











エンティティ関係図(ERD)は、一部の人々によって学術的な演習や文書化のためだけに作られたアーティファクトとして軽視されることがある。しかし、シニア開発者やアーキテクトにとっては、ER図はアプリケーションのデータ層の安定性、パフォーマンス、保守性を規定する戦略的な設計図である。課題は箱と線を描くことではなく、理論的なデータモデリングと生産環境の複雑な制約との間の摩擦をどう乗り越えるかにある。
システムを構築する際、常に妥協を余儀なくされる。完全に正規化されたスキーマはデータ整合性を保証するが、複雑なクエリではパフォーマンスの低下を招く可能性がある。逆に、非正規化された構造は読み取りを高速化するが、冗長性と更新異常を生じる。目標は、図がビジネスドメインを正確に反映しつつ、デプロイ時に負債にならないバランスを見つけることである。
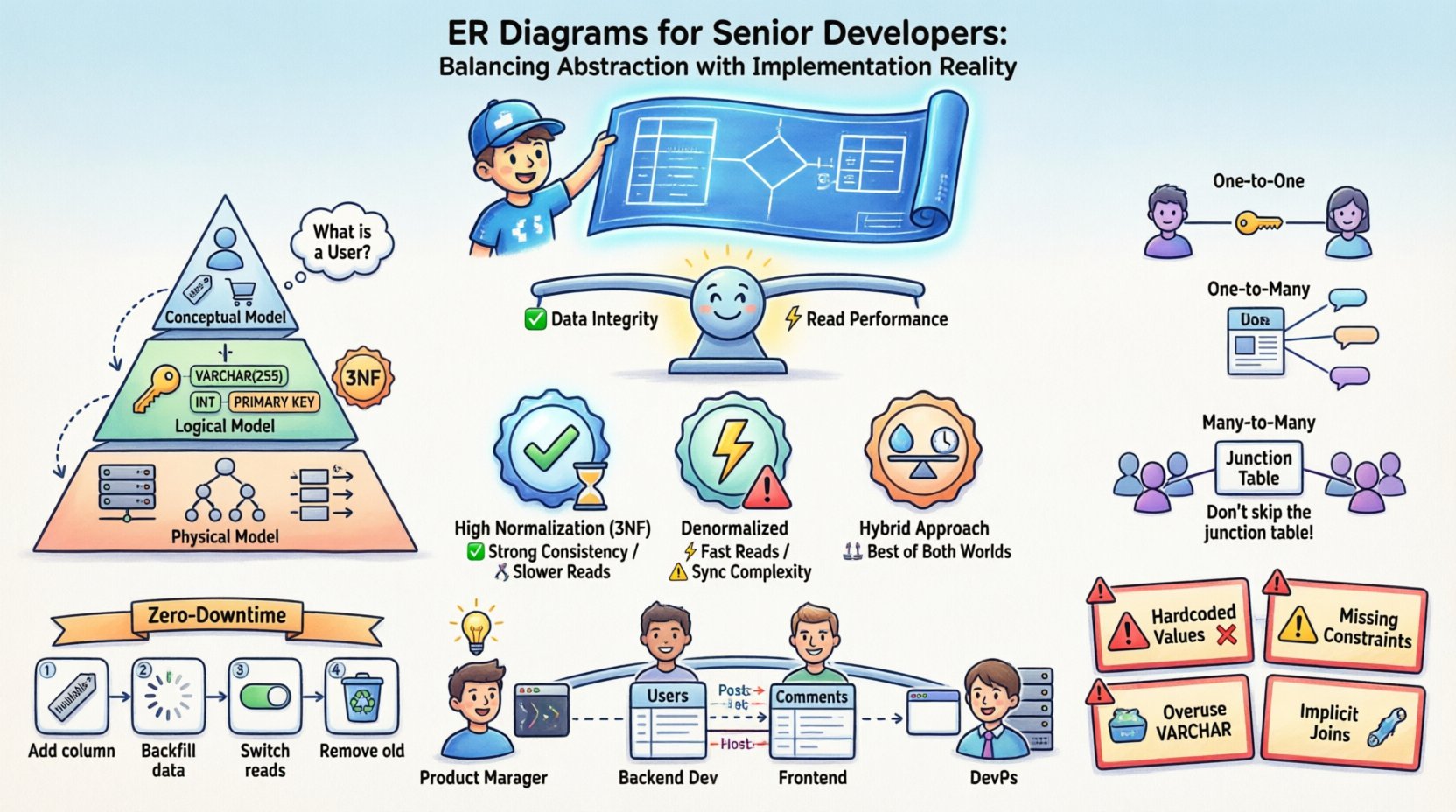
エンティティ関係図の二重性 📐
ER図のライフサイクルを理解するには、それが複数の目的に応じて使われていることを認識することが必要である。それは静的な画像ではなく、ソフトウェアと共に進化する動的な文書である。データが「」のようになるべきか、それとも「」のようになるかという混乱を避けるため、三つの明確な抽象化の段階を別々に管理しなければならない。すべきのように見えるべきか、そしてそれが実際にメモリ上にどのように見えるかを区別する必要がある。
- 概念モデル: この段階では、技術的な詳細を無視してビジネス上のエンティティとその関係性に注目する。例えば「ユーザーとは何か?」や「ユーザーは注文とどのように関係しているか?」といった問いに答える。これは技術に依存しない。
- 論理モデル: ここでは、データ型、キー、正規化ルールを導入する。主キーと外部キーを定義するが、まだ特定のデータベースエンジンのストレージエンジンやインデックス戦略に拘束するわけではない。
- 物理モデル: これは実装の現実である。テーブル名、カラムのデータ型、パーティショニング戦略、インデックス、ターゲットデータベースシステムに特有の制約を含む。ここが実際に動く場所である。
これらの段階が混同されると混乱が生じる。シニア開発者は、バグが物理モデルに隠れていることを知っている。「多対多」の概念的な関係は、物理モデルでは特定の外部キー制約に解決され、元のビジネスロジックには存在しないジョインテーブルを必要とする場合が多い。
データモデリングにおける抽象化の段階 🧩
これらの段階を管理するには、自制心が必要である。ステークホルダーが機能を要請すると、彼らはビジネス用語で説明する。開発者はそれを論理スキーマに、最終的に物理スキーマに変換しなければならない。ステップを飛ばすと技術的負債が生じる。
1. 概念モデリング:ビジネス言語
この段階では、図はコミュニケーションツールである。エンジニアリングチームとプロダクトチームがドメインモデルについて合意できることを保証する。図が「顧客」が複数の「住所」を持つことを示しているなら、SQLの1行も書かれる前に、全員がその事実に合意している。
2. 論理モデリング:エンゲージメントのルール
ここでは正規化ルールを適用する。その住所が頻繁に変更され、他のエンティティに属する可能性がある場合、「顧客」が「住所」を直接格納すべきでないと判断する。冗長性を減らすために正規化を導入する。同時に、読み取りが重いデータを特定し、後で非正規化が必要になる可能性があることも把握する。
3. 物理モデリング:実装の現実
ここではデータベースエンジンの制限が影響する。柔軟な属性に対して、JSONカラムと別々のリレーショナルテーブルのどちらを選ぶかを検討する必要がある。クエリパターンに基づいてインデックス戦略を決定する。書き込みが高速だが読み取りが遅い特定のストレージエンジンを使用することも検討する。
正規化戦略とパフォーマンスのトレードオフ ⚖️
正規化はデータベース設計の基本的な概念である。データの冗長性を減らし、データ整合性を高めるためにデータを整理する。しかし、大規模システムでは、正規化ルールへの厳格な従いがボトルネックになることがある。シニア開発者は、いつルールを破るべきかを理解しなければならない。
正規化のコスト
データを正規化すると、多くのテーブルが作成されることが多い。つまり、クエリ時により多くの結合が必要になる。分散システムや高トラフィックのウェブアプリケーションでは、1つの結合も潜在的な遅延ポイントとなる。テーブルがパーティショニングされている場合、パーティション間の結合は高コストになることがある。
非正規化すべきタイミング
非正規化とは、読み取りパフォーマンスを最適化するために意図的に冗長性を導入することである。これはミスではなく、戦略的な意思決定である。以下の状況では非正規化を検討すべきである:
- 読み取り操作は書き込み操作をはるかに上回っています。
- 複雑な結合がタイムアウトや高CPU使用率を引き起こしています。
- リアルタイムの一貫性がそれほど重要でないレポート作成または分析レイヤーを構築しています。
- データベースの負荷を減らすために、キャッシュレイヤー用にデータを正規化解除する必要があります。
正規化対パフォーマンスマトリクス
| 戦略 | データ整合性 | 書き込みパフォーマンス | 読み取りパフォーマンス | 保守性 |
|---|---|---|---|---|
| 高正規化(3NF) | 高い | 高速(冗長性が少ない) | 遅い(結合が必要) | 高い(更新が容易) |
| 非正規化 | 低い(手動同期が必要) | 遅い(書き込むデータが多い) | 高速(結合が少ない) | 低い(整合性のリスク) |
| ハイブリッドアプローチ | 中程度 | 中程度 | 中程度から高速 | 中程度(明確な論理が必要) |
このマトリクスを理解することで、情報に基づいた意思決定が可能になります。すべてを正規化する、またはすべてを非正規化するという単純な選択はできません。アプリケーションの特定のアクセスパターンを分析する必要があります。
複雑な関係のモデリング 🔗
関係はER図の核です。データエンティティがどのように相互作用するかを定義します。1対1や1対多は直感的ですが、多対多の関係はスケーラビリティを確保するために注意深く扱う必要があります。
1対1の関係
実際には稀ですが存在します。たとえば、ユーザーのプロフィールとユーザーのプロフィール設定のテーブルです。1つのテーブルに外部キーを配置するか、データを2つのテーブルに分割することで実装できます。決定はアクセスパターンに依存します。設定をプロフィールと一緒に頻繁にアクセスする場合は、一緒に保持します。アクセス頻度が低い場合は、メインテーブルのサイズを小さくするために分離します。
1対多の関係
これは最も一般的なパターンです。ブログ投稿には複数のコメントが関連付けられます。外部キーは「多数」側(コメント)に配置されます。特定の投稿のすべてのコメントを取得するクエリにおいて、効率的です。
多対多の関係
ユーザーは複数のユーザーをフォローでき、複数のユーザーにフォローされることもできます。これには中間の結合テーブルが必要です。このテーブルは通常、両方の側の外部キーに加えて、関係に特有のメタデータ(たとえば、接続が行われた時刻など)を保持します。
- 結合テーブルをスキップしないでください: これにより、関係をインデックス化し、効率的にクエリを実行できます。
- 複合キーを検討してください: 結合テーブルの主キーは、2つの外部キーの組み合わせである可能性があります。
- 基数を確認してください: 関係がオプションか必須かの状況を適切に処理していることを確認してください。
スキーマの進化とマイグレーション 🔄
シニア開発者としての最も難しい点の一つは、ER図が永遠に完成しないことに気づくことです。要件は変化し、ビジネスロジックが移行し、データは増大します。既存の機能を壊さずに、スキーマを進化させなければならないのです。
スキーマのバージョン管理
マイグレーションは一度限りのイベントだと仮定してはいけません。スキーマをコードのように扱いましょう。マイグレーションスクリプトにはバージョン管理を使用してください。新しいカラムが問題を引き起こした場合、変更をロールバックできるようになります。また、データ構造が時間とともにどのように変化したかの監査ログも得られます。
ダウンタイムゼロのマイグレーション
本番システムでは、ダウンタイムはしばしば許されません。これには、スキーマ変更を段階的に進めるアプローチが必要です:
- まずカラムを追加します:新しいカラムをnullableとして追加します。それを書き込むコードをデプロイします。
- データをバックフィルします:バックグラウンドジョブを実行して、新しいカラムにデータを埋め込みます。
- 読み取りを切り替えます:アプリケーションを更新して、新しいカラムから読み取るようにします。
- 古いカラムを削除します: システムが安定したら、古いカラムを削除します。
ロックの処理
大規模なテーブルにインデックスや制約を追加すると、テーブルがロックされ、書き込みが停止する可能性があります。ロック時間の最小化のために、オンラインスキーマ変更ツールやパーティショニング戦略を使用する必要があります。ここでは、基盤となるデータベースエンジンのロックメカニズムを理解することが不可欠です。
本番環境における一般的な落とし穴 🚧
経験豊富な開発者でさえ、ERDをSQLに変換する際にミスを犯すことがあります。一般的な落とし穴を認識しておくことで、重大な問題になる前に回避できます。
- ハードコードされた値:明示的な制約なしに、`INT`カラムを使ってブールフラグ(0/1)を保存しないでください。サポートされている場合は、`BOOLEAN`型または列挙型を使用してください。
- 制約の欠如:外部キーを強制するのにアプリケーションロジックにのみ依存するのは危険です。バグにより不正な挿入が許可されると、データが破損します。制約はデータベースレベルで強制してください。
- VARCHARの過剰使用:柔軟性がある一方で、特定のデータに対して`VARCHAR`は`CHAR`のような固定長型よりも遅くなることがあります。UUIDや郵便番号のような固定長データには`CHAR`を使用してください。
- 文字セットの無視:アプリケーションが国際文字をサポートする場合、データベースとテーブルが初期からUTF-8をサポートするように設定されていることを確認してください。後から変更するのは困難です。
- 暗黙の結合:明示的なインデックスがないテーブルの結合を含むクエリを避けてください。常にクエリ実行計画を確認してください。
チーム間の連携 🤝
ER図はコミュニケーションツールです。データベース管理者、バックエンド開発者、フロントエンド開発者、プロダクトマネージャーの間のギャップを埋めます。明確な図は仮定を防ぎます。
- プロダクトマネージャー向け:機能要件のデータ要件を理解するのに役立ちます。
- フロントエンド開発者向け:APIから受け取るデータの構造を明確にします。
- DevOps向け:容量計画とバックアップ戦略に情報を提供します。
図が不明瞭な場合、チームは推測します。推測はバグを生みます。シニア開発者は図が正確で、最新の状態であり、プロジェクトライフサイクルに関与するすべての人にとってアクセス可能であることを保証します。
ツール vs. 考えること 💡
ER図を描くためのツールは多数存在します。視覚化には役立ちますが、批判的思考を置き換えてはいけません。ツールは図からSQLを生成できますが、関係性が存在する背後にあるビジネスロジックを理解することはできません。
- 論理に注力する:図作成ツールのボタンをクリックする時間よりも、ホワイトボードやテキストエディタでモデルについて議論する時間を多く費やしてください。
- SQLで検証する:図を描き終えたら、SQLを書きます。SQLがわかりにくい場合、図に問題がある可能性が高いです。
- シンプルさを保つ:図を過剰に設計しないでください。関係性が推論できるなら、複雑な構造を強制しないでください。
データモデリングに関する最終的な考察 🏁
堅牢なデータレイヤーを構築することは、理論と実践のバランスです。ER図は単なる図ではなく、アプリケーションとデータとの間の契約です。抽象化レイヤーを尊重し、正規化とパフォーマンスのトレードオフを理解し、最初から進化を計画することで、耐障害性とスケーラビリティを持つシステムを構築できます。
最も効果的なシニア開発者は、ボックスアンドラインの図を見た瞬間に、潜在的なクエリ、おそらくのボトルネック、移行経路を直ちに把握できる人です。彼らは単に線を引くのではなく、システムを設計します。これらの原則に注力することで、データアーキテクチャがビジネス目標を支援し、負債にならないことを保証できます。

