











Lorsque les organisations passent des architectures monolithiques aux microservices, l’approche de modélisation des données devient souvent un point de forte controverse. Pendant des décennies, le diagramme Entité-Relation (ERD) a servi de plan directeur pour la conception des bases de données dans les systèmes centralisés. Il cartographiait avec précision les tables, les colonnes, les clés et les relations. Toutefois, la nature distribuée des microservices remet en question ces conventions traditionnelles. L’hypothèse selon laquelle un schéma unique et unifié s’applique à l’ensemble du système est une idée reçue persistante qui peut entraîner un couplage étroit et une fragilité opérationnelle.
Ce guide examine les croyances courantes entourant les diagrammes ER dans les environnements distribués. Il distingue le fait de la fiction, en se concentrant sur la manière dont les frontières des données doivent être définies, comment les relations sont gérées sans tables partagées, et pourquoi la représentation visuelle des données doit évoluer lors du passage à une architecture orientée services. L’objectif est de fournir une compréhension claire des principes de modélisation des données qui soutiennent l’évolutivité et la résilience.
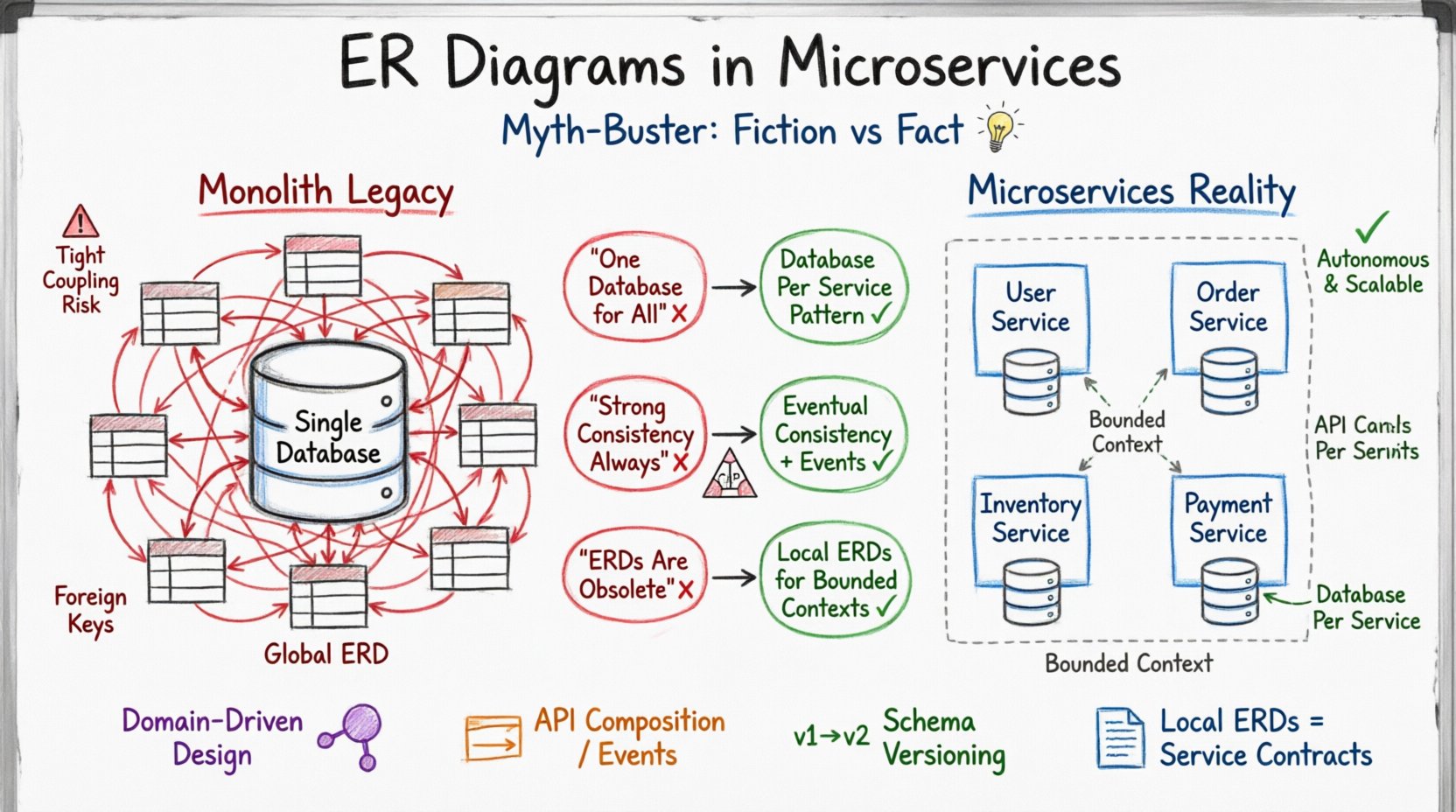
Le legs du monolithe : pourquoi les anciens ERD ne conviennent plus 🏛️
Dans une application monolithique traditionnelle, la base de données agit comme source unique de vérité. Toute la logique d’application interagit avec un seul schéma. Cet environnement favorise un diagramme ER complet qui cartographie chaque entité et chaque relation. Les concepteurs peuvent compter sur les clés étrangères pour assurer l’intégrité référentielle sur l’ensemble du système. Les transactions s’étendent sur plusieurs tables au sein de la même instance de base de données, garantissant que les propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité) sont maintenues globalement.
Lorsque ce mode de pensée est appliqué aux microservices, des frictions apparaissent. Les microservices sont conçus pour être autonomes. Chaque service gère sa propre couche de persistance des données. Cela signifie qu’il n’y a pas de base de données partagée entre les services. Si un service possède ses données, un autre service ne peut pas les interroger directement à l’aide de jointures SQL standard. Le diagramme ER doit donc passer d’une carte systémique à une collection de schémas spécifiques au domaine.
- Contrôle centralisé : Les monolithes permettent à un DBA de gérer l’ensemble du schéma.
- Propriété distribuée : Les microservices exigent que chaque équipe prenne en charge la définition de son propre schéma.
- Transactions globales : Les monolithes supportent les mises à jour en transaction unique sur plusieurs tables.
- Transactions distribuées : Les microservices exigent des patterns de coordination tels que les Sagas ou la cohérence éventuelle.
La première étape de modernisation de la modélisation des données consiste à accepter qu’un seul ERD couvrant l’ensemble de l’application n’est plus réalisable ni souhaitable. En revanche, l’accent se déplace vers la conception pilotée par le domaine, où le modèle de données s’aligne sur les capacités métiers de chaque service.
Mythe 1 : La fausse idée du « un seul base de données » 🗄️❌
Une croyance courante parmi les architectes nouveaux dans les systèmes distribués est qu’ils peuvent maintenir une seule base de données physique tout en séparant logiquement les données à l’aide de préfixes de schéma ou de tables distinctes. Cette approche est souvent qualifiée de « anti-pattern base de données partagée ». Bien qu’elle semble simplifier la conception initiale, elle introduit des risques importants à mesure que le système grandit.
Pourquoi les bases de données partagées échouent
Même si les services ne partagent pas de code, le partage d’une instance de base de données crée un couplage physique. Si un service nécessite une migration de schéma qui affecte les performances ou la disponibilité, tous les autres services partageant cette base de données sont impactés. Cela viole le principe fondamental d’indépendance des microservices.
- Blocage du déploiement : Une migration risquée pour le Service A pourrait empêcher le Service B de se déployer.
- Contestation des ressources : Les requêtes lourdes provenant d’un service peuvent dégrader les performances des autres.
- Risques de sécurité : Un service compromis pourrait potentiellement accéder aux données appartenant à un autre service.
- Verrouillage technologique : Si le Service A nécessite un moteur de base de données différent du Service B, ils ne peuvent pas coexister dans un environnement partagé.
La solution réside dans le pattern « base de données par service ». Chaque service provisionne sa propre base de données. Cela garantit que les modifications de schéma sont isolées. Le diagramme ER du Service A ne doit refléter que les entités de données nécessaires au Service A, et non le système global.
Mythe 2 : La cohérence forte est toujours requise ⚖️
Dans un environnement monolithique, la conformité ACID est la norme. Les développeurs s’attendent à ce qu’une fois une transaction validée, les données soient immédiatement cohérentes sur l’ensemble du système. Dans les microservices, cette attente est souvent irréaliste. Le théorème CAP stipule qu’un système distribué ne peut garantir que deux propriétés sur les trois suivantes : cohérence, disponibilité et tolérance aux partitions.
Comprendre la cohérence distribuée
Lorsque les services communiquent sur un réseau, la latence et les éventuelles défaillances sont inévitables. Essayer d’imposer une cohérence forte au-delà des frontières des services conduit souvent à une latence élevée ou à une indisponibilité du système. À la place, de nombreux systèmes adoptent la cohérence éventuelle. Cela signifie que les données peuvent être temporairement incohérentes entre les services, mais elles convergeront au fil du temps.
- Cohérence forte : Les données sont mises à jour partout immédiatement. Adapté aux systèmes bancaires, mais entraîne une latence élevée.
- Cohérence éventuelle : Les données se propagent de manière asynchrone. Adapté aux profils utilisateurs, aux comptages de stock.
- Disponibilité de base : Le système reste opérationnel même en cas de partition réseau.
Le schéma ER dans un microservice ne représente généralement pas les relations nécessitant un verrouillage immédiat. Il représente plutôt l’état des données qui est localement cohérent. Les relations entre services sont gérées par des événements ou des appels d’API, et non par des clés étrangères de base de données.
Mythe 3 : Les diagrammes ER sont obsolètes dans les systèmes distribués 📉
Certains praticiens affirment que, puisque les microservices déconnectent les données, le concept de diagramme ER n’est plus nécessaire. Cela est incorrect. Bien qu’un diagramme ER global soit obsolète, les diagrammes ER locaux sont plus critiques que jamais. Sans une documentation claire de la structure des données au sein d’un service, le risque de dérive des données et d’erreurs d’intégration augmente considérablement.
Le rôle du diagramme ER local
Un diagramme ER dans un contexte de microservice a une fonction différente de celle dans un monolithe. Il définit le contexte borné. Il garantit que le service sait exactement quelles données il possède et comment ces données sont structurées internement. Il n’a pas besoin de montrer les relations avec des services externes.
- Documentation : Il agit comme un contrat pour le modèle de données interne.
- Communication : Il aide les développeurs à comprendre les entités du domaine sans avoir besoin de connaître les dépendances externes.
- Maintenance : Il simplifie l’intégration des nouveaux membres d’équipe au service spécifique.
- Validation : Il aide à identifier les dépendances circulaires pendant la phase de conception.
Le diagramme doit se concentrer sur les entités, les attributs et les clés primaires. Les clés étrangères faisant référence à des services externes doivent être supprimées ou abstraites en tant qu’identifiants, et non pas comme des liens directs vers des tables.
Meilleures pratiques pour la modélisation des données dans les microservices 🛠️
Pour construire un système robuste, les équipes doivent adopter des stratégies de modélisation spécifiques qui s’alignent sur les principes d’architecture distribuée. Ces pratiques garantissent que les services restent indépendants tout en coopérant pour offrir une expérience utilisateur cohérente.
1. Conception axée sur le domaine (DDD)
Aligner le schéma de base de données avec le modèle métier est essentiel. Chaque service doit représenter une capacité métier spécifique. Par exemple, un « Service utilisateur » ne doit pas stocker les détails des commandes. Un « Service commande » ne doit pas stocker les jetons d’authentification utilisateur. Cette séparation garantit que le diagramme ER reflète la logique métier plutôt que la commodité technique.
- Définir les agrégats en fonction des limites transactionnelles.
- Garder le diagramme ER centré sur la responsabilité du service.
- Éviter de créer des modèles qui s’étendent sur plusieurs domaines métiers.
2. Gestion des relations au-delà des frontières
Lorsque le service A a besoin de données détenues par le service B, il ne doit pas interroger directement la base de données du service B. Au lieu de cela, il doit utiliser l’un des modèles suivants :
- Composition d’API : Le service A appelle l’API du service B pour récupérer les données nécessaires.
- Réplication éventuelle : Le service A conserve une copie des données nécessaires dans sa propre base de données, mise à jour via des événements.
- Jointure via un modèle de lecture : Un service de lecture dédié agrège des données provenant de plusieurs sources afin d’optimiser les requêtes.
3. Versionnage du schéma
Dans un système distribué, les services évoluent à des vitesses différentes. Un changement dans le schéma d’un service ne doit pas briser le consommateur de ce service. Mettre en œuvre un versionnage du schéma permet de garantir la compatibilité descendante.
- Utilisez des points de terminaison versionnés pour les contrats d’API.
- Permettez à plusieurs versions d’un schéma de données de coexister pendant la migration.
- Déprécierez progressivement les anciennes versions de schéma plutôt que de forcer des mises à jour immédiates.
Comparaison : Architecture des données monolithique vs. microservices 📊
Pour clarifier les différences, le tableau suivant décrit les principales distinctions entre la modélisation des données dans les architectures centralisées et distribuées.
| Fonctionnalité | Architecture monolithique | Architecture de microservices |
|---|---|---|
| Stockage des données | Instance unique de base de données | Base de données par service |
| Portée du diagramme ER | Vue globale du système | Vue spécifique au service |
| Relations | Clés étrangères (jointures SQL) | Appels d’API ou événements |
| Modèle de cohérence | Cohérence forte (ACID) | Cohérence éventuelle (BASE) |
| Déploiement | Déploiement monolithique | Déploiement indépendant des services |
| Modifications du schéma | Migration centralisée | Géré par l’équipe du service |
| Interrogation | SQL direct | Modèles de lecture / CQRS |
Gestion des relations de données à travers les frontières 🔗
L’un des aspects les plus difficiles des microservices est la gestion des relations de données. Dans un monolithe, une clé étrangère garantit qu’une commande appartient à un utilisateur. Dans les microservices, la table « Utilisateur » se trouve dans le service Utilisateur, et la table « Commande » se trouve dans le service Commande. Le service Commande ne peut pas posséder une clé étrangère vers la base de données du service Utilisateur.
Modèles d’intégrité référentielle
Pour maintenir l’intégrité référentielle sans tables partagées, les équipes peuvent utiliser des modèles spécifiques :
- Références logiques :Stockez l’ID utilisateur sous forme de chaîne ou de nombre, mais validez son existence via un appel d’API lors de la création.
- Déclencheurs de base de données :Non recommandé entre les services, mais valable au sein d’un service.
- Événements de validation : Le service Utilisateur publie un événement « Utilisateur créé ». Le service Commande le consomme pour reconnaître la relation.
Le problème des jointures
Les jointures à travers les frontières des services constituent un goulot d’étranglement des performances. Elles introduisent une latence réseau et des points de défaillance potentiels. Si le service Utilisateur est hors ligne, le service Commande ne peut pas récupérer les détails de la commande s’il dépend d’une jointure. À la place, le service Commande devrait stocker de manière redondante les informations utilisateur nécessaires (comme le nom) au moment de la création de la commande. Il s’agit d’un compromis entre la normalisation et la disponibilité.
Évolution et versioning du schéma 🔄
L’évolution du schéma est inévitable. Au fur et à mesure que les exigences métiers évoluent, les structures de données doivent s’adapter. Dans un environnement de microservices, modifier un schéma est plus complexe car plusieurs services peuvent dépendre de la structure des données d’un autre.
Stratégies d’évolution
- Modifications ajoutées :L’ajout d’une nouvelle colonne est généralement sans risque si l’application gère correctement les champs manquants.
- Suppression de champs : Cela nécessite une période de dépréciation durant laquelle le champ est masqué mais toujours présent, puis supprimé ultérieurement.
- Changements de type : Le changement d’un type de données (par exemple, chaîne en entier) nécessite une stratégie de migration coordonnée.
Utiliser un registre de schémas peut aider à gérer ces modifications. Il agit comme une source unique de vérité pour la structure des données échangées entre les services, garantissant que producteurs et consommateurs sont d’accord sur le format.
Péchés courants à éviter 🚧
Même avec une bonne compréhension des principes, les équipes tombent souvent dans des pièges lors de la mise en œuvre. Identifier ces pièges tôt peut éviter un endettement technique important.
- Sur-normalisation :Essayer de maintenir une seule source de vérité sur l’ensemble des services entraîne des transactions distribuées complexes. Acceptez la redondance là où c’est nécessaire.
- Ignorer l’idempotence :Les appels réseau peuvent échouer ou être répétés. Les opérations sur les données doivent être conçues pour gérer les requêtes en doublon sans créer de doublons.
- Surcharge de chorégraphie :Se fier uniquement aux événements pour assurer la cohérence des données peut devenir ingérable. Utilisez l’orchestration pour les workflows complexes.
- Sous-estimer la latence :Récupérer des données entre services ajoute des millisecondes à chaque requête. Agrégez les données localement là où c’est possible.
- Manque de documentation :Sans diagrammes ER clairs pour chaque service, l’intégration devient un jeu de devinettes.
Réflexions finales sur la clarté architecturale 🧠
Le passage du modèle monolithique au modèle de données microservices exige un changement de mentalité. Ce n’est pas seulement une question de diviser une base de données en morceaux plus petits. C’est redéfinir la manière dont la propriété des données et les relations sont conceptualisées. Le diagramme ER reste un outil essentiel, mais son champ d’application se limite à la frontière du service.
En évitant les mythes des bases de données partagées et de la cohérence globale, les architectes peuvent construire des systèmes résilients et évolutifs. La clé réside dans la priorité donnée à l’autonomie des services plutôt qu’à la normalisation des données. Cela signifie accepter que certaines données seront redondantes afin de garantir que les services peuvent fonctionner de manière indépendante. Cela signifie aussi comprendre que la cohérence forte est un luxe, et non une exigence, pour chaque opération.
Lors de la conception de l’architecture des données, concentrez-vous sur le domaine. Laissez les capacités métiers définir les frontières. Utilisez les diagrammes ER pour clarifier l’état interne de chaque service. Utilisez les événements et les API pour gérer les connexions entre eux. Cette approche garantit que le système peut évoluer sans compromettre l’intégrité des données sous-jacente.
En fin de compte, l’objectif n’est pas de reproduire le monolithe sous une forme distribuée. Il s’agit de créer un système où les données sont gérées avec la même flexibilité et la même rapidité que le code qui les traite. Ce équilibre est la fondation d’une stratégie microservices réussie.

