











किसी डेटाबेस स्कीमा को देखना जो एक भारी धागे के गुच्छे जैसा लगता है, किसी भी डेटा आर्किटेक्ट या डेवलपर के लिए एक परिचित अनुभव है। आप अपने मॉडलिंग टूल को खोलते हैं, और अपने डेटा के स्पष्ट, तार्किक नक्शे के बजाय आपको लाइनों के एक दूसरे को काटते हुए, अस्पष्ट लेबल और ऐसे एंटिटीज दिखाई देते हैं जो तर्क के विरुद्ध लगते हैं। यह दृश्य अव्यवस्था केवल एक भौतिक समस्या नहीं है; यह संरचनात्मक ऋण का लक्षण है जो अंततः आपके समय, पैसे और सिस्टम स्थिरता को नुकसान पहुंचाएगा। 📉
जब कोई एंटिटी रिलेशनशिप डायग्राम (ERD) टूटा हुआ दिखता है, तो आमतौर पर इसका मतलब होता है कि नीचे के डिजाइन सिद्धांतों को नुकसान पहुंचा गया है। यह सिर्फ बॉक्सों के बीच लाइनें खींचने के बारे में नहीं है; यह आपके डेटा संबंधों की सच्चाई को परिभाषित करने के बारे में है। एक टूटा हुआ डायग्राम एक टूटे हुए डेटाबेस की ओर ले जाता है, जिसके परिणामस्वरूप धीमी जांच, डेटा असंगति और कठिन रखरखाव चक्र आते हैं। अच्छी खबर यह है कि इन समस्याओं को हल नहीं किया जा सकता है। डेटाबेस सिद्धांत के मूल और सदियों पुराने सिद्धांतों पर वापस लौटकर, आप अव्यवस्था में व्यवस्था ला सकते हैं। यह गाइड आपको लक्षणों के निदान, मूल कारणों को समझने और सिद्ध रणनीतियों को लागू करके अपने स्कीमा को ठीक करने में मदद करेगा। 🛡️
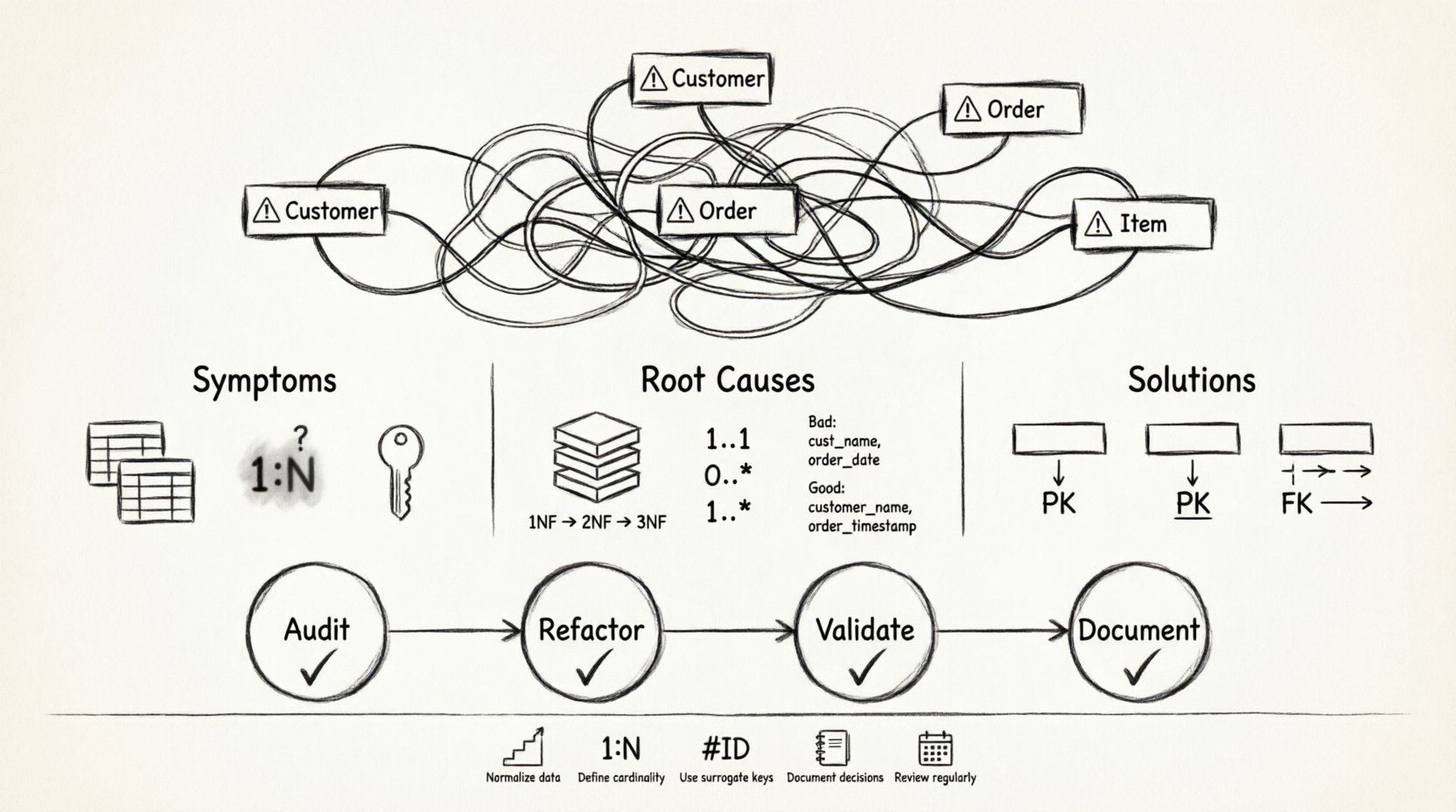
🔍 टूटे हुए ERD के लक्षणों की पहचान करना
किसी समस्या को ठीक करने से पहले, आपको उसके लक्षणों को पहचानना होगा। एक ऐसा डेटाबेस मॉडल जो ‘टूटा हुआ’ लगता है, अक्सर विशिष्ट दृश्य और तार्किक लाल झंडियां दिखाता है। ये संकेत इस बात की ओर इशारा करते हैं कि आपकी व्यावसायिक आवश्यकताओं और भौतिक भंडारण के बीच के अबस्ट्रैक्शन परत में कमी है।
- स्पैगेटी संबंध:लाइनें एक दूसरे को बिना नियंत्रण के काटती हैं, जिससे डेटा के प्रवाह को बिना भटके नहीं ट्रैक करना संभव होता है। यह तब होता है जब विदेशी कीज को स्पष्ट वर्गीकरण के बिना बिना तर्क के रखा जाता है।
- आवर्धित एंटिटीज: आपको दो या अधिक टेबल दिखाई देते हैं जो थोड़े अलग नामों के तहत एक ही जानकारी स्टोर करते हैं। उदाहरण के लिए, दोनों के साथ होना
ग्राहकऔरग्राहकटेबल बिना उनके डेटा स्कोप में स्पष्ट अंतर के। - अस्पष्ट कार्डिनैलिटी: एंटिटीज को जोड़ने वाली लाइनें संबंध के प्रकार को स्पष्ट रूप से परिभाषित नहीं करती हैं। क्या यह एक-एक है? एक-बहुत? बहुत-बहुत? यदि क्राउ के फुट नोटेशन गायब है या असंगत है, तो इरादा स्पष्ट नहीं है।
- चक्रीय निर्भरता: एंटिटी A एंटिटी B से संबंधित है, जो एंटिटी C से संबंधित है, जो एंटिटी A में वापस लौटती है। जबकि कभी-कभी आवश्यक होता है, लेकिन अक्सर डेटा को सही तरीके से नॉर्मलाइज न करने का संकेत होता है।
- कीज का अभाव: प्राथमिक कीज का अभाव है, या विदेशी कीज एक परिभाषित माता-पिता से जुड़ी नहीं हैं। इससे सिस्टम की संदर्भात्मक अखंडता टूट जाती है।
- अपरमाणु मान: एक ही कॉलम में एक से अधिक जानकारी के टुकड़े होते हैं, जैसे कि “पहला नाम” और “आखिरी नाम” एक ही फील्ड में जोड़े गए हों, या एक कॉमा से अलग किए गए स्ट्रिंग के रूप में स्टोर किए गए टैग की सूची।
जब आप इन लक्षणों को देखते हैं, तो डायग्राम यह संकेत दे रहा है कि डेटा मॉडल को लागू करने के लिए तैयार नहीं है। ऐसे डायग्राम के साथ आगे बढ़ना तकनीकी ऋण को आमंत्रित करता है। निम्नलिखित खंड इन समस्याओं को स्थापित सैद्धांतिक ढांचों के उपयोग से संबोधित करने के तरीकों को विस्तार से बताते हैं।
🧠 मूल कारण: मॉडल क्यों विफल होते हैं
एक ERD को टूटा हुआ क्यों दिखता है, इसकी समझ के लिए डिजाइन प्रक्रिया को देखने की आवश्यकता होती है। अधिकांश विफलताएं गति को संरचना के बजाय प्राथमिकता देने के कारण होती हैं। जब डेवलपर फीचर बनाने में जल्दबाजी करते हैं, तो वे अक्सर ऐसी टेबलें बनाते हैं जो तत्काल जांच की आवश्यकताओं के अनुरूप होती हैं, लेकिन व्यापक डेटा अखंडता की आवश्यकताओं को नजरअंदाज कर देते हैं।
1. नॉर्मलाइजेशन को नजरअंदाज करना
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता को कम किया जाता है और डेटा अखंडता में सुधार होता है। इस चरण को छोड़ना टूटे हुए स्कीमा का सबसे आम कारण है। नॉर्मलाइजेशन के बिना, आपको डेटा अनोमाली का खतरा होता है जहां एक जगह जानकारी के अपडेट करने पर वह सभी जगह अपडेट नहीं होती है।
- पहला सामान्य रूप (1NF): सुनिश्चित करता है कि प्रत्येक कॉलम में परमाणु मान हों। यदि कोई कॉलम सूची रखता है, तो टेबल 1NF में नहीं है।
- दूसरा सामान्य रूप (2NF): टेबल को 1NF में होने की आवश्यकता होती है और सुनिश्चित करता है कि सभी गैर-की विशेषताएं प्राथमिक की पर पूर्ण निर्भरता रखती हैं। इससे आंशिक निर्भरता रोकी जाती है।
- तृतीय सामान्य रूप (3NF):तालिका को 2NF में होने की आवश्यकता होती है और यह सुनिश्चित करता है कि कोई अनुक्रमिक निर्भरता नहीं है। दूसरे शब्दों में, गुणक विशेषताएँ अन्य गुणक विशेषताओं पर निर्भर नहीं होनी चाहिए।
यदि आपका आरेख ऐसे कॉलम दिखाता है जो केवल कुंजी पर नहीं बल्कि अन्य कॉलम पर निर्भर हैं, तो आपके पास नॉर्मलाइजेशन की समस्या है। इसके लिए अक्सर बहुत चौड़ी तालिकाएँ बनती हैं जिन्हें प्रभावी ढंग से प्रश्न करना मुश्किल होता है।
2. कार्डिनैलिटी का गलत समझ
कार्डिनैलिटी एकताओं के बीच संख्यात्मक संबंध को परिभाषित करती है। इसकी गलत व्याख्या करने से अक्षम जॉइन और जटिल प्रश्न बनते हैं। एक सामान्य गलती यह है कि बहु-से-बहु संबंध को दो तालिकाओं के बीच सीधे संबंध के रूप में मॉडल करना। वास्तविकता में, मानक संबंधात्मक संरचनाओं में बीच की तालिका के बिना सीधा संबंध नहीं हो सकता।
- एक-से-एक:सुरक्षा या विशिष्ट डेटा के लिए उपयोग किया जाता है। उच्च ट्रैफिक वाले प्रणालियों में दुर्लभ रूप से उपयोग किया जाता है।
- एक-से-बहु:सबसे आम संबंध। एक माता-पिता के कई बच्चे हो सकते हैं।
- बहु-से-बहु:एक जंक्शन तालिका की आवश्यकता होती है। इस ब्रिज को बनाने में विफलता डेटा अखंडता की समस्या उत्पन्न करती है।
3. खराब नामकरण प्रणाली
एक आरेख जिसे पढ़ना मुश्किल हो, वह आरेख है जिसका गलत उपयोग किया जाएगा। असंगत नामकरण, जैसे snake_case और camelCase का मिश्रण करना, या सामान्य नामों का उपयोग करना जैसे तालिका1 और तालिका2कॉग्निटिव लोड बनाता है। जब डेवलपर्स को तालिका का अर्थ तुरंत समझ नहीं आता है, तो वे ऐसी मान्यताएँ बनाते हैं जो बग्स के कारण बनती हैं।
🛠️ पुनर्स्थापन के लिए सदैव उपयोगी सिद्धांत
टूटे हुए आरेख को ठीक करने के लिए आपको नए उपकरण या ट्रेंडी विधियों की आवश्यकता नहीं है। आपको संबंधात्मक सिद्धांत के मूल सिद्धांतों को लागू करने की आवश्यकता है। इन सिद्धांतों को समय के परीक्षण में बने रहने के कारण है क्योंकि वे डेटा की मूल प्रकृति को संबोधित करते हैं।
1. परमाणुता और विभाजनता
परमाणुता के सिद्धांत के अनुसार, आपकी तालिका में प्रत्येक सेल में केवल एक मान होना चाहिए। यदि आपके पास “पता” के लिए एक कॉलम है, तो इसे आदर्श रूप से “सड़क”, “शहर”, “राज्य” और “पिन कोड” में विभाजित किया जाना चाहिए। इससे आप तार्किक रूप से स्ट्रिंग के विश्लेषण के बिना पते के विशिष्ट हिस्सों को प्रश्न कर सकते हैं। इस विभाजनता आपके डेटा को भविष्य की रिपोर्टिंग आवश्यकताओं के लिए अधिक लचीला बनाती है।
2. अद्वितीय पहचान
प्रत्येक एंटिटी को एक अद्वितीय पहचानकर्ता की आवश्यकता होती है। यह आपकी प्राथमिक कुंजी है। इसके बिना, आप एक विशिष्ट पंक्ति को भरोसे से संदर्भित नहीं कर सकते। यदि आपके आरेख में स्पष्ट प्राथमिक कुंजियाँ नहीं हैं, या यदि आप प्राकृतिक कुंजियों पर निर्भर हैं जो बदल सकती हैं (जैसे ईमेल पता), तो आप डेटा विचलन के जोखिम में हैं। आंतरिक स्थिरता के लिए सुरोगेट कुंजियों (जैसे स्वतः बढ़ते पूर्णांक या UUIDs) का उपयोग करें।
3. संदर्भात्मक अखंडता
इस सिद्धांत के अनुसार तालिकाओं के बीच के संबंध वैध रहते हैं। यदि आप एक ग्राहक को हटाते हैं, तो उनके आदेशों का क्या होता है? आरेख को हटाने और अद्यतन के नियमों को दर्शाना चाहिए। इसका अक्सर विदेशी कुंजियों के माध्यम से प्रबंधन किया जाता है। टूटे हुए आरेख में अक्सर विदेशी कुंजियाँ ऐसी होती हैं जो किसी चीज की ओर इशारा नहीं करतीं या वहाँ जहाँ वे नहीं होनी चाहिए, नल मानों की अनुमति देती हैं।
4. चिंताओं का अलगाव
अलग-अलग अवधारणाओं को अलग-अलग तालिकाओं में रखें। एक बात के अलावा उपयोगकर्ता प्रोफाइल डेटा को प्रमाणीकरण क्रेडेंशियल्स के साथ एक ही तालिका में मिलाएं नहीं। इस अलगाव के कारण आप डेटा के अलग-अलग हिस्सों को अलग-अलग तरीके से स्केल और सुरक्षित कर सकते हैं।
📊 सामान्य त्रुटियाँ बनाम मानक समाधान
नीचे दी गई तालिका खराब डिज़ाइन वाले ERD में पाए जाने वाली सामान्य त्रुटियों और डेटाबेस सिद्धांत पर आधारित मानक सुधारात्मक कार्रवाई का सारांश देती है।
| त्रुटि | दृश्य लक्षण | मूल कारण | मानक समाधान |
|---|---|---|---|
| आवर्धित डेटा | एक ही जानकारी बहुत सारी तालिकाओं में | 3NF का उल्लंघन | तालिकाओं को सामान्यीकृत करें; दोहराए गए कॉलम हटाएं |
| अनुपस्थित संबंध | अलग-अलग बॉक्स | मान लिया गया तर्क | स्पष्ट विदेशी कुंजियाँ परिभाषित करें |
| बहु-से-बहु सीधा संबंध | दो बहु-पक्षीय इकाइयों को जोड़ने वाली रेखा | संबंधात्मक सीमा | एक संयोजन तालिका पेश करें |
| मिश्रित कुंजियाँ | प्राथमिक कुंजी के रूप में बहुत सारे कॉलम | जटिलता का जोखिम | जहां संभव हो, एक सुरोगेट कुंजी का उपयोग करें |
| नल-भरे कॉलम | एक कॉलम में बहुत सारी खाली सेलें | वैकल्पिक डेटा का गलत प्रबंधन | वैकल्पिक गुणों के लिए अलग तालिकाएँ बनाएँ |
| स्पैगेटी तर्क | हर जगह लाइनों का प्रतिच्छेदन | रीफैक्टरिंग छोड़ दी गई | एकाधिक इकाइयों को क्षेत्र के अनुसार समूहित करें; तार्किक रूप से फिर से बनाएँ |
🔄 मरम्मत प्रक्रिया: एक चरण-दर-चरण ढांचा
टूटे हुए आरेख को ठीक करना एक व्यवस्थित प्रक्रिया है। इसमें धैर्य और पुनर्गठन करने की इच्छा की आवश्यकता होती है। ठीक करने के लिए जल्दबाजी न करें; पहले वर्तमान स्थिति को समझें।
चरण 1: ऑडिट
शुरुआत में वह बताएं जो मौजूद है। नहीं मानें कि आप हर टेबल के काम के बारे में जानते हैं। प्रत्येक कॉलम के उद्देश्य और अपेक्षित डेटा प्रकार का वर्णन करने वाला एक डेटा शब्दकोश बनाएं। इससे आपको स्कीमा की वास्तविकता का सामना करना पड़ता है। सूचियां संग्रहीत करने वाले कॉलम, तारों के रूप में संग्रहीत तारीखें, या टेक्स्ट के साथ मिले हुए आईडी की तलाश करें।
- सभी संस्थाओं और उनके गुणों की सूची बनाएं।
- सभी मौजूदा संबंधों और उनके प्रकारों की पहचान करें।
- किसी भी डेटा को उजागर करें जो अतिरिक्त या अस्पष्ट लगता है।
चरण 2: पुनर्गठन
जब आप ऑडिट प्राप्त कर लें, तो नॉर्मलाइजेशन नियमों को लागू करें। चौड़ी टेबलों को संकीर्ण टेबलों में बांटें। दोहराए जाने वाले समूहों को अलग टेबल में स्थानांतरित करें। सुनिश्चित करें कि प्रत्येक टेबल में प्राथमिक कुंजी है। यदि आपको ब्रिज टेबल के बिना बहु-से-बहु संबंध मिलता है, तो एक बनाएं। इस चरण में ही भारी काम होता है।
व्यावसायिक नियमों पर विचार करें। यदि एक उपयोगकर्ता के कई पते हो सकते हैं, तो पता टेबल को उपयोगकर्ता टेबल से स्वतंत्र रूप से मौजूद होना चाहिए। संबंध लिंकिंग टेबल या विदेशी कुंजी के माध्यम से प्रबंधित किया जाता है, जो विशिष्ट प्रतिबंध पर निर्भर करता है।
चरण 3: प्रमाणीकरण
पुनर्गठन के बाद, नए डिज़ाइन की पुष्टि करें। चक्रीय निर्भरता की जांच करें। सुनिश्चित करें कि एक रिकॉर्ड को हटाने से अन्य रिकॉर्ड असहाय नहीं होते हैं, जब तक यह इच्छित नहीं है। सुनिश्चित करें कि सभी विदेशी कुंजियां मान्य प्राथमिक कुंजियों की ओर इशारा करती हैं। अपनी मूल आवश्यकताओं के खिलाफ एक संतुलन जांच चलाएं ताकि नए संरचना अभी भी आवश्यक प्रश्नों का समर्थन करे।
चरण 4: दस्तावेज़ीकरण
एक दस्तावेज़ीकृत नहीं डायग्राम एक ऐसा डायग्राम है जो फिर से टूट जाएगा। अपने संस्थाओं में टिप्पणियां जोड़ें। जटिल संबंधों के पीछे के व्यावसायिक तर्क की व्याख्या करें। इससे यह सुनिश्चित होता है कि भविष्य के डेवलपर्स संरचना के “क्यों” को समझें, केवल “क्या” के बजाय।
🛡️ लंबे समय तक अखंडता बनाए रखना
यहां तक कि एक आदर्श डिज़ाइन किया गया डायग्राम भी समय के साथ खराब हो सकता है। आवश्यकताओं में परिवर्तन होने, नए फीचर्स जोड़े जाने और त्वरित रास्ते अपनाए जाने के कारण। एक स्वस्थ स्कीमा बनाए रखने के लिए आपको एक रखरखाव रणनीति की आवश्यकता होती है।
- नियमित समीक्षाएं:अपने स्कीमा की नियमित समीक्षा की योजना बनाएं। एंट्रॉपी के संकेतों की तलाश करें। क्या नए टेबल उसी नामकरण प्रथा का पालन कर रहे हैं? क्या संबंध संगत हैं?
- संस्करण नियंत्रण:अपने ईआरडी को कोड की तरह लें। इसे एक संस्करण नियंत्रण प्रणाली में स्टोर करें। इससे आप समय के साथ बदलावों को ट्रैक कर सकते हैं और यदि कोई बदलाव त्रुटियां लाता है तो वापस ले सकते हैं।
- प्रतिबंध लागू करना:डायग्राम में परिभाषित नियमों को लागू करने के लिए डेटाबेस प्रतिबंधों का उपयोग करें। अवैध डेटा को रोकने के लिए केवल एप्लिकेशन तर्क पर भरोसा न करें। यदि डायग्राम कहता है कि एक फील्ड अनिवार्य है, तो डेटाबेस को इसे लागू करना चाहिए।
- समुदाय मानक:अपने संगठन के लिए एक मानक अपनाएं। चाहे वह नामकरण प्रथा, कुंजी प्रकार, या संबंध निरूपण हो, संगतता घर्षण को कम करती है।
📝 उत्तम व्यवहार का सारांश
एक टिकाऊ डेटाबेस स्कीमा बनाना अनुशासन के बारे में है। यह लंबे समय तक स्थिरता के नुकसान के बदले चीजों को तेजी से काम करने की इच्छा को रोकने के बारे में है। इन सिद्धांतों का पालन करके, आप सुनिश्चित करते हैं कि आपका डेटा मॉडल लचीला और विश्वसनीय बना रहे।
- हमेशा अपने डेटा को नॉर्मलाइज़ करें ताकि अतिरिक्तता कम हो।
- प्रत्येक संबंध के लिए स्पष्ट कार्डिनैलिटी परिभाषित करें।
- स्थिरता के लिए सरोगेट कुंजियों का उपयोग करें।
- अपने निर्णयों और व्यावसायिक नियमों को दस्तावेज़ीकृत करें।
- क्षय को रोकने के लिए अपने स्कीमा की नियमित समीक्षा करें।
टूटा हुआ ईआर डायग्राम एक विफलता नहीं है; यह आपके डेटा के बारे में अपनी समझ को बेहतर बनाने का अवसर है। इन सदियों से अनुभवी सिद्धांतों के अनुप्रयोग से, आप एक अव्यवस्थित गड़बड़ी को एक संरचित संपत्ति में बदलते हैं जो आपके एप्लिकेशन के विकास का समर्थन करती है। आज अपने डायग्राम को साफ करने में आपका निवेश कल डिबगिंग के हजारों घंटों को बचाता है। 🚀
याद रखें, लक्ष्य केवल बॉक्सों के बीच रेखाएं खींचना नहीं है। लक्ष्य एक नक्शा बनाना है जो आपके व्यावसायिक डेटा की वास्तविकता को सही तरीके से दर्शाता है। जब आपका डायग्राम अखंडता, नॉर्मलाइजेशन और स्पष्टता के सिद्धांतों के अनुरूप होता है, तो आपका डेटाबेस एक आधार बन जाता है जिस पर आप आत्मविश्वास के साथ बनावट कर सकते हैं।

