











Der Aufbau einer robusten Backend-Architektur erfordert mehr als nur effizienten Code; es erfordert ein grundlegendes Verständnis dafür, wie Daten strukturiert, gespeichert und unter Last abgerufen werden. Im Zentrum dieser Infrastruktur steht das Entity-Relationship-Diagramm (ERD). Obwohl es oft als statisches Bauplan während der initialen Planungsphase betrachtet wird, dient ein gut gestaltetes ERD als dynamisches Rückgrat hochbelasteter Systeme. Bei Verkehrssteigerungen bestimmt das Datenbankschema Leistung, Latenz und Verfügbarkeit. Ein schlecht strukturiertes Modell kann zu kettenreaktiven Ausfällen führen, während ein skalierbares Design das Wachstum nahtlos unterstützt.
Diese Anleitung untersucht die technischen Feinheiten beim Erstellen von ER-Diagrammen, die hohen Lasten standhalten. Wir gehen über die grundlegende Normalisierung hinaus und untersuchen, wie Beziehungen, Einschränkungen und physische Speicherstrategien in verteilten Umgebungen interagieren. Egal, ob Sie für Millionen gleichzeitiger Benutzer oder einfach nur für zukünftige Erweiterungen planen – die hier dargelegten Prinzipien bieten einen Rahmen für widerstandsfähiges Datenmodellieren.
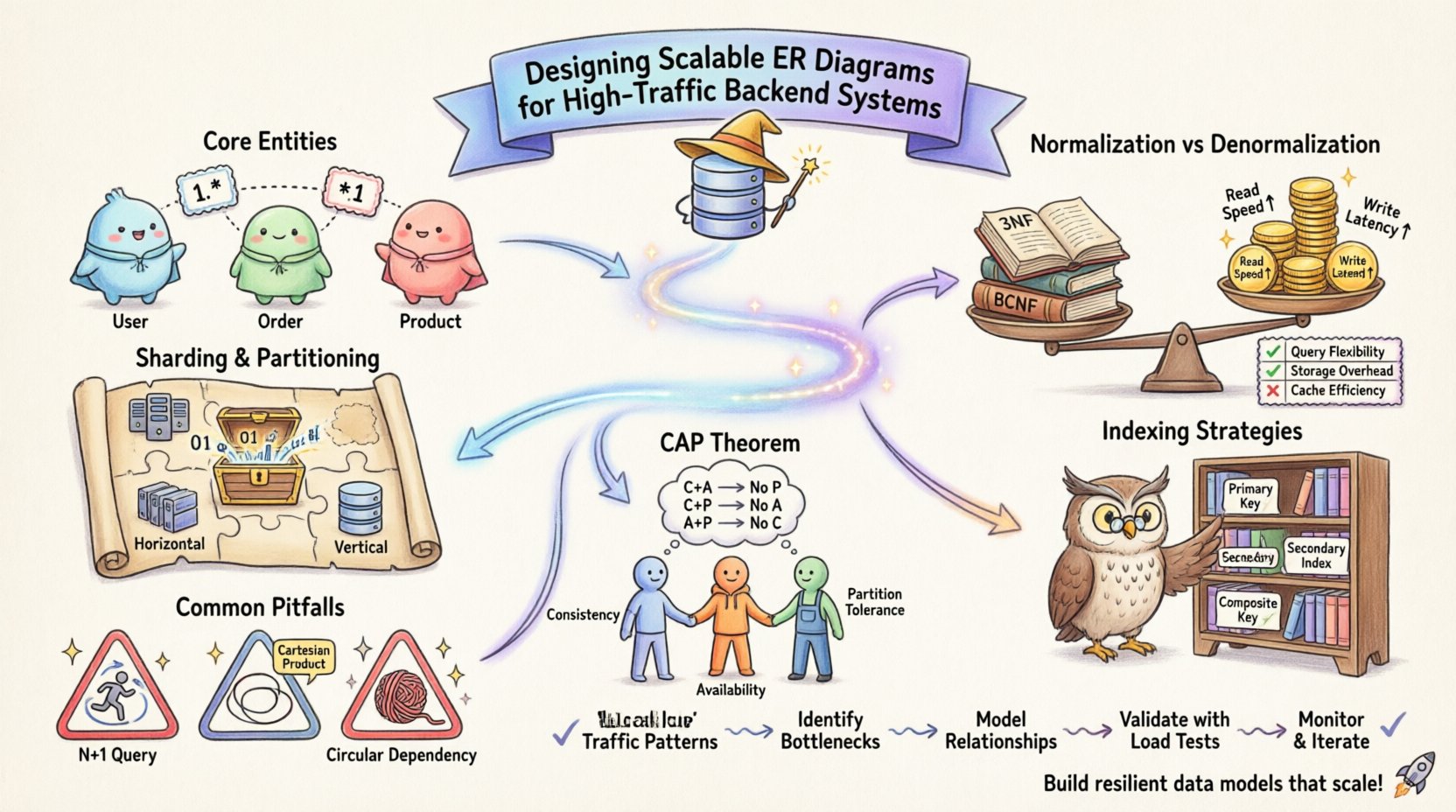
🏗️ Verständnis des Entity-Relationship-Modellierens im großen Maßstab
Die grundlegende Einheit eines ER-Diagramms ist die Entität, die ein eindeutiges Objekt oder Konzept innerhalb Ihres Systems darstellt. In Umgebungen mit geringem Verkehr herrscht oft die Einfachheit vor. Doch mit steigenden Transaktionsvolumina wächst die Komplexität der Interaktionen zwischen Entitäten exponentiell. Hochbelastete Systeme erfordern eine Perspektivverschiebung von „Wie sollte diese Datenstruktur aussehen?“ zu „Wie wird diese Datenstruktur unter Last performen?“
- Identifizieren Sie die Kernentitäten:Bestimmen Sie, welche Datenobjekte am häufigsten abgerufen werden. Das sind Ihre Hot-Pfade.
- Analysieren Sie die Kardinalität:Definieren Sie die Beziehungen zwischen Entitäten. Einer-zu-viele-, viele-zu-viele- und einer-zu-einer-Beziehungen haben jeweils unterschiedliche Auswirkungen auf die Leistung.
- Granularität der Attribute:Entscheiden Sie, wie viel Detail innerhalb eines Attributs gespeichert werden soll. Zu granulare Attribute können die Zeilengröße erhöhen, während zu breite Attribute die Spezifität von Abfragen beeinträchtigen können.
Beim Gestalten für Skalierbarkeit wird die physische Anordnung der Daten ebenso wichtig wie die logische Struktur. Das ERD muss nicht nur die Geschäftslogik widerspiegeln, sondern auch die betrieblichen Beschränkungen der Speicherengine berücksichtigen. Beispielsweise behandeln einige Systeme die Zeilen-Sperre anders als die Seiten-Sperre. Ihr Diagramm sollte diese Beschränkungen antizipieren, indem es Konfliktpunkte minimiert.
📊 Normalisierung vs. Denormalisierung: Der Leistungs-Trade-off
Die Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Obwohl sie traditionell als universelle Bestpraxis vermittelt wird, erfordern hochbelastete Systeme oft einen ausgewogenen Ansatz. Eine strikte Einhaltung des Dritten Normalen Form (3NF) kann zu übermäßigen Join-Operationen führen. In verteilten oder hochkonkurrierenden Umgebungen können Joins über mehrere Tabellen zu erheblichen Engpässen werden.
Umgekehrt beinhaltet die Denormalisierung die Duplizierung von Daten, um die Notwendigkeit von Joins zu reduzieren. Diese Strategie verbessert die Leseleistung, hat aber die Schreiboperationen komplizierter gemacht. Sie müssen die Konsistenz über duplizierte Felder aufrechterhalten, was zusätzlichen Logikcode in Ihrer Anwendungsschicht erfordert.
| Strategie | Lesepreformance | Schreibleistung | Datenkonsistenz | Speicherkosten |
|---|---|---|---|---|
| Vollständige Normalisierung | Niedrig (mehrere Joins) | Hoch (einzelner Schreibvorgang) | Hoch | Niedrig |
| Teilweise Denormalisierung | Hoch (weniger Joins) | Mittel (Aktualisierung von Duplikaten) | Mittel | Mittel |
| Vollständige Denormalisierung | Sehr hoch | Niedrig (komplexe Logik) | Niedrig (erfordert Synchronisation) | Hoch |
Die Wahl des richtigen Gleichgewichts hängt von Ihrem Lese-Schreib-Verhältnis ab. Wenn Ihr System leseschwer ist, beispielsweise ein Inhaltsfeed oder eine Nachrichtenplattform, ist eine Denormalisierung oft notwendig. Wenn Ihr System schreibschwer ist, wie ein Transaktionsbuch, hilft die Normalisierung, Anomalien zu vermeiden.
🌐 Strategien zur Optimierung von Lese- und Schreibvorgängen
Die Optimierung für hohen Datenverkehr erfordert spezifische Techniken, die die Gestalt Ihres ERDs beeinflussen. Diese Strategien konzentrieren sich darauf, die Zeit zu verringern, die zum Abrufen oder Speichern von Informationen benötigt wird.
1. Caching-Strategien, die sich im Schema widerspiegeln
Bei der Gestaltung Ihres Datenmodells sollten Sie berücksichtigen, wie die Daten gecacht werden. Häufig aufgerufene Entitäten sollten so strukturiert sein, dass eine einfache Serialisierung möglich ist. Vermeiden Sie das Speichern großer, variabler Blobs in Tabellen, die häufig verbunden werden. Speichern Sie stattdessen einen Referenzschlüssel und holen Sie das Blob separat ab, wenn es benötigt wird. Dadurch wird der Speicherdruck auf die primäre Cachelayer reduziert.
2. Partitionierungs- und Sharding-Schlüssel
Wenn die Daten wachsen, wird die Speicherung in einer einzigen Tabelle ineffizient. Sharding verteilt die Daten über mehrere Knoten. Ihr ERD muss einen Sharding-Schlüssel klar definieren. Dieser Schlüssel bestimmt, wie die Zeilen verteilt werden. Wenn der Sharding-Schlüssel schlecht gewählt wird, können „heiße Partitionen“ entstehen, bei denen ein Knoten deutlich mehr Datenverkehr verarbeitet als die anderen.
- Horizontales Sharding: Teilt Zeilen basierend auf einem Schlüssel auf. Der ERD muss zeigen, wie der Schlüssel verteilt wird.
- Vertikales Sharding: Teilt Spalten über mehrere Tabellen auf. Nützlich, um schwere Spalten (wie Protokolle) von zentralen transaktionalen Daten zu trennen.
🔗 Verwaltung von Beziehungen in partitionierten Daten
Beziehungen sind der Kitt, der eine Datenbank zusammenhält, können in einem verteilten System aber zu Latenz führen. Fremdschlüssel gewährleisten die Referenzintegrität, aber in einer sharded-Umgebung ist die Durchsetzung dieser Einschränkungen über mehrere Knoten hinweg kostspielig.
Behandlung von Many-to-Many-Beziehungen
Many-to-Many-Beziehungen erfordern eine Verbindungstabelle. In einer hochbelasteten Umgebung kann diese Tabelle zu einer Engstelle werden. Wenn Sie häufig abfragen, erwägen Sie die Denormalisierung der Beziehung. Statt die Verbindungstabelle zu verknüpfen, speichern Sie die Beziehungsnr. direkt in der übergeordneten Entität, falls die Kardinalität es zulässt. Dadurch wird die Tiefe der Abfrage reduziert.
Selbstreferenzierende Entitäten
Einige Entitäten verweisen auf sich selbst, beispielsweise Kategorien oder hierarchische Kommentare. Gestalten Sie diese Beziehungen sorgfältig. Tiefes Rekursivieren in Abfragen kann die Systemressourcen erschöpfen. Begrenzen Sie die Tiefe selbstreferenzierender Ketten in Ihrer Logik oder flachieren Sie die Struktur, wo möglich, mithilfe von materialisierten Pfaden.
🔍 Indexierungsstrategien für Leistung
Ein ERD definiert die logische Struktur, während Indizes die physische Abrufgeschwindigkeit bestimmen. Obwohl das Diagramm selbst keine Indizes zeigt, beeinflussen die Gestaltungsentscheidungen, welche Indizes sinnvoll sind.
- Primärschlüssel: Diese sind in vielen Systemen gruppiert, was bedeutet, dass die Daten physisch nach diesem Schlüssel sortiert sind. Wählen Sie einen Primärschlüssel, der die Fragmentierung minimiert und eine gleichmäßige Verteilung gewährleistet.
- Sekundäre Indizes: Jeder Index verbraucht Schreibleistung. Zu viele Indizes verlangsamen Einfüge- und Aktualisierungsoperationen. Indizieren Sie nur Spalten, die häufig in `WHERE`, `JOIN` oder `ORDER BY`-Klauseln verwendet werden.
- Komposite Indizes: Wenn mehrere Spalten gemeinsam abgefragt werden, kann ein komposites Index effizienter sein. Die Reihenfolge der Spalten im Index ist wichtig und sollte den häufigsten Abfragemustern entsprechen.
⚖️ Konsistenz vs. Verfügbarkeit in verteilten Schemata
Die Datenbanktheorie diskutiert oft den CAP-Satz, der besagt, dass ein System nur zwei der drei Eigenschaften garantieren kann: Konsistenz, Verfügbarkeit und Partitionstoleranz. Ihre ERD-Designentscheidungen beeinflussen, welche dieser Eigenschaften Sie priorisieren.
Wenn Sie Konsistenz priorisieren, werden Sie mit strengen Fremdschlüsseln und ACID-Transaktionen entwerfen. Dies gewährleistet die Datenintegrität, kann aber Latenz während Netzwerkpartitionen verursachen. Wenn Sie Verfügbarkeit priorisieren, könnten Sie die Einschränkungen lockern, um temporäre Inkonsistenzen zuzulassen. In diesem Fall sollte Ihre ERD Muster der letztendlichen Konsistenz unterstützen, beispielsweise durch eine Spalte „Version“ oder „Status“, um den Datenzustand zu verfolgen.
🔄 Schema-Evolution und Versionierung
Softwareanforderungen ändern sich. Das Datenbankschema muss sich entwickeln, ohne Ausfallzeiten zu verursachen. Bei Systemen mit hoher Auslastung können Sie Tabellen nicht einfach löschen und neu erstellen. Migrationsstrategien müssen in den ERD-Entwurfsprozess integriert werden.
- Rückwärtskompatibilität: Wenn Sie eine Spalte hinzufügen, machen Sie sie zunächst nullable. Dadurch kann der alte Code weiterhin funktionieren, während der neue Code die Daten füllt.
- Erweiterbare Typen: Vermeiden Sie feste Längentypen, wenn möglich. Verwenden Sie variable Zeichenketten oder JSON-Felder für Attribute, deren Struktur sich im Laufe der Zeit ändern könnte.
- Logische Löschungen: Löschen Sie Zeilen nicht physisch, sondern markieren Sie sie als inaktiv. Dadurch bleibt die Referenzintegrität für historische Daten erhalten, und es werden kaskadierende Löschvorgänge vermieden, die große Teile der Tabelle sperren könnten.
🛑 Häufige strukturelle Fallstricke
Selbst erfahrene Architekten stoßen bei der Skalierung auf Fallstricke. Die Kenntnis dieser häufigen Probleme kann erhebliche Zeit im Entwurfsphase sparen.
1. Das N+1-Abfrage-Problem
Dies tritt auf, wenn eine Anwendung eine Liste von Datensätzen abruft und dann für jeden Datensatz eine separate Abfrage ausführt, um verwandte Daten abzurufen. Identifizieren Sie in Ihrer ERD Beziehungen, die häufig gemeinsam abgerufen werden. Wenn Sie erwarten, dass verwandte Daten häufig abgerufen werden, erwägen Sie eine Denormalisierung oder die Erstellung spezifischer Lese-Modellansichten.
2. Kartesische Produkte
Wenn mehrere große Tabellen ohne geeignete Filterung verbunden werden, kann die Ergebnismenge exponentiell wachsen. Stellen Sie sicher, dass Ihre ERD Einschränkungen vorsieht, die die potenzielle Größe von Join-Ergebnissen begrenzen. Verwenden Sie Filter auf Fremdschlüsseln, um den Umfang von Beziehungen einzuschränken.
3. Zirkuläre Abhängigkeiten
Entitäten sollten sich nicht in einer Schleife gegenseitig abhängig machen. Zum Beispiel benötigt Entity A Entity B, und Entity B benötigt Entity A zur Initialisierung. Dies führt zu einer Deadlock-Situation beim Start oder beim Datenladen. Brechen Sie diese Zyklen durch Einführung einer Zwischentität oder durch Initialisieren der Daten in einer bestimmten Reihenfolge.
📝 Wartung und Überwachung
Das Design ist kein einmaliger Vorgang. Sobald das System live ist, müssen Sie die Gesundheit Ihrer Datenstruktur überwachen. Leistungsmetriken sollten zukünftige Anpassungen der ERD leiten.
- Abfrageanalyse: Überprüfen Sie regelmäßig die Protokolle langsamer Abfragen. Wenn eine bestimmte Verknüpfung konstant langsam ist, überprüfen Sie die ERD erneut, um zu sehen, ob die Beziehung optimiert werden kann.
- Fragmentierungsprüfungen: Im Laufe der Zeit können Löschungen und Aktualisierungen die Speicherfragmentierung erhöhen. Planen Sie Wartungsintervalle, in denen Indizes neu erstellt oder Tabellen optimiert werden.
- Kapazitätsplanung: Mit wachsenden Daten ändern sich die Speicheranforderungen. Schätzen Sie die Wachstumsrate Ihrer größten Tabellen ab und planen Sie Sharding oder Partitionierung, bevor Sie die Kapazitätsgrenzen erreichen.
🛠️ Praktische Anwendung: Ein skalierbarer Workflow
Um diese Prinzipien umzusetzen, folgen Sie einem strukturierten Workflow beim Erstellen Ihres Diagramms.
- Anforderungserhebung: Definieren Sie das Lese-/Schreibverhältnis und die erwarteten Verkehrsstrukturen.
- Logisches Modellieren: Erstellen Sie das ERD, wobei Sie sich auf geschäftliche Entitäten und Beziehungen konzentrieren, ohne sich um physische Einschränkungen kümmern zu müssen.
- Physisches Modellieren: Übersetzen Sie das logische Modell in ein physisches Schema. Fügen Sie Indizes hinzu, definieren Sie Datentypen und überlegen Sie Partitionierungsstrategien.
- Überprüfung und Validierung: Simulieren Sie Hochlastabfragen gegen das Modell. Identifizieren Sie potenzielle Engpässe bei Joins oder Sperrungen.
- Dokumentation: Dokumentieren Sie die Begründung für die Gestaltungswahl. Dies hilft zukünftigen Entwicklern zu verstehen, warum ein bestimmtes Normalisierungslevel gewählt wurde.
🔮 Zukunftssicherung Ihrer Architektur
Die Technologie entwickelt sich schnell. Was heute funktioniert, mag in fünf Jahren nicht mehr funktionieren. Gestalten Sie mit Flexibilität im Blick. Vermeiden Sie es, Ihr Schema zu stark an eine spezifische Speicher-Engine-Funktion zu binden, die möglicherweise obsolet wird. Konzentrieren Sie sich auf die logischen Beziehungen und die Regeln zur Datenintegrität, da diese auch bei sich ändernder zugrundeliegender Technologie konstant bleiben.
Durch die Einhaltung dieser Richtlinien erstellen Sie ein Datenmodell, das nicht nur den aktuellen Anforderungen entspricht, sondern auch ausreichend widerstandsfähig ist, um der Unvorhersehbarkeit hochbelasteter Umgebungen standzuhalten. Das Ziel ist es, ein System zu entwickeln, das konsistent funktioniert, horizontal skaliert und langfristig wartbar bleibt.

