











Construire une architecture backend solide exige plus que la rédaction de code efficace ; il demande une compréhension fondamentale de la manière dont les données sont structurées, stockées et récupérées sous pression. Au cœur de cette infrastructure se trouve le diagramme Entité-Relation (ERD). Bien qu’il soit souvent considéré comme un plan statique établi pendant la phase initiale de planification, un ERD bien conçu constitue le socle dynamique des systèmes à fort trafic. Lorsque le trafic augmente brusquement, le schéma de la base de données détermine les performances, la latence et la disponibilité. Un modèle mal structuré peut entraîner des défaillances en chaîne, tandis qu’une conception évolutive s’adapte à la croissance de manière fluide.
Ce guide explore les subtilités techniques de la construction de diagrammes ER capables de résister à de fortes charges. Nous allons aller au-delà de la normalisation basique et examiner comment les relations, les contraintes et les stratégies de stockage physique interagissent dans des environnements distribués. Que vous conceviez pour des millions d’utilisateurs simultanés ou simplement planifiez une expansion future, les principes décrits ici fournissent un cadre pour un modélisation de données résiliente.
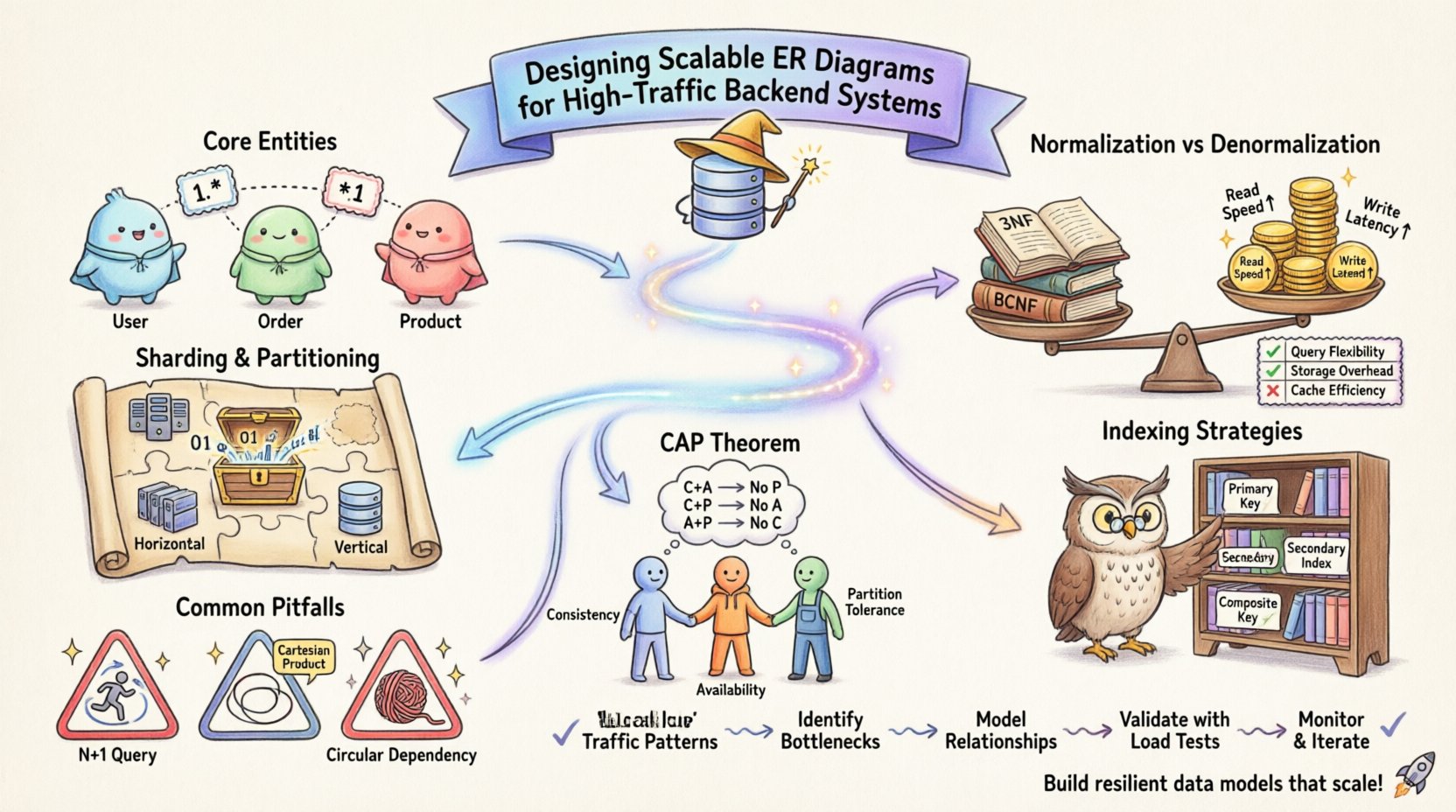
🏗️ Comprendre la modélisation Entité-Relation à grande échelle
L’unité fondamentale d’un diagramme ER est l’entité, représentant un objet ou un concept distinct au sein de votre système. Dans un environnement à faible trafic, la simplicité règne souvent en maître. Toutefois, à mesure que le volume des transactions augmente, la complexité des interactions entre les entités croît de manière exponentielle. Les systèmes à fort trafic exigent un changement de perspective, passant de « comment ces données doivent-elles apparaître ? » à « comment ces données vont-elles performer sous charge ? ».
- Identifier les entités principales : Déterminez quels objets de données sont les plus fréquemment consultés. Ce sont vos chemins critiques.
- Analyser la cardinalité : Définissez les relations entre les entités. Les relations un-à-plusieurs, plusieurs-à-plusieurs et un-à-un ont chacune des implications de performance différentes.
- Granularité des attributs : Décidez de la quantité de détail à stocker dans un attribut. Des attributs trop granulaires peuvent alourdir la taille des lignes, tandis que des attributs trop généraux peuvent nuire à la précision des requêtes.
Lors de la conception à grande échelle, la disposition physique des données devient aussi importante que la structure logique. Le diagramme ER doit refléter non seulement la logique métier, mais aussi les contraintes opérationnelles du moteur de stockage. Par exemple, certains systèmes gèrent le verrouillage au niveau des lignes différemment du verrouillage au niveau des pages. Votre diagramme doit anticiper ces contraintes en minimisant les points de contention.
📊 Normalisation vs. Dénormalisation : le compromis de performance
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien qu’elle soit traditionnellement enseignée comme une meilleure pratique universelle, les systèmes à fort trafic exigent souvent une approche équilibrée. Une application stricte de la Troisième Forme Normale (3NF) peut entraîner un nombre excessif d’opérations de jointure. Dans un environnement distribué ou à haute concurrence, les jointures sur plusieurs tables peuvent devenir des goulets d’étranglement importants.
Inversement, la dénormalisation consiste à dupliquer des données afin de réduire le besoin de jointures. Cette stratégie améliore les performances de lecture, mais complique les opérations d’écriture. Vous devez maintenir la cohérence entre les champs dupliqués, ce qui ajoute de la logique à votre couche d’application.
| Stratégie | Performance de lecture | Performance d’écriture | Consistance des données | Coût de stockage |
|---|---|---|---|---|
| Normalisation complète | Faible (multiples jointures) | Élevée (écriture unique) | Élevée | Faible |
| Dénormalisation partielle | Élevée (moins de jointures) | Modérée (mise à jour de la duplication) | Modérée | Modérée |
| Dénormalisation complète | Très élevé | Faible (logique complexe) | Faible (nécessite une synchronisation) | Élevé |
Le choix du bon équilibre dépend de votre ratio lecture-écriture. Si votre système est orienté lecture, comme un flux de contenu ou une plateforme d’actualités, la dénormalisation est souvent nécessaire. Si votre système est orienté écriture, comme un registre de transactions, la normalisation aide à prévenir les anomalies.
🌐 Stratégies d’optimisation des lectures et des écritures
Optimiser pour un fort trafic implique des techniques spécifiques qui influencent la forme de votre MCD. Ces stratégies se concentrent sur la réduction du temps nécessaire pour récupérer ou stocker des informations.
1. Stratégies de mise en cache reflétées dans le schéma
Lors de la conception de votre modèle de données, envisagez la manière dont les données seront mises en cache. Les entités fréquemment consultées doivent être structurées pour permettre une sérialisation facile. Évitez de stocker de grandes données binaires de longueur variable dans des tables fréquemment jointes. Au lieu de cela, stockez une clé de référence et récupérez le blob séparément lorsque nécessaire. Cela réduit la pression mémoire sur la couche principale de cache.
2. Clés de partitionnement et de fractionnement
À mesure que les données augmentent, le stockage dans une seule table devient inefficace. Le fractionnement divise les données sur plusieurs nœuds. Votre MCD doit définir clairement une clé de fractionnement. Cette clé détermine la répartition des lignes. Si la clé de fractionnement est mal choisie, vous pouvez vous retrouver avec des « partitions chaudes » où un nœud gère significativement plus de trafic que les autres.
- Fractionnement horizontal : Divise les lignes selon une clé. Le MCD doit montrer comment la clé est répartie.
- Fractionnement vertical : Divise les colonnes entre plusieurs tables. Utile pour séparer les colonnes volumineuses (comme les journaux) des données transactionnelles principales.
🔗 Gestion des relations dans les données fractionnées
Les relations sont le ciment qui maintient une base de données ensemble, mais dans un système distribué, elles peuvent devenir une source de latence. Les clés étrangères garantissent l’intégrité référentielle, mais dans un environnement fractionné, appliquer ces contraintes à travers les nœuds est coûteux.
Gestion des relations plusieurs-à-plusieurs
Les relations plusieurs-à-plusieurs nécessitent une table de jonction. Dans un scénario à fort trafic, cette table peut devenir un goulot d’étranglement. Si vous interrogez fréquemment, envisagez de dénormaliser la relation. Au lieu de joindre la table de jonction, stockez l’identifiant de relation directement sur l’entité parente si la cardinalité le permet. Cela réduit la profondeur de la requête.
Entités auto-référentielles
Certaines entités se référencent elles-mêmes, comme les catégories ou les commentaires hiérarchiques. Concevez ces relations avec soin. Une récursion profonde dans les requêtes peut épuiser les ressources système. Limitez la profondeur des chaînes auto-référentielles dans votre logique, ou aplatissez la structure lorsque cela est possible en utilisant des chemins matérialisés.
🔍 Stratégies d’indexation pour les performances
Un MCD définit la structure logique, mais les index définissent la vitesse de récupération physique. Bien que le schéma lui-même ne montre pas les index, les décisions de conception influencent les index qui sont viables.
- Clés primaires : Elles sont regroupées dans de nombreux systèmes, ce qui signifie que les données sont physiquement triées selon cette clé. Choisissez une clé primaire qui minimise la fragmentation et assure une répartition équitable.
- Index secondaires : Chaque index consomme des performances d’écriture. Ajouter trop d’index ralentit les opérations d’insertion et de mise à jour. Indexez uniquement les colonnes fréquemment utilisées dans les clauses `WHERE`, `JOIN` ou `ORDER BY`.
- Index composés : Lorsque plusieurs colonnes sont interrogées ensemble, un index composé peut être plus efficace. L’ordre des colonnes dans l’index est important et doit correspondre aux modèles de requête les plus courants.
⚖️ Cohérence vs Disponibilité dans les schémas distribués
La théorie des bases de données aborde souvent le théorème CAP, qui suggère qu’un système ne peut garantir que deux propriétés sur les trois suivantes : cohérence, disponibilité et tolérance aux partitions. Votre conception du schéma ERD influence celle que vous privilégiez.
Si vous privilégiez la cohérence, vous concevrez avec des clés étrangères strictes et des transactions ACID. Cela garantit l’intégrité des données, mais peut entraîner une latence pendant les partitions réseau. Si vous privilégiez la disponibilité, vous pourriez assouplir les contraintes, permettant des incohérences temporaires. Dans ce cas, votre schéma ERD doit soutenir des modèles de cohérence éventuelle, comme l’ajout d’une colonne « version » ou « statut » pour suivre l’état des données.
🔄 Évolution du schéma et gestion des versions
Les exigences logicielles évoluent. Le schéma de base de données doit évoluer sans entraîner de temps d’arrêt. Dans les systèmes à fort trafic, vous ne pouvez pas simplement supprimer et recréer des tables. Les stratégies de migration doivent être intégrées au processus de conception du schéma ERD.
- Compatibilité descendante : Lors d’ajout d’une colonne, rendez-la d’abord nullable. Cela permet au code ancien de continuer à fonctionner pendant que le nouveau code remplit les données.
- Types évolutifs : Évitez les types de longueur fixe lorsque cela est possible. Utilisez des chaînes de longueur variable ou des champs JSON pour les attributs dont la structure peut évoluer au fil du temps.
- Suppressions logiques : Au lieu de supprimer physiquement les lignes, marquez-les comme inactives. Cela préserve l’intégrité référentielle des données historiques et évite les opérations de suppression en cascade qui peuvent verrouiller de grandes parties de la table.
🛑 Pièges structurels courants
Même les architectes expérimentés rencontrent des pièges lors du dimensionnement. Être conscient de ces problèmes courants peut économiser beaucoup de temps pendant la phase de conception.
1. Le problème des requêtes N+1
Cela se produit lorsque une application récupère une liste d’enregistrements, puis exécute une requête distincte pour chaque enregistrement afin de récupérer des données associées. Dans votre schéma ERD, identifiez les relations fréquemment consultées ensemble. Si vous prévoyez souvent récupérer des données associées, envisagez de dénormaliser ou de créer des vues spécifiques de lecture.
2. Produits cartésiens
Lors de la jointure de plusieurs grandes tables sans filtrage approprié, l’ensemble des résultats peut croître de manière exponentielle. Assurez-vous que votre schéma ERD impose des contraintes limitant la taille potentielle des résultats de jointure. Utilisez des filtres sur les clés étrangères pour restreindre le périmètre des relations.
3. Dépendances circulaires
Les entités ne doivent pas dépendre les unes des autres en boucle. Par exemple, l’entité A a besoin de l’entité B, et l’entité B a besoin de l’entité A pour s’initialiser. Cela crée une situation de blocage pendant le démarrage ou le chargement des données. Brisez ces cycles en introduisant une entité intermédiaire ou en initialisant les données dans un ordre spécifique.
📝 Maintenance et surveillance
La conception n’est pas un événement ponctuel. Une fois le système en production, vous devez surveiller l’état de votre structure de données. Les métriques de performance doivent guider les ajustements futurs du schéma ERD.
- Analyse des requêtes : Revoyez régulièrement les journaux des requêtes lentes. Si une jointure spécifique est constamment lente, reprenez le schéma ERD pour voir si la relation peut être optimisée.
- Vérifications de fragmentation : Au fil du temps, les suppressions et les mises à jour peuvent fragmenter le stockage. Prévoyez des fenêtres de maintenance durant lesquelles les index seront reconstruits ou les tables optimisées.
- Planification de la capacité : Au fur et à mesure que les données augmentent, les besoins de stockage évoluent. Estimez le taux de croissance de vos plus grandes tables et prévoyez le fractionnement ou la partition avant d’atteindre les limites de capacité.
🛠️ Application pratique : un flux de travail évolutif
Pour mettre en œuvre ces principes, suivez un flux de travail structuré lors de la création de votre schéma.
- Recueil des exigences : Définissez le ratio lecture/écriture et les modèles de trafic attendus.
- Modélisation logique : Créez le diagramme ER en vous concentrant sur les entités métiers et les relations, sans vous soucier des contraintes physiques.
- Modélisation physique : Traduisez le modèle logique en schéma physique. Ajoutez des index, définissez les types de données et envisagez des stratégies de partitionnement.
- Revue et validation : Simulez des requêtes à fort volume sur le modèle. Identifiez les éventuels goulets d’étranglement liés aux jointures ou au verrouillage.
- Documentation : Documentez les raisons des choix de conception. Cela aide les développeurs futurs à comprendre pourquoi un niveau de normalisation spécifique a été choisi.
🔮 Rendre votre architecture résistante au futur
La technologie évolue rapidement. Ce qui fonctionne aujourd’hui pourrait ne plus fonctionner dans cinq ans. Concevez avec souplesse. Évitez de lier étroitement votre schéma à une fonctionnalité spécifique du moteur de stockage qui pourrait devenir obsolète. Concentrez-vous sur les relations logiques et les règles d’intégrité des données, qui restent constantes même lorsque la technologie sous-jacente évolue.
En suivant ces directives, vous créez un modèle de données qui est non seulement fonctionnel pour les besoins actuels, mais suffisamment résilient pour gérer l’imprévisibilité des environnements à fort trafic. L’objectif est de construire un système qui fonctionne de manière cohérente, évolue horizontalement et reste maintenable dans le temps.

