











Concevoir un schéma de base de données est l’une des tâches les plus critiques dans l’architecture logicielle. Un modèle de données mal conçu peut entraîner des goulets d’étranglement de performance, des vulnérabilités en matière de sécurité et une dette technique importante à mesure que l’application grandit. Ce guide vous accompagne dans la création d’un diagramme d’entités et de relations (ERD) robuste, spécifiquement adapté à un service de gestion des utilisateurs. Nous passerons de la conception initiale à un schéma prêt pour la production, en mettant l’accent sur l’intégrité des données, la conformité en matière de sécurité et la scalabilité.
📋 Comprendre le périmètre et les exigences
Avant de tracer une seule ligne ou de définir une table, vous devez comprendre les exigences fonctionnelles du service. Un système de gestion des utilisateurs ne consiste pas uniquement à stocker des noms et des adresses e-mail ; il s’agit de gérer les identités, les autorisations et les journaux d’audit. Commencez par lister les acteurs principaux et leurs interactions.
- Administrateurs :Ont besoin d’un accès complet pour gérer d’autres utilisateurs et les paramètres du système.
- Utilisateurs finaux :Doivent s’authentifier, mettre à jour leurs profils et accéder à des fonctionnalités spécifiques.
- Système :Nécessite une journalisation automatisée et une gestion des sessions.
Pensez dès le départ aux types de données et aux contraintes. Allez-vous prendre en charge les caractères internationaux ? Comment gérez-vous les fuseaux horaires ? Ces décisions influencent les définitions des champs dans votre diagramme. Un document complet des exigences sert de plan directeur pour votre ERD, garantissant que aucune entité critique n’est oubliée pendant la phase de conception.
🏗️ Définition des entités principales
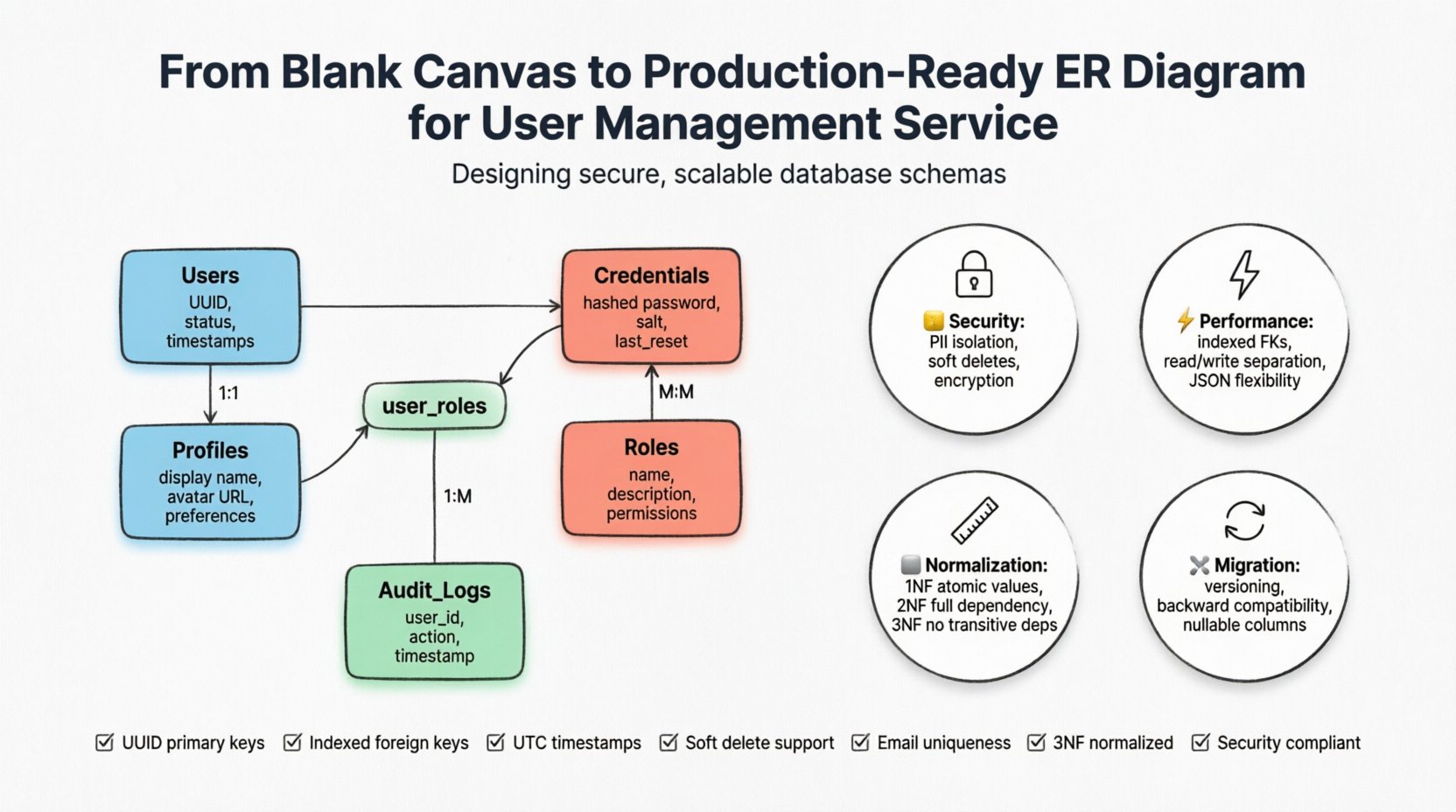
La fondation de tout système de gestion des utilisateurs repose sur les entités principales. Ce sont les tables qui stockeront les données persistantes. Nous allons identifier cinq entités principales :Utilisateurs, Profils, Informations d’identification, Rôles, et Journaux d’audit.
1. L’entité Utilisateur
C’est l’objet d’identité central. Il doit contenir des identifiants uniques et des indicateurs d’état plutôt que des données sensibles. Une table utilisateur bien structurée inclut :
- UUID :Un identifiant universellement unique plutôt qu’un entier auto-incrémenté. Cela empêche les attaques par énumération et facilite le dimensionnement horizontal.
- Statut :Un champ d’énumération (par exemple, actif, suspendu, supprimé) pour contrôler l’accès sans supprimer les enregistrements.
- Métadonnées : Horodatages de création et de mise à jour dernière.
2. L’entité Profil
Le stockage des noms d’affichage, des avatars et des informations de contact dans la table principale Utilisateur peut entraîner un gonflement. Une entité Profil permet une relation un à un, en maintenant la table d’authentification principale légère.
- Nom d’affichage : Pour une visibilité publique.
- URL de l’avatar : Lien vers un stockage externe plutôt que de stocker des données binaires.
- Préférences : JSON ou une table séparée pour les paramètres de thème et les préférences de notification.
3. L’entité Identifiants
La sécurité est primordiale. Les détails d’authentification doivent être séparés des données d’identité utilisateur. Cette séparation permet une rotation plus facile des protocoles de sécurité sans modifier la structure d’identité utilisateur.
- Mot de passe haché : Ne jamais stocker du texte en clair. Utilisez un algorithme de hachage puissant.
- Sel : Assurez-vous qu chaque utilisateur dispose d’une valeur de sel unique.
- Dernier moment de réinitialisation : Suivre les changements de mot de passe pour les politiques de sécurité.
🔗 Modélisation des relations et de la cardinalité
Une fois les entités définies, les relations entre elles doivent être établies. La cardinalité définit combien d’instances d’une entité sont liées à une autre. Une mauvaise compréhension de ces relations est une cause fréquente de redondance des données.
| Relation | Type | Raisonnement |
|---|---|---|
| Utilisateur & Profil | Un à un | Chaque utilisateur possède exactement un ensemble de détails de profil. |
| Utilisateur & Rôles | Many-to-Many | Un utilisateur peut détenir plusieurs rôles, et un rôle peut être attribué à plusieurs utilisateurs. |
| Utilisateur & journaux d’audit | Un à plusieurs | Une seule action utilisateur génère une entrée de journal, mais un seul utilisateur génère de nombreuses entrées de journal. |
| Rôle et autorisations | Nombreux à nombreux | Les rôles définissent les autorisations, mais les autorisations peuvent être partagées entre les rôles. |
Pour implémenter une relation nombreux à nombreux, vous devez introduire une table de jonction. Par exemple, entre les utilisateurs et les rôles, créez une user_roles table. Cette table contient des clés étrangères pointant vers les clés primaires des tables Utilisateur et Rôle. Cette structure garantit l’intégrité référentielle et permet des affectations d’autorisations flexibles.
📉 Normalisation et intégrité des données
Un schéma prêt pour la production suit les principes de normalisation afin de réduire la redondance. Bien que la Troisième Forme Normale (3NF) soit l’objectif standard, comprendre les compromis est essentiel.
Première Forme Normale (1NF)
Assurez-vous que chaque colonne contient des valeurs atomiques. Évitez de stocker plusieurs adresses e-mail dans une seule colonne. Utilisez une table séparée pour les contacts si un utilisateur possède plusieurs e-mails vérifiés.
Deuxième Forme Normale (2NF)
Assurez-vous que les attributs non clés dépendent entièrement de la clé primaire. Dans un scénario de clé composite, assurez-vous qu’il n’existe aucune dépendance partielle. Pour la gestion des utilisateurs, utiliser un UUID unique comme clé primaire simplifie considérablement ce processus.
Troisième Forme Normale (3NF)
Assurez-vous qu’il n’existe aucune dépendance transitive. Si le pays d’un utilisateur détermine son taux de taxation, stockez le pays séparément de la table utilisateur, et liez l’utilisateur au pays. Cela permet de mettre à jour les taux de taxation sans modifier chaque enregistrement utilisateur.
La normalisation n’est pas seulement une question de théorie ; elle consiste à maintenir une seule source de vérité. Lorsque les données sont dupliquées entre les tables, les mises à jour deviennent sujettes aux erreurs. En gardant les données atomiques, vous assurez que la cohérence est maintenue automatiquement par le moteur de base de données.
🔒 Considérations en matière de sécurité et de conformité
Un schéma de base de données est la première ligne de défense pour les données utilisateur. La conformité aux réglementations telles que le RGPD ou le CCPA exige des choix spécifiques dans la conception du schéma.
- Isolation des données personnelles (PII) :Les informations personnelles doivent être stockées dans des colonnes chiffrées ou dans des tables séparées avec des contrôles d’accès stricts.
- Droit à l’oubli :Votre schéma doit prendre en charge les suppressions douces ou l’anonymisation des données. Au lieu de supprimer une ligne, marquez-la comme supprimée et remplacez les champs PII par un espace réservé générique.
- Traçabilité des audits :Implémentez une table de journal immuable. Enregistrez qui a modifié quelles données et quand. Cela est crucial pour la responsabilité.
- Chiffrement au repos :Concevez les champs qui stockent des données sensibles pour qu’ils soient compatibles avec les fonctionnalités de chiffrement au niveau de la base de données.
Pensez à la politique de rétention de vos journaux. Une table qui croît indéfiniment peut dégrader les performances. Mettez en œuvre une stratégie de partitionnement pour la table des journaux d’audit, archivant les enregistrements anciens dans un stockage froid ou les supprimant selon la politique.
⚡ Modèles de performance et de scalabilité
Concevoir pour la production signifie anticiper la charge. Un schéma qui fonctionne pour 100 utilisateurs peut échouer avec 100 000 utilisateurs. Les stratégies d’indexation sont une partie essentielle du processus de conception du schéma ERD.
Indexation des clés étrangères
Indexez toujours les colonnes de clés étrangères. Si vous interrogez les utilisateurs par leur ID de rôle, la base de données a besoin d’un index sur la colonne de clé étrangère pour éviter un balayage complet de la table. C’est une erreur courante dans les premiers designs.
Séparation lecture vs écriture
Bien que le MCD définisse la structure logique, envisagez une séparation physique. Les données d’authentification des utilisateurs (Identifiants) sont très lues. Les données de profil sont très lues. Les journaux d’audit sont très écrits. Concevoir le schéma pour supporter ultérieurement le fractionnement ou des réplicas de lecture est plus facile si les limites des entités sont claires.
Champs JSON pour plus de flexibilité
Les bases de données modernes supportent les colonnes JSON. Utilisez-les pour les attributs qui varient considérablement entre les utilisateurs, tels que des champs personnalisés ou des paramètres. Cela évite les migrations de schéma pour chaque nouvelle fonctionnalité, bien que cela se fasse au détriment des performances des requêtes.
🛠️ Gestion des migrations et du cycle de vie
Une base de données de production n’est jamais statique. Elle évolue au fur et à mesure que les exigences changent. Le MCD doit pouvoir s’adapter à cette évolution.
- Versioning : Ne modifiez pas directement les tables en production. Utilisez des scripts de migration qui créent de nouvelles tables, copient les données, puis basculent les références.
- Compatibilité descendante : Lors de l’ajout d’une colonne, autorisez-la initialement à être nulle. Cela empêche de casser le code applicatif existant qui ne définit pas immédiatement la valeur.
- Contraintes : Commencez par des contraintes souples et resserrez-les au fur et à mesure que les données se stabilisent. Imposer une unicité stricte trop tôt peut bloquer le développement.
Pensez à ajouter une versioncolonne aux tables principales. Cela vous permet de suivre les modifications du schéma si vous mettez en œuvre un versionnement au niveau de l’application pour les structures de données.
🚧 Pièges courants à éviter
Même les architectes expérimentés commettent des erreurs. Revoyez votre schéma par rapport à ces problèmes courants avant le déploiement.
- Stockage de données sensibles dans les journaux : Assurez-vous que la table des journaux d’audit ne capture pas involontairement des mots de passe ou des numéros de carte de crédit. Masquez les données PII dans les entrées de journal.
- Sur-indexation : Chaque index ralentit les opérations d’écriture. Indexez uniquement les colonnes utilisées fréquemment dans les clauses WHERE ou les jointures.
- Ignorer les fuseaux horaires : Stockez toutes les dates-temps en UTC. Convertissez en heure locale uniquement au niveau de la couche de présentation. Cela évite les problèmes liés aux changements d’heure d’été.
- Valeurs codées en dur : Ne codez pas en dur les noms de rôles ou les valeurs d’état dans le code applicatif. Définissez-les comme des énumérations ou des tables de référence dans la base de données.
✅ Liste de contrôle de validation finale
Avant de considérer le MCD comme complet, passez en revue cette liste de contrôle pour vous assurer de la préparation.
- Toutes les clés primaires sont-elles des UUIDs ou des entiers auto-incrémentés ?
- Toutes les clés étrangères sont-elles indexées ?
- Y a-t-il une contrainte d’unicité sur les adresses e-mail ou les noms d’utilisateur ?
- Les horodatages sont-ils stockés au format UTC ?
- Existe-t-il un mécanisme pour les suppressions douces ?
- Les données sensibles sont-elles séparées des données d’identité ?
- Y a-t-il des index pour les modèles de requête courants ?
- Le schéma est-il normalisé au moins jusqu’à la 3FN ?
- La conception supporte-t-elle les normes de conformité en matière de sécurité requises ?
Un examen approfondi de ces points garantit que la fondation de votre service de gestion des utilisateurs est solide. L’effort investi pendant la phase de conception porte ses fruits en termes de maintenance, de sécurité et de performance tout au long du cycle de vie de l’application.
📝 Résumé des composants du schéma
Pour regrouper les éléments de conception, voici un résumé des composants clés requis pour une base de données de gestion des utilisateurs de haute qualité.
| Composant | Champs clés | Contrainte |
|---|---|---|
| Utilisateurs | id, statut, date_creation | Clé primaire, statut unique |
| Identifiants | id_utilisateur, hachage, sel, derniere_reinitialisation | Clé étrangère, non nul |
| Rôles | id, nom, description | Clé primaire, nom unique |
| Utilisateurs_Rôles | id_utilisateur, id_role | Clé primaire composée |
| Journaux_d’audit | id, id_utilisateur, action, horodatage | Clé étrangère, index sur l’utilisateur |
En suivant ces directives et ces modèles structurels, vous établissez un système fiable capable de gérer de manière sécurisée des interactions complexes avec les utilisateurs. Le diagramme ER résultant sert de contrat entre les données et l’application, garantissant une stabilité au fur et à mesure de la croissance de votre service.

