











सॉफ्टवेयर आर्किटेक्चर में डेटाबेस स्कीमा डिजाइन करना सबसे महत्वपूर्ण कार्यों में से एक है। खराब ढंग से बनाए गए डेटा मॉडल से एप्लिकेशन के पैमाने पर बढ़ने पर प्रदर्शन के बॉटलनेक, सुरक्षा के खतरे और महत्वपूर्ण तकनीकी ऋण की संभावना होती है। इस गाइड में हम एक उपयोगकर्ता प्रबंधन सेवा के लिए विशेष रूप से डिज़ाइन किए गए एक बल्क एंटिटी रिलेशनशिप डायग्राम (ईआरडी) बनाने की प्रक्रिया के माध्यम से चलेंगे। हम प्रारंभिक अवधारणा से लेकर उत्पादन-तैयार स्कीमा तक जाएंगे, जिसमें डेटा अखंडता, सुरक्षा संगतता और स्केलेबिलिटी पर ध्यान केंद्रित करेंगे।
📋 स्कोप और आवश्यकताओं को समझना
किसी भी लाइन या टेबल को परिभाषित करने से पहले, आपको सेवा की कार्यात्मक आवश्यकताओं को समझना होगा। उपयोगकर्ता प्रबंधन प्रणाली केवल नाम और ईमेल स्टोर करने के बारे में नहीं है; यह पहचान, अनुमतियों और ऑडिट ट्रेल के प्रबंधन के बारे में है। मुख्य कार्यकर्ताओं और उनके बातचीत के बारे में सूची बनाना शुरू करें।
- प्रशासक:अन्य उपयोगकर्ताओं और सिस्टम सेटिंग्स को प्रबंधित करने के लिए पूर्ण पहुंच की आवश्यकता होती है।
- अंतिम उपयोगकर्ता:प्रमाणीकरण, प्रोफाइल अपडेट करना और विशिष्ट विशेषताओं तक पहुंच की आवश्यकता होती है।
- प्रणाली:स्वचालित लॉगिंग और सत्र प्रबंधन की आवश्यकता होती है।
शुरुआत में डेटा प्रकार और सीमाओं को ध्यान में रखें। क्या आप अंतरराष्ट्रीय अक्षरों का समर्थन करेंगे? आप समय क्षेत्रों को कैसे संभालेंगे? इन निर्णयों को आपके डायग्राम में फील्ड परिभाषाओं पर प्रभाव पड़ता है। एक व्यापक आवश्यकता दस्तावेज आपके ईआरडी के लिए ब्लूप्रिंट के रूप में कार्य करता है, जिससे डिज़ाइन चरण में कोई महत्वपूर्ण एंटिटी न छूटे।
🏗️ मुख्य एंटिटी को परिभाषित करना
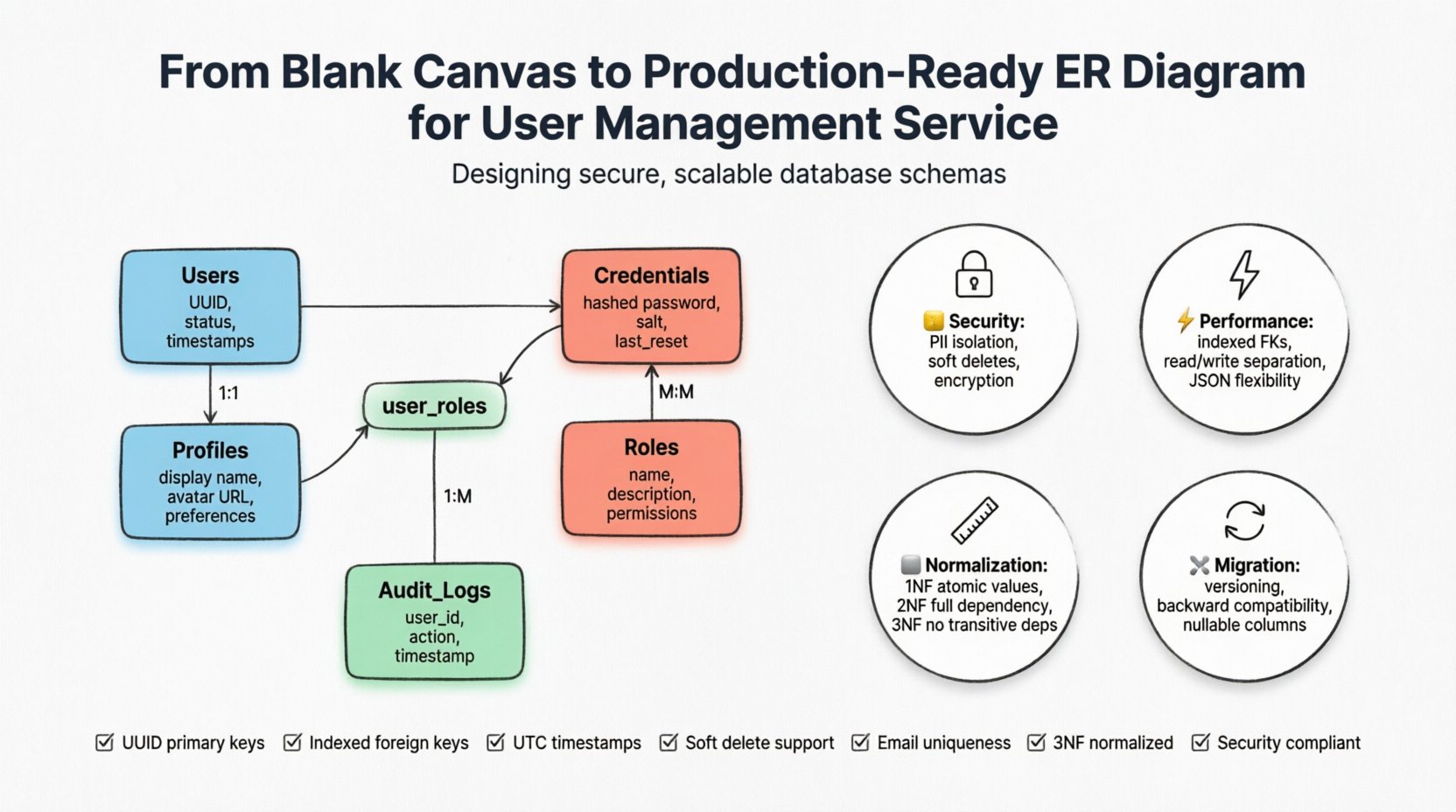
किसी भी उपयोगकर्ता प्रबंधन प्रणाली का आधार मुख्य एंटिटी में होता है। ये वे टेबल हैं जो स्थायी डेटा संग्रहीत करेंगी। हम पांच प्राथमिक एंटिटी की पहचान करेंगे:उपयोगकर्ता, प्रोफाइल, प्रमाणपत्र, भूमिकाएं, औरऑडिट लॉग.
1. उपयोगकर्ता एंटिटी
यह केंद्रीय पहचान वस्तु है। इसमें संवेदनशील डेटा के बजाय यूनिक आईडी और स्थिति फ्लैग होने चाहिए। एक अच्छी तरह से संरचित उपयोगकर्ता टेबल में शामिल है:
- यूयूआईडी:एक स्वतंत्र रूप से अद्वितीय पहचानकर्ता, ऑटो-इनक्रीमेंट इंटीजर के बजाय। इससे संख्या बढ़ाने वाले हमलों को रोका जाता है और क्षैतिज स्केलिंग में सहायता मिलती है।
- स्थिति:एक प्रकार के फील्ड (उदाहरण के लिए, सक्रिय, निलंबित, हटाया गया) जिससे रिकॉर्ड हटाए बिना पहुंच को नियंत्रित किया जा सके।
- मेटाडेटा: रचना और अंतिम अद्यतन के लिए समयांक।
2. प्रोफ़ाइल एंटिटी
मुख्य उपयोगकर्ता तालिका में प्रदर्शन नाम, अवतार और संपर्क जानकारी संग्रहीत करने से ब्लॉट हो सकता है। एक प्रोफ़ाइल एंटिटी एक-एक के संबंध की अनुमति देती है, जिससे मूल प्रमाणीकरण तालिका संक्षिप्त रहती है।
- प्रदर्शन नाम: सार्वजनिक दृश्यता के लिए।
- अवतार URL: बाइनरी डेटा संग्रहीत करने के बजाय बाहरी स्टोरेज से लिंक करें।
- पसंदीदा: थीम सेटिंग्स और सूचना पसंदीदा के लिए JSON या अलग तालिका।
3. प्रमाणपत्र एंटिटी
सुरक्षा अत्यंत महत्वपूर्ण है। प्रमाणीकरण विवरण को उपयोगकर्ता पहचान डेटा से अलग करना चाहिए। इस अलगाव के कारण सुरक्षा प्रोटोकॉल को बदले बिना उपयोगकर्ता पहचान संरचना को बदले बिना आसानी से घूमाया जा सकता है।
- हैश किया गया पासवर्ड: कभी भी सामान्य पाठ संग्रहीत न करें। एक मजबूत हैशिंग एल्गोरिदम का उपयोग करें।
- लवांग: सुनिश्चित करें कि प्रत्येक उपयोगकर्ता के पास एक अद्वितीय लवांग मान हो।
- अंतिम रीसेट समय: सुरक्षा नीतियों के लिए पासवर्ड बदलाव का ट्रैक रखें।
🔗 संबंधों और कार्डिनैलिटी का मॉडलिंग
एंटिटी को परिभाषित करने के बाद, उनके बीच संबंध स्थापित करने की आवश्यकता होती है। कार्डिनैलिटी यह निर्धारित करती है कि एक एंटिटी के कितने उदाहरण दूसरे एंटिटी से संबंधित हैं। इन संबंधों को गलत समझना डेटा अतिरेक का एक सामान्य कारण है।
| संबंध | प्रकार | तर्क |
|---|---|---|
| उपयोगकर्ता और प्रोफ़ाइल | एक-एक | प्रत्येक उपयोगकर्ता के ठीक एक प्रोफ़ाइल विवरण सेट होते हैं। |
| उपयोगकर्ता और भूमिकाएं | बहुत-बहुत | एक उपयोगकर्ता कई भूमिकाएं रख सकता है, और एक भूमिका कई उपयोगकर्ताओं को नियुक्त की जा सकती है। |
| उपयोगकर्ता और ऑडिट लॉग | एक-बहुत | एक उपयोगकर्ता क्रिया एक लॉग प्रविष्टि उत्पन्न करती है, लेकिन एक उपयोगकर्ता कई लॉग उत्पन्न करता है। |
| भूमिका और अनुमतियाँ | बहुत-से-बहुत | भूमिकाएँ अनुमतियों को परिभाषित करती हैं, लेकिन अनुमतियाँ भूमिकाओं के बीच साझा की जा सकती हैं। |
बहुत-से-बहुत संबंध को लागू करने के लिए, आपको एक संयोजन तालिका पेश करनी होगी। उदाहरण के लिए, उपयोगकर्ताओं और भूमिकाओं के बीच, एक बनाएँउपयोगकर्ता_भूमिकाएँतालिका। इस तालिका में उपयोगकर्ता और भूमिका तालिकाओं के मुख्य कुंजियों की ओर इशारा करने वाली विदेशी कुंजियाँ होती हैं। इस संरचना से संदर्भी अखंडता सुनिश्चित होती है और लचीले अनुमति निर्धारण की अनुमति मिलती है।
📉 सामान्यीकरण और डेटा अखंडता
एक उत्पादन-तैयार योजना अतिरेक को कम करने के लिए सामान्यीकरण सिद्धांतों का पालन करती है। तीसरे सामान्य रूप (3NF) मानक लक्ष्य है, लेकिन व्यापार विकल्पों को समझना आवश्यक है।
पहला सामान्य रूप (1NF)
सुनिश्चित करें कि प्रत्येक कॉलम में परमाणु मान हों। एक ही कॉलम में कई ईमेल पते स्टोर करने से बचें। यदि उपयोगकर्ता के कई सत्यापित ईमेल हैं, तो संपर्कों के लिए अलग तालिका का उपयोग करें।
दूसरा सामान्य रूप (2NF)
सुनिश्चित करें कि गुणांक विशेषताएँ मुख्य कुंजी पर पूरी तरह निर्भर हों। संयुक्त कुंजी के मामले में, सुनिश्चित करें कि कोई आंशिक निर्भरता न हो। उपयोगकर्ता प्रबंधन के लिए, मुख्य कुंजी के रूप में एकल UUID का उपयोग इस प्रक्रिया को बहुत सरल बनाता है।
तीसरा सामान्य रूप (3NF)
सुनिश्चित करें कि कोई स्थानांतरित निर्भरता न हो। यदि उपयोगकर्ता का देश उनकी कर दर निर्धारित करता है, तो देश को उपयोगकर्ता तालिका से अलग स्टोर करें और उपयोगकर्ता को देश से जोड़ें। इससे कर दरों में अपडेट करने की अनुमति मिलती है बिना हर उपयोगकर्ता रिकॉर्ड को संशोधित किए।
सामान्यीकरण केवल सिद्धांत के बारे में नहीं है; यह एकमात्र सत्य के स्रोत को बनाए रखने के बारे में है। जब डेटा तालिकाओं के बीच दोहराया जाता है, तो अपडेट त्रुटिपूर्ण हो जाते हैं। डेटा को परमाणु रखकर, आप सुनिश्चित करते हैं कि सुसंगतता डेटाबेस इंजन द्वारा स्वतः ही बनाए रखी जाती है।
🔒 सुरक्षा और सुसंगतता के मामले
एक डेटाबेस योजना उपयोगकर्ता डेटा के लिए पहली रक्षा रेखा है। GDPR या CCPA जैसे नियमों के अनुपालन के लिए विशिष्ट योजना डिजाइन चयन आवश्यक हैं।
- PII का अलगाव:व्यक्तिगत रूप से पहचाने जाने वाली जानकारी को एन्क्रिप्टेड कॉलम या सख्त पहुंच नियंत्रण वाली अलग तालिकाओं में स्टोर किया जाना चाहिए।
- भूलने का अधिकार:आपकी योजना में सॉफ्ट डिलीट या डेटा अनामीकरण का समर्थन होना चाहिए। एक पंक्ति को हटाने के बजाय, इसे हटाए गए के रूप में चिह्नित करें और PII फ़ील्ड को एक सामान्य स्थानापन्न से बदल दें।
- ऑडिट ट्रेल्स:एक अपरिवर्तनीय लॉग तालिका कार्यान्वित करें। यह रिकॉर्ड करें कि किसने किस डेटा को और कब बदला। यह जवाबदेही के लिए महत्वपूर्ण है।
- आराम के समय एन्क्रिप्शन:संवेदनशील डेटा स्टोर करने वाले फ़ील्ड को डेटाबेस-स्तरीय एन्क्रिप्शन विशेषताओं के साथ संगत बनाने का डिजाइन करें।
अपने लॉग के रखरखाव नीति को ध्यान में रखें। अनंत तक बढ़ने वाली तालिका प्रदर्शन को खराब कर सकती है। ऑडिट लॉग तालिका के लिए एक विभाजन रणनीति कार्यान्वित करें, पुराने रिकॉर्ड को कोल्ड स्टोरेज में संग्रहीत करें या नीति के आधार पर उन्हें हटा दें।
⚡ प्रदर्शन और स्केलेबिलिटी पैटर्न
उत्पादन के लिए डिजाइन करना लोड की अपेक्षा करने का अर्थ है। 100 उपयोगकर्ताओं के लिए काम करने वाली योजना 100,000 उपयोगकर्ताओं पर विफल हो सकती है। इंडेक्सिंग रणनीतियाँ ईआरडी डिजाइन प्रक्रिया का एक महत्वपूर्ण हिस्सा हैं।
विदेशी कुंजियों का इंडेक्सिंग
विदेशी कुंजी कॉलम का हमेशा इंडेक्स बनाएं। यदि आप उपयोगकर्ताओं को उनके भूमिका ID द्वारा प्रश्न करते हैं, तो डेटाबेस को विदेशी कुंजी कॉलम पर इंडेक्स की आवश्यकता होती है ताकि पूरी टेबल स्कैन करने से बचा जा सके। यह शुरुआती डिजाइनों में एक सामान्य लापरवाही है।
पढ़ना बनाम लेखन अलगाव
जबकि एरडी तार्किक संरचना को परिभाषित करता है, भौतिक अलगाव को भी ध्यान में रखें। उपयोगकर्ता प्रमाणीकरण डेटा (प्रमाणपत्र) पढ़ने पर अधिक निर्भर है। प्रोफाइल डेटा पढ़ने पर अधिक निर्भर है। ऑडिट लॉग लेखन पर अधिक निर्भर है। यदि एंटिटी सीमाएं स्पष्ट हैं, तो बाद में शार्डिंग या पठन प्रतिलिपि समर्थन करने के लिए स्कीमा डिजाइन करना आसान होता है।
लचीलापन के लिए JSON फ़ील्ड
आधुनिक डेटाबेस JSON कॉलम का समर्थन करते हैं। उपयोगकर्ताओं के बीच बहुत अंतर वाले लक्षणों के लिए इनका उपयोग करें, जैसे कि कस्टम फ़ील्ड या सेटिंग्स। यह हर नए फीचर के लिए स्कीमा माइग्रेशन से बचाता है, हालांकि इसका मूल्य जांच प्रदर्शन के रूप में आता है।
🛠️ माइग्रेशन और जीवनचक्र प्रबंधन
उत्पादन डेटाबेस कभी भी स्थिर नहीं होता है। आवश्यकताओं में परिवर्तन के साथ यह विकसित होता रहता है। एरडी को इस विकास को स्वीकार करना चाहिए।
- संस्करण निर्धारण: उत्पादन में टेबल को सीधे बदलें नहीं। माइग्रेशन स्क्रिप्ट का उपयोग करें जो नए टेबल बनाती हैं और डेटा कॉपी करती हैं, फिर संदर्भ बदलती हैं।
- पीछे की ओर संगतता: जब कोई कॉलम जोड़ते हैं, तो शुरू में इसे खाली छोड़ने की अनुमति दें। इससे ऐसे अस्तित्व में अनुप्रयोग कोड को नुकसान नहीं पहुंचता जो मूल्य को तुरंत सेट नहीं करता है।
- सीमाएं: ढीली सीमाओं के साथ शुरुआत करें और डेटा स्थिर होने पर उन्हें कसकर बनाएं। बहुत जल्दी सख्त अद्वितीयता लागू करने से विकास रुक सकता है।
एक के लिए विचार करेंसंस्करण मुख्य टेबल में एक कॉलम जोड़ने के बारे में सोचें। यदि आप डेटा संरचनाओं के लिए एप्लीकेशन-स्तरीय संस्करण निर्धारण लागू करते हैं, तो इससे आप स्कीमा परिवर्तनों को ट्रैक कर सकते हैं।
🚧 बचने के लिए सामान्य त्रुटियां
यहां तक कि अनुभवी वास्तुकार भी गलतियां करते हैं। डिप्लॉयमेंट से पहले अपने चित्र को इन सामान्य समस्याओं के खिलाफ समीक्षा करें।
- लॉग में संवेदनशील डेटा संग्रहित करना: सुनिश्चित करें कि ऑडिट लॉग टेबल गलती से पासवर्ड या क्रेडिट कार्ड नंबर को कैप्चर न करे। लॉग एंट्री में पीआईआई को मास्क करें।
- अत्यधिक इंडेक्सिंग: प्रत्येक इंडेक्स लेखन ऑपरेशन को धीमा कर देता है। केवल उन कॉलम को इंडेक्स करें जो नियमित रूप से WHERE क्लॉज या जॉइन में उपयोग किए जाते हैं।
- समय क्षेत्रों को नजरअंदाज करना: सभी समयचिह्न को यूटीसी में स्टोर करें। स्थानीय समय में बदलना केवल प्रस्तुति परत पर करें। इससे दिन के बदलाव के दौरान समस्याओं से बचा जा सकता है।
- कड़े मान: एप्लीकेशन कोड में भूमिका नाम या स्थिति मान को कड़े रूप से न लिखें। उन्हें डेटाबेस में संख्यात्मक या लुकअप टेबल के रूप में परिभाषित करें।
✅ अंतिम सत्यापन चेकलिस्ट
एरडी को पूरा मानने से पहले, तैयारी सुनिश्चित करने के लिए इस चेकलिस्ट को चलाएं।
- क्या सभी प्राथमिक कुंजियां UUIDs या स्वतः बढ़ते पूर्णांक हैं?
- क्या सभी विदेशी कुंजियां इंडेक्स की गई हैं?
- ईमेल पते या उपयोगकर्ता नाम पर एकमात्र सीमा है?
- क्या समय टैग UTC में संग्रहीत हैं?
- क्या नरम हटाने के लिए कोई तंत्र है?
- क्या संवेदनशील डेटा पहचान डेटा से अलग है?
- क्या सामान्य प्रश्न पैटर्न के लिए इंडेक्स हैं?
- क्या स्कीमा कम से कम 3NF तक सामान्यीकृत है?
- क्या डिज़ाइन आवश्यक सुरक्षा सुसंगतता मानकों का समर्थन करता है?
इन बिंदुओं की विस्तृत समीक्षा सुनिश्चित करती है कि आपकी उपयोगकर्ता प्रबंधन सेवा का आधार मजबूत है। डिज़ाइन चरण में निवेश की गई मेहनत एप्लिकेशन के जीवनचक्र के दौरान रखरखाव, सुरक्षा और प्रदर्शन में लाभ देती है।
📝 स्कीमा घटकों का सारांश
डिज़ाइन तत्वों को संगठित करने के लिए, यहां उच्च गुणवत्ता वाले उपयोगकर्ता प्रबंधन डेटाबेस के लिए आवश्यक मुख्य घटकों का सारांश है।
| घटक | मुख्य फ़ील्ड | सीमा |
|---|---|---|
| उपयोगकर्ता | आईडी, स्थिति, बनाए गए का समय | मुख्य कुंजी, एकल स्थिति |
| प्रमाणपत्र | उपयोगकर्ता आईडी, हैश, नमक, आखिरी रीसेट | विदेशी कुंजी, खाली नहीं |
| भूमिकाएं | आईडी, नाम, विवरण | मुख्य कुंजी, एकल नाम |
| उपयोगकर्ता_भूमिकाएं | उपयोगकर्ता आईडी, भूमिका आईडी | मिश्रित मुख्य कुंजी |
| सुरक्षा लॉग | आईडी, उपयोगकर्ता आईडी, क्रिया, समय टैग | विदेशी कुंजी, उपयोगकर्ता पर सूचकांक |
इन दिशानिर्देशों और संरचनात्मक पैटर्नों का पालन करके, आप एक विश्वसनीय प्रणाली स्थापित करते हैं जो जटिल उपयोगकर्ता बातचीत को सुरक्षित ढंग से संभाल सकती है। परिणामस्वरूप एरडी डेटा और एप्लिकेशन के बीच एक अनुबंध के रूप में कार्य करता है, जिससे आपकी सेवा बढ़ने के साथ स्थिरता सुनिश्चित होती है।

