











जब कोई सॉफ्टवेयर सिस्टम स्केल होने लगता है, तो डेटा परत अक्सर सबसे महत्वपूर्ण बैरियर बन जाती है। जबकि एप्लीकेशन कोड को फिर से लिखा जा सकता है और फ्रंट-एंड इंटरफेस को फिर से डिज़ाइन किया जा सकता है, डेटाबेस स्कीमा एप्लीकेशन की मूल सच्चाई का प्रतिनिधित्व करता है। खराब ढंग से बनाए गए एंटिटी-रिलेशनशिप डायग्राम (ERD) केवल एक दृश्य असुविधा नहीं है; यह समय के साथ बढ़ती एक संरचनात्मक कमजोरी है। इस विश्लेषण में गलत डेटाबेस मॉडलिंग से जुड़ी भौतिक और अभौतिक लागतों और विकास चक्र के बाद के चरण में इन संरचनाओं के रीफैक्टरिंग की जटिल वास्तविकता का अध्ययन किया गया है।
बहुत से टीमें स्कीमा डिज़ाइन को एक प्रारंभिक कार्य के रूप में देखती हैं, जिसे वास्तविक कोडिंग शुरू करने से पहले पूरा कर लेना चाहिए। हालांकि, जैसे ही आवश्यकताएं बदलती हैं और व्यावसायिक तर्क विकसित होते हैं, खराब योजना वाले ERD की कठोरता स्पष्ट हो जाती है। इन विवरणों को नजरअंदाज करने की लागत केवल SQL लिखने में लगे घंटों में नहीं मापी जाती है, बल्कि वेलोसिटी के नुकसान, डाउनटाइम के बढ़े हुए जोखिम और इंफ्रास्ट्रक्चर पर टीम के विश्वास के कम होने में मापी जाती है।
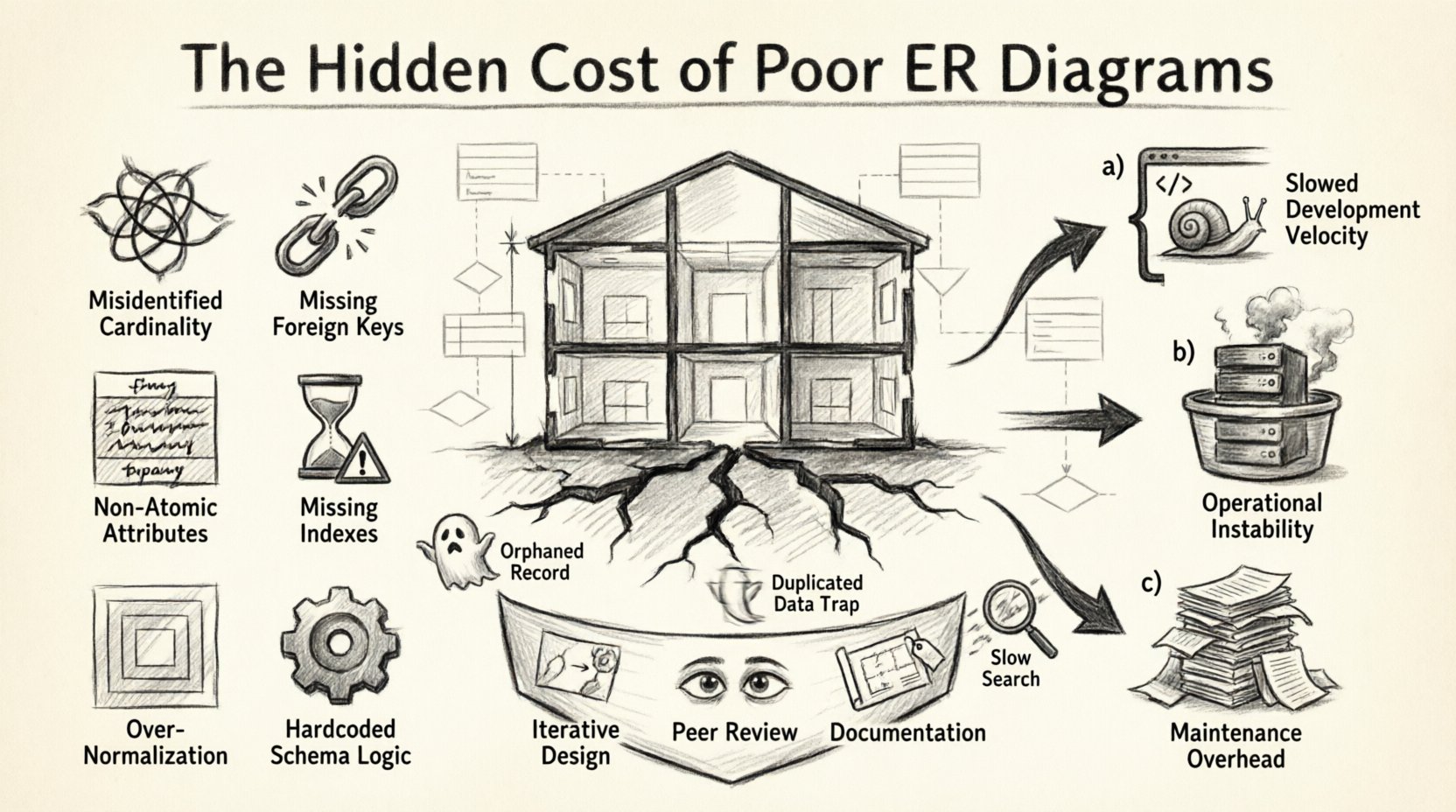
1. ब्लूप्रिंट तुलना: स्कीमा क्यों महत्वपूर्ण है 🏗️
एक डेटाबेस स्कीमा को एक इमारत के आर्किटेक्चरल ब्लूप्रिंट के रूप में सोचें। यदि लोड-बैरिंग दीवारों को गलत जगह रखा गया है, या यदि प्लंबिंग पाइप का रास्ता अनुकूल नहीं है, तो संरचना शुरू में खड़ी रह सकती है। लेकिन समय के साथ, दरारें दिखने लगती हैं। कमजोर आधार पर अतिरिक्त फीचर जोड़ने से संरचनात्मक विफलता होती है। सॉफ्टवेयर में, इसका प्रभाव धीमे प्रश्नों, डेटा असंगतियों और नए फीचर जोड़ने की असमर्थता के रूप में दिखाई देता है, जिससे मौजूदा चीजों को तोड़ना पड़ता है।
एक ERD स्टेकहोल्डर्स, डेवलपर्स और डेटा आर्किटेक्ट्स के बीच संचार उपकरण के रूप में काम करता है। यह एंटिटीज, उनके गुण और उनके बीच के संबंधों को परिभाषित करता है। जब इस डायग्राम में अस्पष्टता या अपूर्णता होती है, तो इसके परिणामस्वरूप होता है:
- इम्प्लीमेंटेशन अस्पष्टता:डेवलपर्स डेटा अखंडता के बारे में ऐसी मान्यताएं बनाते हैं जो व्यावसायिक नियमों से मेल नहीं खाती हैं।
- नॉर्मलाइजेशन की समस्याएं:डेटा या तो अत्यधिक टुकड़ों में बंटा होता है, जिसके लिए अत्यधिक जॉइन की आवश्यकता होती है, या अत्यधिक डेनॉर्मलाइज्ड होता है, जिससे अपडेट विचलन होते हैं।
- प्रतिबंधों की खाई:विदेशी कीज़ या चेक प्रतिबंधों की कमी के कारण अमान्य डेटा सिस्टम में प्रवेश कर सकता है।
इन समस्याओं का एकत्रीकरण होता है। एक संबंध प्रकार में छोटी गलती को महीनों तक नजरअंदाज किया जा सकता है, लेकिन जब कोई विशिष्ट रिपोर्ट या माइग्रेशन निष्पादित की जाती है, तो इसके कारण विनाशकारी विफलता हो सकती है।
2. दोषपूर्ण स्कीमा का अनातम: सामान्य मॉडलिंग त्रुटियां 🔍
ERD में विशिष्ट त्रुटियों की पहचान करना लागतों को समझने का पहला चरण है। नीचे सामान्य मॉडलिंग त्रुटियों का विश्लेषण दिया गया है जो महत्वपूर्ण तकनीकी ऋण के कारण बनती हैं।
| श्रेणी | सामान्य त्रुटि | सिस्टम पर प्रभाव |
|---|---|---|
| संबंध | गलत पहचान की गई कार्डिनैलिटी (1:1 बनाम 1:N) | अनुकूल भंडारण, जटिल जॉइन, डेटा दोहराव। |
| प्रतिबंध | गायब विदेशी कीज़ | अनाथ रिकॉर्ड, डेटा अखंडता का नुकसान, हाथ से साफ करने की आवश्यकता। |
| गुण | अन-एटॉमिक कॉलम | प्रश्न करने में कठिनाई, डेटा के विशिष्ट हिस्सों को इंडेक्स करने की असमर्थता। |
| प्रदर्शन | विदेशी कीज़ पर गायब इंडेक्स | धीमे जॉइन, लेखन के दौरान लॉकिंग प्रतिस्पर्धा, उच्च CPU उपयोग। |
| डिज़ाइन | गहन नेस्टेड नॉर्मलाइज़ेशन | सरल पढ़ाई के लिए अत्यधिक टेबल जॉइन, क्वेरी जटिलता। |
| स्केलेबिलिटी | स्कीमा में हार्डकोडेड लॉजिक | अनलची योजना जो नए व्यापार स्थितियों के अनुकूल नहीं हो सकती। |
इनमें से प्रत्येक प्रविष्टि एक घर्षण के बिंदु का प्रतिनिधित्व करती है। जब कोई डेवलपर स्कीमा में एक त्रुटि का सामना करता है, तो वह अक्सर एप्लिकेशन-लेवल लॉजिक के साथ इसके चारों ओर घूमता है। इससे व्यापार नियम को कोडबेस में ले जाया जाता है, जिससे एक ऐसी चिंता उत्पन्न होती है जिसे बनाए रखना मुश्किल होता है।
3. तकनीकी ऋण को मापना 💰
खराब डिज़ाइन की लागत अक्सर तुरंत नहीं होती है। यह संसाधनों पर एक धीमी लीक है। हम इन लागतों को तीन मुख्य श्रेणियों में वर्गीकृत कर सकते हैं: विकास गति, संचालन स्थिरता, और रखरखाव अतिरिक्त लागत।
3.1 विकास गति
जब स्कीमा अस्पष्ट होता है, तो डेवलपर्स फीचर बनाने के बजाय डेटा मॉडल को उल्टा इंजीनियर करने में समय बिताते हैं। उन्हें आवश्यकता होती है:
- एक ही फील्ड को समझने के लिए कई टेबलों के माध्यम से डेटा प्रवाह का पता लगाना।
- गायब संबंधों की भरपाई के लिए जटिल SQL क्वेरी लिखना।
- डेटा की सफाई के कार्यों को संभालना जो मूल स्रोत पर रोके जाने चाहिए थे।
इससे फीचर डिलीवरी धीमी हो जाती है। डेटा डिबगिंग के कारण तीन दिन में पूरा होने वाला स्प्रिंट पांच या छह दिन तक बढ़ सकता है। यह संगठन के समय और बजट पर सीधा खर्च है।
3.2 संचालन स्थिरता
डेटाबेस की समस्याएं आमतौर पर लोड के तहत उत्पादन में उभरती हैं। खराब इंडेक्सिंग रणनीतियां या सीमाओं की कमी के कारण हो सकता है:
- लॉक प्रतिस्पर्धा:जब कई लेनदेन एक ही खराब ढंग से बनी टेबल को अपडेट करने की कोशिश करते हैं, तो सिस्टम रुक जाता है।
- क्वेरी समय समाप्त होना:अनऑप्टिमाइज्ड जॉइन के कारण डेटाबेस को अनावश्यक रूप से मिलियन पंक्तियों को स्कैन करना पड़ता है।
- डेटा क्षति:उचित सीमाओं के बिना, अमान्य डेटा प्रणाली के माध्यम से फैल सकता है, जिससे रिपोर्टों पर भरोसा करना मुश्किल हो जाता है।
3.3 रखरखाव अतिरिक्त लागत
हर साल एक दोषपूर्ण स्कीमा मौजूद रहने से इसे ठीक करने की लागत बढ़ती है। इसका कारण निर्भरताओं का संचय है। नए फीचर पुरानी, दोषपूर्ण संरचना पर बनाए जाते हैं। रिफैक्टरिंग एक ऐसे घर के फंडेशन को उसके अंदर रहने वाले लोगों के साथ ही हटाने जैसा हो जाता है।
4. रिफैक्टरिंग प्रक्रिया: जटिलता और जोखिम 🛠️
जब डेटाबेस को रिफैक्टर करने का निर्णय लिया जाता है, तो प्रक्रिया चुनौतियों से भरी होती है। यह सिर्फ टेबलों में बदलाव करने के बारे में नहीं है। इसमें माइग्रेशन, डेटा संगतता जांच और न्यूनतम बाधा के साथ सावधानीपूर्वक नियोजन शामिल होता है।
4.1 माइग्रेशन रणनीति
रिफैक्टरिंग के लिए माइग्रेशन स्क्रिप्ट की आवश्यकता होती है। इन स्क्रिप्ट्स को आइडेम्पोटेंट और वापस ले जाने योग्य होना चाहिए। हालांकि, यदि स्कीमा खराब तरीके से दस्तावेज़ीकृत था, तो इन स्क्रिप्ट्स को लिखना एक अनुमान खेल बन जाता है। आपको सुनिश्चित करना होगा कि:
- मौजूदा डेटा को बिना किसी हानि के सही तरीके से परिवर्तित किया जाए।
- संक्रमण के दौरान चल रहे एप्लिकेशन क्रैश नहीं होते हैं।
- अगर कुछ गलत हो जाए, तो रोलबैक योजनाएं व्यवहार्य हैं।
जटिल प्रणालियों में, इसके लिए दोहरी लेखन रणनीति की आवश्यकता हो सकती है, जहां नए डेटा को नए संरचना में लिखा जाता है जबकि पुराने डेटा को पृष्ठभूमि में स्थानांतरित किया जाता है। इससे अस्थायी रूप से एप्लिकेशन तर्क की जटिलता दोगुनी हो जाती है।
4.2 बंदी और उपलब्धता
कुछ संरचनात्मक परिवर्तन, जैसे डिफ़ॉल्ट के साथ कॉलम जोड़ना या बड़ी टेबलों को फिर से इंडेक्स करना, डेटाबेस को लॉक कर सकते हैं। उच्च उपलब्धता वाली प्रणालियों के लिए यह अस्वीकार्य है। रिफैक्टरिंग के लिए अक्सर रखरखाव के खंडों की योजना बनानी होती है, जिससे उपयोगकर्ता अनुभव और राजस्व प्रभावित होते हैं।
4.3 मानव कारक
रिफैक्टरिंग टीम के लिए एक मनोवैज्ञानिक घटना भी है। अगर टीम को स्कीमा के कारण लगातार डेटा बग्स के साथ निपटना पड़ता है, तो मोरल गिर जाता है। वे महसूस करते हैं कि वे लगातार इंफ्रास्ट्रक्चर के खिलाफ लड़ रहे हैं, बल्कि मूल्य बनाने के बजाय। एक साफ, अच्छी तरह से मॉडलिंग वाला डेटाबेस प्लेटफॉर्म में विश्वास वापस लाता है।
5. रणनीतिक रोकथाम: लचीले मॉडल बनाना 🛡️
जबकि रिफैक्टरिंग संभव है, रोकथाम बहुत अधिक लागत-प्रभावी है। एरडी के निर्माण के लिए एक अनुशासित दृष्टिकोण अधिकांश जोखिमों को कम कर सकता है।
5.1 आवर्ती डिज़ाइन
अंतिम आवश्यकताओं का इंतजार करके स्कीमा डिज़ाइन न करें। स्थिर मूल एंटिटी और संबंधों के साथ शुरुआत करें। मॉडल के विकास की अनुमति दें। ईआरडी को एक जीवंत दस्तावेज़ के रूप में लें, जिसे फीचर अनुरोधों के साथ अपडेट किया जाता है।
5.2 डेटा मॉडल की सहकर्मी समीक्षा
जैसे कोड की समीक्षा की जाती है, वैसे ही डेटाबेस स्कीमा की भी समीक्षा की जानी चाहिए। एक ताज़ा नज़र निम्नलिखित को देख सकती है:
- आवश्यकता से अधिक डेटा क्षेत्र।
- टेबलों के बीच गायब संबंध।
- संभावित नाम संघर्ष।
- नॉर्मलाइज़ेशन नियमों का उल्लंघन।
इस समीक्षा प्रक्रिया सुनिश्चित करती है कि मॉडल बिल्कुल भी माइग्रेशन कोड लिखे जाने से पहले व्यापार के उद्देश्य के अनुरूप हो।
5.3 दस्तावेज़ीकरण और नामांकन प्रथाएं
स्थिरता महत्वपूर्ण है। टेबल और कॉलम के लिए सख्त नामांकन प्रथाएं स्थापित करें। ऐसे संक्षिप्त रूपों से बचें जो व्यापक रूप से समझे नहीं जाते हैं। प्रत्येक विदेशी कुंजी के पीछे के व्यापार नियम को दस्तावेज़ करें। इससे यह सुनिश्चित होता है कि टीम में शामिल होने वाला कोई भी व्यक्ति प्रश्न पूछे बिना डेटा को समझ सकता है।
6. मृत्यु के बाद के मामले: सीखे गए पाठ 📝
आइए काल्पनिक परिदृश्यों का अध्ययन करें जहां खराब ईआरडी डिज़ाइन ने महत्वपूर्ण समस्याओं का कारण बनाया, जिससे बचने के लिए ज्ञान मिलता है।
परिदृश्य A: अनाथ रिकॉर्ड संकट
स्थिति:एक टीम ने उपयोगकर्ता आदेशों और डिलीवरी पतों को ट्रैक करने के लिए एक प्रणाली डिज़ाइन की। उन्होंने लेखन प्रदर्शन में सुधार के लिए विदेशी कुंजी सीमा को हटा दिया, मानकर कि एप्लिकेशन तर्क नियंत्रण करेगा।
विफलता:समय के साथ, उपयोगकर्ताओं ने अपने खाते मिटा दिए लेकिन आदेश बनाए रखे। डिलीवरी पते अनाथ हो गए। जब टीम ने कर रिपोर्ट बनाने की कोशिश की, तो जॉइन विफल हो गया क्योंकि उपयोगकर्ता डेटा गायब था।
लागत:टीम को ऐतिहासिक डेटा को एक सामान्य “अनजान” उपयोगकर्ता बाल्टी से हाथापाई से जोड़ने के लिए स्क्रिप्ट लिखनी पड़ी। इसमें इंजीनियरिंग समय के तीन दिन लगे और सुरक्षित रूप से परीक्षण के लिए पूर्ण डेटाबेस डंप और पुनर्स्थापना की आवश्यकता थी।
परिदृश्य B: अनॉर्मलाइज़ेशन की जाल
स्थिति:पढ़ने के प्रदर्शन को तेज करने के लिए, एक टीम ने उपयोगकर्ता प्रोफ़ाइल डेटा को ऑर्डर टेबल में कॉपी कर दिया। उन्हें लगा कि इससे जॉइन ऑपरेशन कम होंगे।
विफलता: जब किसी उपयोगकर्ता ने अपना नाम अपडेट किया, तो एप्लिकेशन ने उपयोगकर्ता टेबल को अपडेट किया लेकिन पुराने नाम वाले हजारों ऑर्डर रिकॉर्ड को अपडेट नहीं किया। रिपोर्ट्स में एक ही उपयोगकर्ता के असंगत नाम दिखाए गए।
लागत: डेटा सुसंगतता खो गई। टीम को तय करना था कि क्या वे असंगतता को स्वीकार करें या डेटा को सिंक करने के लिए एक जटिल ट्रिगर सिस्टम लागू करें। उन्होंने डुप्लीकेशन हटाने के लिए स्कीमा को फिर से डिज़ाइन करने का निर्णय लिया, जिसमें एप्लिकेशन के लेखन लॉजिक को पुनर्लेखित करने की आवश्यकता थी।
परिदृश्य C: इंडेक्सिंग की अंधी बिंदु
स्थिति: एक सर्च फीचर को मिलियनों पंक्तियों वाली टेबल पर बनाया गया था। डेवलपर ने मान लिया कि प्राइमरी की पर्याप्त होगी।
विफलता: जैसे-जैसे टेबल बड़ी होती गई, सर्च कॉलम पर क्वेरी धीमी हो गई। डेटाबेस को पूरी टेबल स्कैन करनी पड़ी।
लागत: शीर्ष घंटों के दौरान सिस्टम उपयोगी नहीं रहा। बाद में इंडेक्स जोड़ने के लिए एक लंबे समय तक चलने वाले ऑपरेशन की आवश्यकता थी जिसने टेबल को घंटों तक लॉक कर दिया, जिससे सेवा में व्यवधान आया।
7. अपनी डेटा परत को भविष्य के लिए सुरक्षित बनाएं 🔮
किसी भी डेटा मॉडलिंग प्रयास का लक्ष्य बदलाव को सहने योग्य एक आधार बनाना है। जब तक कोई स्कीमा हमेशा के लिए सही नहीं होता, एक अच्छा ईआरडी विकास के लिए स्पष्ट रास्ता प्रदान करता है।
- संस्करण नियंत्रण: अपने स्कीमा माइग्रेशन को कोड के रूप में लें। उन्हें संस्करण नियंत्रण में स्टोर करें ताकि समय के साथ बदलावों को ट्रैक किया जा सके।
- स्वचालित परीक्षण: अपने सीआई/सीडी पाइपलाइन में स्कीमा वैधता शामिल करें। यह सुनिश्चित करें कि माइग्रेशन मौजूदा क्वेरी को तोड़ते नहीं हैं।
- निगरानी: अभावगत इंडेक्स या अकुशल जॉइन को जल्दी से पहचानने के लिए क्वेरी प्रदर्शन की निगरानी करें।
- समुदाय मानक: अपने विशिष्ट डेटाबेस तकनीक के लिए स्थापित बेस्ट प्रैक्टिस का पालन करें ताकि संगतता और प्रदर्शन सुनिश्चित हो।
ईआरडी चरण में समय निवेश करना एक देरी नहीं है; यह तेजी है। यह भविष्य के विकास की रुकावट को कम करता है और यह सुनिश्चित करता है कि डेटा एक विश्वसनीय संपत्ति बनी रहे, न कि एक दायित्व।
निष्कर्ष: अज्ञान की लागत बनाम योजना का मूल्य ⚖️
खराब ईआरडी की छिपी हुई लागत अक्सर तब तक अदृश्य रहती है जब तक बहुत देर न हो जाए। यह धीमी फीचर डिलीवरी, अस्थिर उत्पादन वातावरण और निराश इंजीनियरिंग टीमों के रूप में दिखाई देती है। डेटाबेस को फिर से डिज़ाइन करना एक उच्च-जोखिम ऑपरेशन है जिसमें सटीकता, योजना और अक्सर बड़े समय तक बंद रहने की आवश्यकता होती है।
डेटा मॉडलिंग को एक महत्वपूर्ण इंजीनियरिंग कार्य के रूप में लेने से निर्माण के तकनीकी ऋण के फंदे से बचा जा सकता है। एक अच्छी तरह से डिज़ाइन किए गए स्कीमा के रूप में एक सुरक्षा बनता है, जो यह सुनिश्चित करता है कि एप्लिकेशन बढ़ते रहने पर भी मजबूत रहे। एक ठोस ईआरडी को डिज़ाइन करने में लगाए गए प्रयास के बाद लिखे गए हर कोड लाइन, हर क्वेरी और हर उपयोगकर्ता के लिए लाभ देते हैं।
एक अच्छे ब्लूप्रिंट के मूल्य को समझने के लिए पोस्ट-मॉर्टम का इंतजार न करें। दिन भर से शुरू करते हुए स्पष्टता, कठोरता और डेटा अखंडता के प्रति प्रतिबद्धता के साथ योजना बनाना शुरू करें।

