











जब संगठन मोनोलिथिक आर्किटेक्चर से माइक्रोसर्विसेज में स्थानांतरित होते हैं, तो डेटा मॉडलिंग के तरीके अक्सर विवाद का विषय बन जाते हैं। दशकों तक एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) केंद्रीकृत प्रणालियों में डेटाबेस डिजाइन के लिए नक्शा बना रहा है। इसने तालिकाओं, कॉलम, कीज़ और संबंधों को सटीकता के साथ मैप किया। हालांकि, माइक्रोसर्विसेज की वितरित प्रकृति इन पारंपरिक विधियों के चुनौती करती है। एकल, एकीकृत स्कीमा के पूरे प्रणाली में लागू होने का मानना एक लगातार गलत धारणा है जो कठोर निर्भरता और संचालन संवेदनशीलता की ओर ले जा सकती है।
यह मार्गदर्शिका वितरित परिवेशों में ईआर डायग्राम्स के बारे में आम मान्यताओं का विश्लेषण करती है। यह तथ्य और काल्पनिक बातों को अलग करती है, जो डेटा सीमाओं को कैसे परिभाषित किया जाना चाहिए, साझा तालिकाओं के बिना संबंधों का प्रबंधन कैसे किया जाता है, और एक सेवा-आधारित आर्किटेक्चर में जाने पर डेटा के दृश्य प्रतिनिधित्व को क्यों बदलने की आवश्यकता होती है, इस पर ध्यान केंद्रित करती है। लक्ष्य स्केलेबिलिटी और लचीलेपन को समर्थन देने वाले डेटा मॉडलिंग सिद्धांतों की स्पष्ट समझ प्रदान करना है।
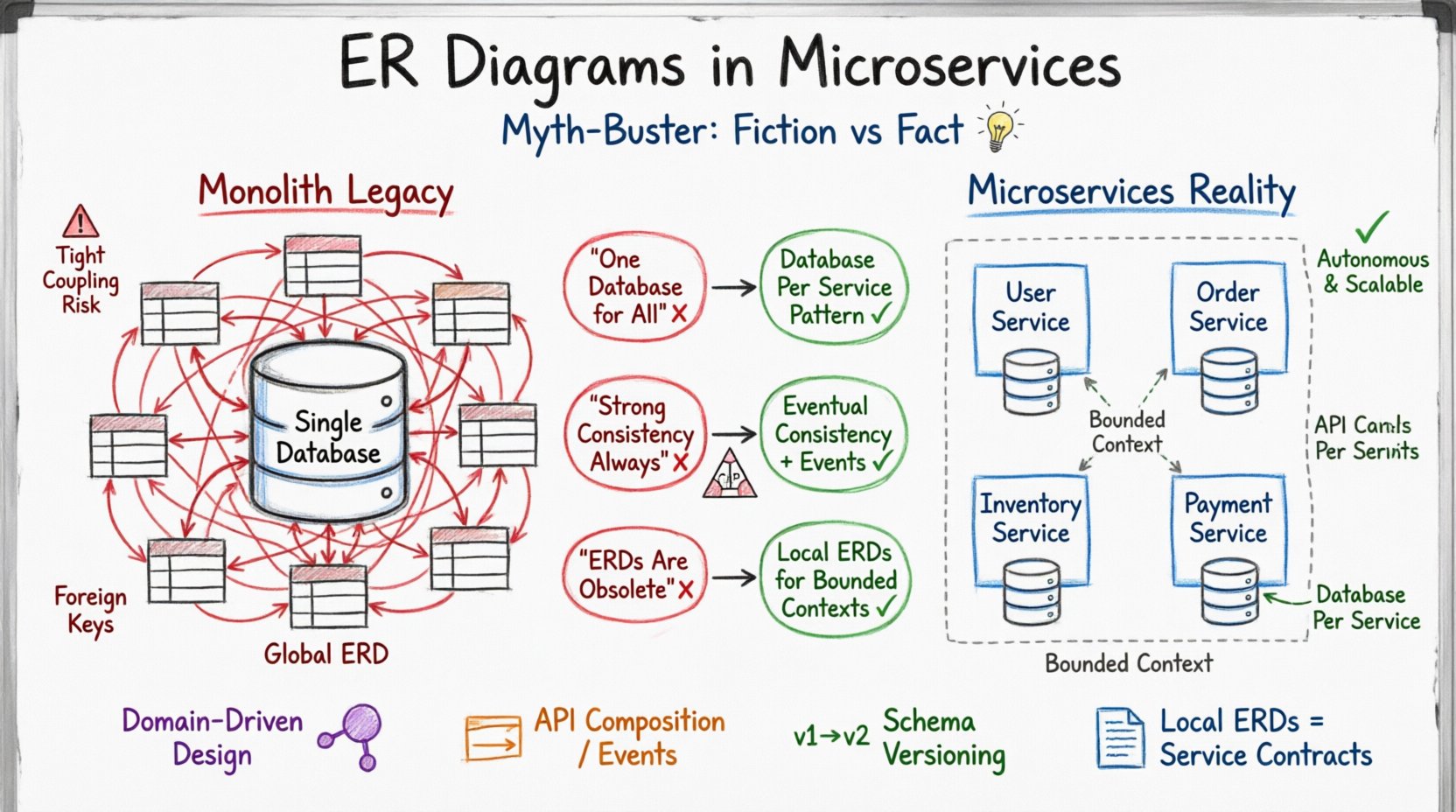
मोनोलिथिक विरासत: पुराने ईआरडी क्यों फिट नहीं होते 🏛️
एक पारंपरिक मोनोलिथिक एप्लिकेशन में, डेटाबेस केंद्रीय सत्य स्रोत के रूप में कार्य करता है। सभी एप्लिकेशन तर्क एकल स्कीमा के साथ बातचीत करते हैं। इस परिवेश में एक व्यापक ईआर डायग्राम को बढ़ावा दिया जाता है जो प्रत्येक एंटिटी और संबंध को मैप करता है। डिजाइनर विदेशी कीज़ पर भरोसा कर सकते हैं ताकि पूरी प्रणाली में रेफरेंशियल इंटीग्रिटी बनाए रखी जा सके। लेनदेन एक ही डेटाबेस इंस्टेंस के भीतर बहुत सारी तालिकाओं के बीच फैलते हैं, जिससे एसीआईडी गुण (परमाणुता, सुसंगतता, अलगाव, टिकाऊपन) को वैश्विक रूप से बनाए रखा जाता है।
जब इस दृष्टिकोण को माइक्रोसर्विसेज पर लागू किया जाता है, तो बाधा उत्पन्न होती है। माइक्रोसर्विसेज स्वतंत्र होने के लिए डिज़ाइन किए गए हैं। प्रत्येक सेवा अपनी डेटा पर्सिस्टेंस लेयर का प्रबंधन करती है। इसका मतलब है कि सेवाओं के बीच कोई साझा डेटाबेस नहीं है। यदि कोई सेवा अपने डेटा का मालिक है, तो दूसरी सेवा मानक एसक्यूएल जॉइन्स का उपयोग करके उसके डेटा को सीधे प्रश्न नहीं कर सकती है। इसलिए ईआरडी को पूरी प्रणाली के नक्शे से डोमेन-विशिष्ट स्कीमा के संग्रह में बदलना होगा।
- केंद्रीकृत नियंत्रण: मोनोलिथिक प्रणालियाँ डीबीए को पूरे स्कीमा के प्रबंधन की अनुमति देती हैं।
- वितरित मालिकता: माइक्रोसर्विसेज के प्रत्येक टीम को अपने स्कीमा परिभाषा के मालिक होने की आवश्यकता होती है।
- वैश्विक लेनदेन: मोनोलिथिक प्रणालियाँ तालिकाओं के बीच एकल-लेनदेन अपडेट का समर्थन करती हैं।
- वितरित लेनदेन: माइक्रोसर्विसेज को सैगा या अंततः सुसंगतता जैसे समन्वय पैटर्न की आवश्यकता होती है।
डेटा मॉडलिंग को आधुनिक बनाने का पहला चरण यह स्वीकार करना है कि पूरे एप्लिकेशन को छूते हुए एकल ईआरडी अब लागू या इच्छित नहीं है। इसके बजाय, ध्यान डोमेन-ड्रिवन डिजाइन की ओर जाता है, जहां डेटा मॉडल प्रत्येक सेवा की व्यावसायिक क्षमताओं के साथ मेल खाता है।
माइथ 1: ‘एक डेटाबेस’ की गलतफहमी 🗄️❌
वितरित प्रणालियों में नए डिजाइनकारों में एक आम मान्यता यह है कि वे एकल भौतिक डेटाबेस को बनाए रख सकते हैं जबकि स्कीमा प्रीफिक्स या अलग-अलग तालिकाओं के उपयोग से डेटा को तार्किक रूप से अलग किया जा सकता है। इस दृष्टिकोण को अक्सर ‘शेयर्ड डेटाबेस’ एंटी-पैटर्न के रूप में जाना जाता है। जबकि यह प्रारंभिक डिजाइन को सरल बनाने की लगती है, लेकिन जैसे प्रणाली बढ़ती है, इसमें महत्वपूर्ण जोखिम उत्पन्न होते हैं।
क्यों साझा डेटाबेस विफल होते हैं
यद्यपि सेवाएं कोड साझा नहीं करती हैं, लेकिन डेटाबेस इंस्टेंस को साझा करने से भौतिक निर्भरता उत्पन्न होती है। यदि एक सेवा को एक स्कीमा माइग्रेशन की आवश्यकता होती है जो प्रदर्शन या उपलब्धता को प्रभावित करती है, तो उस डेटाबेस को साझा करने वाली सभी अन्य सेवाएं प्रभावित होती हैं। इससे माइक्रोसर्विसेज में स्वतंत्रता के मूल सिद्धांत का उल्लंघन होता है।
- डिप्लॉयमेंट ब्लॉकिंग: सेवा ए के लिए जोखिम भरा माइग्रेशन सेवा बी के डिप्लॉयमेंट को रोक सकता है।
- संसाधन प्रतिस्पर्धा: एक सेवा से भारी प्रश्न अन्य सेवाओं के प्रदर्शन को खराब कर सकते हैं।
- सुरक्षा जोखिम: एक कमजोर सेवा किसी अन्य सेवा के डेटा तक संभवतः पहुंच सकती है।
- तकनीकी बंधन: यदि सेवा ए को सेवा बी से अलग डेटाबेस इंजन की आवश्यकता हो, तो वे साझा परिवेश में एक साथ नहीं रह सकते हैं।
समाधान डेटाबेस पर सेवा पैटर्न है। प्रत्येक सेवा अपना अलग डेटाबेस तैयार करती है। इससे यह सुनिश्चित होता है कि स्कीमा बदलाव अलग-अलग हों। सेवा ए के लिए ईआर डायग्राम केवल सेवा ए के लिए आवश्यक डेटा एंटिटी को ही दर्शाना चाहिए, न कि पूरी प्रणाली को।
माइथ 2: मजबूत सुसंगतता हमेशा आवश्यक होती है ⚖️
मोनोलिथिक परिवेश में, एसीआईडी संगतता मानक है। डेवलपर्स की अपेक्षा होती है कि जब एक लेनदेन कमिट होता है, तो डेटा पूरी प्रणाली में तुरंत सुसंगत हो जाता है। माइक्रोसर्विसेज में, यह अपेक्षा अक्सर अवास्तविक होती है। कैप प्रमेय कहता है कि एक वितरित प्रणाली केवल तीन में से दो गुणों की गारंटी दे सकती है: सुसंगतता, उपलब्धता, और पार्टीशन टॉलरेंस।
वितरित सुसंगतता को समझना
जब सेवाएं नेटवर्क के माध्यम से संचार करती हैं, तो लैटेंसी और संभावित विफलताएं अनिवार्य हैं। सेवा सीमाओं के बीच मजबूत सुसंगतता लागू करने की कोशिश अक्सर उच्च लैटेंसी या प्रणाली अनउपलब्धता के कारण बनती है। इसके बजाय, बहुत सी प्रणालियां अंततः सुसंगतता को अपनाती हैं। इसका मतलब है कि सेवाओं के बीच डेटा अस्थायी रूप से असंगत हो सकता है, लेकिन समय के साथ यह समान हो जाता है।
- मजबूत सुसंगतता: डेटा सभी जगह तुरंत अपडेट होता है। बैंकिंग के लिए अच्छा है, लेकिन उच्च लैटेंसी होती है।
- अंततः सुसंगतता: डेटा असिंक्रोनस तरीके से प्रसारित होता है। उपयोगकर्ता प्रोफाइल, इन्वेंटरी गिनती के लिए अच्छा है।
- आधार उपलब्धता: प्रणाली नेटवर्क विभाजन के दौरान भी संचालन में रहती है।
माइक्रोसर्विस में ईआर आरेख आमतौर पर तुरंत लॉकिंग की आवश्यकता वाले संबंधों का प्रतिनिधित्व नहीं करता है। इसके बजाय, यह स्थानीय रूप से सुसंगत डेटा की स्थिति का प्रतिनिधित्व करता है। क्रॉस-सर्विस संबंध ईवेंट्स या एपीआई कॉल्स के माध्यम से संभाले जाते हैं, डेटाबेस फॉरेन कीज़ के माध्यम से नहीं।
पौराणिक कथा 3: वितरित प्रणालियों में ईआर आरेख अप्रासंगिक हो गए हैं 📉
कुछ व्यवसायिक व्यक्ति दावा करते हैं कि क्योंकि माइक्रोसर्विसेज डेटा को अलग करते हैं, ईआरडी की अवधारणा अब आवश्यक नहीं है। यह गलत है। जबकि एक सार्वभौमिक ईआरडी अप्रासंगिक हो गया है, स्थानीय ईआरडी अब अधिक महत्वपूर्ण हैं। एक सेवा के भीतर डेटा संरचना के स्पष्ट दस्तावेजीकरण के बिना, डेटा ड्रिफ्ट और एकीकरण त्रुटियों का जोखिम बहुत बढ़ जाता है।
स्थानीय ईआरडी की भूमिका
माइक्रोसर्विस संदर्भ में ईआरडी का उद्देश्य मोनोलिथ की तुलना में अलग होता है। यह सीमित संदर्भ को परिभाषित करता है। यह सुनिश्चित करता है कि सेवा को ठीक से पता हो कि वह कौन सा डेटा स्वामित्व में रखती है और आंतरिक रूप से डेटा कैसे संरचित है। इसे बाहरी सेवाओं के संबंधों को दिखाने की आवश्यकता नहीं है।
- दस्तावेजीकरण: यह आंतरिक डेटा मॉडल के लिए एक अनुबंध के रूप में कार्य करता है।
- संचार: यह विकासकर्मियों को बाहरी निर्भरताओं के बारे में जाने के बिना डोमेन एंटिटीज को समझने में मदद करता है।
- रखरखाव: यह नए टीम सदस्यों को विशिष्ट सेवा में शामिल करने को सरल बनाता है।
- सत्यापन: यह डिजाइन चरण के दौरान चक्रीय निर्भरताओं की पहचान करने में मदद करता है।
आरेख का ध्यान प्राथमिक कुंजियों, एंटिटीज और विशेषताओं पर केंद्रित होना चाहिए। बाहरी सेवाओं को संदर्भित करने वाली विदेशी कुंजियों को हटा देना चाहिए या उन्हें प्रत्यक्ष तालिका लिंक के बजाय पहचानकर्ता के रूप में सारांशित करना चाहिए।
माइक्रोसर्विसेज में डेटा मॉडलिंग के लिए सर्वोत्तम प्रथाएं 🛠️
एक विश्वसनीय प्रणाली बनाने के लिए, टीमों को वितरित आर्किटेक्चर सिद्धांतों के अनुरूप विशिष्ट मॉडलिंग रणनीतियों को अपनाना होगा। इन प्रथाओं के माध्यम से सुनिश्चित किया जाता है कि सेवाएं स्वतंत्र रहें, लेकिन फिर भी एक सुसंगत उपयोगकर्ता अनुभव प्रदान करने के लिए सहयोग करें।
1. क्षेत्र-ड्राइवन डिजाइन (डीडीडी)
डेटाबेस स्कीमा को डोमेन मॉडल के साथ मिलाना आवश्यक है। प्रत्येक सेवा को एक विशिष्ट व्यावसायिक क्षमता का प्रतिनिधित्व करना चाहिए। उदाहरण के लिए, एक “उपयोगकर्ता सेवा” को आदेश विवरण नहीं रखना चाहिए। एक “आदेश सेवा” को उपयोगकर्ता प्रमाणीकरण टोकन नहीं रखना चाहिए। इस विभाजन से यह सुनिश्चित होता है कि ईआरडी तकनीकी सुविधा के बजाय व्यावसायिक तर्क को दर्शाती है।
- लेनदेन सीमाओं के आधार पर एग्रीगेट्स को परिभाषित करें।
- ईआरडी को सेवा की जिम्मेदारी पर केंद्रित रखें।
- एक से अधिक व्यावसायिक क्षेत्रों को जोड़ने वाले मॉडल बनाने से बचें।
2. सीमाओं के पार संबंधों का प्रबंधन
जब सेवा A को सेवा B द्वारा स्वामित्व वाले डेटा की आवश्यकता होती है, तो इसे सीधे सेवा B के डेटाबेस को प्रश्न नहीं करना चाहिए। इसके बजाय, इसे निम्नलिखित पैटर्न में से एक का उपयोग करना चाहिए:
- API संयोजन: सेवा A सेवा B के API को कॉल करती है ताकि आवश्यक डेटा प्राप्त कर सके।
- अंततः प्रतिलिपि बनाना: सेवा A अपने डेटाबेस में आवश्यक डेटा की प्रतिलिपि बनाए रखती है, जिसे घटनाओं के माध्यम से अद्यतन किया जाता है।
- पठन मॉडल के माध्यम से जोड़ें: एक निर्दिष्ट पठन सेवा बहुस्रोतों से डेटा संग्रहीत करती है प्रश्न अनुकूलन के लिए।
3. स्कीमा संस्करण
एक वितरित प्रणाली में, सेवाएं अलग-अलग गति से विकसित होती हैं। एक सेवा के स्कीमा में परिवर्तन को उस सेवा के उपभोक्ता को तोड़ने नहीं चाहिए। स्कीमा संस्करण को लागू करने से पीछे की अनुकूलता संभव होती है।
- API संवाद के लिए संस्करण युक्त एंडपॉइंट का उपयोग करें।
- पुनर्स्थापना के दौरान डेटा स्कीमा के कई संस्करणों को एक साथ अस्तित्व में रहने दें।
- तुरंत अपडेट करने के बजाय पुराने स्कीमा संस्करणों को धीरे-धीरे अप्रचलित करें।
तुलना: मोनोलिथ बनाम माइक्रोसर्विस डेटा आर्किटेक्चर 📊
अंतर को स्पष्ट करने के लिए, निम्नलिखित तालिका केंद्रीकृत बनाम वितरित आर्किटेक्चर में डेटा मॉडलिंग के मुख्य अंतरों को चित्रित करती है।
| विशेषता | मोनोलिथिक आर्किटेक्चर | माइक्रोसर्विस आर्किटेक्चर |
|---|---|---|
| डेटा भंडारण | एकल डेटाबेस उदाहरण | प्रत्येक सेवा के लिए डेटाबेस |
| ईआर आरेख का परिसर | वैश्विक प्रणाली दृश्य | सेवा-विशिष्ट दृश्य |
| संबंध | विदेशी कुंजियाँ (SQL जॉइन्स) | API कॉल या घटनाएँ |
| संगतता मॉडल | मजबूत संगतता (एसीआईडी) | अंततः संगतता (बेस) |
| डेप्लॉयमेंट | एकल डिप्लॉयमेंट | स्वतंत्र सेवा डिप्लॉयमेंट |
| स्कीमा परिवर्तन | केंद्रीकृत स्थानांतरण | सेवा टीम द्वारा स्वामित्व |
| प्रश्न पूछना | सीधा SQL | पढ़ने के मॉडल / CQRS |
सीमाओं के पार डेटा संबंधों का प्रबंधन 🔗
माइक्रोसर्विसेज के सबसे कठिन पहलुओं में से एक डेटा संबंधों का प्रबंधन है। एक मोनोलिथ में, एक विदेशी कुंजी यह सुनिश्चित करती है कि एक ऑर्डर एक उपयोगकर्ता से संबंधित है। माइक्रोसर्विसेज में, “उपयोगकर्ता” तालिका उपयोगकर्ता सेवा में स्थित है, और “ऑर्डर” तालिका ऑर्डर सेवा में स्थित है। ऑर्डर सेवा के पास उपयोगकर्ता सेवा के डेटाबेस के लिए एक विदेशी कुंजी रखने की अनुमति नहीं है।
संदर्भित अखंडता पैटर्न
साझा तालिकाओं के बिना संदर्भित अखंडता बनाए रखने के लिए, टीमें विशिष्ट पैटर्न का उपयोग कर सकती हैं:
- तार्किक संदर्भ: उपयोगकर्ता ID को एक स्ट्रिंग या संख्या के रूप में स्टोर करें, लेकिन निर्माण के दौरान उपयोगकर्ता की उपस्थिति की पुष्टि API कॉल के माध्यम से करें।
- डेटाबेस ट्रिगर्स: सेवाओं के बीच उपयोग नहीं किया जाना चाहिए, लेकिन एक सेवा के भीतर वैध है।
- प्रमाणीकरण घटनाएँ: उपयोगकर्ता सेवा एक “उपयोगकर्ता बनाया गया” घटना प्रकाशित करती है। ऑर्डर सेवा इसे उपयोगकर्ता संबंध के अनुमोदन के लिए उपयोग करती है।
जॉइन्स की समस्या
सेवा सीमाओं के पार जॉइन्स प्रदर्शन की एक बाधा बन जाते हैं। वे नेटवर्क लेटेंसी और संभावित विफलता के बिंदु लाते हैं। यदि उपयोगकर्ता सेवा बंद है, तो ऑर्डर सेवा ऑर्डर विवरण प्राप्त नहीं कर सकती है यदि वह जॉइन पर निर्भर है। इसके बजाय, ऑर्डर सेवा को ऑर्डर निर्माण के समय आवश्यक उपयोगकर्ता विवरण (जैसे नाम) को अतिरिक्त रूप से स्टोर करना चाहिए। यह नॉर्मलाइजेशन और उपलब्धता के बीच एक व्यापार बनाता है।
स्कीमा विकास और संस्करण प्रबंधन 🔄
स्कीमा विकास अनिवार्य है। जैसे-जैसे व्यावसायिक आवश्यकताएँ बदलती हैं, डेटा संरचनाओं को अनुकूलित करना होता है। माइक्रोसर्विसेज वातावरण में, स्कीमा बदलना अधिक जटिल होता है क्योंकि कई सेवाएँ एक अन्य की डेटा संरचना पर निर्भर हो सकती हैं।
विकास के लिए रणनीतियाँ
- जोड़ने वाले परिवर्तन: यदि एप्लिकेशन गैर-मौजूदा फील्ड्स को बेहतर तरीके से संभालता है, तो एक नई कॉलम जोड़ना आमतौर पर सुरक्षित है।
- फील्ड्स को हटाना: इसमें एक अप्रचलन अवधि की आवश्यकता होती है जहां फील्ड छिपाई जाती है लेकिन अभी भी मौजूद होती है, फिर बाद में हटा दी जाती है।
- प्रकार परिवर्तन: डेटा प्रकार को बदलना (उदाहरण के लिए, स्ट्रिंग से पूर्णांक) एक समन्वित स्थानांतरण रणनीति की आवश्यकता होती है।
एक स्कीमा रजिस्ट्री का उपयोग इन परिवर्तनों के प्रबंधन में मदद कर सकता है। यह सेवाओं के बीच आदान-प्रदान की जा रही डेटा संरचना के लिए एक केंद्रीय सत्य स्रोत के रूप में कार्य करता है, जिससे उत्पादकों और उपभोक्ताओं को फॉर्मेट पर सहमति मिलती है।
टालने वाले सामान्य गलतियाँ 🚧
सिद्धांतों के ठोस समझ के बावजूद, टीमें कार्यान्वयन के दौरान अक्सर जाल में फंस जाती हैं। इन गलतियों को जल्दी पहचानने से महत्वपूर्ण तकनीकी ऋण बचाया जा सकता है।
- अत्यधिक सामान्यीकरण:सभी सेवाओं के बीच एक ही स्रोत के सत्य को बनाए रखने की कोशिश करने से जटिल वितरित लेनदेन का निर्माण होता है। आवश्यकता पड़ने पर अतिरेक को स्वीकार करें।
- आवृत्ति-निरपेक्षता को नजरअंदाज करना:नेटवर्क कॉल विफल हो सकते हैं या दोहराए जा सकते हैं। डेटा संचालन को दोहराए गए अनुरोधों को बिना दोहराए बनाए रखने के लिए डिज़ाइन किया जाना चाहिए।
- नृत्य संगठन की अत्यधिक भारितता:डेटा सुसंगतता के लिए केवल घटनाओं पर निर्भर रहना अनियंत्रित हो सकता है। जटिल कार्यप्रवाहों के लिए निर्देशन का उपयोग करें।
- लेटेंसी के अंतर्गत आंकना:सेवा के बीच डेटा लेने से प्रत्येक अनुरोध में मिलीसेकंड जोड़ देता है। जहां संभव हो, डेटा को स्थानीय रूप से संगृहीत करें।
- दस्तावेज़ीकरण की कमी:प्रत्येक सेवा के लिए स्पष्ट एरडी के बिना, एकीकरण एक अनुमान खेल बन जाता है।
संरचनात्मक स्पष्टता पर अंतिम विचार 🧠
एकल ब्लॉक से माइक्रोसर्विस डेटा मॉडलिंग में संक्रमण के लिए मनोवृत्ति में परिवर्तन की आवश्यकता होती है। यह केवल डेटाबेस को छोटे टुकड़ों में तोड़ने के बारे में नहीं है। यह डेटा स्वामित्व और संबंधों की अवधारणा को पुनर्परिभाषित करने के बारे में है। एरडी आरेख अभी भी एक महत्वपूर्ण उपकरण बना हुआ है, लेकिन इसकी सीमा सेवा सीमा तक सीमित हो जाती है।
साझा डेटाबेस और वैश्विक सुसंगतता के भ्रमों से बचकर, वास्तुकार ऐसे प्रणालियाँ बना सकते हैं जो लचीली और स्केलेबल हों। मुख्य बात यह है कि डेटा सामान्यीकरण के बजाय सेवा स्वायत्तता को प्राथमिकता देना। इसका अर्थ है कि कुछ डेटा की दोहराव को स्वीकार करना जिससे सेवाएँ स्वतंत्र रूप से काम कर सकें। इसका अर्थ यह भी है कि मजबूत सुसंगतता हर ऑपरेशन के लिए आवश्यक नहीं है, बल्कि एक विलासिता है।
जब डेटा संरचना का डिज़ाइन कर रहे हों, तो क्षेत्र पर ध्यान केंद्रित करें। व्यापार क्षमताओं को सीमाओं को निर्धारित करने दें। प्रत्येक सेवा के आंतरिक अवस्था को स्पष्ट करने के लिए एरडी का उपयोग करें। उनके बीच कनेक्शन को प्रबंधित करने के लिए घटनाओं और एपीआई का उपयोग करें। इस दृष्टिकोण से यह सुनिश्चित होता है कि प्रणाली तब भी विकसित हो सकती है जब तक डेटा अखंडता के आधार को नहीं तोड़ा जाता।
अंततः, लक्ष्य एक वितरित रूप में मोनोलिथ की प्रतिलिपि बनाना नहीं है। यह एक प्रणाली बनाना है जहां डेटा को उसी लचीलेपन और गति के साथ प्रबंधित किया जाता है जैसे कि उसे प्रसंस्करण करने वाले कोड को प्रबंधित किया जाता है। यह संतुलन सफल माइक्रोसर्विस रणनीति की नींव है।

