de producción.
Al construir sistemas, estás constantemente haciendo compromisos. Un esquema perfectamente normalizado garantiza la integridad de los datos, pero puede generar penalizaciones de rendimiento durante consultas complejas. Una estructura desnormalizada acelera las lecturas, pero introduce redundancia y anomalías de actualización. El objetivo es encontrar el equilibrio en el que el diagrama refleje con precisión el dominio del negocio sin convertirse en una carga durante la implementación.
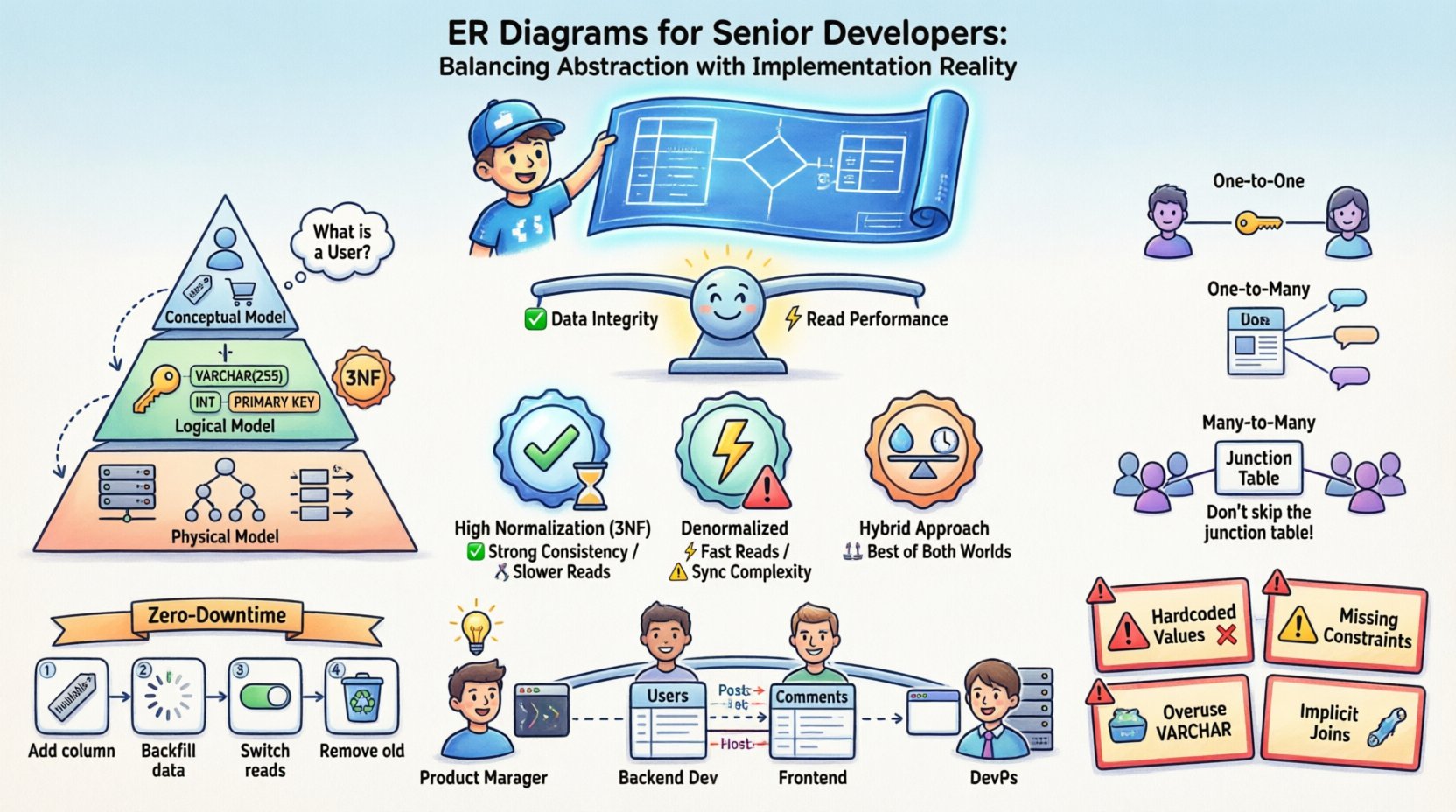
La naturaleza dual de los diagramas de entidad-relación 📐
Comprender el ciclo de vida de un diagrama ER requiere reconocer que sirve a múltiples dueños. No es una imagen estática, sino un documento vivo que evoluciona junto con el software. Existen tres capas distintas de abstracción que deben gestionarse por separado para evitar la confusión entre lo que los datos deberíandeberían parecer y lo que realmente parecen en memoriaparecen en memoria.
- Modelo conceptual: Esta capa se centra en entidades del negocio y sus relaciones sin detalles técnicos. Responde preguntas como «¿Qué es un Usuario?» y «¿Cómo se relaciona un Usuario con un Pedido?». Es independiente de la tecnología.
- Modelo lógico: Aquí introduces tipos de datos, claves y reglas de normalización. Defines claves primarias y foráneas, pero aún no te comprometes con el motor de almacenamiento ni con la estrategia de indexación de un motor de base de datos específico.
- Modelo físico: Este es la realidad de la implementación. Incluye nombres de tablas, tipos de datos de columnas, estrategias de partición, indexación y restricciones específicas del sistema de base de datos objetivo. Aquí es donde la teoría se convierte en práctica.
La confusión surge con frecuencia cuando estas capas se confunden. Un desarrollador senior sabe que en el modelo físico se esconden los errores. Una relación conceptual de «muchos a muchos» debe resolverse en restricciones de clave foránea específicas en el modelo físico, a menudo requiriendo tablas de unión que no existen en la lógica de negocio original.
Capas de abstracción en el modelado de datos 🧩
Gestionar estas capas requiere disciplina. Cuando un interesado solicita una funcionalidad, la describe en términos de negocio. El desarrollador debe traducirla en un esquema lógico, y finalmente en un esquema físico. Saltarse pasos aquí genera deuda técnica.
1. Modelado conceptual: el lenguaje del negocio
En esta etapa, el diagrama es una herramienta de comunicación. Asegura que el equipo de ingeniería y el equipo de producto estén de acuerdo sobre el modelo de dominio. Si el diagrama muestra que un «Cliente» puede tener múltiples «Direcciones», todos acuerdan ese hecho antes de escribir una sola línea de SQL.
2. Modelado lógico: las reglas de compromiso
Aquí aplicas las reglas de normalización. Determinas que un «Cliente» no debería almacenar su «Dirección» directamente si esa dirección podría cambiar con frecuencia y pertenecer a otras entidades. Introduces la normalización para reducir la redundancia. Sin embargo, también identificas qué datos serán de lectura intensiva y podrían requerir desnormalización más adelante.
3. Modelado físico: la realidad de la implementación
Aquí entran en juego las limitaciones del motor de base de datos. Podrías necesitar elegir entre una columna JSON y una tabla relacional separada para atributos flexibles. Decides las estrategias de indexación según los patrones de consulta. Podrías decidir usar un motor de almacenamiento específico que permita escrituras más rápidas, pero lecturas más lentas.
Estrategias de normalización y compromisos de rendimiento ⚖️
La normalización es un concepto fundamental en el diseño de bases de datos. Organiza los datos para reducir la redundancia y mejorar la integridad de los datos. Sin embargo, en sistemas de gran escala, el cumplimiento estricto de las reglas de normalización puede convertirse en un cuello de botella. Los desarrolladores senior deben entender cuándo romper las reglas.
El costo de la normalización
Cuando normalizas los datos, a menudo creas más tablas. Esto significa más uniones al consultar. En un sistema distribuido o una aplicación web de alto tráfico, cada unión es un punto potencial de latencia. Si una tabla está particionada, unirse entre particiones puede ser costoso.
Cuándo desnormalizar
La desnormalización es la introducción intencional de redundancia para optimizar el rendimiento de lectura. No es un error; es una decisión estratégica. Deberías considerar la desnormalización cuando:
- Las operaciones de lectura superan significativamente las operaciones de escritura.
- Las uniones complejas están causando tiempos de espera o un uso elevado de la CPU.
- Estás construyendo una capa de informes o análisis donde la consistencia en tiempo real es menos crítica.
- Necesitas denormalizar los datos para las capas de caché con el fin de reducir la carga de la base de datos.
Matriz de Normalización frente al Rendimiento
| Estrategia | Integridad de los datos | Rendimiento de escritura | Rendimiento de lectura | Mantenibilidad |
|---|---|---|---|---|
| Alta normalización (3FN) | Alto | Rápido (menos redundancia) | Más lento (requiere uniones) | Alto (actualizaciones fáciles) |
| Denormalizado | Más bajo (se necesita sincronización manual) | Más lento (más datos que escribir) | Más rápido (menos uniones) | Más bajo (riesgo de inconsistencia) |
| Enfoque híbrido | Moderado | Moderado | Moderado a rápido | Moderado (requiere lógica clara) |
Comprender esta matriz te permite tomar decisiones informadas. No debes simplemente ‘normalizar todo’ o ‘denormalizar todo’. Debes analizar los patrones específicos de acceso de tu aplicación.
Modelado de relaciones complejas 🔗
Las relaciones son el núcleo de un diagrama ER. Definen cómo interactúan las entidades de datos. Si bien las relaciones uno a uno y uno a muchos son sencillas, las relaciones muchos a muchos a menudo requieren un manejo cuidadoso para garantizar la escalabilidad.
Relaciones uno a uno
Estas son poco comunes en la práctica, pero existen. Por ejemplo, un perfil de usuario y una tabla de configuración de perfiles de usuario. Puedes implementar esto colocando una clave foránea en una tabla o dividiendo los datos en dos tablas. La decisión depende de los patrones de acceso. Si la configuración se accede con frecuencia junto con el perfil, mantén ambos juntos. Si se accede raramente, sepáralos para reducir el tamaño de la tabla principal.
Relaciones uno a muchos
Este es el patrón más común. Una publicación de blog tiene muchas comentarios. La clave foránea se encuentra en el lado «muchos» (comentarios). Esto es eficiente para consultas que recuperan todos los comentarios de una publicación específica.
Relaciones muchos a muchos
Un usuario puede seguir a muchos usuarios, y un usuario puede ser seguido por muchos usuarios. Esto requiere una tabla de unión intermedia. Esta tabla normalmente almacena las claves foráneas de ambos lados, además de cualquier metadato específico de la relación, como una marca de tiempo de cuándo se estableció la conexión.
- No omitas la tabla de unión: Te permite indexar la relación y consultar de forma eficiente.
- Considera claves compuestas: La clave primaria de la tabla de unión podría ser una combinación de las dos claves foráneas.
- Ten cuidado con la cardinalidad: Asegúrate de manejar los casos en los que la relación es opcional frente a obligatoria.
Evolución y migración de esquemas 🔄
Una de las partes más difíciles de ser un desarrollador senior es darse cuenta de que el diagrama ER nunca está terminado. Los requisitos cambian, la lógica de negocio se transforma y los datos crecen. Tu esquema debe evolucionar sin romper la funcionalidad existente.
Versionado del esquema
Nunca asumas que una migración es un evento único. Trata tu esquema como código. Usa control de versiones para tus scripts de migración. Esto te permite deshacer cambios si una nueva columna causa un problema. También proporciona un historial de auditoría de cómo cambió la estructura de los datos con el tiempo.
Migraciones sin tiempo de inactividad
En sistemas de producción, el tiempo de inactividad a menudo es inaceptable. Esto requiere un enfoque por fases para los cambios en el esquema:
- Agrega las columnas primero:Agrega la nueva columna como nullable. Implementa el código que escribe en ella.
- Rellena los datos:Ejecuta un trabajo en segundo plano para rellenar la nueva columna.
- Cambia las lecturas:Actualiza la aplicación para que lea desde la nueva columna.
- Elimina las columnas antiguas:Una vez que el sistema esté estable, elimina la columna antigua.
Manejo de bloqueos
Agregar un índice o una restricción en una tabla grande puede bloquear la tabla, deteniendo las escrituras. Debes usar herramientas de cambio de esquema en línea o estrategias de partición para minimizar la duración del bloqueo. Comprender el mecanismo de bloqueo del motor de base de datos subyacente es crucial aquí.
Errores comunes en entornos de producción 🚧
Incluso los desarrolladores con experiencia cometen errores al traducir diagramas ER a SQL. Estar consciente de los errores comunes te ayuda a evitarlos antes de que se conviertan en problemas críticos.
- Valores codificados:Evita usar columnas `INT` para almacenar marcas booleanas (0/1) sin restricciones explícitas. Usa tipos `BOOLEAN` o tipos enumerados cuando estén disponibles.
- Restricciones faltantes:Confiar únicamente en la lógica de la aplicación para forzar claves foráneas es arriesgado. Si un error permite una inserción incorrecta, los datos se corrompen. Aplicar restricciones a nivel de base de datos.
- Sobreuso de VARCHAR:Aunque es flexible, `VARCHAR` puede ser más lento que los tipos de longitud fija como `CHAR` para ciertos datos. Utilice `CHAR` para datos de longitud fija como UUIDs o códigos postales.
- Ignorar conjuntos de caracteres:Si su aplicación admite caracteres internacionales, asegúrese de que su base de datos y tablas estén configuradas para admitir UTF-8 desde el principio. Cambiar esto más adelante es difícil.
- Uniones implícitas:Evite consultas que unan tablas sin índices explícitos. Revise siempre el plan de ejecución de la consulta.
Comunicación entre equipos 🤝
Un diagrama ER es una herramienta de comunicación. Cierra la brecha entre administradores de bases de datos, desarrolladores backend, desarrolladores frontend y gerentes de producto. Un diagrama claro evita suposiciones.
- Para los gerentes de producto:Les ayuda a comprender los requisitos de datos para una solicitud de funcionalidad.
- Para los desarrolladores frontend:Aclara la estructura de los datos que recibirán desde las APIs.
- Para DevOps:Informa sobre la planificación de capacidad y las estrategias de copia de seguridad.
Si el diagrama no es claro, el equipo adivinará. Adivinar conduce a errores. Un desarrollador senior asegura que el diagrama sea preciso, actualizado y accesible para todos los involucrados en el ciclo de vida del proyecto.
Herramientas frente al pensamiento 💡
Hay muchas herramientas disponibles para dibujar diagramas ER. Aunque son útiles para la visualización, no deben reemplazar el pensamiento crítico. Una herramienta puede generar SQL a partir de un diagrama, pero no puede comprender la lógica empresarial detrás de por qué existe una relación.
- Enfóquese en la lógica:Pase más tiempo en la pizarra o en editores de texto discutiendo el modelo que haciendo clic en botones de una herramienta de dibujo.
- Valide con SQL:Una vez dibujado el diagrama, escriba el SQL. Si el SQL es confuso, es probable que el diagrama esté defectuoso.
- Manténgalo simple:No sobrediseñe el diagrama. Si una relación puede inferirse, no fuerce una estructura compleja.
Reflexiones finales sobre el modelado de datos 🏁
Construir una capa de datos sólida es un equilibrio entre teoría y práctica. Un diagrama ER no es solo una imagen; es un contrato entre su aplicación y sus datos. Cuando respeta las capas de abstracción, entiende los compromisos entre normalización y rendimiento, y planifica la evolución desde el primer día, crea sistemas resilientes y escalables.
Los desarrolladores senior más efectivos son aquellos que pueden mirar un diagrama de cajas y líneas y ver inmediatamente las consultas potenciales, los cuellos de botella probables y la ruta de migración. No solo dibujan líneas; diseñan sistemas. Al centrarse en estos principios, asegura que su arquitectura de datos apoye sus objetivos empresariales sin convertirse en una carga.

