











Les schémas de bases de données évoluent souvent de manière organique plutôt que par une conception intentionnelle. Au fil du temps, les cycles rapides de développement, le manque de documentation et les exigences commerciales changeantes entraînent des structures complexes et difficiles à naviguer. De nombreuses organisations se retrouvent héritières de systèmes hérités où les architectes d’origine ne sont plus disponibles, et le modèle de données est obscurci par des années de correctifs et de solutions d’urgence. Ce processus consiste à analyser les couches de données existantes et à les reconstruire sous la forme d’un diagramme de relations d’entités (ERD) standardisé. L’objectif est la clarté, la maintenabilité et l’intégrité.
L’ingénierie inverse d’une base de données ne consiste pas seulement à tracer des lignes entre les tables ; il s’agit de comprendre la logique métier intégrée dans les données. Un ERD propre sert de plan directeur pour le développement futur, d’outil de communication pour les parties prenantes et de garde-fou contre la corruption des données. Ce guide détaille le flux technique pour transformer un schéma chaotique en une conception structurée et normalisée, sans dépendre d’outils propriétaires spécifiques.
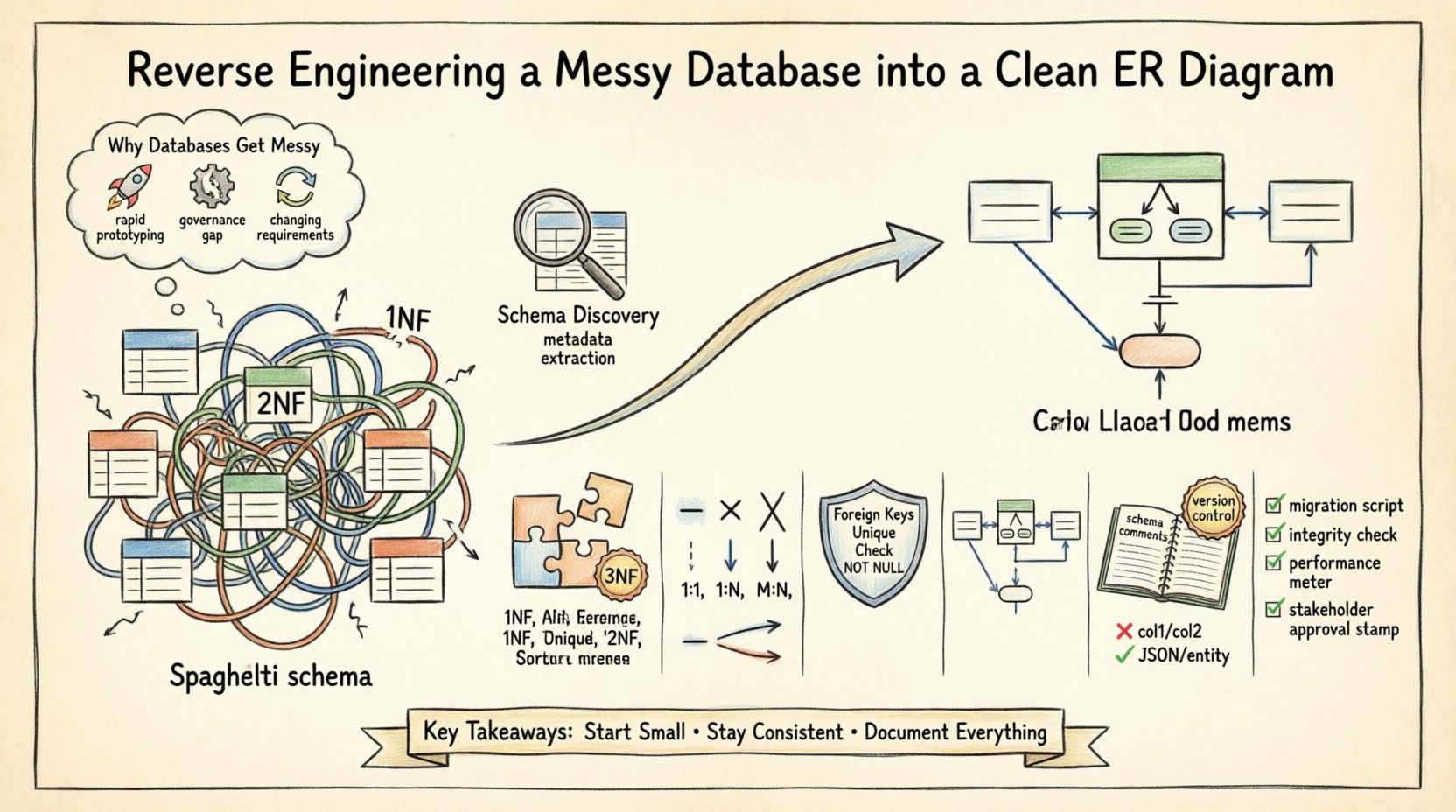
Pourquoi les bases de données deviennent-elles désordonnées 📉
Comprendre la cause racine de la dette du schéma est la première étape vers sa correction. Plusieurs facteurs contribuent à une structure de base de données désorganisée :
- Prototypage rapide :Le développement initial privilégie souvent la vitesse plutôt que la structure. Les tables sont créées de manière ponctuelle pour satisfaire des demandes fonctionnelles immédiates, sans tenir compte de l’évolutivité à long terme.
- Manque de gouvernance :Lorsque plusieurs développeurs modifient le schéma sans processus de revue centralisé, les conventions de nommage divergent et des colonnes redondantes apparaissent.
- Changements de logique métier :Lorsque les exigences évoluent, les tables sont modifiées pour intégrer de nouveaux champs. Les clés étrangères sont parfois supprimées pour contourner les contraintes, ce qui entraîne des enregistrements orphelins.
- Manques de documentation :Les commentaires et les descriptions de métadonnées sont souvent omis lors du déploiement initial, ce qui rend difficile la compréhension de l’intention derrière des colonnes spécifiques ultérieurement.
Ces problèmes entraînent ce qu’on appelle souvent un « schéma spaghetti ». Les relations deviennent implicites plutôt que explicites, et les clés primaires peuvent être perdues ou dupliquées sur plusieurs tables. Les sections suivantes décrivent l’approche systématique pour résoudre ces problèmes.
Phase 1 : Découverte et profilage du schéma 🔍
Avant de tracer la moindre ligne, vous devez comprendre l’état actuel de la base de données. Cette phase se concentre sur l’extraction et l’analyse plutôt que sur la modification.
Extraction des métadonnées
Chaque système de gestion de base de données relationnelle maintient des catalogues système ou des vues de schéma d’information. Ces répertoires contiennent des détails sur les tables, les colonnes, les types de données, les contraintes et les index. Utilisez des interfaces de requête pour récupérer ces métadonnées.
- Liste des tables :Récupérez tous les noms de tables ainsi que leurs dates de création afin d’identifier les structures héritées.
- Définitions des colonnes :Extrayez les noms de colonnes, les types de données, la possibilité de valeurs nulles et les valeurs par défaut.
- Contraintes :Identifiez les clés primaires, les contraintes uniques et les relations de clés étrangères. Notez que certaines relations peuvent être appliquées uniquement au niveau de l’application, et non dans la base de données.
- Index :Analysez les index existants pour comprendre les modèles de performance des requêtes et identifier des clés candidates potentielles.
Profilage des données
Les métadonnées vous disent ce que le schéma *devrait* être, mais le profilage des données vous indique ce qu’il *est*. L’analyse des valeurs réelles des données révèle des incohérences que les définitions de schéma négligent.
- Répartition des valeurs :Vérifiez les colonnes à haute ou basse cardinalité, qui pourraient indiquer un besoin de normalisation.
- Taux de valeurs nulles :Des taux élevés de valeurs nulles dans des champs obligatoires suggèrent des contraintes manquantes ou de mauvaises pratiques de saisie des données.
- Qualité des données :Identifiez les incohérences de format, telles que les numéros de téléphone stockés sous forme de texte avec des formats variés.
Phase 2 : Identification et normalisation des entités 🧱
Une fois les données brutes comprises, la prochaine étape consiste à restructurer logiquement les données. Cela implique l’identification des entités et l’application de règles de normalisation afin de réduire la redondance.
Identification des entités
Une entité représente un objet ou un concept distinct au sein du domaine métier. Dans une base de données désordonnée, les entités sont souvent réparties sur plusieurs tables ou combinées de manière incorrecte.
- Granularité :Assurez-vous qu’une table représente une seule notion. Si une table contient à la fois des informations sur les clients et des informations sur les commandes, elle viole probablement les principes de normalisation.
- Clés primaires :Établissez un identifiant unique pour chaque entité. Évitez d’utiliser des clés naturelles (comme les adresses e-mail) si elles sont sujettes à modification ; utilisez plutôt des clés surrogées.
- Conventions de nommage :Standardisez les noms de table selon un format cohérent, par exemple des noms au singulier (par exemple,
clientau lieu declients).
Application de la normalisation
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien que l’objectif ne soit pas toujours d’atteindre le maximum théorique (forme normale de Boyce-Codd), viser la Troisième Forme Normale (3NF) constitue une norme solide pour les systèmes transactionnels.
| Forme | Définition | Objectif |
|---|---|---|
| Première Forme Normale (1NF) | Valeurs atomiques dans les colonnes ; pas de groupes répétés. | Assurez-vous que chaque cellule contient une seule valeur. |
| Deuxième Forme Normale (2NF) | Répond à la 1NF et élimine les dépendances partielles. | Assurez-vous que les attributs non clés dépendent de la clé primaire entière. |
| Troisième Forme Normale (3NF) | Répond à la 2NF et élimine les dépendances transitives. | Assurez-vous que les attributs non clés dépendent uniquement de la clé primaire. |
Lors de la conception inverse, recherchez les colonnes qui stockent des listes de valeurs (par exemple, une chaîne séparée par des virgules d’étiquettes). Elles doivent être divisées en lignes distinctes dans une table d’association afin de satisfaire la 1NF. De même, les attributs qui décrivent des entités différentes (par exemple, nom_produit et adresse_fournisseur dans la même table) doivent être séparés en entités distinctes afin de satisfaire la 2NF et la 3NF.
Phase 3 : Mappage des relations 🔗
Les relations définissent la manière dont les entités interagissent. Dans une base de données désordonnée, celles-ci sont souvent implicites ou absentes. Cette phase consiste à définir la cardinalité et l’optionnalité de ces connexions.
Types de cardinalité
- Un à un (1:1) : Une ligne dans la table A est associée à exactement une ligne dans la table B. Cela est rare et indique souvent une séparation pour des raisons de sécurité ou de performance.
- Un à plusieurs (1:N) : Une ligne dans la table A est associée à plusieurs lignes dans la table B. C’est la relation la plus courante (par exemple, un client passe plusieurs commandes).
- Plusieurs à plusieurs (M:N) : Plusieurs lignes dans la table A sont associées à plusieurs lignes dans la table B. Cela nécessite une table d’association intermédiaire (par exemple, Étudiants et Cours).
Résolution des relations plusieurs à plusieurs
Les bases de données désordonnées tentent souvent de gérer les relations plusieurs à plusieurs en dupliquant des données ou en créant des tables larges avec plusieurs colonnes de clés étrangères. La bonne approche consiste à introduire une table de pont.
- Identifiez les deux entités parentes.
- Créez une nouvelle table contenant les clés primaires des deux parents.
- Ajoutez tout attribut spécifique lié à la relation elle-même (par exemple,
date_inscriptiondans une table de pont Étudiant-Cours).
Phase 4 : Contraintes et intégrité des données 🔒
Un schéma est inutile s’il ne met pas en œuvre les règles qu’il illustre. La mise en œuvre physique doit refléter la conception logique à travers des contraintes.
- Clés étrangères :Définissez explicitement les contraintes de clés étrangères pour éviter les enregistrements orphelins. Cela garantit automatiquement l’intégrité référentielle.
- Contraintes uniques :Appliquez des contraintes uniques aux colonnes qui doivent être distinctes (par exemple, adresses e-mail, noms d’utilisateur).
- Contraintes de vérification : Utilisez les contraintes de vérification pour valider les formats ou les plages de données (par exemple,
age >= 0). - Non nul :Marquez les champs essentiels comme étant
NON NULpour garantir l’intégrité des données.
Phase 5 : Visualisation du MCD 🎨
Une fois le modèle logique établi, il doit être visualisé. Bien qu’un logiciel spécifique existe à cet effet, les principes de représentation graphique restent constants.
Normes de représentation graphique
Choisissez une norme de notation pour garantir que le diagramme soit lisible par différents acteurs.
- Notation en pied de corbeau :Utilisée couramment dans l’industrie. Utilise des symboles spécifiques pour indiquer la cardinalité (par exemple, une ligne simple pour « un », un pied de corbeau pour « plusieurs »).
- Diagrammes de classes UML :Utilise des boîtes et des flèches, souvent préférée par les développeurs logiciels familiers avec la conception orientée objet.
- Notation de Chen :Utilise des losanges pour les relations, courant dans les milieux académiques mais moins fréquent dans les outils d’entreprise modernes.
Meilleures pratiques de mise en page
- Regroupement :Regroupez les tables liées ensemble (par exemple, toutes les tables Commande dans une même zone) pour montrer des domaines logiques.
- Direction du flux :Organisez les diagrammes pour qu’ils s’écoulent logiquement de gauche à droite ou du haut vers le bas.
- Lisibilité :Assurez-vous que les noms de table soient clairement visibles et que les croisements de lignes soient minimisés.
Phase 6 : Documentation et maintenance 📝
Un diagramme statique est une capture d’écran. Pour garantir une valeur à long terme, la documentation doit être maintenue conjointement au code.
Commentaires du schéma
Utilisez les commentaires de colonne et de table pour expliquer la logique métier. Par exemple, une colonne nommée statut doit avoir un commentaire expliquant quels sont les valeurs valides (par exemple, « 0 : En attente, 1 : Approuvé, 2 : Rejeté »).
Contrôle de version
Stockez les fichiers ERD et de définition du schéma dans un système de contrôle de version. Cela vous permet de suivre les modifications au fil du temps et de revenir en arrière si nécessaire.
Paterns courants à éviter 🚫
Pendant le processus de nettoyage, soyez vigilant face aux pièges courants.
| Anti-patrons | Problème | Solution |
|---|---|---|
| Colonnes de données génériques | Utilisation de colonnes telles quecol1, col2 pour un stockage flexible. |
Remplacez par une colonne JSON ou une nouvelle table d’entité. |
| Clés composées | Utilisation de plusieurs colonnes comme clé primaire. | Préférez les clés surrogées (entiers auto-incrémentés) pour plus de simplicité. |
| Dénormalisation pour la vitesse | Duplication des données pour éviter les jointures. | Acceptez le coût de performance des jointures, sauf si le profilage prouve le contraire. |
Phase 7 : Validation et tests ✅
Après le restructurage, le nouveau schéma doit être validé par rapport aux données existantes.
- Scripts de migration : Écrivez des scripts pour déplacer les données du vieux schéma vers le nouveau. Assurez-vous qu’aucune donnée n’est perdue pendant le transfert.
- Vérifications d’intégrité référentielle : Exécutez des requêtes pour vous assurer que toutes les clés étrangères pointent vers des enregistrements parents valides.
- Tests de performance : Exécutez l’application contre le nouveau schéma pour vérifier que les performances des requêtes restent acceptables.
- Revue par les parties prenantes : Présentez le diagramme aux utilisateurs métiers pour confirmer qu’il reflète fidèlement leurs processus.
Considérations finales 🏁
L’ingénierie inverse d’une base de données est une tâche importante qui exige de la patience et de la précision. Ce n’est pas une tâche ponctuelle, mais une partie d’un cycle continu de gouvernance des données. En suivant une approche structurée, les organisations peuvent transformer des répertoires de données chaotiques en actifs fiables.
Souvenez-vous que le schéma est un outil de communication. Si les parties prenantes métier ne peuvent pas comprendre les relations représentées, l’effort technique n’a pas pleinement réussi. Les revues régulières du schéma garantissent que le développement futur s’aligne sur l’architecture établie.
Concentrez-vous sur la cohérence. Que ce soit les conventions de nommage, les définitions de contraintes ou les styles de schémas, l’uniformité réduit la charge cognitive pour tous ceux qui interagissent avec le système. Commencez petit. Choisissez un module ou un domaine, nettoyez-le et documentez-le soigneusement. Ensuite, étendez ce processus aux autres domaines. Cette approche progressive réduit les risques et permet une amélioration continue.
En fin de compte, une structure ERD propre est la fondation d’une stratégie de données solide. Elle permet aux développeurs de construire des fonctionnalités plus rapidement et réduit la probabilité de perte ou de corruption des données. Investissez du temps maintenant pour bénéficier de la stabilité et de la clarté à l’avenir.

