










データは、あらゆる現代の情報システムの基盤を成す。しかし、構造のないデータは単なるノイズにすぎない。原始的な情報を実行可能な知性に変換するためには、構造化されたデータモデルに依存する。エンティティ関係図(ERD)は、こうした構造の建築図として機能する。抽象的なビジネス要件と具体的な技術的実装の間のギャップを埋める役割を果たす。このガイドでは、データモデリングのメカニズムに焦点を当て、運用論理をスキーマ定義に正確に変換する方法を解説する。
🏗️ コアコンポーネントの理解
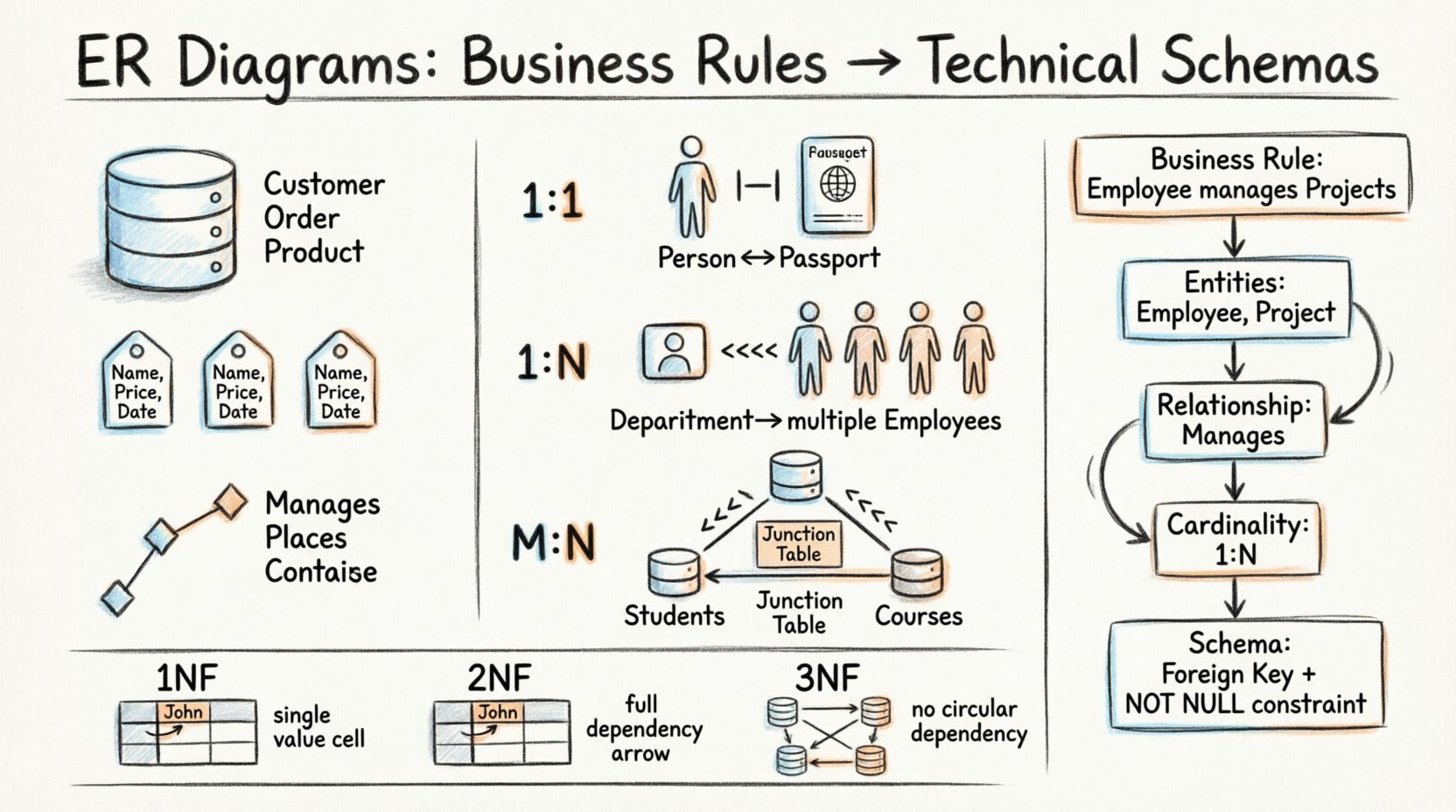
ER図は、三つの基本的な構成要素で構成される。各構成要素は、データの格納および関連付け方の特定の側面を表す。これらのコンポーネントを習得することで、組織のニーズに合致した堅牢なデータベースの構築が可能になる。
- エンティティ: これらは、データが収集される対象や概念を表す。ビジネスの文脈では、これらは「顧客, 注文」や「製品」など、名詞として現れることが多い。スキーマでは、エンティティはテーブルになる。
- 属性: これらはエンティティの特性を記述する。例として「名前, 価格」や「日付」などがある。属性は、対応するテーブル内の列になる。
- 関係: これらはエンティティ間の関連を定義する。関係は、あるエンティティのインスタンスが別のエンティティのインスタンスとどのように結びついているかを示す。データベースでは、関係はしばしばキーによって強制される。
🔄 ビジネスルールをスキーマ要素に変換する
データモデリングにおいて最も重要なステップは、変換フェーズである。ビジネス関係者はプロセスやポリシーの観点で話す。エンジニアはテーブルや制約の観点で話す。モデラーは、この二つの言語の間の通訳者として機能しなければならない。
次のビジネスルールを考えてみよう:「1人の従業員が複数のプロジェクトを管理できるが、プロジェクトには少なくとも1人のマネージャーが必須である。」このルールは、どのようにスキーマになるのか?
- エンティティを特定する: 従業員 および プロジェクト.
- 関係を特定する: 管理する.
- 基数を定義する:1人の従業員が複数のプロジェクトを管理する(1:N)。1つのプロジェクトは少なくとも1人の従業員に紐づく(解釈により1:1または1:N)。
- オプショナリティを強制する: プロジェクト はマネージャーを持たなければならない。これは外部キーにNOT NULL制約を課すことになる。
このプロセスでは、ビジネスユーザーが提供する自然言語を慎重に分析する必要がある。曖昧さはデータ整合性の敵である。ルールが「顧客は注文を出すことができる」と述べている場合、それは顧客が注文をゼロ件も可能であることを意味するのか、それとも最低1件は注文しなければならないのか。この違いは外部キーの実装に影響する。「顧客は注文を出すことができる」、それは彼らがはゼロ件の注文を出すことができるのか、それとも最低1件は注文しなければならないのか。この違いは外部キーの実装を変える。
📏 基数とオプショナリティ
基数は、あるエンティティのインスタンスが、別のエンティティの各インスタンスと関連付けられる数(可能または必須)を定義する。これは関係の数学的基盤である。
1対1(1:1)
1つのテーブルの1つのレコードが、別のテーブルの正確に1つのレコードと関連する場合に発生する。セキュリティやパフォーマンスの理由でテーブルを分割する場合に一般的だが、一般的なビジネス論理ではそれほど頻繁ではない。
- 例: 1人の人物は1つのパスポートを持つ。1つのパスポートは1人の人物に属する。
- 実装: どちらかのテーブルに外部キーを設け、もう一方のテーブルの主キーを参照する。
1対多(1:N)
これはリレーショナルデータベースで最も一般的な関係タイプである。Table Aの1つのレコードが、Table Bの複数のレコードに関連する。Table Bが外部キーを保持する。
- 例: 部門には多くの従業員がいる。従業員は1つの部門に所属する。
- 実装: の 従業員 テーブルには 部門ID 列があります。
多対多(M:N)
テーブルAの2つのレコードがテーブルBの複数のレコードに関連し、その逆も成り立つ。この関係を標準的なリレーショナルスキーマで直接実装することは、中間ステップを経ない限り不可能である。
- 例: 学生が授業に登録する。1人の学生は複数の授業を受ける。1つの授業には複数の学生がいる。
- 実装: 親テーブル双方の外部キーを含む結合テーブル(関連エンティティ)を作成する。
| 関係の種類 | 視覚的表記(概念) | スキーマの実装 | 一般的な使用例 |
|---|---|---|---|
| 1対1(1:1) | |—| | いずれかのテーブルに外部キー | 個人 ↔ パスポート |
| 1対多(1:N) | |—<<< | 「多」側のテーブルに外部キー | 部門 ↔ 従業員 |
| 多対多(M:N) | <<<—<<< | 2つの外部キーを持つ結合テーブル | 学生 ↔ 授業 |
🧩 正規化の原則
エンティティと関係が定義されると、スキーマは正規化されなければならない。正規化とは、データの冗長性を減らし、データの整合性を向上させるためにデータを体系的に整理するプロセスである。これは、テーブルをより小さく、良好に構造化されたコンポーネントに分解することを含む。
第一正規形(1NF)
すべての列には原子的な値が含まれている必要があります。1つのセル内に繰り返しグループや配列があってはなりません。各行は一意でなければなりません。
- 違反: A スキル 列に含まれる 「SQL、Python、Java」 1つのセル内に。
- 修正: スキルを関係によってリンクされた別々のテーブルに分割する。
第二正規形(2NF)
テーブルは1NFにあり、すべての非キー属性は主キーに完全に依存しなければなりません。これにより部分的依存が排除されます。
- シナリオ: 組み合わせたテーブル 注文 と 注文項目 ここで 製品名 はただちに 項目ID に依存し、注文ID.
- 修正: 移動する 製品名 を 項目 テーブルに。
第三正規形 (3NF)
テーブルは2NFにないといけないし、推移的依存関係があってはならない。非キー属性は他の非キー属性に依存してはならない。
- シナリオ: A 顧客 テーブルには 都市 と 国 があり、国 は 都市.
- 修正: 場所 テーブルを作成して都市と国データを保持する。
🛡️ 制約と整合性の管理
スキーマの質は、それを守るルールの質に依存する。制約は、データが時間の経過とともに正確かつ一貫性を保つことを保証する。
主キー
すべてのテーブルには一意の識別子が必要である。これにより、2つの行が同一になることを防ぎ、正確な検索が可能になる。多くのシステムでは、自動増分整数が使用される。他のシステムでは、UUIDや自然キーが使用されることがある。
外部キー
外部キーは参照整合性を維持する。子テーブルのレコードが親テーブルに対応するレコードが存在しない状態で存在することは保証されない。これにより、孤立データを防ぐ。
- 削除時に連鎖処理: 親が削除されると、子も自動的に削除される。
- 削除を制限: 子が存在する場合、親の削除を防ぐ。
- 削除時にNULL設定: 親を削除するが、子レコードは外部キーがNULLのまま残す。
チェック制約
これらはデータベース内に直接、特定のビジネスロジックを強制します。例として、価格がゼロより大きいこと、または開始日が終了日.
⚠️ データモデリングにおける一般的な落とし穴
経験豊富なアーキテクトですら、重要な詳細を見落とすことがあります。一般的なミスに気づいておくことで、より強靭なシステム設計が可能になります。
- 過剰な正規化:テーブルをあまりにも積極的に分割すると、クエリのパフォーマンスを低下させる複雑な結合が発生する可能性があります。読み込みが重いワークロードでは、非正規化を許容する場合もあります。
- ソフトデリートを無視する:ビジネスルールでは、履歴データを保持する必要があることがよくあります。レコードを永続的に削除すると、監査ログが失われます。IsDeletedフラグを設けることがしばしば必要です。
- 一意性を前提とする:ビジネスルールが一意性を示唆しているからといって(例としてメールアドレス)データベースがそれを強制するとは限りません。一意制約は明示的に定義する必要があります。
- 時間要素を無視する:ほとんどのビジネスデータには時間的な側面があります。レコードがいつ作成または更新されたかを記録することは、監査やデバッグにおいて不可欠です。いつを記録することは、監査やデバッグにおいて不可欠です。
- 値をハードコードする:SQLクエリで特定の値を使用し、参照テーブルを使わないことで、システムが硬直化し、保守が難しくなります。
🔄 反復的な設計プロセス
データモデリングはほとんど線形的なプロセスではありません。反復的です。初期の図は、実際の使用パターンやフィードバックに基づいて検証しなければならない仮説です。
- 概念設計:高レベルのエンティティと関係性に注目する。データ型のような技術的詳細は無視する。
- 論理設計:属性を追加し、データ型を定義し、キーを設定する。構造を正規化する。
- 物理設計:特定のデータベースエンジンに最適化する。インデックス戦略、パーティショニング、ストレージを検討する。
- レビュー:ステークホルダーとモデルを検証する。将来のビジネス成長をサポートしていることを確認する。
レビュー段階では、関係性が誤解されていたことがよくある。例えば、多対多関係は、実際には階層構造または一対多関係の連鎖であることが判明することがある。設計段階での柔軟性は、実装段階での膨大な作業を節約する。
📈 スケーリングと進化
スキーマは進化する。要件は変化する。今日適しているものが、明日も適しているとは限らない。良好に設計されたER図は成長を予見する。
- 拡張性:特定の機能をスキーマにハードコードしない。非常に動的な要件に対しては、汎用テーブルや属性パターン(EAVなど)を適切に使用する。
- バージョン管理:スキーマの変更を追跡する。マイグレーションスクリプトはアプリケーションコードと同様にバージョン管理する。
- ドキュメント化:図はドキュメントである。図とデータベースが一致しない場合は、データベースを信頼し、図を直ちに更新する。
🔍 構造的整合性に関する結論
データベーススキーマの品質は、それを依存とするアプリケーションの信頼性に直接影響する。ER図は単なる図面以上のものであり、ビジネスロジックと技術的インフラの間の契約である。ビジネスルールを技術的スキーマに厳密にマッピングし、適切な正規化を確保し、厳格な整合性制約を維持することで、耐障害性と効率性を兼ね備えたシステムを構築する。
図の明確さに注力する。標準的な表記法を使用して、どのエンジニアも設計を読み取れるようにする。後で整合性の問題を修正するコストは、早期にクエリ最適化を行うよりもはるかに高くなるため、短期的なパフォーマンス向上よりもデータ整合性を優先する。目標は、現在のビジネスを支え、将来の変化にも対応できるスキーマを構築することである。

