











जब एक कागज पर डिज़ाइन की गई डेटाबेस आर्किटेक्चर सैंडबॉक्स में बिना किसी त्रुटि के काम करती है, लेकिन वास्तविक दुनिया के ट्रैफिक के तहत ढह जाती है, तो अक्सर दृश्य मॉडल और रनटाइम वास्तविकता के बीच अंतर होता है। एक एंटिटी रिलेशनशिप डायग्राम (ईआरडी) एक नक्शा है, एक जीवित इंजन नहीं। हालांकि, जब डेवलपर्स एक “ईआरडी के लोड के तहत विफल होने” की बात करते हैं, तो वे आमतौर पर उस डायग्राम से निकले डिज़ाइन वाले स्कीमा के बारे में बात कर रहे होते हैं जो उत्पादन की आवश्यकताओं को संभाल नहीं पाता है। यह गाइड संरचनात्मक, तार्किक और प्रदर्शन की बाधाओं के बारे में बताता है जो डेटा के आयतन और समानांतरता में वृद्धि के साथ संबंधात्मक मॉडल को कठिनाई में डालती हैं।
इन समस्याओं का निदान करने के लिए डेटा संबंधों के आईओ ऑपरेशन, लॉक प्रतिस्पर्धा और मेमोरी उपयोग में कैसे बदलते हैं, इसकी गहन समझ आवश्यक है। हम उन घर्षण बिंदुओं का अध्ययन करेंगे जहां डिज़ाइन चयनों का टकराव हार्डवेयर की सीमाओं और ट्रैफिक पैटर्न के साथ होता है। संरचनात्मक विफलता के विशिष्ट लक्षणों को पहचानकर, आप अपने डेटा मॉडल को पुनर्गठित कर सकते हैं ताकि स्केल को समर्थन दिया जा सके बिना डेटा अखंडता को नुकसान पहुंचाए बिना।
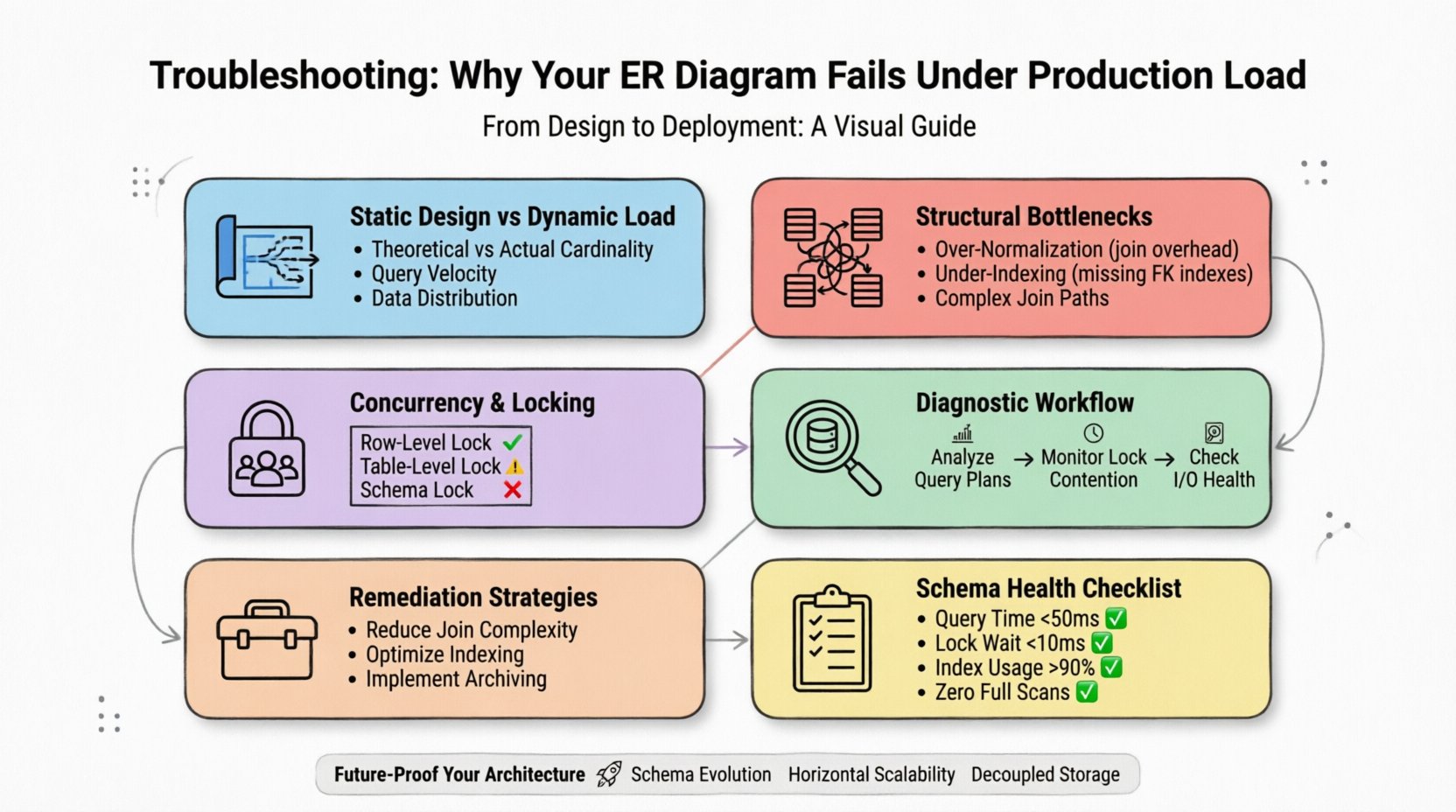
1. स्थिर डिज़ाइन और डायनामिक लोड के बीच का अंतर ⚡
एक ईआर डायग्राम संभावित संबंधों और डेटा प्रकारों का प्रतिनिधित्व करता है। इसमें लेखन की गति, पढ़ने का वितरण या आधारभूत इंजन की भौतिक स्टोरेज सीमाओं को ध्यान में नहीं रखा जाता है। एक ऐसा मॉडल जो व्हाइटबोर्ड पर संतुलित लगता है, वह अक्सर अनुप्रयोगों के बाहर दिखाई देने वाली अक्षमताओं को छिपाता है जो कि लाखों पंक्तियों को एक साथ प्रश्न करने पर ही प्रकट होती हैं।
- सैद्धांतिक बनावट बनाम वास्तविक बनावट:डायग्राम एक-से-एक या एक-से-बहुत के संबंधों के बारे में मानते हैं। उत्पादन में, इन्हें अक्सर बहुत-से-बहुत के रूप में बदल दिया जाता है, जिसमें जटिल जॉइन पथ होते हैं जो सीपीयू संसाधनों को खत्म कर देते हैं।
- प्रश्न गति:एक स्कीमा प्रति सेकंड कुछ हजार पढ़ाई को संभाल सकता है, लेकिन लॉक विभाजन के कारण प्रति मिलीसेकंड हजारों पर रुक जाता है।
- डेटा वितरण:जब डेटा स्टोरेज नोड्स के बीच समान रूप से वितरित नहीं होता है, तो हॉटस्पॉट उत्पन्न होते हैं, जिससे असमान लोड बैलेंसिंग होती है।
प्रभावी रूप से निदान करने के लिए, आपको स्कीमा को एक स्थिर वस्तु के रूप में नहीं देखना चाहिए। यह एक गतिशील संसाधन है जिसे सर्वर के समान निरीक्षण की आवश्यकता होती है।
2. सामान्य संरचनात्मक बाधाएं 📉
प्रदर्शन में गिरावट का सबसे आम कारण संबंध संरचना ही है। टेबल्स कैसे जुड़ते हैं, इससे इंजन डेटा को कैसे तय करता है। जटिल जॉइन धीमी प्रश्न निष्पादन समय के मुख्य कारण हैं।
2.1 अत्यधिक सामान्यीकरण के जोखिम
जबकि सामान्यीकरण अतिरेक को कम करता है, अत्यधिक सामान्यीकरण एक ही डेटासेट को प्राप्त करने के लिए आवश्यक जॉइन की संख्या बढ़ा देता है। उच्च लोड वाले परिदृश्यों में, प्रत्येक जॉइन एक संभावित विफलता का बिंदु हो सकता है।
- जॉइन ओवरहेड:प्रत्येक जॉइन ऑपरेशन के लिए डेटाबेस को दो टेबलों से पंक्तियों का मिलान करने की आवश्यकता होती है। यदि इन टेबलों का आकार बड़ा है और उनमें उचित इंडेक्स नहीं हैं, तो इंजन पूरी टेबल स्कैन करता है।
- लेनदेन की गहराई:गहन रूप से सामान्यीकृत स्कीमा अक्सर संबंधित डेटा प्राप्त करने के लिए लंबे समय तक चलने वाले लेनदेन की आवश्यकता महसूस करते हैं, जिससे लॉक लंबे समय तक रखे जाते हैं।
- कैश प्रभावशीलता:सामान्यीकृत डेटा कई पेजों पर बिखरा होता है, जिससे बफर पूल कैशिंग की प्रभावशीलता कम हो जाती है।
2.2 अपर्याप्त इंडेक्सिंग और पहुंच मार्ग
एक अच्छी तरह से बनाए गए ईआरडी में पहुंच पैटर्न का अनुमान होता है। यदि डायग्राम वास्तविक प्रश्न लोड के साथ मेल नहीं खाता है, तो डेटाबेस इंजन डेटा तक पहुंचने के लिए सबसे तेज रास्ता नहीं ढूंढ पाता है।
- विदेशी कुंजी इंडेक्स:विदेशी कुंजियों में अक्सर इंडेक्स की कमी होती है, जिससे माता-पिता रिकॉर्ड को हटाने या अपडेट करने पर प्रदर्शन में गिरावट आती है।
- मिश्रित कुंजी का क्रम:मिश्रित इंडेक्स में कॉलम के क्रम का महत्व होता है। यदि प्रश्न पहले दूसरे कॉलम पर फ़िल्टर करते हैं, तो इंडेक्स को नजरअंदाज कर दिया जा सकता है।
- चयनात्मक इंडेक्स की कमी:उच्च कार्डिनैलिटी वाले कॉलम पर इंडेक्स के बिना, इंजन पूरी टेबल को स्कैन करता है ताकि विशिष्ट मान ढूंढे जा सकें।
3. समानांतरता और लॉकिंग तंत्र 🔒
जब लोड बढ़ता है, तो समानांतरता प्राथमिक सीमा बन जाती है। एक ही डेटा को संपादित करने की कोशिश करने वाले बहुत से उपयोगकर्ता संघर्ष पैदा करते हैं। यदि स्कीमा डिज़ाइन में लॉक विभाजन को ध्यान में नहीं रखा गया है, तो प्रणाली डेडलॉक या समय सीमा समाप्त हो जाती है।
| लॉक प्रकार | लोड पर प्रभाव | सामान्य लक्षण |
|---|---|---|
| पंक्ति-स्तर लॉक | न्यूनतम प्रभाव, उच्च समानांतरता | कम लेटेंसी, उच्च थ्रूपुट |
| तालिका-स्तर लॉक | उच्च प्रभाव, अन्य उपयोगकर्ताओं को रोकता है | समय सीमा त्रुटियाँ, लटकते हुए प्रश्न |
| स्कीमा लॉक | DDL के दौरान सभी पहुँच को रोकता है | रखरखाव के दौरान प्रणाली-स्तर का बंद होना |
3.1 डेडलॉक और दौड़ स्थितियाँ
डेडलॉक तब होते हैं जब दो लेनदेन एक दूसरे के संसाधन छोड़ने का इंतजार करते हैं। यह अक्सर ऐप्लिकेशन लॉजिक में असंगत लॉकिंग क्रम के कारण होता है, जो स्कीमा के साथ बातचीत करता है।
- लेनदेन अलगाव स्तर: उच्च अलगाव स्तर (जैसे Serializable) सुरक्षा प्रदान करते हैं, लेकिन समानांतरता को काफी कम कर देते हैं।
- लॉक वृद्धि: यदि एक लेनदेन बहुत सारी पंक्तियों को लॉक करता है, तो इंजन तालिका लॉक पर बढ़ सकता है, जिससे सभी अन्य संचालन रोक दिए जाते हैं।
- लंबे समय तक चलने वाले लेनदेन: सेकंड के बजाय मिलीसेकंड के लिए लॉक रखने वाले संचालन पूरी कतार के लिए बॉटलनेक बन जाते हैं।
4. डेटा आयतन और पार्टीशनिंग रणनीतियाँ 📊
जैसे-जैसे डेटा बढ़ता है, स्टोरेज लेयर की भौतिक सीमाएँ स्पष्ट हो जाती हैं। 10,000 पंक्तियों के लिए काम करने वाला एक स्कीमा 10 करोड़ पंक्तियों के साथ आपदाग्रस्त रूप से विफल हो सकता है। पार्टीशनिंग बड़ी तालिकाओं को छोटे, प्रबंधनीय टुकड़ों में विभाजित करने के लिए उपयोग की जाने वाली विधि है।
- उर्ध्वाधर पार्टीशनिंग: दुर्लभ रूप से पहुँचे जाने वाले कॉलम को अलग तालिका में स्थानांतरित करने से मुख्य तालिका का आकार कम होता है, जिससे गर्म डेटा के लिए कैश हिट दर में सुधार होता है।
- क्षैतिज पार्टीशनिंग: बहुत से भौतिक सेगमेंट (शार्डिंग) में पंक्तियों को विभाजित करना लोड को बहुत से स्टोरेज नोड्स पर वितरित करता है।
- समय-आधारित पार्टीशनिंग: लेनदेन डेटा के लिए, तारीख द्वारा पार्टीशनिंग इंजन को पुराने पार्टीशन को तुरंत ड्रॉप करने की अनुमति देती है बिना पूरी तालिका को लॉक किए।
5. उत्पादन विफलताओं के लिए निदान कार्यप्रवाह 🔍
जब प्रणाली धीमी हो जाती है, तो जड़ कारण को पहचानने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। यादृच्छिक अनुकूलन अक्सर संसाधनों का व्यर्थ करता है। समस्या को सटीक रूप से निर्धारित करने के लिए इस कार्यप्रवाह का पालन करें।
5.1 प्रश्न क्रियान्वयन योजनाओं का विश्लेषण करें
क्रियान्वयन योजना यह बताती है कि डेटाबेस इंजन डेटा को कैसे प्राप्त करने की योजना बना रहा है। अक्षमता के विशिष्ट संकेतों को देखें।
- पूर्ण तालिका स्कैन:एक अनुपस्थित सूचीकरण या बहुत अधिक डेटा मांगने वाले प्रश्न को इंगित करता है।
- की खोजें:इंजन को निरंतर सूचीकरण और तालिका डेटा के बीच कूदना पड़ता है, जिससे I/O बढ़ता है।
- क्रमबद्ध क्रियाएँ:बड़े परिणाम सेटों को क्रमबद्ध करने में महत्वपूर्ण मेमोरी और CPU का उपयोग होता है।
5.2 लॉक प्रतिस्पर्धा का निरीक्षण करें
प्रतीक्षा घटनाओं को निरीक्षण करने के लिए प्रणाली उपकरणों का उपयोग करें। लॉक पर उच्च प्रतीक्षा समय इंगित करता है कि स्कीमा वर्तमान समानांतरता स्तर को समर्थित नहीं कर सकता है।
- प्रतीक्षा समय मापदंड:संसाधनों के लिए प्रतीक्षा करने वाले लेनदेन के अवधि को ट्रैक करें।
- डेडलॉक ग्राफ:संघर्ष करने वाले किन प्रश्नों को देखने के लिए ऐतिहासिक डेटा की समीक्षा करें।
- लॉक प्रतीक्षा रेखा:एक ही संसाधन के लिए प्रतीक्षा कर रहे लेनदेनों की संख्या को निरीक्षण करें।
5.3 I/O उपप्रणाली के स्वास्थ्य की जांच करें
यहां तक कि एक सही स्कीमा के साथ भी, धीमी स्टोरेज विफलता का कारण बनेगी। सुनिश्चित करें कि आधारभूत ढांचा डेटा पहुंच पैटर्न के अनुरूप है।
- थ्रूपुट सीमाएं:जांचें कि स्टोरेज उपकरण पढ़ने/लिखने के कार्यों से संतृप्त है या नहीं।
- लेटेंसी शिखर:स्टोरेज लेयर से अस्थिर प्रतिक्रिया समय अक्सर हार्डवेयर के घटते हुए गुणवत्ता को इंगित करते हैं।
- बफर पूल की कार्यक्षमता:यदि डेटाबेस डिस्क से पढ़ने में मेमोरी की तुलना में अधिक समय बिताता है, तो स्कीमा या डेटा आयतन कैश के लिए बहुत बड़ा है।
6. स्कीमा अनुकूलन के लिए उपचार रणनीतियां 🛠️
जब बफलेट को पहचान लिया जाता है, तो लक्षित परिवर्तन लागू करें। उत्पादन स्कीमा के पुनर्गठन के लिए सावधानी बरतने की आवश्यकता होती है ताकि डेटा हानि या बंदी को रोका जा सके।
6.1 जॉइन की जटिलता को कम करना
वे संबंध सरल करें जो सबसे अधिक घर्षण उत्पन्न करते हैं। इसमें आमतौर पर मॉडल के विशिष्ट क्षेत्रों को अनियमित बनाना शामिल होता है।
- सामग्री दृश्य:जटिल जॉइन की पूर्व-गणना करें और परिणाम को तेजी से प्राप्त करने के लिए अलग तालिका में संग्रहीत करें।
- गणना वाले कॉलम:प्रश्न समय पर गणना करने से बचने के लिए व्युत्पन्न डेटा को सीधे तालिका में संग्रहीत करें।
- पठन-प्रतिकृति रूटिंग:पठन-भारी प्रश्नों को एक प्रतिकृति में भेजें जो डेटा की अनियमित प्रतिलिपि रखती है।
6.2 इंडेक्सिंग रणनीति को अनुकूलित करना
इंडेक्स लुकअप को तेज करने के लिए सबसे प्रभावी उपकरण हैं, लेकिन लेखन संचालन पर उनकी लागत होती है।
- फ़िल्टर्ड इंडेक्स:केवल उन डेटा उपसमूहों पर इंडेक्स बनाएं जिन्हें अक्सर प्रश्न किया जाता है।
- कवरिंग इंडेक्स:मुख्य तालिका तक पहुंचने से बचने के लिए प्रश्न के लिए आवश्यक सभी कॉलम को इंडेक्स में शामिल करें।
- इंडेक्स रखरखाव:अक्सर अपडेट के कारण होने वाले टुकड़े बनने से बचने के लिए इंडेक्स को नियमित रूप से पुनर्निर्माण या पुनर्व्यवस्थित करें।
6.3 नरम हटाने और संग्रहण कार्यान्वयन करना
सक्रिय डेटा ऐतिहासिक डेटा की तुलना में तेजी से प्रश्न किया जा सकता है। प्राथमिक तालिका से पुराने डेटा को हटाने से प्रदर्शन में सुधार होता है।
- संग्रहण तालिकाएं:एक निश्चित सीमा से पुराने रिकॉर्ड को अलग, ठंडे स्टोरेज लेयर में स्थानांतरित करें।
- नरम हटाना:रिकॉर्ड को हटाए बिना उन्हें हटाए गए के रूप में चिह्नित करें, ताकि तालिका संरचना स्थिर रहे और डेटा तार्किक रूप से छिपा रहे।
- डेटा रखरखाव नीतियां:अनावश्यक डेटा को साफ करने के लिए स्वचालन करें ताकि अनियंत्रित वृद्धि से बचा जा सके।
7. स्कीमा स्वास्थ्य के लिए मूल्यांकन चेकलिस्ट ✅
परिवर्तनों को डेप्लॉय करने से पहले, अपने मॉडल की इन मानदंडों के अनुसार जांच करें ताकि यह यह सुनिश्चित किया जा सके कि यह उत्पादन तनाव को संभाल सकता है।
| मानदंड | पास की स्थिति | असफलता की स्थिति |
|---|---|---|
| औसत प्रश्न समय | < 50 मिलीसेकंड | > 500 मिलीसेकंड |
| लॉक वेट समय | < 10ms | > 100ms |
| インडेक्स उपयोग | > 90% | < 50% |
| पूर्ण टेबल स्कैन | शून्य | अक्सर |
इन मापदंडों के खिलाफ अपने डेटा मॉडल का नियमित रूप से ऑडिट करना सुनिश्चित करता है कि डिज़ाइन आपकी व्यापार आवश्यकताओं के साथ विकसित होता रहे। एक स्थिर स्कीमा अंततः एक दोष के रूप में बन जाएगा। विश्वसनीयता बनाए रखने का एकमात्र तरीका निरंतर मॉनिटरिंग और धीरे-धीरे समायोजन है।
8. प्रश्न पैटर्न और वर्कलोड को समझना 📈
प्रदर्शन केवल स्कीमा के बारे में नहीं है; यह उस स्कीमा के उपयोग के तरीके के बारे में है। मॉडल को ट्यून करने के लिए वर्कलोड प्रोफाइल को समझना आवश्यक है।
- OLTP बनाम OLAP:ऑनलाइन ट्रांजैक्शन प्रोसेसिंग (OLTP) को तेज, छोटे लेखन की आवश्यकता होती है। ऑनलाइन एनालिटिकल प्रोसेसिंग (OLAP) को तेज, बड़े पाठ की आवश्यकता होती है। एक के लिए अनुकूलित स्कीमा अक्सर दूसरे के साथ समस्या उत्पन्न करती है।
- लेखन भारी पैटर्न: यदि आपका एप्लिकेशन अक्सर लिखता है, तो इंडेक्स की कार्यक्षमता को प्राथमिकता दें और लेखन पर लॉकिंग को न्यूनतम करें।
- पढ़ने भारी पैटर्न: यदि आपका एप्लिकेशन अक्सर पढ़ता है, तो कैशिंग रणनीतियों और रीड-रिप्लिका को प्राथमिकता दें।
9. डेटाबेस प्रदर्शन में एप्लिकेशन तर्क की भूमिका 💻
अक्सर, दोष डेटाबेस में नहीं होता है, बल्कि एप्लिकेशन के इससे बातचीत करने के तरीके में होता है। N+1 प्रश्न समस्याएं एप्लिकेशन स्तरीय अक्षमता का एक प्राचीन उदाहरण है जो डेटाबेस विफलता के रूप में प्रकट होती है।
- बल्क ऑपरेशन:हजारों अलग-अलग इन्सर्ट स्टेटमेंट भेजना एकल बैच ऑपरेशन की तुलना में धीमा होता है।
- लेजी लोडिंग:छोटे टुकड़ों में डेटा लाने से डेटाबेस के लिए अत्यधिक राउंड-ट्रिप्स उत्पन्न हो सकते हैं।
- कनेक्शन पूलिंग:डेटाबेस कनेक्शन के अक्षम प्रबंधन के कारण शीर्ष भार के दौरान उपलब्ध संसाधनों का उपयोग कर लिया जा सकता है।
एप्लिकेशन स्तर को अनुकूलित करने से स्कीमा पर दबाव कम होता है, जिससे डेटाबेस अपने डिज़ाइन के अनुरूप काम करने में सक्षम होता है।
10. अपनी डेटा संरचना को भविष्य के लिए सुरक्षित बनाना 🚀
भविष्य के लिए डिज़ाइन करने के लिए वृद्धि की अनुमान लगाने की आवश्यकता होती है। आप निश्चित ट्रैफिक संख्या का अनुमान नहीं लगा सकते, लेकिन लचीलापन के लिए डिज़ाइन कर सकते हैं।
- स्कीमा विकास: डेटा मॉडल में बिना बाधा के बदलाव की अनुमति देने वाली माइग्रेशन रणनीतियों का उपयोग करें।
- क्षैतिज स्केलेबिलिटी: शार्डिंग को शुरू से ही समर्थन करने के लिए तालिकाओं को डिज़ाइन करें।
- अलग किए गए स्टोरेज: उन्हें स्वतंत्र रूप से स्केल करने के लिए स्टोरेज लेयर को कंप्यूट लेयर से अलग करें।
इन सिद्धांतों का पालन करने से आप एक आधार बनाते हैं जो उत्पादन के दबाव को सहन कर सकता है। लक्ष्य केवल वर्तमान समस्याओं को ठीक करना नहीं है, बल्कि भविष्य की चुनौतियों के प्रति अनुकूलित होने में सक्षम एक लचीला प्रणाली बनाना है।
11. मुख्य निदान चरणों का सारांश 📝
सारांश के लिए, उत्पादन लोड विफलताओं का निदान एक बहु-स्तरीय दृष्टिकोण के साथ शामिल होता है।
- ERD की समीक्षा करें: अत्यधिक जटिल संबंधों और गायब इंडेक्स के लिए जांच करें।
- प्रश्नों का विश्लेषण करें: पूरी तालिका स्कैन और अकुशल जॉइन मार्गों के लिए तलाश करें।
- लॉक्स को मॉनिटर करें: उन बिंदुओं को पहचानें जो टाइमआउट का कारण बनते हैं।
- हार्डवेयर की जांच करें: सुनिश्चित करें कि स्टोरेज और मेमोरी बॉटलनेक नहीं हैं।
- स्कीमा को अनुकूलित करें: पार्टीशनिंग और इंडेक्सिंग रणनीतियों को लागू करें।
- एप्लिकेशन को पुनर्गठित करें: डेटाबेस कॉल्स की संख्या कम करें और लेनदेन प्रबंधन को अनुकूलित करें।
इस संरचित दृष्टिकोण का पालन करने से यह सुनिश्चित होता है कि आप लक्षणों के बजाय मूल कारण को संबोधित करते हैं। प्रदर्शन अनुकूलन एक आवर्ती प्रक्रिया है जिसमें धैर्य और सटीकता की आवश्यकता होती है।
12. स्कीमा लचीलापन पर अंतिम विचार 🧠
एक मजबूत डेटा मॉडल किसी भी उच्च प्रदर्शन वाले एप्लिकेशन की रीढ़ है। इसके लिए निरंतर ध्यान और ट्रैफिक पैटर्न में बदलाव के साथ अनुकूलित होने की इच्छा की आवश्यकता होती है। संबंधों, इंडेक्सिंग और समानांतरता के बारे में समझने से आप उन सामान्य गड़बड़ियों को रोक सकते हैं जो उत्पादन विफलताओं के कारण बनती हैं।
याद रखें कि आरेख एक उपकरण है, प्रणाली नहीं। आपके डिज़ाइन का वास्तविक परीक्षण लाइव वातावरण में होता है। अपने मॉनिटरिंग को कसकर रखें, अपने इंडेक्स साफ रखें और अपने लेनदेन छोटे रखें। इन अभ्यासों के साथ, आपकी डेटा संरचना आपके व्यवसाय विकास के लिए एक विश्वसनीय आधार के रूप में काम करेगी।
सतर्क रहें। अपने मीट्रिक्स को मॉनिटर करें। आवश्यकता पड़ने पर पुनर्गठित करें। आपकी प्रणाली आपका धन्यवाद करेगी।

