











Схемы баз данных часто развиваются органично, а не по заранее продуманному проекту. Со временем быстрые циклы разработки, отсутствие документации и изменяющиеся бизнес-требования приводят к сложным, труднообозримым структурам. Многие организации оказываются наследниками устаревших систем, где первоначальные архитекторы уже недоступны, а модель данных затуманена годами патчей и срочных исправлений. Этот процесс включает анализ существующих уровней данных и их реконструкцию в стандартизированную диаграмму сущность-связь (ERD). Цель — ясность, поддерживаемость и целостность.
Обратная разработка базы данных — это не просто рисование линий между таблицами; это понимание бизнес-логики, встроенной в данные. Чистая ERD служит чертежом для будущей разработки, инструментом коммуникации для заинтересованных сторон и защитой от повреждения данных. Данное руководство описывает технический процесс преобразования хаотичной схемы в структурированный, нормализованный дизайн без использования специфических проприетарных инструментов.
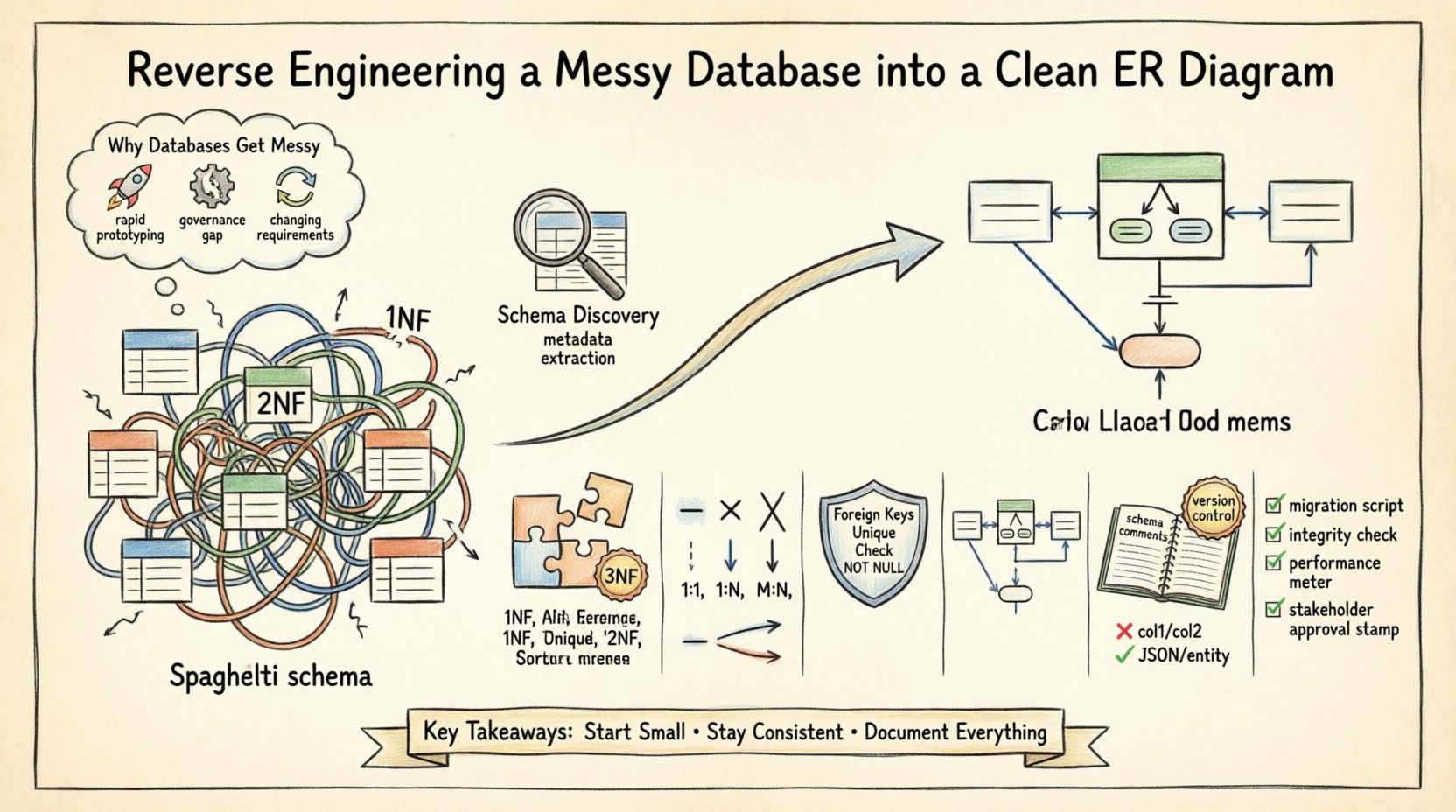
Почему базы данных становятся беспорядочными 📉
Понимание коренных причин накопления долгов схемы — первый шаг к их устранению. Несколько факторов способствуют неорганизованной структуре базы данных:
- Быстрая разработка прототипов:На начальном этапе разработки часто приоритет отдается скорости, а не структуре. Таблицы создаются по ходу дела, чтобы удовлетворить срочные запросы на функциональность, не учитывая долгосрочную масштабируемость.
- Отсутствие управления: Когда несколько разработчиков изменяют схему без централизованного процесса проверки, соглашения об именовании расходятся, появляются избыточные столбцы.
- Изменения бизнес-логики: По мере изменения требований таблицы изменяются для поддержки новых полей. Иногда внешние ключи удаляются, чтобы обойти ограничения, что приводит к появлению «сиротских» записей.
- Пробелы в документации: Комментарии и описания метаданных часто опускаются при первоначальной развертке, что затрудняет понимание намерений конкретных столбцов позже.
Эти проблемы приводят к тому, что часто называют «спагетти-схемой». Связи становятся неявными, а не явными, а первичные ключи могут быть потеряны или дублированы в нескольких таблицах. В следующих разделах описан системный подход к решению этих проблем.
Этап 1: Обнаружение и анализ схемы 🔍
Прежде чем рисовать какие-либо линии, необходимо понять текущее состояние базы данных. На этом этапе акцент делается на извлечении и анализе, а не на модификации.
Извлечение метаданных
Каждая система управления реляционными базами данных поддерживает системные каталоги или представления схемы информации. Эти хранилища содержат сведения о таблицах, столбцах, типах данных, ограничениях и индексах. Используйте интерфейсы запросов для извлечения этих метаданных.
- Список таблиц: Получите все имена таблиц и их даты создания, чтобы выявить устаревшие структуры.
- Определения столбцов: Извлеките имена столбцов, типы данных, возможность NULL и значения по умолчанию.
- Ограничения: Определите первичные ключи, уникальные ограничения и связи внешних ключей. Обратите внимание, что некоторые связи могут быть реализованы только на уровне приложения, а не в базе данных.
- Индексы: Проанализируйте существующие индексы, чтобы понять паттерны производительности запросов и выявить потенциальные кандидаты на ключи.
Анализ данных
Метаданные говорят вам, какой должна быть схема, но анализ данных показывает, какой она *является*. Сканирование реальных значений данных выявляет несоответствия, которые не учитываются в определениях схемы.
- Распределение значений: Проверьте столбцы с высокой или низкой кардинальностью, которые могут указывать на необходимость нормализации.
- Нулевые значения:Высокая доля пустых значений в обязательных полях указывает на отсутствие ограничений или плохие практики ввода данных.
- Качество данных:Выявите несогласованности в форматировании, например, номера телефонов, хранящиеся как текст с различными форматами.
Фаза 2: Идентификация сущностей и нормализация 🧱
Как только исходные данные поняты, следующий шаг — логическая перестройка. Это включает в себя идентификацию сущностей и применение правил нормализации для уменьшения избыточности.
Идентификация сущностей
Сущность представляет собой отдельный объект или понятие в бизнес-области. В неупорядоченной базе данных сущности часто разбросаны по нескольким таблицам или неправильно объединены.
- Детализация: Убедитесь, что каждая таблица представляет собой одну концепцию. Если таблица содержит информацию о клиентах и заказах, она, скорее всего, нарушает принципы нормализации.
- Первичные ключи: Установите уникальный идентификатор для каждой сущности. Избегайте использования естественных ключей (например, адресов электронной почты), если они могут меняться; вместо этого используйте суррогатные ключи.
- Правила именования:Приведите имена таблиц к единообразному формату, например, в форме единственного числа (например,
клиентвместоклиенты).
Применение нормализации
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя цель не всегда заключается в достижении теоретического максимума (форма Бойса-Кодда), стремление к третьей нормальной форме (3НФ) является надежным стандартом для транзакционных систем.
| Форма | Определение | Цель |
|---|---|---|
| Первая нормальная форма (1НФ) | Атомарные значения в столбцах; отсутствие повторяющихся групп. | Убедитесь, что каждая ячейка содержит одно значение. |
| Вторая нормальная форма (2НФ) | Соответствует 1НФ и устраняет частичные зависимости. | Убедитесь, что атрибуты, не являющиеся ключевыми, зависят от всего первичного ключа. |
| Третья нормальная форма (3НФ) | Соответствует 2НФ и устраняет транзитивные зависимости. | Убедитесь, что неполевые атрибуты зависят только от первичного ключа. |
При обратном проектировании ищите столбцы, хранящие списки значений (например, строку с тегами, разделёнными запятыми). Их необходимо разбить на отдельные строки в промежуточной таблице, чтобы удовлетворить 1НФ. Аналогично, атрибуты, описывающие разные сущности (например, product_name и vendor_address в одной и той же таблице) должны быть разделены на отдельные сущности, чтобы удовлетворить 2НФ и 3НФ.
Этап 3: Сопоставление связей 🔗
Связи определяют, как взаимодействуют сущности. В неупорядоченной базе данных они часто являются неявными или отсутствуют. На этом этапе определяется кардинальность и необязательность этих связей.
Типы кардинальности
- Один к одному (1:1): Одна запись в таблице А связана с одной записью в таблице Б. Это редкость и часто указывает на разделение из соображений безопасности или производительности.
- Один ко многим (1:N): Одна запись в таблице А связана с несколькими записями в таблице Б. Это наиболее распространённая связь (например, один клиент размещает много заказов).
- Многие ко многим (M:N): Несколько записей в таблице А связаны с несколькими записями в таблице Б. Это требует промежуточной таблицы-связки (например, студенты и курсы).
Решение связей «многие ко многим»
Неупорядоченные базы данных часто пытаются обрабатывать связи «многие ко многим» путём дублирования данных или создания широких таблиц с несколькими столбцами внешних ключей. Правильный подход — введение мостовой таблицы.
- Определите две родительские сущности.
- Создайте новую таблицу, содержащую первичные ключи обоих родителей.
- Добавьте любые специфические атрибуты, связанные с самой связью (например,
enrollment_dateв мостовой таблице «Студент-Курс»).
Этап 4: Ограничения и целостность данных 🔒
Схема бесполезна, если она не обеспечивает соблюдение правил, которые она отображает. Физическая реализация должна отражать логический дизайн с помощью ограничений.
- Внешние ключи: Явно определите ограничения внешнего ключа, чтобы предотвратить появление «сиротских» записей. Это обеспечивает целостность ссылок автоматически.
- Ограничения уникальности: Примените ограничения уникальности к столбцам, которые должны быть уникальными (например, адреса электронной почты, имена пользователей).
- Ограничения проверки: Используйте проверочные ограничения для проверки форматов или диапазонов данных (например,
возраст >= 0). - Не пусто: Отметьте обязательные поля как
НЕ ПУСТОчтобы обеспечить полноту данных.
Этап 5: Визуализация ERD 🎨
Как только логическая модель будет создана, её необходимо визуализировать. Хотя для этого существуют специальные программы, принципы построения диаграмм остаются неизменными.
Стандарты построения диаграмм
Выберите стандарт нотации, чтобы обеспечить читаемость диаграммы различными заинтересованными сторонами.
- Нотация клювов (Crow’s Foot): Широко используется в промышленности. Использует специальные символы для обозначения кардинальности (например, одиночная линия для «одного», клюв для «многих»).
- Диаграммы классов UML: Использует прямоугольники и стрелки, часто предпочитается программистами, знакомыми с объектно-ориентированным проектированием.
- Нотация Чена: Использует ромбы для обозначения связей, распространено в академических кругах, но реже встречается в современных корпоративных инструментах.
Рекомендации по компоновке
- Группировка: Группируйте связанные таблицы вместе (например, все таблицы заказов в одной области), чтобы показать логические домены.
- Направление потока: Располагайте диаграммы так, чтобы они логически шли слева направо или сверху вниз.
- Читаемость: Убедитесь, что имена таблиц хорошо видны, а пересечения линий минимизированы.
Этап 6: Документирование и сопровождение 📝
Статическая диаграмма — это снимок. Чтобы обеспечить долгосрочную ценность, документация должна сопровождаться кодом.
Комментарии к схеме
Используйте комментарии к столбцам и таблицам для объяснения бизнес-логики. Например, столбец с именем статус должен иметь комментарий, объясняющий, какие значения являются допустимыми (например, «0: Ожидает, 1: Утверждено, 2: Отклонено»).
Система контроля версий
Храните ERD и файлы определения схемы в системе контроля версий. Это позволяет отслеживать изменения во времени и возвращаться к предыдущей версии при необходимости.
Распространённые антишаблоны, которые следует избегать 🚫
Во время процесса очистки будьте бдительны по отношению к распространённым ловушкам.
| Антишаблон | Проблема | Решение |
|---|---|---|
| Общие столбцы данных | Использование столбцов, таких какcol1, col2 для гибкого хранения данных. |
Замените на столбец JSON или новую таблицу сущностей. |
| Составные ключи | Использование нескольких столбцов в качестве первичного ключа. | Предпочитайте искусственные ключи (автоинкрементные целые числа) для простоты. |
| Денормализация для повышения скорости | Дублирование данных для избежания соединений. | Примите стоимость производительности соединений, если профилирование не доказывает обратное. |
Этап 7: Проверка и тестирование ✅
После переустройства новая схема должна быть проверена на соответствие существующим данным.
- Скрипты миграции: Напишите скрипты для переноса данных из старой схемы в новую. Убедитесь, что при переносе не будет потеряно никаких данных.
- Проверки целостности ссылок: Запустите запросы, чтобы убедиться, что все внешние ключи указывают на действительные родительские записи.
- Тестирование производительности: Запустите приложение на новой схеме, чтобы убедиться, что производительность запросов остается приемлемой.
- Обзор заинтересованных сторон: Представьте диаграмму бизнес-пользователям, чтобы подтвердить, что она точно отражает их процессы.
Заключительные соображения 🏁
Обратная разработка базы данных — это значительный труд, требующий терпения и точности. Это не разовое задание, а часть непрерывного цикла управления данными. Следуя структурированному подходу, организации могут превратить хаотичные хранилища данных в надежные активы.
Помните, что диаграмма — это инструмент коммуникации. Если бизнес-заинтересованные стороны не могут понять изображенные на ней отношения, технические усилия не достигли полного успеха. Регулярные обзоры схемы обеспечивают соответствие будущей разработки установленной архитектуре.
Сосредоточьтесь на согласованности. Независимо от того, идет ли речь о соглашениях об именовании, определениях ограничений или стилях диаграмм, единообразие снижает когнитивную нагрузку для всех, кто взаимодействует с системой. Начните с малого. Выберите один модуль или область, приведите его в порядок и тщательно документируйте. Затем расширьте процесс на другие области. Такой поэтапный подход снижает риски и позволяет добиваться непрерывного улучшения.
В конечном счете, чистая структура ERD является основой надежной стратегии управления данными. Она позволяет разработчикам быстрее создавать функции и снижает вероятность потери или повреждения данных. Вложите время сейчас, чтобы в будущем получить выгоду от стабильности и ясности.

