











Los esquemas de bases de datos a menudo evolucionan de forma orgánica en lugar de a través de un diseño intencional. Con el tiempo, los ciclos rápidos de desarrollo, la falta de documentación y los cambios en los requisitos empresariales conducen a estructuras complejas y difíciles de navegar. Muchas organizaciones se encuentran heredando sistemas heredados en los que los arquitectos originales ya no están disponibles, y el modelo de datos queda oscurecido por años de parches y arreglos urgentes. Este proceso implica analizar las capas de datos existentes y reconstruirlas en un Diagrama de Relaciones de Entidades (ERD) estandarizado. El objetivo es claridad, mantenibilidad e integridad.
La ingeniería inversa de una base de datos no consiste únicamente en dibujar líneas entre tablas; se trata de comprender la lógica empresarial incrustada en los datos. Un ERD limpio sirve como plano para el desarrollo futuro, como herramienta de comunicación para los interesados y como salvaguarda contra la corrupción de datos. Esta guía detalla el flujo técnico para transformar un esquema caótico en un diseño estructurado y normalizado sin depender de herramientas propietarias específicas.
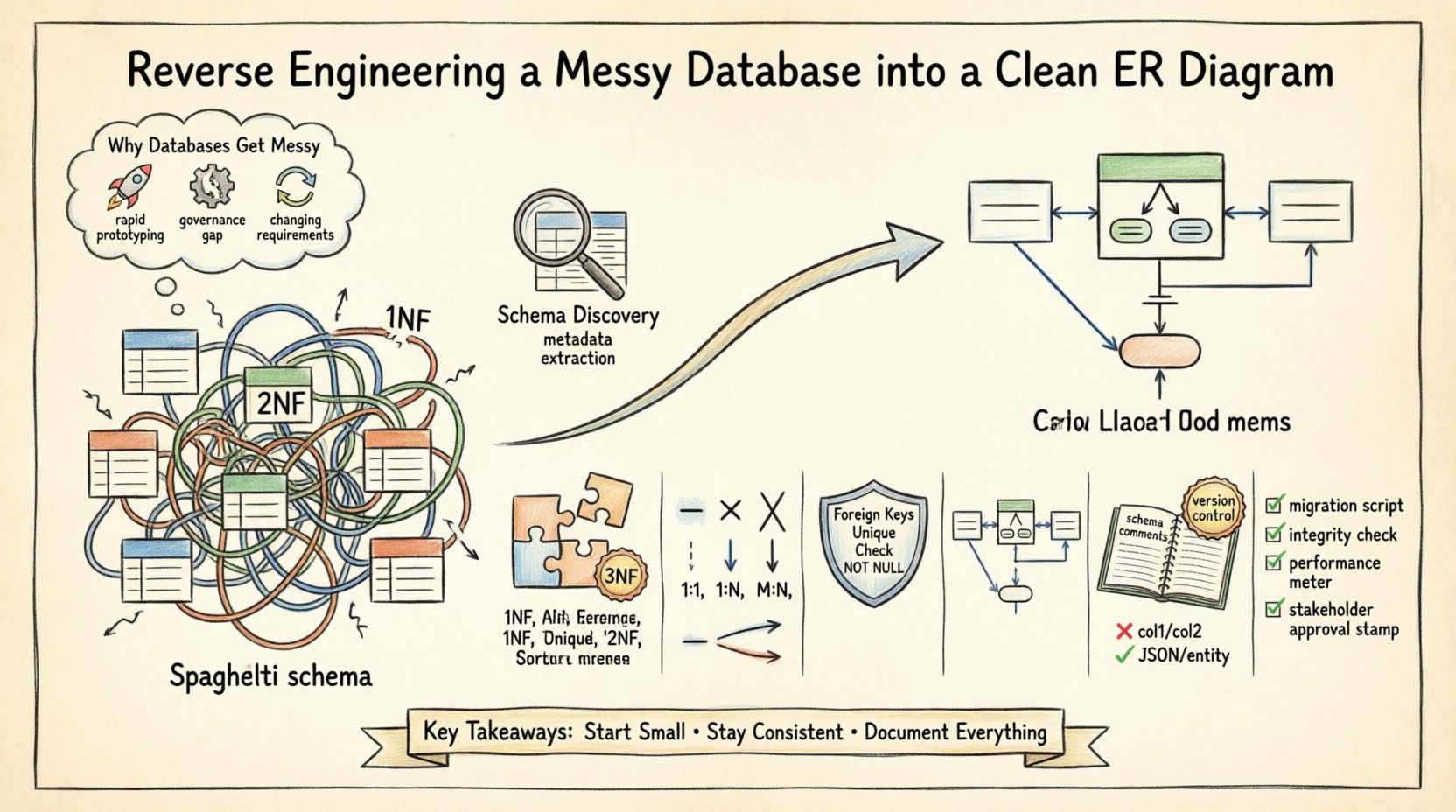
¿Por qué las bases de datos se vuelven desordenadas 📉
Comprender la causa raíz de la deuda del esquema es el primer paso hacia su corrección. Varios factores contribuyen a una estructura de base de datos desorganizada:
- Prototipado rápido:El desarrollo inicial suele priorizar la velocidad sobre la estructura. Las tablas se crean de forma ad hoc para satisfacer solicitudes de características inmediatas sin considerar la escalabilidad a largo plazo.
- Falta de gobernanza:Cuando múltiples desarrolladores modifican el esquema sin un proceso de revisión centralizado, las convenciones de nombres divergen y aparecen columnas redundantes.
- Cambios en la lógica empresarial:A medida que los requisitos cambian, las tablas se modifican para acomodar nuevos campos. A veces se eliminan claves foráneas para evadir restricciones, lo que genera registros huérfanos.
- Fallas en la documentación:Los comentarios y las descripciones de metadatos a menudo se omiten durante la implementación inicial, lo que dificulta comprender la intención de columnas específicas más adelante.
Estos problemas dan lugar a lo que comúnmente se denomina ‘esquema espagueti’. Las relaciones se vuelven implícitas en lugar de explícitas, y las claves primarias pueden perderse o duplicarse en múltiples tablas. Las siguientes secciones describen el enfoque sistemático para resolver estos problemas.
Fase 1: Descubrimiento y perfilado del esquema 🔍
Antes de dibujar cualquier línea, debes comprender el estado actual de la base de datos. Esta fase se centra en la extracción y el análisis, más que en la modificación.
Extracción de metadatos
Cada sistema de gestión de bases de datos relacionales mantiene catálogos del sistema o vistas de esquema de información. Estos repositorios contienen detalles sobre tablas, columnas, tipos de datos, restricciones e índices. Utilice interfaces de consulta para recuperar estos metadatos.
- Lista de tablas:Recupere todos los nombres de tablas y sus fechas de creación para identificar estructuras heredadas.
- Definiciones de columnas:Extraiga los nombres de columnas, tipos de datos, nulabilidad y valores predeterminados.
- Restricciones:Identifique las claves primarias, restricciones únicas y relaciones de claves foráneas. Observe que algunas relaciones pueden estar garantizadas únicamente a nivel de aplicación, no en la base de datos.
- Índices:Analice los índices existentes para comprender los patrones de rendimiento de las consultas e identificar claves candidatas potenciales.
Perfilado de datos
Los metadatos te dicen qué debería ser el esquema, pero el perfilado de datos te dice qué es en realidad. Escanear los valores reales de los datos revela inconsistencias que las definiciones de esquema omiten.
- Distribución de valores:Verifique columnas con alta o baja cardinalidad que podrían indicar la necesidad de normalización.
- Tasas de nulos:Altas tasas de nulos en campos obligatorios sugieren la ausencia de restricciones o malas prácticas de entrada de datos.
- Calidad de los datos:Identifique inconsistencias en el formato, como números de teléfono almacenados como texto con formatos variables.
Fase 2: Identificación y normalización de entidades 🧱
Una vez que se entiende los datos brutos, el siguiente paso es la reestructuración lógica. Esto implica identificar entidades y aplicar reglas de normalización para reducir la redundancia.
Identificación de entidades
Una entidad representa un objeto o concepto distinto dentro del dominio empresarial. En una base de datos desordenada, las entidades a menudo se distribuyen entre múltiples tablas o se combinan incorrectamente.
- Granularidad:Asegúrese de que cada tabla represente un solo concepto. Si una tabla almacena información de clientes y de pedidos, es probable que viole los principios de normalización.
- Claves primarias:Establezca un identificador único para cada entidad. Evite usar claves naturales (como direcciones de correo electrónico) si están sujetas a cambios; en su lugar, use claves de sustitución.
- Convenciones de nomenclatura:Estandarice los nombres de las tablas a un formato consistente, como sustantivos en singular (por ejemplo,
clienteen lugar declientes).
Aplicación de la normalización
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque el objetivo no siempre es alcanzar el máximo teórico (Forma Normal de Boyce-Codd), buscar la Tercera Forma Normal (3NF) es una norma sólida para los sistemas transaccionales.
| Forma | Definición | Objetivo |
|---|---|---|
| Primera Forma Normal (1NF) | Valores atómicos en columnas; sin grupos repetidos. | Asegúrese de que cada celda contenga un solo valor. |
| Segunda Forma Normal (2NF) | Cumple con la 1NF y elimina dependencias parciales. | Asegúrese de que los atributos no clave dependan de toda la clave primaria. |
| Tercera Forma Normal (3NF) | Cumple con la 2FN y elimina las dependencias transitivas. | Asegúrese de que los atributos no clave dependan únicamente de la clave primaria. |
Al realizar ingeniería inversa, busque columnas que almacenen listas de valores (por ejemplo, una cadena separada por comas de etiquetas). Estas deben dividirse en filas separadas en una tabla de unión para cumplir con la 1FN. De manera similar, los atributos que describen entidades diferentes (por ejemplo, nombre_producto y dirección_proveedor en la misma tabla) deben separarse en entidades distintas para cumplir con la 2FN y la 3FN.
Fase 3: Mapeo de relaciones 🔗
Las relaciones definen cómo interactúan las entidades. En una base de datos desordenada, estas suelen ser implícitas o ausentes. Esta fase implica definir la cardinalidad y la opcionalidad de estas conexiones.
Tipos de cardinalidad
- Uno a uno (1:1): Una fila en la tabla A se relaciona con exactamente una fila en la tabla B. Esto es raro y a menudo indica una división por razones de seguridad o rendimiento.
- Uno a muchos (1:N): Una fila en la tabla A se relaciona con múltiples filas en la tabla B. Esta es la relación más común (por ejemplo, un cliente realiza muchos pedidos).
- Muchos a muchos (M:N): Múltiples filas en la tabla A se relacionan con múltiples filas en la tabla B. Esto requiere una tabla de unión intermedia (por ejemplo, estudiantes y cursos).
Resolución de relaciones muchos a muchos
Las bases de datos desordenadas a menudo intentan manejar relaciones muchos a muchos duplicando datos o creando tablas anchas con múltiples columnas de claves foráneas. El enfoque correcto es introducir una tabla puente.
- Identifique las dos entidades padres.
- Cree una nueva tabla que contenga las claves primarias de ambos padres.
- Agregue cualquier atributo específico relacionado con la propia relación (por ejemplo,
fecha_inscripciónen una tabla puente de Estudiante-Curso).
Fase 4: Restricciones e integridad de datos 🔒
Un diagrama es inútil si no impone las reglas que representa. La implementación física debe reflejar el diseño lógico mediante restricciones.
- Claves foráneas: Defina explícitamente las restricciones de clave foránea para evitar registros huérfanos. Esto garantiza automáticamente la integridad referencial.
- Restricciones únicas: Aplicar restricciones únicas a las columnas que deben ser distintas (por ejemplo, direcciones de correo electrónico, nombres de usuario).
- Restricciones de verificación: Utilice restricciones de verificación para validar formatos o rangos de datos (por ejemplo,
edad >= 0). - No nulo:Marque los campos esenciales como
NO NULOpara garantizar la integridad de los datos.
Fase 5: Visualización del ERD 🎨
Una vez establecido el modelo lógico, debe visualizarse. Aunque existen software específicos para esto, los principios de diagramación permanecen consistentes.
Normas de diagramación
Elija una norma de notación para garantizar que el diagrama sea legible para diferentes partes interesadas.
- Notación de pie de cuervo: Ampliamente utilizada en la industria. Utiliza símbolos específicos para indicar cardinalidad (por ejemplo, una línea simple para “uno”, una pata de cuervo para “muchos”).
- Diagramas de clases UML: Utiliza cuadros y flechas, generalmente preferido por desarrolladores de software familiarizados con el diseño orientado a objetos.
- Notación de Chen: Utiliza diamantes para las relaciones, común en entornos académicos pero menos frecuente en herramientas empresariales modernas.
Mejores prácticas de diseño
- Agrupación: Agrupe las tablas relacionadas juntas (por ejemplo, todas las tablas de Pedido en una misma área) para mostrar dominios lógicos.
- Dirección del flujo: Organice los diagramas para que fluyan lógicamente de izquierda a derecha o de arriba hacia abajo.
- Legibilidad: Asegúrese de que los nombres de las tablas sean claramente visibles y se minimicen las intersecciones de líneas.
Fase 6: Documentación y mantenimiento 📝
Un diagrama estático es una instantánea. Para garantizar un valor a largo plazo, la documentación debe mantenerse junto con el código.
Comentarios de esquema
Utilice comentarios de columna y tabla para explicar la lógica de negocio. Por ejemplo, una columna denominada estado debe tener un comentario que explique qué valores son válidos (por ejemplo, “0: Pendiente, 1: Aprobado, 2: Rechazado”).
Control de versiones
Almacene los archivos de ERD y definición de esquema en un sistema de control de versiones. Esto le permite rastrear los cambios con el tiempo y revertir si es necesario.
Patrones anti-comunes que se deben evitar 🚫
Durante el proceso de limpieza, tenga cuidado con los errores comunes.
| Patrón anti-común | Problema | Solución |
|---|---|---|
| Columnas genéricas de datos | Usar columnas comocol1, col2para almacenamiento flexible. |
Reemplace por una columna JSON o una nueva tabla de entidades. |
| Claves compuestas | Usar múltiples columnas como clave primaria. | Prefiera claves surrogadas (enteros autoincrementales) por simplicidad. |
| Denormalización para velocidad | Duplicar datos para evitar uniones. | Acepte el costo de rendimiento de las uniones, a menos que el perfilado demuestre lo contrario. |
Fase 7: Validación y prueba ✅
Después de la reestructuración, el nuevo esquema debe validarse frente a los datos existentes.
- Scripts de migración:Escriba scripts para mover los datos desde el esquema antiguo al nuevo. Asegúrese de que no se pierda ningún dato durante la transferencia.
- Verificaciones de integridad referencial:Ejecute consultas para asegurarse de que todas las claves foráneas apunten a registros padres válidos.
- Pruebas de rendimiento:Ejecute la aplicación contra el nuevo esquema para verificar que el rendimiento de las consultas siga siendo aceptable.
- Revisión de partes interesadas:Presente el diagrama a los usuarios del negocio para confirmar que refleja con precisión sus procesos.
Consideraciones Finales 🏁
La ingeniería inversa de una base de datos es una tarea importante que requiere paciencia y precisión. No es una tarea única, sino parte de un ciclo continuo de gobernanza de datos. Al seguir un enfoque estructurado, las organizaciones pueden transformar repositorios de datos caóticos en activos confiables.
Recuerda que el diagrama es una herramienta de comunicación. Si los interesados del negocio no pueden entender las relaciones representadas, el esfuerzo técnico no ha tenido éxito total. Las revisiones regulares del esquema aseguran que el desarrollo futuro se alinee con la arquitectura establecida.
Enfócate en la consistencia. Ya sea en convenciones de nombres, definiciones de restricciones o estilos de diagramas, la uniformidad reduce la carga cognitiva para todos los que interactúan con el sistema. Empieza pequeño. Elige un módulo o dominio, límpialo y documentalo a fondo. Luego amplía el proceso a otras áreas. Este enfoque incremental reduce el riesgo y permite una mejora continua.
En última instancia, una estructura ERD limpia es la base de una estrategia de datos sólida. Permite a los desarrolladores crear características más rápido y reduce la probabilidad de pérdida o corrupción de datos. Invierte el tiempo ahora para obtener los beneficios de estabilidad y claridad más adelante.

