








Les données constituent le pilier de chaque système numérique, des applications web simples aux plateformes complexes de planification des ressources d’entreprise. Sans une approche structurée pour organiser ces informations, les systèmes deviennent fragiles, lents et difficiles à maintenir. C’est là que le diagramme Entité-Relation, communément appelé ERD, devient essentiel. Il sert de carte fondamentale pour la conception des bases de données, traduisant les exigences métiers abstraites en une structure technique concrète.
Ce guide explore les mécanismes de modélisation ER, les règles régissant l’intégrité des données, et les stratégies nécessaires pour construire des architectures évolutives. En comprenant les principes fondamentaux des entités, des relations et de la normalisation, les architectes peuvent garantir que leurs couches de données restent robustes et efficaces au fil du temps.
🔍 Qu’est-ce qu’un diagramme Entité-Relation ?
Un diagramme Entité-Relation est une représentation visuelle des structures de données et des relations entre elles. C’est un outil conceptuel utilisé pendant la phase de conception du développement d’une base de données. Plutôt que de se concentrer sur les mécanismes de stockage physique, tels que les blocs disque ou les adresses mémoire, l’ERD se concentre sur l’organisation logique des données.
Pensez-y comme un plan architectural pour une maison. Avant de verser du béton ou de poser des briques, un architecte dessine un plan montrant où vont les murs, où les portes relient les pièces, et comment les services circulent. De même, un ERD montre où les données vivent, comment elles sont connectées et comment elles circulent à travers l’application.
Objectifs principaux de la modélisation ER
- Communication : Il comble l’écart entre les équipes techniques et les parties prenantes métiers. Les diagrammes visuels sont plus faciles à comprendre que du code brut ou des scripts SQL.
- Planification : Il identifie les problèmes potentiels avant le début de la mise en œuvre. Les défauts de conception sont moins coûteux à corriger sur papier qu’en production.
- Documentation : Il sert de référence pour les développeurs futurs, expliquant comment les données sont structurées et liées.
- Optimisation : Il met en évidence les redondances et les inefficacités pouvant entraîner des performances de requêtes plus lentes.
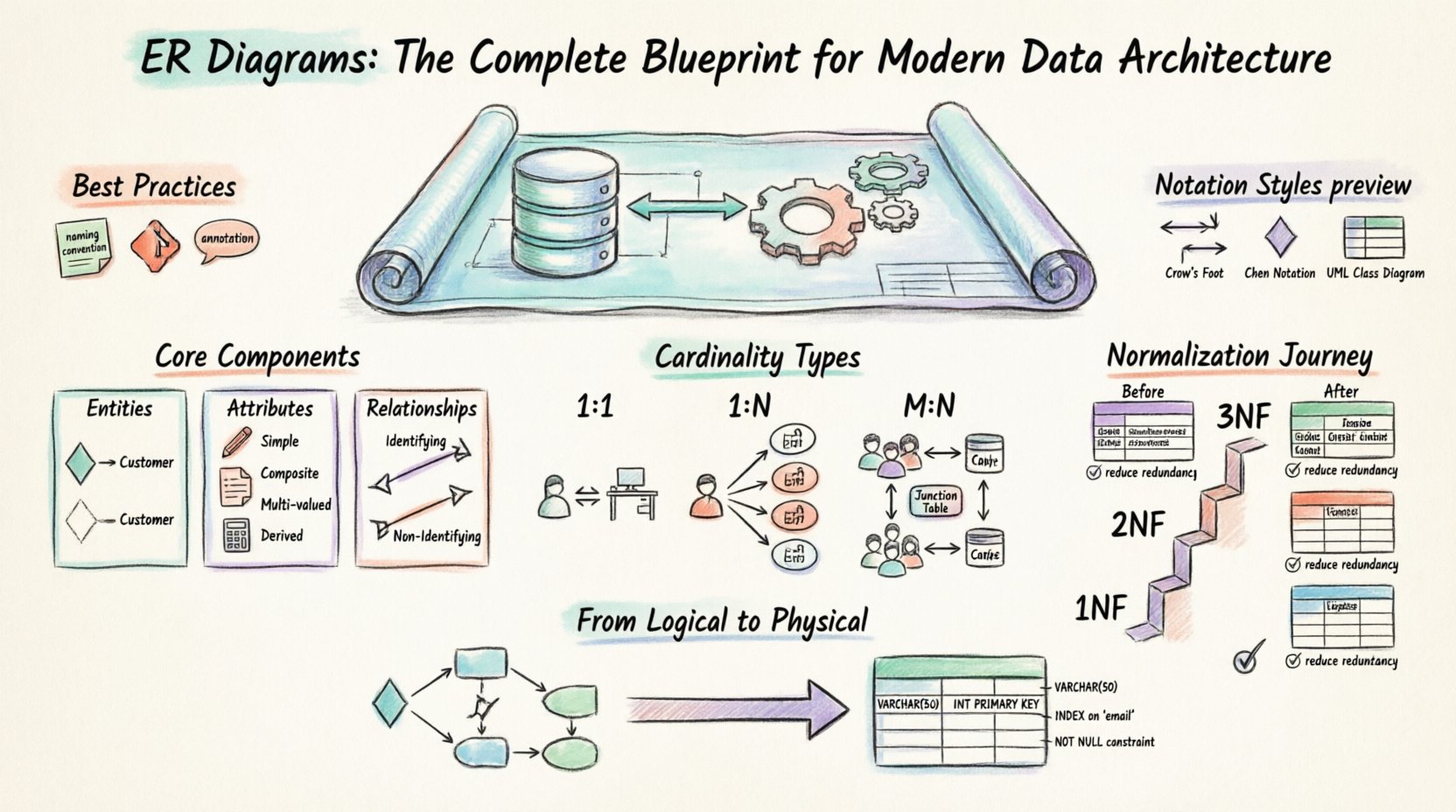
🏗️ Composants fondamentaux d’un ERD
Pour construire un diagramme valide, il faut comprendre les trois blocs de construction fondamentaux. Toute relation et contrainte dans une base de données découle de l’interaction de ces éléments.
1. Entités
Une entité représente un objet ou un concept distinct au sein du domaine métier. Dans un contexte de base de données, une entité correspond généralement à une table. Les entités peuvent être :
- Entités fortes : Elles existent indépendamment et possèdent leur propre clé primaire. Par exemple, une entité Client existe même sans une entité associée Commande.
- Entités faibles : Elles dépendent d’une entité forte pour exister. Une entité Ligne_Commande ne peut exister sans une entité parente Commande.
Les entités sont généralement représentées par des rectangles dans la notation standard. Elles sont nommées à l’aide de noms communs au singulier pour représenter la classe d’objets.
2. Attributs
Les attributs décrivent les propriétés ou caractéristiques d’une entité. Ce sont les colonnes au sein d’une table. Les attributs se divisent en plusieurs catégories :
- Attributs simples : Des valeurs indivisibles, telles qu’une Prénom ou Âge.
- Attributs composés : Des attributs pouvant être divisés en parties sous-jacentes, tels qu’une Adresse (Rue, Ville, Code postal).
- Attributs multivalués : Des attributs pouvant contenir plusieurs valeurs, tels que Numéros_de_téléphone ou Compétences.
- Attributs dérivés : Des valeurs calculées à partir d’autres attributs, telles que Âge dérivé de Date_de_naissance.
Le plus important attribut est le Clé primaire. Cet identifiant unique permet de distinguer un enregistrement d’un autre au sein d’une entité. Sans clé primaire, l’intégrité des données ne peut être garantie.
3. Relations
Les relations définissent la manière dont les entités interagissent entre elles. Elles indiquent les contraintes et les associations entre les points de données. Les relations sont le tissu conjonctif de la base de données.
- Relations identifiantes :Une entité faible dépend d’une entité forte. La relation détermine l’existence de l’entité faible.
- Relations non identifiantes :Les entités sont indépendantes. La relation existe, mais ne détermine pas l’existence.
🔗 Comprendre la cardinalité et la modalité
La cardinalité définit le nombre d’instances d’une entité qui peuvent ou doivent s’associer à chaque instance d’une autre entité. Cela est souvent appelé la structure « un à un », « un à plusieurs » ou « plusieurs à plusieurs ».
La modalité fait référence au fait que la relation est obligatoire ou facultative. Un enregistrement doitavoir un enregistrement associé, ou est-il autorisé à exister sans en avoir ?
Types de cardinalité
| Cardinalité | Notation | Scénario d’exemple |
|---|---|---|
| Un à un (1:1) | Un ─── Un | Un employé possède un bureau |
| Un à plusieurs (1:N) | Un ─── Plusieurs | Un client passe plusieurs commandes |
| Plusieurs à plusieurs (M:N) | Plusieurs ─── Plusieurs | Plusieurs étudiants s’inscrivent à plusieurs cours |
Les relations plusieurs à plusieurs sont particulièrement importantes à noter. Dans une base de données physique, un lien direct plusieurs à plusieurs n’est pas pris en charge. Il doit être résolu en introduisant une entité associative (une table de jonction) qui divise la relation en deux relations un à plusieurs.
⚖️ Principes de normalisation
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité des données. Elle consiste à diviser les grandes tables en tables plus petites, logiquement connectées, et à définir des relations entre elles. L’objectif est de s’assurer que chaque morceau de données est stocké à un seul endroit.
Première forme normale (1NF)
La première étape de la normalisation consiste à s’assurer que :
- Toutes les valeurs de colonne sont atomiques (indivisibles).
- Il n’y a pas de groupes répétés ou de tableaux dans une seule colonne.
- Chaque colonne ne contient qu’une seule valeur par ligne.
Par exemple, une Compétences colonne contenant « Java, SQL, Python » viole la 1NF. Elle devrait être divisée en lignes distinctes ou dans une table distincte.
Deuxième forme normale (2NF)
Une table est en 2NF si elle est en 1NF et que toutes les attributs non clés dépendent entièrement de la clé primaire. Cela élimine les dépendances partielles. Si une table possède une clé primaire composée, chaque colonne non clé doit dépendre de toute la clé, et non seulement d’une partie.
Troisième forme normale (3NF)
Une table est en 3NF si elle est en 2NF et qu’il n’y a pas de dépendances transitives. Cela signifie que les attributs non clés ne doivent pas dépendre d’autres attributs non clés. Par exemple, si Ville dépend de Code postal, et Code postal dépend de ID_Client, stocker Ville dans la table Client table crée une redondance. Il est préférable d’avoir une table distincte pour le Code postal table.
📐 Normes de notation
Différentes notations existent pour représenter les modèles entité-relations. Bien que la logique sous-jacente reste la même, les symboles visuels varient. Choisir une norme garantit la cohérence dans la documentation.
- Pied de corbeau : La notation la plus courante dans la conception moderne des bases de données. Elle utilise des lignes avec des extrémités spécifiques (comme le pied d’un oiseau) pour indiquer la cardinalité. Elle est intuitive et largement prise en charge par les outils de conception.
- Chen : Une notation plus ancienne où les relations sont des losanges et les entités des rectangles. Elle est très explicite quant à la nature de la relation, mais peut devenir encombrée dans les modèles complexes.
- UML : Langage unifié de modélisation. Souvent utilisé en génie logiciel, il adapte les concepts des entités-relations pour s’intégrer dans le cadre plus large de l’UML pour la conception de systèmes.
🔄 Du modèle logique au modèle physique
Le parcours allant d’un schéma abstrait à une base de données fonctionnelle implique le passage des modèles logiques aux modèles physiques.
Modèle de données logique
Ce modèle se concentre sur la structure des données sans tenir compte du système de gestion de base de données spécifique. Il définit les entités, les attributs et les relations à l’aide de termes génériques. Il est indépendant de la technologie. Cette étape répond à la question : « Quels données avons-nous besoin et comment sont-ils liés ? »
Modèle de données physique
Ce modèle traduit la conception logique dans les spécificités d’un système de base de données. Il définit les types de données (par exemple, Entier, Varchar, Timestamp), les index, les contraintes et les stratégies de partitionnement. Il répond à la question : « Comment stocker cela de manière efficace ? »
Pendant cette transition, des décisions spécifiques sont prises :
- Types de données : Décider entre
INTouBIGINTen fonction du volume prévu. - Index : Ajout d’index sur les colonnes fréquemment utilisées dans les conditions de recherche afin d’accélérer la récupération.
- Contraintes : Appliquer
NOT NULLdes règles ouUNIQUEdes contraintes au niveau de la base de données. - Conventions de nommage : Adopter une norme comme
snake_casepour les tables et les colonnes afin d’assurer la lisibilité.
🛡️ Défis courants dans la modélisation des données
Même les architectes expérimentés rencontrent des obstacles lors de la conception des diagrammes entité-association. Reconnaître ces défis tôt peut éviter des reprises coûteuses.
1. Ambiguïté des règles métiers
Les parties prenantes décrivent souvent les besoins en données de manière vague. « Nous devons suivre les utilisateurs » pourrait signifier une simple liste ou un système complexe avec des rôles, des permissions et des journaux d’audit. Une communication claire est essentielle pour résoudre ces ambiguïtés avant de tracer des lignes sur le schéma.
2. Sur-normalisation
Bien que la normalisation réduise la redondance, une normalisation excessive peut fragmenter les données sur trop de tables. Cela entraîne des jointures complexes qui ralentissent les performances des requêtes. Un équilibre doit être trouvé entre l’intégrité des données et les performances de lecture.
3. Ignorer la croissance future
Les conceptions se concentrent souvent sur les exigences actuelles. Toutefois, les modèles de données doivent prévoir les évolutions futures. Une table conçue pour un seul numéro de téléphone doit prévoir plusieurs numéros ou des formats internationaux.
4. Relations manquantes
Il est fréquent de définir des entités sans les relier. Une Produit table sans lien avec une Catégorie table rend la catégorisation impossible. Chaque entité doit être revue pour s’assurer qu’elle est logiquement connectée au reste du schéma.
📋 Meilleures pratiques pour la documentation
Un schéma n’est utile que s’il est compris. La documentation complète le modèle visuel.
- Nommage cohérent : Utilisez des noms clairs et descriptifs. Évitez les abréviations sauf si elles sont des normes de l’industrie.
- Contrôle de version : Traitez le schéma comme du code. Suivez les modifications du MCD au fil du temps pour comprendre l’évolution du système.
- Annotations : Ajoutez des notes au schéma pour expliquer la logique métier complexe ou les exceptions qui ne peuvent pas être représentées visuellement.
- Cycles de revue : Revoyez régulièrement le modèle avec des membres techniques et non techniques de l’équipe pour assurer une cohérence.
🚀 Le rôle du MCD dans les systèmes modernes
Dans le paysage de l’architecture des données modernes, les principes de modélisation relationnelle restent pertinents malgré l’essor des bases de données NoSQL et graphes. Bien que les mécanismes de stockage évoluent, la nécessité de comprendre les relations et l’intégrité des données ne disparaît pas.
Pour les systèmes basés sur SQL, le MCD est l’élément de conception principal. Pour les systèmes NoSQL, il informe la structure des documents et les stratégies d’incorporation. Pour les bases de données graphes, il définit explicitement les nœuds et les arêtes.
La modélisation des données n’est pas une tâche ponctuelle. À mesure que les exigences métiers évoluent, le MCD doit évoluer avec elles. Ce processus itératif garantit que le niveau de données reste un atout stratégique plutôt qu’une charge technique.
✅ Résumé des points clés
- Fondation :Les MCD sont le plan directeur pour la conception des bases de données, garantissant une cohérence logique.
- Composants :Les entités, les attributs et les relations forment le trio fondamental de tout modèle.
- Cardinalité :Comprendre les relations 1:1, 1:N et M:N est essentiel pour une cartographie des données précise.
- Normalisation : Appliquez la 1NF, la 2NF et la 3NF pour réduire la redondance et assurer l’intégrité.
- Évolution : Passez des modèles logiques aux modèles physiques pour vous préparer à l’implémentation.
- Documentation : Maintenez des conventions de nommage claires et un contrôle de version pour une maintenance à long terme.
En suivant ces principes, les architectes conçoivent des systèmes qui sont non seulement fonctionnels aujourd’hui, mais aussi adaptables pour demain. Le diagramme ER est bien plus qu’un dessin ; c’est un contrat entre la logique métier et la mise en œuvre technique.

