











Construir uma arquitetura de backend robusta exige mais do que apenas escrever código eficiente; exige uma compreensão fundamental de como os dados são estruturados, armazenados e recuperados sob pressão. No centro dessa infraestrutura está o Diagrama de Relacionamento de Entidades (ERD). Embora frequentemente tratado como um plano estático criado durante a fase inicial de planejamento, um ERD bem projetado serve como a estrutura dinâmica de sistemas de alta tração. Quando há picos de tráfego, o esquema do banco de dados determina o desempenho, a latência e a disponibilidade. Um modelo mal estruturado pode levar a falhas em cadeia, enquanto um design escalável acomoda o crescimento de forma transparente.
Este guia explora os detalhes técnicos da construção de diagramas ER que suportam cargas pesadas. Vamos além da normalização básica e examinaremos como relacionamentos, restrições e estratégias de armazenamento físico interagem em ambientes distribuídos. Se você está projetando para milhões de usuários simultâneos ou simplesmente planejando expansão futura, os princípios apresentados aqui fornecem uma estrutura para modelagem de dados resiliente.
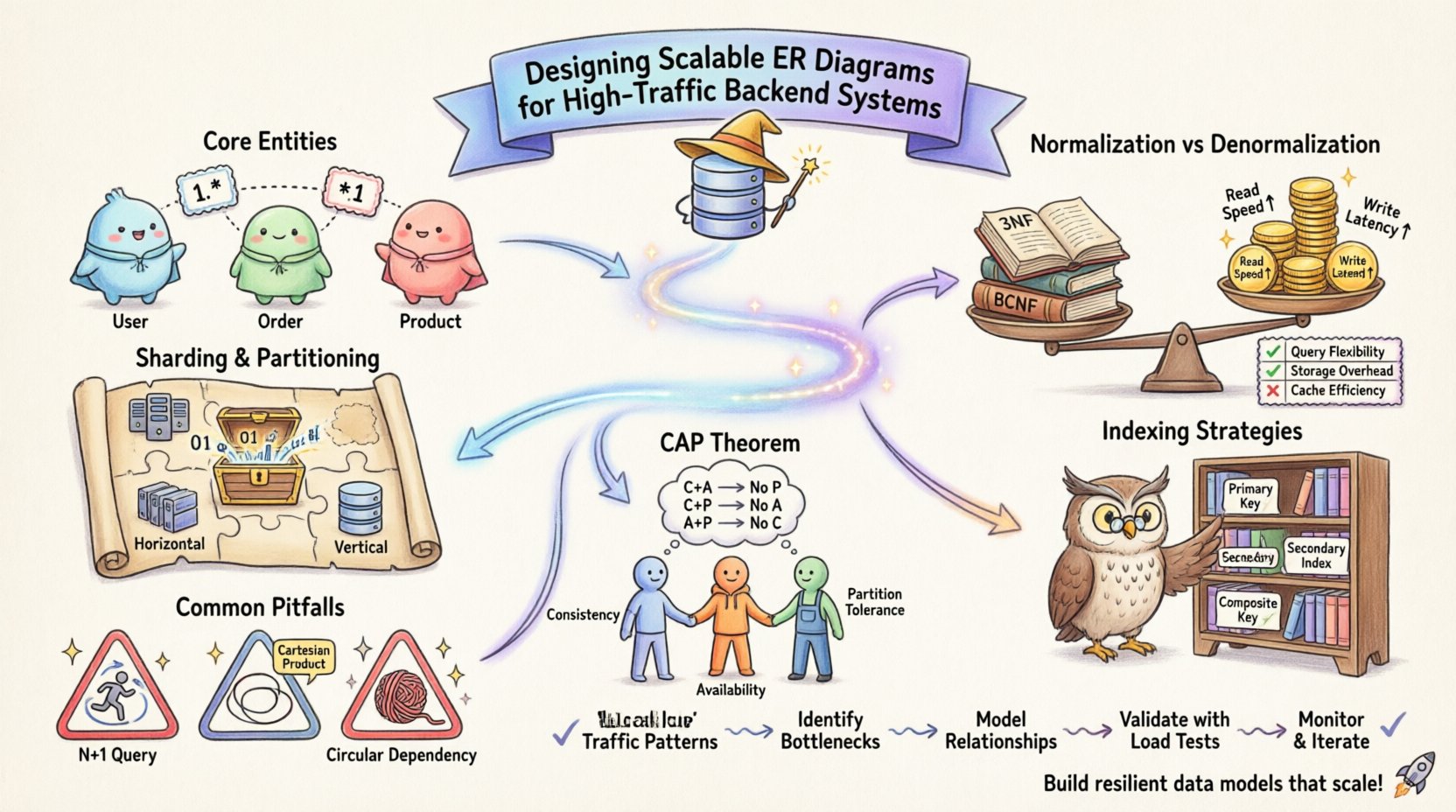
🏗️ Compreendendo o Modelamento de Relacionamento de Entidades em Escala
A unidade fundamental de um diagrama ER é a entidade, representando um objeto ou conceito distinto dentro do seu sistema. Em um ambiente de baixa tração, a simplicidade geralmente reina soberana. No entanto, à medida que os volumes de transações aumentam, a complexidade das interações entre entidades cresce exponencialmente. Sistemas de alta tração exigem uma mudança de perspectiva, de ‘como essa data deve parecer?’ para ‘como esse dado se comportará sob carga?’
- Identifique Entidades Principais: Determine quais objetos de dados são acessados com mais frequência. São os seus caminhos críticos.
- Analise a Cardinalidade: Defina as relações entre entidades. Relações um-para-muitos, muitos-para-muitos e um-para-um têm implicações de desempenho diferentes.
- Granularidade dos Atributos: Decida quanta detalhamento armazenar em um atributo. Atributos excessivamente granulares podem aumentar o tamanho das linhas, enquanto atributos excessivamente amplos podem dificultar a especificidade das consultas.
Ao projetar para escala, a disposição física dos dados torna-se tão importante quanto a estrutura lógica. O ERD deve refletir não apenas a lógica de negócios, mas também as restrições operacionais do motor de armazenamento. Por exemplo, alguns sistemas lidam com bloqueios em nível de linha de forma diferente dos bloqueios em nível de página. Seu diagrama deve antecipar essas restrições minimizando pontos de contenção.
📊 Normalização vs. Denormalização: O Trade-off de Desempenho
A normalização é o processo de organizar dados para reduzir redundâncias e melhorar a integridade. Embora tradicionalmente ensinada como uma melhor prática universal, sistemas de alta tração frequentemente exigem uma abordagem equilibrada. A aderência rígida à Terceira Forma Normal (3FN) pode introduzir operações de junção excessivas. Em um ambiente distribuído ou de alta concorrência, junções entre múltiplas tabelas podem se tornar gargalos significativos.
Por outro lado, a denormalização envolve a duplicação de dados para reduzir a necessidade de junções. Essa estratégia melhora o desempenho de leitura, mas complica as operações de escrita. Você deve manter a consistência entre campos duplicados, o que adiciona lógica à camada de aplicação.
| Estratégia | Desempenho de Leitura | Desempenho de Escrita | Consistência dos Dados | Custo de Armazenamento |
|---|---|---|---|---|
| Normalização Completa | Baixo (Múltiplas Junções) | Alto (Escrita Única) | Alta | Baixo |
| Denormalização Parcial | Alto (Menos Junções) | Moderado (Atualização de Duplicação) | Moderado | Moderado |
| Denormalização Total | Muito Alto | Baixo (Lógica Complexa) | Baixo (Requer Sincronização) | Alto |
Escolher o equilíbrio certo depende da sua razão de leitura para escrita. Se o seu sistema é intensivo em leituras, como um feed de conteúdo ou uma plataforma de notícias, a denormalização é frequentemente necessária. Se o seu sistema é intensivo em escritas, como um livro de registros de transações, a normalização ajuda a prevenir anomalias.
🌐 Estratégias para Otimização de Leitura e Escrita
Otimizar para alto tráfego envolve técnicas específicas que influenciam a forma do seu ERD. Essas estratégias focam em reduzir o tempo necessário para buscar ou armazenar informações.
1. Estratégias de Cache Refletidas no Esquema
Ao projetar seu modelo de dados, considere como os dados serão armazenados em cache. Entidades frequentemente acessadas devem ser estruturadas para permitir uma serialização fácil. Evite armazenar grandes blobs de comprimento variável em tabelas que são frequentemente unidas. Em vez disso, armazene uma chave de referência e recupere o blob separadamente quando necessário. Isso reduz a pressão de memória na camada principal de cache.
2. Chaves de Particionamento e Sharding
À medida que os dados crescem, o armazenamento em uma única tabela torna-se ineficiente. O sharding divide os dados entre múltiplos nós. Seu ERD deve definir claramente uma chave de sharding. Essa chave determina como as linhas são distribuídas. Se a chave de sharding for escolhida de forma inadequada, você pode acabar com ‘partições quentes’, em que um nó processa significativamente mais tráfego do que os outros.
- Sharding Horizontal: Divide as linhas com base em uma chave. O ERD deve mostrar como a chave é distribuída.
- Sharding Vertical: Divide as colunas entre tabelas. Útil para separar colunas pesadas (como logs) dos dados transacionais principais.
🔗 Gerenciando Relacionamentos em Dados Particionados
Relacionamentos são a cola que mantém o banco de dados unido, mas em um sistema distribuído, eles podem se tornar uma fonte de latência. Chaves estrangeiras garantem a integridade referencial, mas em um ambiente particionado, impor essas restrições entre nós é caro.
Gerenciando Relacionamentos Muitos para Muitos
Relacionamentos muitos para muitos exigem uma tabela de junção. Em um cenário de alto tráfego, essa tabela pode se tornar um gargalo. Se você consulta com frequência, considere a denormalização do relacionamento. Em vez de fazer uma junção com a tabela de junção, armazene o ID do relacionamento diretamente na entidade pai, se a cardinalidade permitir. Isso reduz a profundidade da consulta.
Entidades Auto-Referenciadas
Algumas entidades se referem a si mesmas, como categorias ou comentários hierárquicos. Projete esses relacionamentos com cuidado. Recursão profunda em consultas pode esgotar os recursos do sistema. Limite a profundidade das cadeias de referência auto-referenciadas na sua lógica, ou aplane a estrutura quando possível usando caminhos materializados.
🔍 Estratégias de Indexação para Desempenho
Um ERD define a estrutura lógica, mas os índices definem a velocidade de recuperação física. Embora o diagrama em si não mostre índices, as decisões de design afetam quais índices são viáveis.
- Chaves Primárias: Em muitos sistemas, são agrupados, o que significa que os dados são fisicamente ordenados por essa chave. Escolha uma chave primária que minimize a fragmentação e garanta uma distribuição uniforme.
- Índices Secundários: Cada índice consome desempenho de escrita. Adicionar muitos índices torna mais lento os operações de inserção e atualização. Índice apenas colunas que são frequentemente usadas em cláusulas `WHERE`, `JOIN` ou `ORDER BY`.
- Índices Compostos: Quando múltiplas colunas são consultadas juntas, um índice composto pode ser mais eficiente. A ordem das colunas no índice é importante e deve corresponder aos padrões de consulta mais comuns.
⚖️ Consistência vs Disponibilidade em Esquemas Distribuídos
A teoria de bancos de dados frequentemente discute o teorema CAP, que sugere que um sistema só pode garantir duas das três propriedades: Consistência, Disponibilidade e Tolerância a Partições. O seu design de ERD influencia qual dessas propriedades você prioriza.
Se você priorizar a consistência, irá projetar com chaves estrangeiras rígidas e transações ACID. Isso garante a integridade dos dados, mas pode introduzir latência durante partições de rede. Se você priorizar a disponibilidade, pode relaxar as restrições, permitindo inconsistências temporárias. Nesse caso, o seu ERD deve apoiar padrões de consistência eventual, como ter uma coluna “versão” ou “status” para rastrear o estado dos dados.
🔄 Evolução e Versionamento de Esquemas
Requisitos de software mudam. O esquema do banco de dados deve evoluir sem causar tempo de inatividade. Em sistemas de alta carga, você não pode simplesmente descartar e recrear tabelas. Estratégias de migração devem ser incorporadas ao processo de design do ERD.
- Compatibilidade com versões anteriores: Ao adicionar uma coluna, torne-a nula inicialmente. Isso permite que o código antigo continue funcionando enquanto o novo código preenche os dados.
- Tipos Expansíveis: Evite tipos de comprimento fixo sempre que possível. Use strings de comprimento variável ou campos JSON para atributos que podem mudar de estrutura ao longo do tempo.
- Exclusão Lógica: Em vez de excluir fisicamente linhas, marque-as como inativas. Isso preserva a integridade referencial para dados históricos e evita operações de exclusão em cascata que podem bloquear grandes partes da tabela.
🛑 Armadilhas Estruturais Comuns
Mesmo arquitetos experientes enfrentam armadilhas ao escalar. Estar ciente desses problemas comuns pode poupar muito tempo na fase de design.
1. O Problema da Consulta N+1
Isso ocorre quando um aplicativo recupera uma lista de registros e depois executa uma consulta separada para cada registro para buscar dados relacionados. No seu ERD, identifique relacionamentos que são frequentemente acessados juntos. Se você antecipa que dados relacionados serão buscados com frequência, considere a desnormalização ou a criação de visualizações específicas para leitura.
2. Produtos Cartesianos
Quando unir múltiplas tabelas grandes sem filtragem adequada, o conjunto de resultados pode crescer exponencialmente. Certifique-se de que o seu ERD impeça restrições que limitam o tamanho potencial dos resultados de junção. Use filtros em chaves estrangeiras para restringir o escopo dos relacionamentos.
3. Dependências Circulares
Entidades não devem depender umas das outras em um ciclo. Por exemplo, a Entidade A precisa da Entidade B, e a Entidade B precisa da Entidade A para inicializar. Isso cria uma situação de deadlock durante a inicialização ou carregamento de dados. Quebre esses ciclos introduzindo uma entidade intermediária ou inicializando os dados em uma ordem específica.
📝 Manutenção e Monitoramento
O design não é um evento único. Uma vez que o sistema esteja em funcionamento, você deve monitorar a saúde da sua estrutura de dados. Métricas de desempenho devem orientar ajustes futuros do ERD.
- Análise de Consultas: Revise regularmente os logs de consultas lentas. Se uma junção específica for consistentemente lenta, revise o ERD para verificar se o relacionamento pode ser otimizado.
- Verificações de Fragmentação: Com o tempo, exclusões e atualizações podem fragmentar o armazenamento. Planeje janelas de manutenção onde índices sejam reconstruídos ou tabelas sejam otimizadas.
- Planejamento de Capacidade: À medida que os dados crescem, os requisitos de armazenamento mudam. Estime a taxa de crescimento das suas maiores tabelas e planeje o shard ou particionamento antes de atingir os limites de capacidade.
🛠️ Aplicação Prática: Um Fluxo Escalável
Para implementar esses princípios, siga um fluxo estruturado ao criar o seu diagrama.
- Coleta de Requisitos: Defina a proporção de leitura/gravação e os padrões de tráfego esperados.
- Modelagem Lógica:Crie o diagrama ERD focando nas entidades e relacionamentos de negócios, sem se preocupar com restrições físicas.
- Modelagem Física:Traduza o modelo lógico em um esquema físico. Adicione índices, defina tipos de dados e considere estratégias de particionamento.
- Revisão e Validação:Simule consultas de alto tráfego contra o modelo. Identifique gargalos potenciais em junções ou bloqueios.
- Documentação:Documente o raciocínio por trás das escolhas de design. Isso ajuda desenvolvedores futuros a entenderem por que um nível específico de normalização foi escolhido.
🔮 Futurizando sua Arquitetura
A tecnologia evolui rapidamente. O que funciona hoje pode não funcionar daqui a cinco anos. Projete com flexibilidade em mente. Evite vincular seu esquema muito fortemente a um recurso específico do motor de armazenamento que possa se tornar obsoleto. Foque nas relações lógicas e nas regras de integridade dos dados, pois essas permanecem constantes mesmo quando a tecnologia subjacente muda.
Ao seguir estas diretrizes, você cria um modelo de dados que não é apenas funcional para as necessidades atuais, mas também resistente o suficiente para lidar com a imprevisibilidade de ambientes de alto tráfego. O objetivo é construir um sistema que performe de forma consistente, escale horizontalmente e permaneça mantido ao longo do tempo.

