











Ketika arsitektur basis data yang dirancang di atas kertas berjalan sempurna di lingkungan uji coba tetapi runtuh di bawah lalu lintas dunia nyata, ketidaksesuaian sering terletak antara model visual dan kenyataan saat berjalan. Diagram Hubungan Entitas (ERD) adalah gambaran rancangan, bukan mesin yang hidup. Namun, ketika pengembang menyebut ‘ERD gagal di bawah beban’, mereka biasanya menggambarkan desain skema yang berasal dari diagram tersebut dan tidak mampu menopang permintaan produksi. Panduan ini membahas hambatan struktural, logis, dan kinerja yang menyebabkan model relasional mengalami kesulitan ketika volume data dan konkurensi meningkat tajam.
Mendiagnosis masalah-masalah ini membutuhkan pemahaman mendalam tentang bagaimana hubungan data berubah menjadi operasi I/O, persaingan kunci, dan penggunaan memori. Kami akan mengeksplorasi titik-titik gesekan di mana pilihan desain bertabrakan dengan keterbatasan perangkat keras dan pola lalu lintas. Dengan mengidentifikasi gejala spesifik kegagalan struktural, Anda dapat merefaktor model data Anda agar mendukung skalabilitas tanpa mengorbankan integritas data.
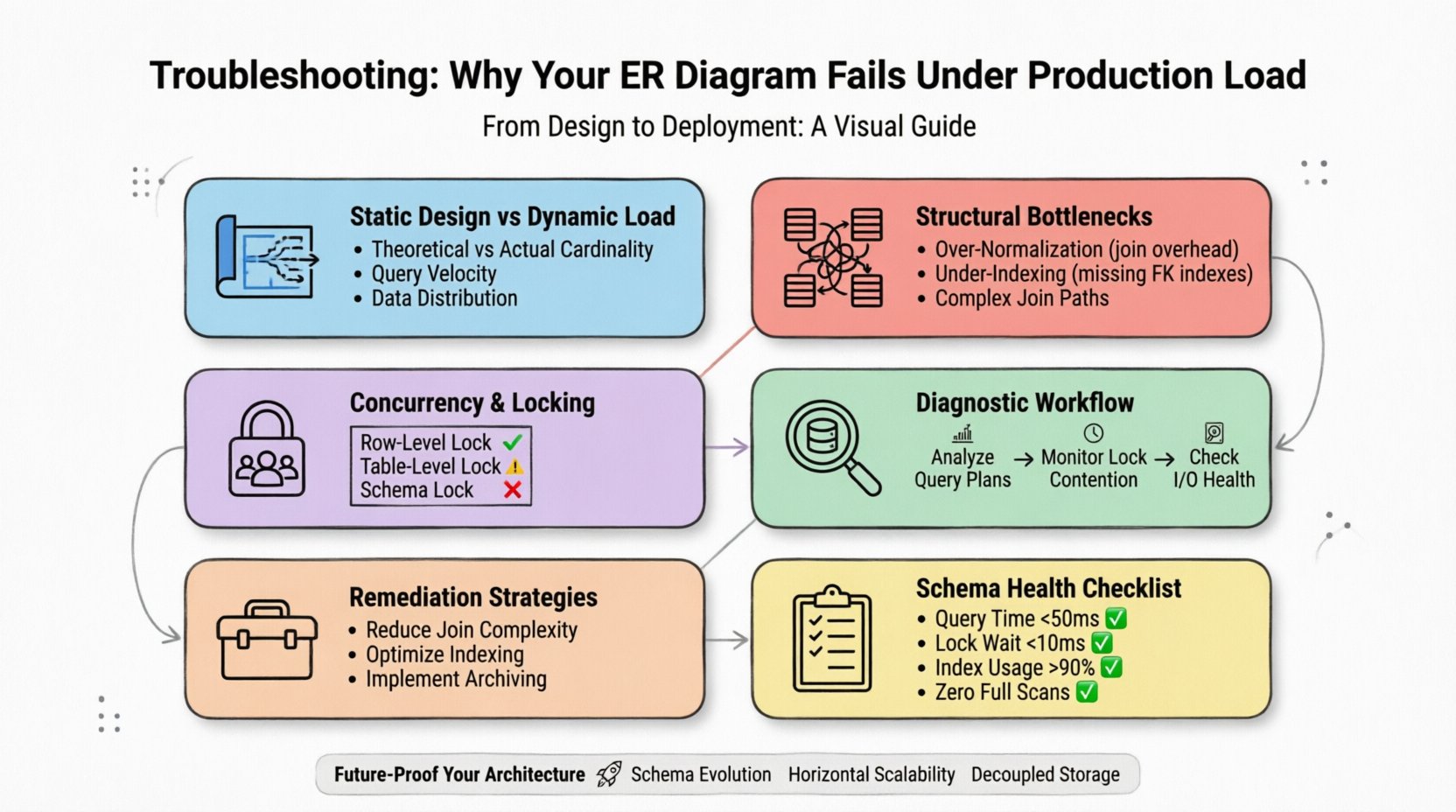
1. Celah Antara Desain Statis dan Beban Dinamis ⚡
Diagram ER mewakili hubungan potensial dan tipe data. Diagram ini tidak mempertimbangkan kecepatan operasi tulis, distribusi operasi baca, atau keterbatasan penyimpanan fisik dari mesin dasar. Model yang tampak seimbang di papan tulis sering menyembunyikan ketidakefisienan yang hanya muncul ketika jutaan baris diproses secara bersamaan.
- Kardinalitas Teoritis vs. Nyata:Diagram mengasumsikan hubungan satu-ke-satu atau satu-ke-banyak. Di produksi, hubungan ini sering berubah menjadi banyak-ke-banyak dengan jalur join yang kompleks yang menghabiskan sumber daya CPU.
- Kecepatan Query:Skema mungkin dapat menangani beberapa ribu baca per detik tetapi macet pada ribuan per milidetik karena granularitas kunci.
- Distribusi Data:Titik panas terjadi ketika data tidak didistribusikan secara merata di antara node penyimpanan, menyebabkan keseimbangan beban yang tidak merata.
Untuk mendiagnosis secara efektif, Anda harus berhenti memperlakukan skema sebagai benda statis. Skema adalah sumber daya dinamis yang harus dipantau seakurat server itu sendiri.
2. Hambatan Struktural Umum 📉
Penyebab paling umum penurunan kinerja adalah struktur hubungan itu sendiri. Cara tabel terhubung menentukan bagaimana mesin menelusuri data. Gabungan yang kompleks adalah penyebab utama waktu eksekusi query yang lambat.
2.1 Risiko Normalisasi Berlebihan
Meskipun normalisasi mengurangi redundansi, normalisasi berlebihan meningkatkan jumlah join yang diperlukan untuk mengambil satu set data. Dalam skenario beban tinggi, setiap join merupakan titik potensial kegagalan.
- Overhead Join:Setiap operasi join membutuhkan basis data untuk mencocokkan baris dari dua tabel. Jika kedua tabel besar dan tidak memiliki indeks yang tepat, mesin akan melakukan pemindaian penuh tabel.
- Kedalaman Transaksi:Skema yang sangat dinormalisasi sering membutuhkan transaksi yang berjalan lama untuk mengambil data terkait, sehingga mempertahankan kunci dalam waktu yang lama.
- Efisiensi Cache:Data yang dinormalisasi terfragmentasi di berbagai halaman, mengurangi efektivitas penyimpanan sementara buffer pool.
2.2 Indeks yang Kurang dan Jalur Akses
ERD yang terstruktur baik mengimplikasikan pola akses. Jika diagram tidak sesuai dengan beban query aktual, mesin basis data tidak dapat menemukan jalur tercepat menuju data.
- Indeks Kunci Asing:Kunci asing sering tidak memiliki indeks, menyebabkan penurunan kinerja saat menghapus atau memperbarui catatan induk.
- Urutan Kunci Komposit:Urutan kolom dalam indeks komposit penting. Jika query melakukan filter pada kolom kedua terlebih dahulu, indeks mungkin diabaikan.
- Indeks Selektif yang Hilang:Tanpa indeks pada kolom dengan kardinalitas tinggi, mesin melakukan pemindaian seluruh tabel untuk menemukan nilai tertentu.
3. Konkurensi dan Mekanisme Kunci 🔒
Ketika beban meningkat, konkurensi menjadi kendala utama. Banyak pengguna yang berusaha mengubah data yang sama menciptakan persaingan. Jika desain skema tidak mempertimbangkan granularitas kunci, sistem akan mengalami deadlock atau waktu habis.
| Jenis Kunci | Dampak terhadap Beban | Gejala Umum |
|---|---|---|
| Kunci Tingkat Baris | Dampak minimal, konkurensi tinggi | Latensi rendah, throughput tinggi |
| Kunci Tingkat Tabel | Dampak tinggi, menghambat pengguna lain | Kesalahan waktu habis, kueri tergantung |
| Kunci Skema | Menghambat semua akses selama DDL | Gangguan sistem secara keseluruhan saat pemeliharaan |
3.1 Deadlock dan Kondisi Persaingan
Deadlock terjadi ketika dua transaksi menunggu satu sama lain melepaskan sumber daya. Hal ini sering disebabkan oleh urutan kunci yang tidak konsisten dalam logika aplikasi yang berinteraksi dengan skema.
- Tingkat Isolasi Transaksi:Tingkat isolasi yang lebih tinggi (seperti Serializable) memberikan keamanan tetapi secara signifikan mengurangi konkurensi.
- Peningkatan Kunci:Jika transaksi mengunci terlalu banyak baris, mesin dapat meningkatkan ke kunci tabel, menghambat semua operasi lainnya.
- Transaksi Panjang:Operasi yang memegang kunci selama detik alih-alih milidetik menciptakan kemacetan bagi seluruh antrian.
4. Volume Data dan Strategi Partisi 📊
Ketika data tumbuh, batas fisik lapisan penyimpanan menjadi jelas. Skema yang berfungsi untuk 10.000 baris dapat gagal secara kritis dengan 100 juta baris. Partisi adalah metode yang digunakan untuk membagi tabel besar menjadi bagian-bagian kecil yang lebih mudah dikelola.
- Partisi Vertikal:Memindahkan kolom yang jarang diakses ke tabel terpisah mengurangi ukuran tabel utama, meningkatkan tingkat keberhasilan cache untuk data panas.
- Partisi Horizontal:Memecah baris di seluruh beberapa segmen fisik (sharding) mendistribusikan beban ke beberapa node penyimpanan.
- Partisi Berbasis Waktu:Untuk data transaksional, partisi berdasarkan tanggal memungkinkan mesin menghapus partisi lama secara instan tanpa mengunci seluruh tabel.
5. Alur Diagnostik untuk Kegagalan Produksi 🔍
Ketika sistem melambat, Anda memerlukan pendekatan sistematis untuk mengidentifikasi akar masalahnya. Optimasi acak sering kali membuang-buang sumber daya. Ikuti alur kerja ini untuk mengidentifikasi masalahnya.
5.1 Analisis Rencana Eksekusi Query
Rencana eksekusi mengungkapkan bagaimana mesin basis data bermaksud mengambil data. Perhatikan indikator khusus yang menunjukkan ketidakefisienan.
- Pemindaian Seluruh Tabel:Menunjukkan indeks yang hilang atau query yang meminta terlalu banyak data.
- Pencarian Kunci:Menunjukkan bahwa mesin harus bolak-balik antara indeks dan data tabel secara berulang, meningkatkan I/O.
- Operasi Pengurutan:Mengurutkan hasil set besar menghabiskan memori dan CPU yang signifikan.
5.2 Pantau Persaingan Kunci
Gunakan alat sistem untuk memantau peristiwa menunggu. Waktu tunggu tinggi pada kunci menunjukkan bahwa skema tidak dapat mendukung tingkat konkurensi saat ini.
- Metrik Waktu Tunggu:Lacak durasi transaksi yang menghabiskan waktu menunggu sumber daya.
- Grafik Kematian Mati:Tinjau data historis untuk melihat query mana yang menyebabkan konflik.
- Antrian Tunggu Kunci:Pantau jumlah transaksi yang menunggu sumber daya yang sama.
5.3 Periksa Kesehatan Subsistem I/O
Bahkan dengan skema yang sempurna, penyimpanan yang lambat akan menyebabkan kegagalan. Pastikan infrastruktur dasar sesuai dengan pola akses data.
- Batasan Throughput:Periksa apakah perangkat penyimpanan jenuh dengan operasi baca/tulis.
- Lonjakan Latensi:Waktu respons yang tidak konsisten dari lapisan penyimpanan sering menunjukkan kerusakan perangkat keras.
- Efisiensi Buffer Pool:Jika basis data menghabiskan lebih banyak waktu membaca dari disk daripada memori, maka skema atau volume data terlalu besar untuk cache.
6. Strategi Perbaikan untuk Optimalisasi Skema 🛠️
Setelah bottleneck diidentifikasi, terapkan perubahan yang ditargetkan. Refactoring skema produksi memerlukan kehati-hatian untuk menghindari kehilangan data atau downtime.
6.1 Mengurangi Kompleksitas Join
Sederhanakan hubungan yang menyebabkan gesekan paling besar. Ini sering melibatkan denormalisasi area tertentu dari model.
- Tampilan yang Dibuat Nyata: Hitung terlebih dahulu gabungan yang kompleks dan simpan hasilnya dalam tabel terpisah untuk pengambilan data yang cepat.
- Kolom yang Dihitung: Simpan data yang dihasilkan langsung di dalam tabel untuk menghindari perhitungan saat query dilakukan.
- Rute Pembacaan Replika: Kirim query yang padat baca ke replika yang menyimpan salinan data yang tidak normalisasi.
6.2 Mengoptimalkan Strategi Indeks
Indeks adalah alat paling efektif untuk mempercepat pencarian, tetapi memiliki biaya pada operasi tulis.
- Indeks yang Disaring: Buat indeks hanya pada subset data yang sering diquery.
- Indeks yang Meliputi: Sertakan semua kolom yang dibutuhkan untuk sebuah query dalam indeks agar menghindari akses ke tabel utama.
- Pemeliharaan Indeks: Bangun ulang atau organisasi indeks secara rutin untuk mencegah fragmentasi yang disebabkan oleh pembaruan yang sering.
6.3 Menerapkan Penghapusan Lembut dan Arsip
Data aktif lebih cepat diquery dibandingkan data historis. Memindahkan data lama keluar dari tabel utama meningkatkan kinerja.
- Tabel Arsip: Pindahkan catatan yang lebih tua dari ambang batas tertentu ke lapisan penyimpanan terpisah yang lebih dingin.
- Penghapusan Lembut: Tandai catatan sebagai dihapus tanpa menghapusnya, menjaga struktur tabel tetap stabil sambil menyembunyikan data secara logis.
- Kebijakan Penyimpanan Data: Otomatiskan penghapusan data yang tidak perlu untuk mencegah pertumbuhan yang tidak terkendali.
7. Daftar Periksa Evaluasi Kesehatan Skema ✅
Sebelum menerapkan perubahan, verifikasi model Anda terhadap kriteria ini untuk memastikan dapat menangani tekanan produksi.
| Kriteria | Kondisi Lulus | Kondisi Gagal |
|---|---|---|
| Waktu Query Rata-Rata | < 50ms | > 500ms |
| Waktu Tunggu Kunci | < 10ms | > 100ms |
| Penggunaan Indeks | > 90% | < 50% |
| Pemindaian Seluruh Tabel | Nol | Sering |
Secara rutin meninjau model data Anda terhadap metrik-metrik ini memastikan bahwa desain berkembang seiring dengan kebutuhan bisnis Anda. Skema statis pada akhirnya akan menjadi beban. Pemantauan berkelanjutan dan penyesuaian bertahap adalah satu-satunya cara untuk menjaga keandalan.
8. Memahami Pola Query dan Beban Kerja 📈
Kinerja bukan hanya soal skema; itu tentang bagaimana skema tersebut digunakan. Memahami profil beban kerja sangat penting untuk menyesuaikan model.
- OLTP vs. OLAP:Pemrosesan Transaksi Online (OLTP) membutuhkan tulisan cepat dan kecil. Pemrosesan Analitik Online (OLAP) membutuhkan bacaan cepat dan besar. Skema yang dioptimalkan untuk satu sering mengalami kesulitan dengan yang lain.
- Pola Berat Menulis: Jika aplikasi Anda sering menulis, prioritaskan efisiensi indeks dan minimalisasi kunci saat menulis.
- Pola Berat Membaca: Jika aplikasi Anda sering membaca, prioritaskan strategi penyimpanan sementara dan replika baca.
9. Peran Logika Aplikasi dalam Kinerja Basis Data 💻
Seringkali, kesalahan bukan terletak pada basis data, tetapi pada bagaimana aplikasi berinteraksi dengannya. Masalah query N+1 adalah contoh klasik ketidakefisienan tingkat aplikasi yang muncul sebagai kegagalan basis data.
- Operasi Massal: Mengirim ribuan pernyataan insert individual lebih lambat daripada satu operasi batch tunggal.
- Pemuatan Lalai: Mengambil data dalam ukuran kecil dapat menghasilkan jumlah perjalanan bolak-balik yang berlebihan ke basis data.
- Pembuangan Koneksi: Pengelolaan koneksi basis data yang tidak efisien dapat menghabiskan sumber daya yang tersedia saat beban puncak.
Mengoptimalkan lapisan aplikasi mengurangi tekanan pada skema, memungkinkan basis data berfungsi dalam parameter yang dirancang.
10. Membuat Arsitektur Data yang Tahan Masa Depan 🚀
Merancang untuk masa depan membutuhkan antisipasi pertumbuhan. Meskipun Anda tidak dapat memprediksi jumlah lalu lintas secara pasti, Anda dapat merancang untuk elastisitas.
- Evolusi Skema: Gunakan strategi migrasi yang memungkinkan perubahan yang tidak mengganggu terhadap model data.
- Skalabilitas Horizontal: Rancang tabel untuk mendukung pembagian data sejak awal.
- Penyimpanan Terpisah: Pisahkan lapisan penyimpanan dari lapisan komputasi agar keduanya dapat diskalakan secara independen.
Dengan mematuhi prinsip-prinsip ini, Anda membangun fondasi yang mampu bertahan terhadap tekanan produksi. Tujuannya bukan hanya memperbaiki masalah saat ini, tetapi menciptakan sistem yang tangguh dan mampu beradaptasi terhadap tantangan masa depan.
11. Ringkasan Langkah Diagnostik Utama 📝
Untuk mengingatkan kembali, mendiagnosis kegagalan beban produksi melibatkan pendekatan berlapis-lapis.
- Tinjau ERD: Periksa adanya hubungan yang terlalu rumit dan indeks yang hilang.
- Analisis Kueri: Cari tanda-tanda pemindaian lengkap tabel dan jalur gabungan yang tidak efisien.
- Pantau Kunci: Identifikasi titik persaingan yang menyebabkan waktu habis.
- Periksa Perangkat Keras: Pastikan penyimpanan dan memori tidak menjadi hambatan.
- Optimalkan Skema: Terapkan strategi partisi dan indeks.
- Refaktor Aplikasi: Kurangi jumlah panggilan ke basis data dan optimalkan penanganan transaksi.
Mengikuti pendekatan terstruktur ini memastikan Anda menangani akar masalah, bukan hanya gejalanya. Penyesuaian kinerja adalah proses iteratif yang membutuhkan kesabaran dan ketelitian.
12. Pikiran Akhir tentang Ketahanan Skema 🧠
Model data yang kuat adalah tulang punggung dari setiap aplikasi berkinerja tinggi. Ini membutuhkan perhatian terus-menerus dan kemauan untuk beradaptasi seiring perubahan pola lalu lintas. Dengan memahami nuansa hubungan, indeks, dan konkurensi, Anda dapat mencegah jebakan umum yang menyebabkan kegagalan produksi.
Ingatlah bahwa diagram adalah alat, bukan sistem itu sendiri. Ujian sebenarnya dari desain Anda terjadi di lingkungan yang sedang berjalan. Pertahankan pemantauan yang ketat, indeks yang bersih, dan transaksi yang singkat. Dengan praktik-praktik ini diterapkan, arsitektur data Anda akan menjadi fondasi yang dapat diandalkan untuk pertumbuhan bisnis Anda.
Tetap waspada. Pantau metrik Anda. Refaktor jika diperlukan. Sistem Anda akan menghargainya.

