











एंटिटी रिलेशनशिप डायग्राम (ईआरडीएस) को कुछ लोग आकादमिक अभ्यास या केवल डॉक्यूमेंटेशन कंप्लायंस के लिए बनाए गए एर्टिफैक्ट के रूप में नजरअंदाज कर देते हैं। हालांकि, सीनियर डेवलपर्स और आर्किटेक्ट्स के लिए, ईआर डायग्राम एक रणनीतिक ब्लूप्रिंट है जो एप्लीकेशन की डेटा लेयर की स्थिरता, प्रदर्शन और रखरखाव को निर्धारित करता है। चुनौती बॉक्स और लाइनें बनाने में नहीं है, बल्कि सैद्धांतिक डेटा मॉडलिंग और उत्पादन वातावरण की गड़बड़ अनुमतियों के बीच घर्षण को संभालने में है।
जब आप प्रणालियां बना रहे होते हैं, तो आप लगातार ट्रेडऑफ्स कर रहे होते हैं। एक पूरी तरह से नॉर्मलाइज्ड स्कीमा डेटा अखंडता सुनिश्चित करता है, लेकिन जटिल क्वेरी के दौरान प्रदर्शन के नुकसान का कारण बन सकता है। एक डेनॉर्मलाइज्ड संरचना पढ़ने को तेज करती है, लेकिन अतिरिक्तता और अपडेट विचलन लाती है। लक्ष्य यह है कि संतुलन ढूंढना जहां डायग्राम व्यापार क्षेत्र का सही प्रतिबिंब दिखाता है बिना डिप्लॉयमेंट के दौरान एक जोखिम बनने के बावजूद।
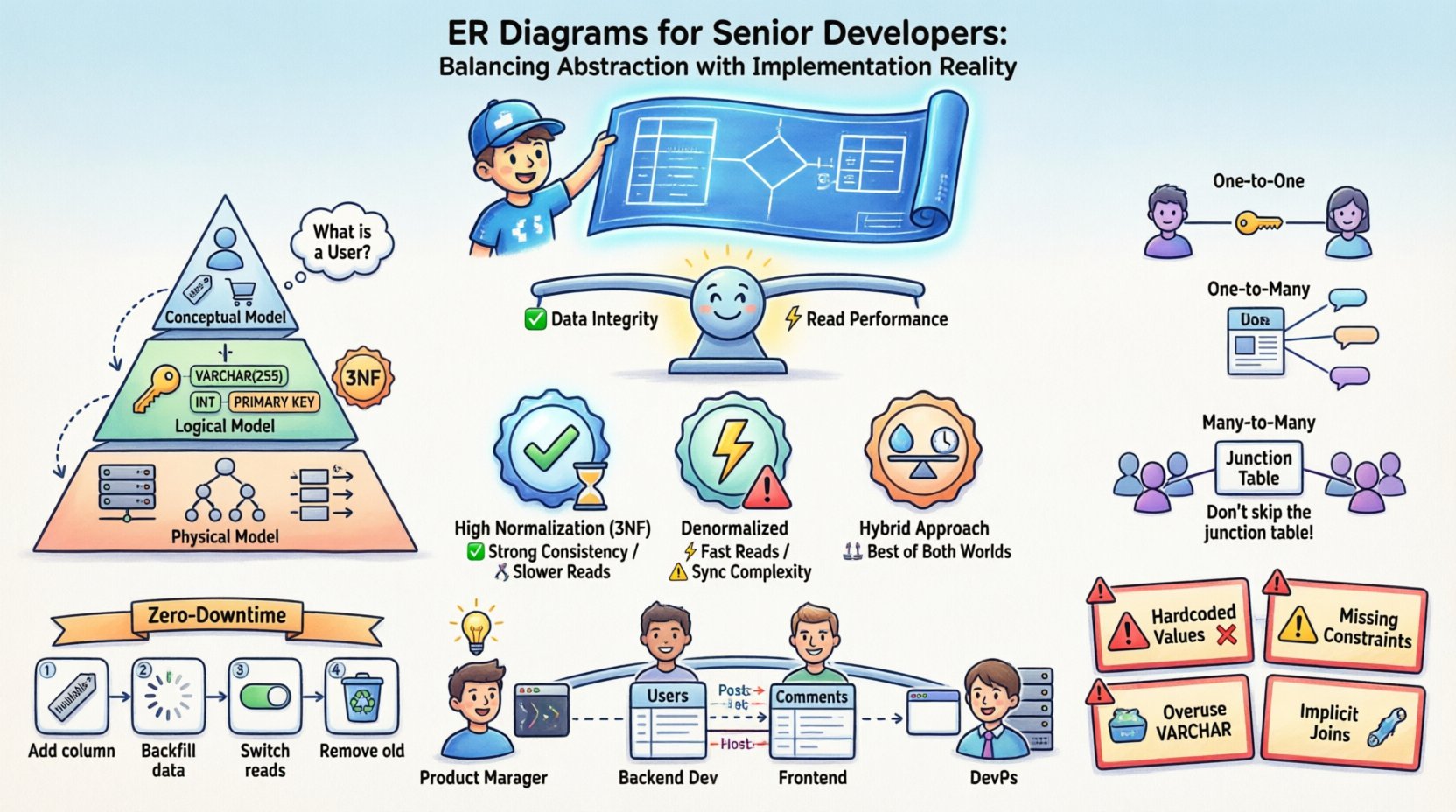
एंटिटी रिलेशनशिप डायग्राम की द्वैत प्रकृति 📐
ईआर डायग्राम के जीवनचक्र को समझने के लिए यह जानना आवश्यक है कि यह कई मालिकों के लिए काम करता है। यह एक स्थिर छवि नहीं है, बल्कि एक जीवंत दस्तावेज है जो सॉफ्टवेयर के साथ विकसित होता रहता है। तीन अलग-अलग स्तरों की अबस्ट्रैक्शन हैं जिन्हें अलग-अलग प्रबंधित करने की आवश्यकता है ताकि डेटा के बारे में जो दिखना चाहिए और जो यह यादृच्छिक स्मृति में दिखता है, उसके बीच भ्रम न हो।होना चाहिएकैसा दिखना चाहिए और जो यह करता हैमेमोरी में कैसा दिखता है।
- अवधारणात्मक मॉडल: इस स्तर पर व्यापार इकाइयों और उनके संबंधों पर ध्यान केंद्रित किया जाता है, तकनीकी विवरणों के बिना। यह “एक उपयोगकर्ता क्या है?” और “एक उपयोगकर्ता एक ऑर्डर से कैसे संबंधित है?” जैसे प्रश्नों के उत्तर देता है। यह तकनीकी निरपेक्ष है।
- तार्किक मॉडल: यहां, आप डेटा प्रकार, कुंजियां और नॉर्मलाइजेशन नियमों को शामिल करते हैं। आप प्राथमिक और विदेशी कुंजियों को परिभाषित करते हैं, लेकिन अभी एक विशिष्ट डेटाबेस इंजन के स्टोरेज इंजन या इंडेक्सिंग रणनीति के प्रति प्रतिबद्ध नहीं होते हैं।
- भौतिक मॉडल: यह इम्प्लीमेंटेशन वास्तविकता है। इसमें टेबल के नाम, कॉलम डेटा प्रकार, पार्टीशनिंग रणनीतियां, इंडेक्सिंग और लक्षित डेटाबेस सिस्टम के लिए विशिष्ट सीमाएं शामिल हैं। यहीं रबर सड़क से टकराता है।
जब इन स्तरों को मिलाया जाता है, तो भ्रम अक्सर उत्पन्न होता है। एक सीनियर डेवलपर जानता है कि भौतिक मॉडल में बग छिपे होते हैं। एक अवधारणात्मक संबंध “बहुत-से-से-बहुत” को भौतिक मॉडल में विशिष्ट विदेशी कुंजी सीमाओं में हल किया जाना चाहिए, जिसमें अक्सर जंक्शन टेबल की आवश्यकता होती है जो मूल व्यापार तर्क में मौजूद नहीं होती है।
डेटा मॉडलिंग में अबस्ट्रैक्शन स्तर 🧩
इन स्तरों को प्रबंधित करने के लिए अनुशासन की आवश्यकता होती है। जब कोई स्टेकहोल्डर एक फीचर के लिए अनुरोध करता है, तो वह इसे व्यापार शब्दों में वर्णित करता है। डेवलपर को इसे एक तार्किक स्कीमा में और अंततः एक भौतिक स्कीमा में अनुवाद करना होता है। यहां स्टेप्स छोड़ने से तकनीकी देनदारी उत्पन्न होती है।
1. अवधारणात्मक मॉडलिंग: व्यापार भाषा
इस चरण में, डायग्राम एक संचार उपकरण है। यह सुनिश्चित करता है कि इंजीनियरिंग टीम और प्रोडक्ट टीम डोमेन मॉडल पर सहमत हैं। यदि डायग्राम दिखाता है कि एक “ग्राहक” के कई “पते” हो सकते हैं, तो एक भी SQL लाइन लिखे जाने से पहले सभी इस तथ्य पर सहमत हो जाते हैं।
2. तार्किक मॉडलिंग: एंगेजमेंट के नियम
यहीं आप नॉर्मलाइजेशन नियमों को लागू करते हैं। आप तय करते हैं कि यदि एक पता अक्सर बदल सकता है और अन्य इकाइयों का हिस्सा हो सकता है, तो एक “ग्राहक” को अपना “पता” सीधे स्टोर नहीं करना चाहिए। आप अतिरिक्तता को कम करने के लिए नॉर्मलाइजेशन लागू करते हैं। हालांकि, आप यह भी पहचानते हैं कि कौन सी डेटा रीड-हेवी होगी और बाद में डेनॉर्मलाइजेशन की आवश्यकता हो सकती है।
3. भौतिक मॉडलिंग: इम्प्लीमेंटेशन वास्तविकता
यहीं डेटाबेस इंजन की सीमाएं खेल में आती हैं। आपको लचीले लक्षणों के लिए JSON कॉलम और अलग रिलेशनल टेबल के बीच चयन करने की आवश्यकता हो सकती है। आप क्वेरी पैटर्न के आधार पर इंडेक्सिंग रणनीतियों का निर्णय लेते हैं। आप एक विशिष्ट स्टोरेज इंजन का उपयोग करने का निर्णय ले सकते हैं जो तेज लेखन का समर्थन करता है लेकिन धीमी पढ़ाई का समर्थन करता है।
नॉर्मलाइजेशन रणनीतियां और प्रदर्शन के ट्रेडऑफ्स ⚖️
नॉर्मलाइजेशन डेटाबेस डिजाइन में एक मूलभूत अवधारणा है। यह डेटा को अतिरिक्तता को कम करने और डेटा अखंडता में सुधार करने के लिए व्यवस्थित करता है। हालांकि, उच्च पैमाने वाली प्रणालियों में, नॉर्मलाइजेशन नियमों के सख्त पालन को एक बफलेट बन सकता है। सीनियर डेवलपर्स को यह समझना चाहिए कि कब नियमों को तोड़ना चाहिए।
नॉर्मलाइजेशन की कीमत
जब आप डेटा को नॉर्मलाइज करते हैं, तो आप अक्सर अधिक टेबल बनाते हैं। इसका मतलब है कि क्वेरी करते समय अधिक जॉइन होंगे। एक वितरित प्रणाली या उच्च ट्रैफिक वेब एप्लीकेशन में, प्रत्येक जॉइन एक संभावित लेटेंसी बिंदु है। यदि एक टेबल पार्टीशन की गई है, तो पार्टीशन के बीच जॉइन करना महंगा हो सकता है।
जब डेनॉर्मलाइज करना चाहिए
डेनॉर्मलाइजेशन पढ़ने के प्रदर्शन को अनुकूलित करने के लिए अतिरिक्तता को जानबूझकर शामिल करना है। यह एक गलती नहीं है; यह एक रणनीतिक निर्णय है। आपको डेनॉर्मलाइजेशन के बारे में सोचना चाहिए जब:
- पठन संचालन लेखन संचालन की तुलना में महत्वपूर्ण रूप से अधिक होते हैं।
- जटिल जॉइन के कारण समय सीमा समाप्त हो जाती है या उच्च सीपीयू उपयोग होता है।
- आप एक रिपोर्टिंग या विश्लेषण परत बना रहे हैं जहां वास्तविक समय की सुसंगतता कम महत्वपूर्ण है।
- कैश परतों के लिए डेटा को अनियमित बनाने की आवश्यकता है ताकि डेटाबेस लोड कम किया जा सके।
नॉर्मलाइजेशन बनाम प्रदर्शन मैट्रिक्स
| रणनीति | डेटा अखंडता | लेखन प्रदर्शन | पठन प्रदर्शन | रखरखाव योग्यता |
|---|---|---|---|---|
| उच्च नॉर्मलाइजेशन (3NF) | उच्च | तेज (कम अतिरेक) | धीमा (जॉइन की आवश्यकता होती है) | उच्च (आसान अपडेट) |
| अनियमित | कम (हाथ से सिंक करने की आवश्यकता होती है) | धीमा (लेखन के लिए अधिक डेटा) | तेज (कम जॉइन) | कम (असंगति का जोखिम) |
| हाइब्रिड दृष्टिकोण | मध्यम | मध्यम | मध्यम से तेज | मध्यम (स्पष्ट तर्क की आवश्यकता होती है) |
इस मैट्रिक्स को समझने से आप सूचित निर्णय लेने में सक्षम होते हैं। आप सिर्फ ‘सभी को नॉर्मलाइज़ करें’ या ‘सभी को अनियमित बनाएं’ नहीं करते हैं। आप अपने एप्लिकेशन के विशिष्ट पहुंच पैटर्न का विश्लेषण करते हैं।
जटिल संबंधों का मॉडलिंग 🔗
संबंध एक ईआर आरेख का केंद्र हैं। वे डेटा एंटिटीज के बीच बातचीत को परिभाषित करते हैं। जबकि एक से एक और एक से बहुत के संबंध स्पष्ट हैं, बहुत से बहुत संबंधों को अक्सर स्केलेबिलिटी सुनिश्चित करने के लिए सावधानी से संभालने की आवश्यकता होती है।
एक से एक संबंध
ये व्यवहार में दुर्लभ हैं लेकिन मौजूद हैं। उदाहरण के लिए, एक उपयोगकर्ता प्रोफाइल और उपयोगकर्ता प्रोफाइल सेटिंग्स टेबल। आप इसे एक टेबल में विदेशी कुंजी रखकर या डेटा को दो टेबलों में विभाजित करके लागू कर सकते हैं। निर्णय पहुंच पैटर्न पर निर्भर करता है। यदि सेटिंग्स को प्रोफाइल के साथ अक्सर प्राप्त किया जाता है, तो उन्हें एक साथ रखें। यदि वे दुर्लभ रूप से प्राप्त किए जाते हैं, तो उन्हें अलग करें ताकि मुख्य टेबल का आकार कम किया जा सके।
एक से बहुत के संबंध
यह सबसे आम पैटर्न है। एक ब्लॉग पोस्ट में कई कमेंट्स होते हैं। विदेशी कुंजी ‘बहुत’ वाली तरफ (कमेंट्स) में रहती है। यह एक विशिष्ट पोस्ट के सभी कमेंट्स को प्राप्त करने वाले प्रश्नों के लिए कुशल है।
बहुत से बहुत के संबंध
एक उपयोगकर्ता कई उपयोगकर्ताओं को फॉलो कर सकता है, और एक उपयोगकर्ता कई उपयोगकर्ताओं द्वारा फॉलो किया जा सकता है। इसके लिए एक मध्यवर्ती जंक्शन तालिका की आवश्यकता होती है। इस तालिका में आमतौर पर दोनों तरफ की विदेशी कुंजियाँ और संबंध के लिए विशिष्ट कोई भी मेटाडेटा शामिल होता है, जैसे कि संबंध स्थापित करने का समयांक।
- जंक्शन तालिका को छोड़ें नहीं: यह आपको संबंध को सूचीबद्ध करने और प्रश्नों को कुशलता से प्रश्न करने की अनुमति देता है।
- मिश्रित कुंजियों को विचार में लें: जंक्शन तालिका की प्राथमिक कुंजी दो विदेशी कुंजियों के संयोजन हो सकती है।
- कार्डिनैलिटी का ध्यान रखें: सुनिश्चित करें कि आप उन मामलों को संभालें जहाँ संबंध वैकल्पिक है बनाम अनिवार्य है।
स्कीमा विकास और माइग्रेशन 🔄
सीनियर डेवलपर बनने के सबसे कठिन हिस्सों में से एक यह समझना है कि ईआर आरेख कभी भी पूरा नहीं होता। आवश्यकताएँ बदलती हैं, व्यावसायिक तर्क बदलता है, और डेटा बढ़ता है। आपके स्कीमा को मौजूदा कार्यक्षमता को तोड़े बिना विकसित होना चाहिए।
स्कीमा का संस्करण निर्धारण
कभी भी नहीं मानें कि माइग्रेशन एक बार की घटना है। अपने स्कीमा को कोड की तरह लें। अपने माइग्रेशन स्क्रिप्ट्स के लिए संस्करण नियंत्रण का उपयोग करें। यह आपको बदलाव वापस लेने की अनुमति देता है यदि एक नया कॉलम समस्या पैदा करता है। इसके अलावा, यह डेटा संरचना के समय के साथ कैसे बदली इसका लेखा-जोखा प्रदान करता है।
शून्य डाउनटाइम माइग्रेशन
उत्पादन प्रणालियों के लिए, बंदी अक्सर अस्वीकार्य होती है। इसके लिए स्कीमा बदलावों के चरणबद्ध दृष्टिकोण की आवश्यकता होती है:
- सबसे पहले कॉलम जोड़ें: नए कॉलम को नल-सहिष्णु बनाएं। उसमें लिखने वाले कोड को डेप्लॉय करें।
- डेटा भरें: नए कॉलम को भरने के लिए एक बैकग्राउंड कार्य चलाएं।
- पढ़ने को बदलें: एप्लिकेशन को नए कॉलम से पढ़ने के लिए अपडेट करें।
- पुराने कॉलम हटाएं: जब तक प्रणाली स्थिर नहीं हो जाती, पुराने कॉलम को हटा दें।
लॉक का प्रबंधन
एक बड़ी तालिका पर एक सूचकांक या प्रतिबंध जोड़ने से तालिका लॉक हो सकती है, जिससे लेखन रुक जाता है। आपको लॉक के दौरान कम से कम समय के लिए ऑनलाइन स्कीमा बदलाव टूल या पार्टीशनिंग रणनीतियों का उपयोग करना होगा। यहाँ नीचे वाले डेटाबेस इंजन के लॉकिंग तंत्र को समझना आवश्यक है।
उत्पादन परिवेशों में सामान्य त्रुटियाँ 🚧
यहाँ तक कि अनुभवी डेवलपर भी ईआरडी को एसक्यूएल में बदलते समय गलतियाँ करते हैं। सामान्य त्रुटियों के बारे में जागरूक होने से आप उन्हें आलाप बनने से पहले बच सकते हैं।
- कड़े मान: निर्पक्ष प्रतिबंधों के बिना `INT` कॉलम का उपयोग बूलियन फ्लैग (0/1) स्टोर करने के लिए न करें। जहाँ समर्थित हो, `BOOLEAN` प्रकार या प्रकार सूचीबद्ध प्रकार का उपयोग करें।
- अनुपस्थित सीमाएँ: विदेशी कुंजियों को लागू करने के लिए केवल एप्लिकेशन लॉजिक पर निर्भर रहना जोखिम भरा है। यदि कोई बग खराब इनसर्ट की अनुमति देता है, तो डेटा क्षतिग्रस्त हो जाता है। सीमाओं को डेटाबेस स्तर पर लागू करें।
- VARCHAR का अत्यधिक उपयोग: जबकि यह लचीला है, `VARCHAR` कुछ डेटा के लिए `CHAR` जैसे निश्चित लंबाई वाले प्रकारों की तुलना में धीमा हो सकता है। UUIDs या पोस्टल कोड जैसे निश्चित लंबाई वाले डेटा के लिए `CHAR` का उपयोग करें।
- अक्षर सेट के बारे में उपेक्षा करना: यदि आपकी एप्लिकेशन अंतरराष्ट्रीय अक्षरों का समर्थन करती है, तो सुनिश्चित करें कि आपके डेटाबेस और टेबल को शुरुआत से ही UTF-8 का समर्थन करने के लिए कॉन्फ़िगर किया गया है। बाद में इसे बदलना मुश्किल होता है।
- अप्रत्यक्ष जॉइन्स: ऐसे क्वेरीज़ से बचें जो स्पष्ट इंडेक्स के बिना टेबल्स को जोड़ती हैं। हमेशा क्वेरी निष्पादन योजना की समीक्षा करें।
टीमों के बीच संचार 🤝
एक एर डायग्राम एक संचार उपकरण है। यह डेटाबेस प्रशासकों, बैकएंड विकासकर्मियों, फ्रंटएंड विकासकर्मियों और उत्पाद प्रबंधकों के बीच के अंतर को पार करता है। एक स्पष्ट डायग्राम अनुमानों को रोकता है।
- उत्पाद प्रबंधकों के लिए: यह उन्हें एक फीचर अनुरोध के लिए डेटा आवश्यकताओं को समझने में मदद करता है।
- फ्रंटएंड विकासकर्मियों के लिए: यह उनके द्वारा एपीआई से प्राप्त डेटा की संरचना को स्पष्ट करता है।
- डेवोप्स के लिए: यह क्षमता योजना और बैकअप रणनीतियों के बारे में जानकारी देता है।
यदि डायग्राम अस्पष्ट है, तो टीम अनुमान लगाएगी। अनुमान लगाने से बग आते हैं। एक सीनियर विकासकर्मी सुनिश्चित करता है कि डायग्राम सही, अद्यतन और प्रोजेक्ट चक्र में शामिल सभी लोगों तक पहुँच योग्य है।
उपकरण बनाम सोच 💡
एर डायग्राम बनाने के लिए कई उपकरण उपलब्ध हैं। जबकि वे दृश्यीकरण के लिए उपयोगी हैं, उन्हें आलोचनात्मक सोच के स्थान पर नहीं रखा जाना चाहिए। एक उपकरण डायग्राम से SQL उत्पन्न कर सकता है, लेकिन यह नहीं समझ सकता कि एक संबंध क्यों मौजूद है, इसके पीछे का व्यावसायिक तर्क क्या है।
- तर्क पर ध्यान केंद्रित करें: ड्रॉइंग टूल में बटन दबाने के बजाय, मॉडल पर चर्चा करने के लिए व्हाइटबोर्ड या टेक्स्ट एडिटर पर अधिक समय बिताएं।
- SQL के साथ प्रमाणीकरण करें: जब डायग्राम बन जाए, तो SQL लिखें। यदि SQL भ्रमित है, तो डायग्राम शायद दोषपूर्ण है।
- इसे सरल रखें: डायग्राम को अत्यधिक जटिल न बनाएं। यदि संबंध निष्कर्ष निकाला जा सकता है, तो जटिल संरचना को बल न डालें।
डेटा मॉडलिंग पर अंतिम विचार 🏁
एक टिकाऊ डेटा परत बनाना सिद्धांत और व्यावहार के बीच संतुलन है। एक एर डायग्राम केवल एक चित्र नहीं है; यह आपके एप्लिकेशन और आपके डेटा के बीच एक अनुबंध है। जब आप अबस्ट्रैक्शन लेयर का सम्मान करते हैं, नॉर्मलाइजेशन और प्रदर्शन के बीच व्यापार को समझते हैं, और प्रारंभ से ही विकास की योजना बनाते हैं, तो आप ऐसी प्रणालियाँ बनाते हैं जो लचीली और स्केलेबल होती हैं।
सबसे प्रभावी सीनियर विकासकर्मी वे हैं जो बॉक्स और लाइन वाले डायग्राम को देखकर तुरंत संभावित क्वेरीज़, संभावित बॉटलनेक्स और माइग्रेशन पथ को देख सकते हैं। वे केवल रेखाएँ नहीं खींचते; वे प्रणालियाँ डिज़ाइन करते हैं। इन सिद्धांतों पर ध्यान केंद्रित करके, आप सुनिश्चित करते हैं कि आपकी डेटा आर्किटेक्चर आपके व्यापार लक्ष्यों का समर्थन करती है, बिना एक दायित्व बने।

