










एंटिटी रिलेशनशिप डायग्राम (ईआरडी) डेटाबेस आर्किटेक्चर के लिए ब्लूप्रिंट के रूप में कार्य करते हैं। हालांकि, अनुभवी डिजाइनरों को भी व्यापार तर्क को डेटा मॉडल में बदलते समय दिक्कत का सामना करना पड़ता है। अस्पष्टता अक्सर शब्दावली के ओवरलैप और संरचनात्मक तत्वों के बीच सूक्ष्म अंतरों से उत्पन्न होती है। यह गाइड कुंजियों, कार्डिनैलिटी और संबंधों के बारे में सबसे लंबे समय तक रहने वाले प्रश्नों को संबोधित करता है।
इन अवधारणाओं को समझने से डेटा अतिरेक से बचाव होता है और प्रश्न प्रदर्शन सुनिश्चित होता है। हम 15 विशिष्ट भ्रमों के माध्यम से चलेंगे, उन्हें स्पष्ट और क्रियान्वयन योग्य परिभाषाओं में बांटेंगे। प्रत्येक खंड में व्यावहारिक उदाहरण और दृश्य विवरण शामिल हैं जो मूल यांत्रिकी को स्पष्ट करते हैं।
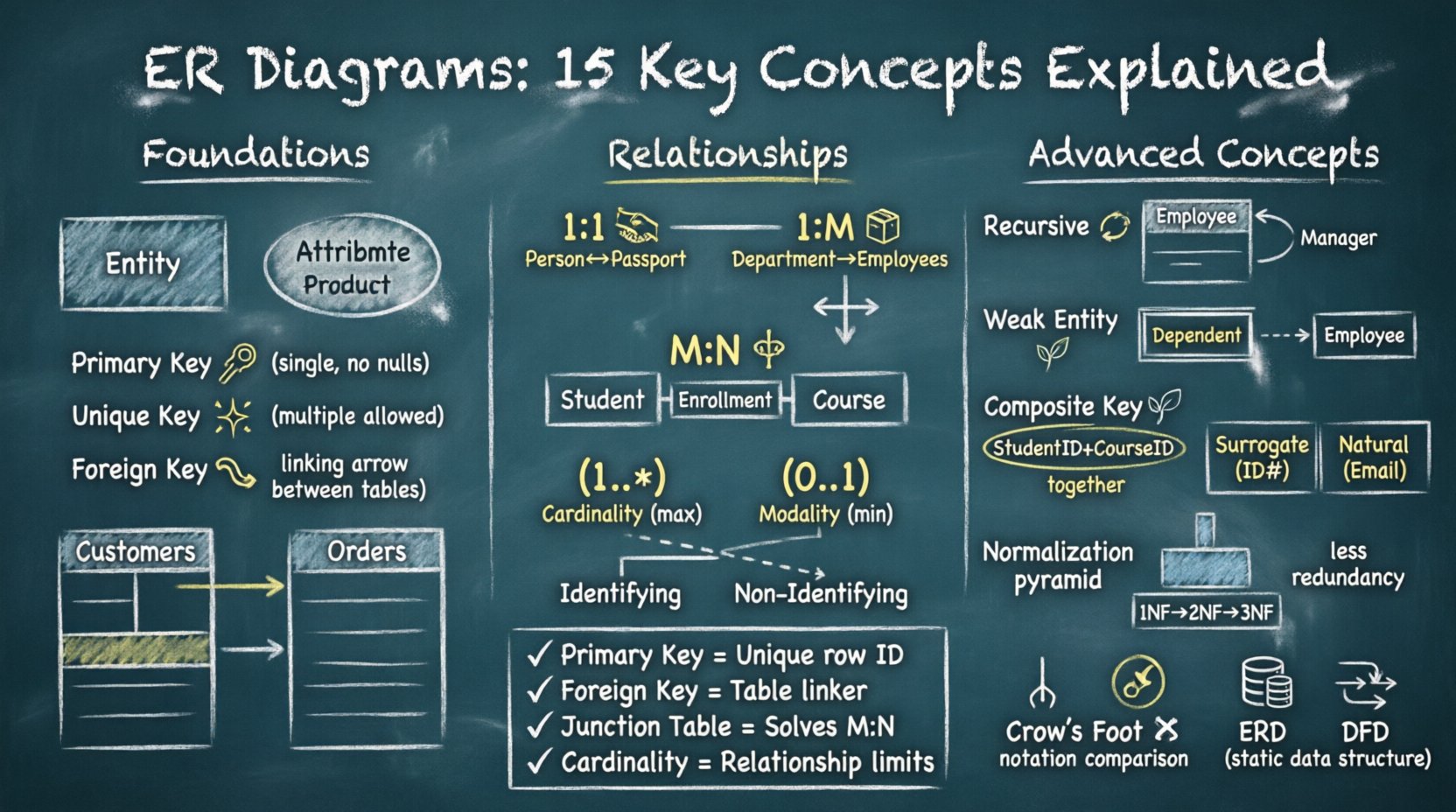
1. एक एंटिटी और एक एट्रिब्यूट में क्या अंतर है? 🏷️
एक एंटिटीएक वास्तविक दुनिया की वस्तु या अवधारणा का प्रतिनिधित्व करता है जिसके बारे में डेटा संग्रहीत किया जाता है। इसे आमतौर पर एक आयत के रूप में दर्शाया जाता है। उदाहरणों में शामिल हैं ग्राहक, उत्पाद, या आदेश.
एक एट्रिब्यूटएक एंटिटी के गुण का वर्णन करता है। इसे एंटिटी से जुड़े एक अंडाकार के रूप में दर्शाया जाता है। उदाहरण के लिए, ग्राहकनाम या उत्पादमूल्यऊपर बताए गए एंटिटी के एट्रिब्यूट हैं।
- एंटिटी: संज्ञा (कौन/क्या)।
- एट्रिब्यूट: विशेषण (जो इसे वर्णित करता है)।
भ्रम तब उत्पन्न होता है जब एक एट्रिब्यूट में एक से अधिक जानकारी होती है। यदि पताएक एट्रिब्यूट है, तो इसे बांटना बेहतर हो सकता है सड़क, शहर, और ज़िप बेहतर नॉर्मलाइज़ेशन के लिए।
2. प्राइमरी की और यूनिक की में क्या अंतर है? 🔑
दोनों डेटा अखंडता सुनिश्चित करते हैं, लेकिन उनके उपयोग में अंतर होता है।
- प्राइमरी की: एक तालिका में प्रत्येक पंक्ति की एकल पहचान करता है। एक तालिका में केवल एक प्राइमरी की हो सकती है। इसमें नॉल वैल्यूज नहीं हो सकती हैं।
- यूनिक की: सुनिश्चित करता है कि कॉलम में सभी मान अलग-अलग हों। एक तालिका में कई यूनिक की हो सकती हैं। नॉल मान अक्सर अनुमत हैं (उपाय पर निर्भर करते हुए)।
एक प्राइमरी की के रूप में एक रिकॉर्ड के लिए सोशल सिक्योरिटी नंबर के बारे में सोचें। एक यूनिक की एक पासपोर्ट नंबर के समान है—भी अद्वितीय, लेकिन एक व्यक्ति के लिए एक से अधिक यूनिक पहचानकर्ता उपलब्ध हो सकते हैं।
3. एक विदेशी की क्या है और यह तालिकाओं को कैसे जोड़ती है? 🔗
एक विदेशी की एक तालिका में एक फील्ड (या फील्ड्स का संग्रह) है जो दूसरी तालिका में प्राइमरी की को संदर्भित करता है। यह दो तालिकाओं के बीच एक लिंक स्थापित करता है।
एक आर्डर्स तालिका को जानने की आवश्यकता है कि कौन सा ग्राहक ने आर्डर दिया। ग्राहकआईडी में आर्डर्स तालिका विदेशी की है।
| तालिका | कॉलम | भूमिका |
|---|---|---|
| ग्राहक | ग्राहकआईडी | प्राइमरी की |
| आर्डर्स | ग्राहक ID | विदेशी कुंजी |
इस संबंध के कारण डेटाबेस एक संदर्भी अखंडता को लागू कर सकता है, जिससे सुनिश्चित होता है कि कोई ऑर्डर वैध ग्राहक के बिना नहीं हो सकता।
4. संबंध एक से एक कब होता है? 🤝
एक से एक (1:1) संबंध तब होता है जब तालिका A में एक एकल रिकॉर्ड तालिका B में ठीक एक रिकॉर्ड से संबंधित होता है, और विपरीत भी।
- उदाहरण: एक व्यक्ति और एक पासपोर्ट.
- कार्यान्वयन:आमतौर पर एक तालिका की प्राथमिक कुंजी को दूसरी तालिका में विदेशी कुंजी के रूप में रखकर कार्यान्वित किया जाता है।
जब किसी एकता को प्रदर्शन या सुरक्षा को अनुकूलित करने के लिए विभाजित किया जाता है, तो यह सामान्य है। उदाहरण के लिए, संवेदनशील डेटा जैसे सामाजिक सुरक्षा संख्या को एक अलग तालिका में स्थानांतरित करना, जो 1:1 से जुड़ी हो।
5. एक से बहुत के संबंध का कार्य कैसे होता है? 📦
यह सबसे आम संबंध प्रकार है। तालिका A में एक एकल रिकॉर्ड तालिका B में बहुत से रिकॉर्ड से संबंधित होता है, लेकिन तालिका B में एक रिकॉर्ड केवल तालिका A में एक रिकॉर्ड से संबंधित होता है।
- उदाहरण: विभाग से कर्मचारी.
- दिशा:एक विभाग में बहुत से कर्मचारी होते हैं।
ERD में, इसे दो एकताओं को जोड़ने वाली रेखा के साथ बनाया जाता है। “बहुत” वाली ओर को विदेशी कुंजी मिलती है।
6. बहुत से से बहुत से संबंध क्यों समस्याग्रस्त हैं? ⚖️
एक बहुत से से बहुत से (M:N) संबंध तब होता है जब तालिका A में बहुत से रिकॉर्ड तालिका B में बहुत से रिकॉर्ड से संबंधित होते हैं। एक पुल के बिना इसका सीधे रूप से एक संबंधात्मक डेटाबेस में कार्यान्वयन संभव नहीं है।
- समस्या:आप बस एक तालिका में विदेशी कुंजी जोड़ नहीं सकते, क्योंकि एक पंक्ति में बहुत से आईडी स्टोर करने की आवश्यकता होगी।
- समाधान: एक जंक्शन तालिका (सह-संबंधित एकाई) बनाएं।
के लिएछात्र और पाठ्यक्रम, एक बनाएंपंजीकरण तालिका जिसमें शामिल हैछात्र आईडी और पाठ्यक्रम आईडी। इससे M:N को दो 1:बहुत संबंधों में बदल दिया जाता है।
7. कार्डिनैलिटी और मोडैलिटी में क्या अंतर है? ⚖️
इन शब्दों का उपयोग संबंध की सीमाओं का वर्णन करने के लिए किया जाता है, जिसे समान प्रतीकों के कारण अक्सर गलत समझा जाता है।
- कार्डिनैलिटी: अधिकतम संख्या उदाहरण। (उदाहरण के लिए, एक से बहुत अधिक)।
- मोडैलिटी: न्यूनतम संख्या उदाहरण। (उदाहरण के लिए, अनिवार्य या वैकल्पिक)।
उदाहरण: एककर्मचारी को एक के साथ होना चाहिएविभाग (मोडैलिटी: अनिवार्य/1)। एकविभाग बिना एक के भी मौजूद हो सकता हैकर्मचारी (मोडैलिटी: वैकल्पिक/0)।
8. पहचानकर्ता बनाम गैर-पहचानकर्ता संबंध 🧩
अंतर बच्चे के एकाई के निर्भरता में है।
- पहचानकर्ता: बच्चे का संस्थान माता-पिता के बिना अस्तित्व में नहीं आ सकता है। विदेशी कुंजी बच्चे की प्राथमिक कुंजी का हिस्सा है। अक्सर एक ठोस रेखा के साथ दिखाया जाता है।
- गैर-पहचानकर्ता: बच्चे का संस्थान स्वतंत्र रूप से अस्तित्व में हो सकता है। विदेशी कुंजी प्राथमिक कुंजी का हिस्सा नहीं है। अक्सर एक बिंदीदार रेखा के साथ दिखाया जाता है।
एक के बारे में सोचेंबिल (माता-पिता) औरबिल पंक्ति आइटम (बच्चा)। पंक्ति आइटम पहचानकर्ता है क्योंकि एक आइटम बिना बिल के अर्थहीन है।
9. एक पुनरावृत्त संबंध क्या है? 🔄
एक पुनरावृत्त संबंध तब होता है जब एक संस्थान स्वयं से संबंधित होता है। यह विशेष रूप से पदानुक्रमिक डेटा में सामान्य है।
- उदाहरण: एककर्मचारी तालिका जहां एक कर्मचारी दूसरों काप्रबंधक दूसरों का।
- कार्यान्वयन: एक ही तालिका में विदेशी कुंजी जो उसी तालिका की प्राथमिक कुंजी की ओर इशारा करती है।
इस संरचना का समर्थन संगठनात्मक आरेखों या उप-श्रेणियों वाले उत्पाद श्रेणियों के लिए किया जाता है।
10. कमजोर संस्थानों में मजबूत संस्थानों से क्या अंतर है? 🌱
एकमजबूत संस्थान की एक प्राथमिक कुंजी होती है जो अन्य संस्थानों से स्वतंत्र होती है। एककमजोर संस्थान माता-पिता संस्थान की प्राथमिक कुंजी के बिना अद्वितीय रूप से पहचान नहीं किया जा सकता है।
- दृश्य: कमजोर संस्थानों को अक्सर डबल आयताकार आकृति के साथ बनाया जाता है।
- निर्भरता: वे पहचानकर्ता संबंध पर निर्भर होते हैं।
उदाहरण: एक निर्भर (पति/पत्नी/बच्चा) एक कंपनी प्रणाली में। एक निर्भर रिकॉर्ड के पास आमतौर पर अपना अद्वितीय ID नहीं होता है; इसकी पहचान करने के लिए इसकी आवश्यकता होती है कर्मचारीआईडी के रूप में पहचाना जाना चाहिए।
11. आप कब एक संयुक्त कुंजी का उपयोग करना चाहिए? 🧩
एक संयुक्त कुंजी दो या अधिक कॉलमों का संयोजन होता है जो मिलकर एक पंक्ति की विशिष्ट पहचान करते हैं। जब कोई भी एक कॉलम अद्वितीयता प्रदान नहीं करता है, तब इसका उपयोग किया जाता है।
- परिदृश्य: एक छात्रपाठ्यक्रम तालिका।
- कुंजियाँ: छात्रआईडी + पाठ्यक्रमआईडी.
इस संदर्भ में दोनों आईडी अपने आप में अद्वितीय नहीं हैं, लेकिन संयोजन अद्वितीय है। सावधान रहें, क्योंकि संयुक्त कुंजियाँ अन्य तालिकाओं में विदेशी कुंजी संबंधों को जटिल बना सकती हैं।
12. सुरोगेट बनाम प्राकृतिक कुंजियाँ: कौन सी चुननी चाहिए? 🔢
यह एक रणनीतिक डिज़ाइन निर्णय है।
- प्राकृतिक कुंजी: एक वास्तविक दुनिया की विशेषता (उदाहरण के लिए, ईमेल, एसएसएन)। लाभ: सार्थक। नुकसान: बदल सकती है, लंबी हो सकती है, या संवेदनशील जानकारी शामिल हो सकती है।
- सुरोगेट कुंजी: एक प्रणाली-उत्पन्न आईडी (उदाहरण के लिए, स्वतः वृद्धि वाली पूर्ण संख्या)। लाभ: स्थिर, छोटी, तेज। नुकसान: कोई व्यापारिक अर्थ नहीं।
सर्वोत्तम अभ्यास आंतरिक तालिका संरचना के लिए सुरोगेट कुंजियों के पक्ष में होता है, जबकि प्राकृतिक कुंजियाँ खोज और रिपोर्टिंग के लिए उपयोगी बनी रहती हैं।
13. सामान्यीकरण एरडी को कैसे प्रभावित करता है? 📉
सामान्यीकरण डेटा को अतिरेक को कम करने के लिए संगठित करने की प्रक्रिया है। जैसे-जैसे आप सामान्यीकरण करते हैं, एरडी विकसित होता है।
- 1NF: दोहराए जाने वाले समूहों को हटाएं।
- 2NF: आंशिक निर्भरताओं को हटाएं।
- 3NF: स्थानांतरित निर्भरताओं को हटाएं।
उच्च स्तर के सामान्यीकरण के कारण आमतौर पर तालिकाओं और संबंधों की संख्या बढ़ जाती है। यह डेटा अखंडता में सुधार करता है, लेकिन प्रश्नों को जटिल बना सकता है। सामान्यीकरण के स्तर को प्रश्न प्रदर्शन की आवश्यकताओं के साथ संतुलित करें।
14. क्राउ के पैर बनाम चेन नोटेशन: कौन स्टैंडर्ड है? 👣
नोटेशन का अर्थ है कि संबंधों का दृश्य रूप से प्रतिनिधित्व कैसे किया जाता है।
- क्राउ के पैर: रेखाओं, क्रॉसेज और रेखाओं के अंत में गोलों जैसे प्रतीकों का उपयोग करता है। आधुनिक उपकरणों में बहुत आम।
- चेन: संबंधों के लिए हीरे और एकाधिकारों के लिए आयताकार आकृतियों का उपयोग करता है। अधिक शैक्षणिक।
क्राउ के पैर को आमतौर पर कार्यान्वयन के लिए प्राथमिकता दी जाती है क्योंकि यह SQL प्रतिबंधों के अधिक सीधे अनुरूप होता है। हालांकि, चेन नोटेशन उच्च स्तर के अवधारणात्मक मॉडलिंग के लिए उत्कृष्ट है।
15. ईआरडी बनाम डेटा फ्लो डायग्राम (DFD) 📊
इनका उपयोग सिस्टम डिजाइन चक्र में अलग-अलग उद्देश्यों के लिए किया जाता है।
- ईआरडी: ध्यान केंद्रित करता है डेटा संरचना और भंडारण। संबंधों का स्थिर दृश्य।
- DFD: ध्यान केंद्रित करता है डेटा गति और प्रक्रियाएं। डेटा के सिस्टम के माध्यम से प्रवाह के बारे में गतिशील दृश्य।
दोनों को गलती से न जाने। ईआरडी आपको बताता है कि कौन सा डेटा मौजूद है। डीएफडी आपको बताता है कि उस डेटा को कैसे प्रक्रिया किया जाता है। एक पूर्ण सिस्टम विवरण के लिए दोनों की आवश्यकता होती है।
मुख्य अवधारणाओं का सारांश 📝
| अवधारणा | मुख्य बात |
|---|---|
| प्राथमिक कुंजी | एक पंक्ति के लिए एकमात्र पहचानकर्ता। शून्य की अनुमति नहीं है। |
| विदेशी कुंजी | दूसरी तालिका की प्राथमिक कुंजी से जुड़ना। |
| कार्डिनैलिटी | अधिकतम संबंध (1, 1..N). |
| जंक्शन टेबल | बहु-से-बहु संबंधों को हल करता है। |
इन अंतरों को समझने से मजबूत डेटाबेस डिजाइन की संभावना होती है। लक्ष्य स्पष्टता, अखंडता और स्केलेबिलिटी है। अपने मॉडल को व्यावसायिक वास्तविकता के अनुरूप दिखाने के लिए इन बिंदुओं के खिलाफ अपने डायग्राम की समीक्षा करें।
इन 15 सामान्य भ्रमों को दूर करके आप ऐसे प्रणालियों के लिए आधार तैयार करते हैं जिन्हें आसानी से बनाए रखा और विस्तारित किया जा सकता है। डेटा सेमेंटिक्स पर ध्यान केंद्रित करें, और तकनीकी कार्यान्वयन स्वाभाविक रूप से आगे बढ़ेगा।

