











Wenn eine auf Papier entworfene Datenbankarchitektur in einer Sandbox einwandfrei funktioniert, aber unter realen Verkehrsbedingungen zusammenbricht, liegt der Unterschied oft zwischen dem visuellen Modell und der Laufzeitrealität. Ein Entitäts-Beziehungs-Diagramm (ERD) ist eine Bauplanung, kein lebendiger Motor. Wenn Entwickler jedoch von einem „ERD sprechen, der unter Last versagt“, meinen sie in der Regel eine Schema-Design, das aus diesem Diagramm abgeleitet wurde und die Anforderungen der Produktion nicht erfüllen kann. Dieser Leitfaden behandelt strukturelle, logische und Leistungsengpässe, die dazu führen, dass relationale Modelle unter steigendem Datenvolumen und Konkurrenzversorgung Schwierigkeiten haben.
Die Diagnose dieser Probleme erfordert ein tiefes Verständnis dafür, wie Datenbeziehungen in I/O-Operationen, Sperrkonflikte und Speicherverbrauch übersetzt werden. Wir werden die Spannungspunkte untersuchen, an denen Gestaltungsentscheidungen mit Hardwarebeschränkungen und Verkehrsstrukturen kollidieren. Indem Sie die spezifischen Symptome struktureller Ausfälle identifizieren, können Sie Ihr Datenmodell so umgestalten, dass es Skalierung unterstützt, ohne die Datenintegrität zu gefährden.
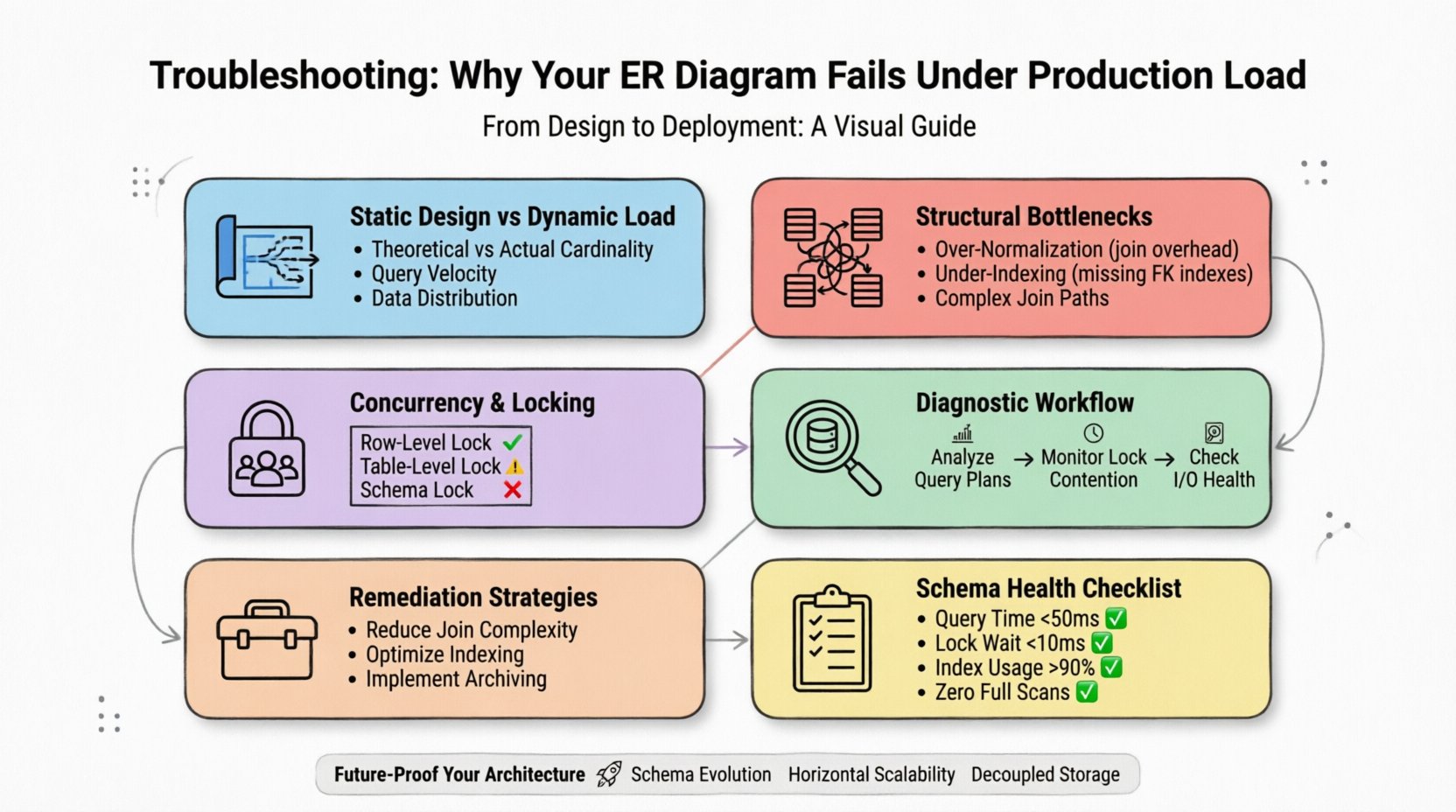
1. Die Kluft zwischen statischer Gestaltung und dynamischer Last ⚡
Ein ER-Diagramm stellt mögliche Beziehungen und Datentypen dar. Es berücksichtigt nicht die Schreibgeschwindigkeit, die Verteilung der Lesezugriffe oder die physischen Speicherbeschränkungen der zugrundeliegenden Engine. Ein Modell, das auf der Tafel ausgewogen wirkt, verbirgt oft Unzulänglichkeiten, die erst dann sichtbar werden, wenn Millionen von Zeilen gleichzeitig abgefragt werden.
- Theoretische vs. tatsächliche Kardinalität:Diagramme gehen von ein-zu-eins- oder ein-zu-viele-Beziehungen aus. In der Produktion werden diese oft zu viele-zu-viele-Beziehungen mit komplexen Join-Wegen, die die CPU-Ressourcen erschöpfen.
- Abfragegeschwindigkeit:Ein Schema könnte einige Tausend Lesezugriffe pro Sekunde bewältigen, aber bei Tausenden pro Millisekunde an der Granularität der Sperrung scheitern.
- Datenverteilung:Hotspots entstehen, wenn die Daten nicht gleichmäßig über die Speicher-Knoten verteilt sind, was zu einer ungleichmäßigen Lastverteilung führt.
Um effektiv diagnostizieren zu können, müssen Sie aufhören, das Schema als statisches Artefakt zu betrachten. Es ist eine dynamische Ressource, die ebenso sorgfältig überwacht werden muss wie der Server selbst.
2. Häufige strukturelle Engpässe 📉
Der häufigste Grund für Leistungsabfall ist die Beziehungsstruktur selbst. Wie Tabellen miteinander verbunden sind, bestimmt, wie die Engine die Daten durchläuft. Komplexe Joins sind der Hauptgrund für langsame Abfrageausführungszeiten.
2.1 Risiken der Über-Normalisierung
Während die Normalisierung Redundanz verringert, erhöht eine übermäßige Normalisierung die Anzahl der Joins, die erforderlich sind, um ein einzelnes Datenset abzurufen. In Hochlast-Szenarien ist jeder Join ein potenzieller Ausfallpunkt.
- Join-Aufwand:Jeder Join-Vorgang erfordert von der Datenbank, Zeilen aus zwei Tabellen zu verbinden. Wenn diese Tabellen groß sind und keine geeigneten Indizes besitzen, führt die Engine eine vollständige Tabellen-Suche durch.
- Transaktions-Tiefe:Tief normalisierte Schemata erfordern oft lang laufende Transaktionen, um verwandte Daten abzurufen, wodurch Sperrungen über längere Zeiträume gehalten werden.
- Cache-Effizienz:Normalisierte Daten sind über mehrere Seiten verteilt, was die Effektivität des Pufferpool-Cache verringert.
2.2 Unter-Indizierung und Zugriffspfade
Ein gut strukturiertes ERD impliziert Zugriffsmuster. Wenn das Diagramm nicht mit der tatsächlichen Abfragebelastung übereinstimmt, kann die Datenbank-Engine den schnellsten Weg zu den Daten nicht finden.
- Fremdschlüssel-Indizes:Fremdschlüssel besitzen oft keine Indizes, was zu Leistungsabfällen führt, wenn Eltern-Records gelöscht oder aktualisiert werden.
- Reihenfolge der zusammengesetzten Schlüssel:Die Reihenfolge der Spalten in einem zusammengesetzten Index ist entscheidend. Wenn Abfragen zuerst auf die zweite Spalte filtern, kann der Index ignoriert werden.
- Fehlende selektive Indizes:Ohne Indizes auf Spalten mit hoher Kardinalität durchsucht die Engine ganze Tabellen, um bestimmte Werte zu finden.
3. Konkurrenz und Sperre Mechanismen 🔒
Wenn die Last steigt, wird die Konkurrenz zur primären Beschränkung. Mehrere Benutzer, die versuchen, dieselben Daten zu ändern, erzeugen Konkurrenz. Wenn die Schema-Design nicht die Sperre-Granularität berücksichtigt, kommt es zu Deadlocks oder Zeitüberschreitungen.
| Sperrtyp | Auswirkung auf die Last | Typisches Symptom |
|---|---|---|
| Zeilen-Level-Sperre | Minimaler Einfluss, hohe Konkurrenz | Niedrige Latenz, hoher Durchsatz |
| Tabellen-Level-Sperre | Hoher Einfluss, blockiert andere Benutzer | Zeitüberschreitungsfehler, hängende Abfragen |
| Schema-Sperre | Blockiert allen Zugriff während DDL | Systemweiter Ausfall während Wartung |
3.1 Deadlocks und Rennbedingungen
Deadlocks treten auf, wenn zwei Transaktionen aufeinander warten, um Ressourcen freizugeben. Dies wird oft durch inkonsistente Sperre-Reihenfolgen in der Anwendungslogik verursacht, die mit dem Schema interagiert.
- Transaktions-Isolationsstufen: Höhere Isolationsstufen (wie Serializable) bieten Sicherheit, reduzieren aber die Konkurrenz erheblich.
- Sperre-Escalation: Wenn eine Transaktion zu viele Zeilen sperren muss, kann die Engine auf eine Tabellensperre hochgestuft werden, wodurch alle anderen Operationen blockiert werden.
- Lange Transaktionen: Operationen, die Sperren für Sekunden statt Millisekunden halten, erzeugen Engpässe für die gesamte Warteschlange.
4. Datenmenge und Partitionierungsstrategien 📊
Wenn die Daten wachsen, werden die physischen Grenzen der Speicherebene sichtbar. Ein Schema, das für 10.000 Zeilen funktioniert, kann katastrophal versagen, wenn es 100 Millionen Zeilen gibt. Die Partitionierung ist die Methode, große Tabellen in kleinere, handhabbare Teile zu unterteilen.
- Vertikale Partitionierung:Das Verschieben selten genutzter Spalten in eine separate Tabelle verringert die Größe der Haupttabelle und verbessert die Cache-Trefferquote für heiße Daten.
- Horizontale Partitionierung:Das Aufteilen von Zeilen über mehrere physische Segmente (Sharding) verteilt die Last auf mehrere Speicher-Knoten.
- Zeitbasierte Partitionierung: Für transaktionale Daten ermöglicht die Datumsbasierte Partitionierung, dass die Engine alte Partitionen sofort löschen kann, ohne die gesamte Tabelle zu sperren.
5. Diagnose-Workflow für Produktionsausfälle 🔍
Wenn das System langsamer wird, benötigen Sie einen systematischen Ansatz, um die Ursache zu identifizieren. Zufällige Optimierungen verschwenden oft Ressourcen. Folgen Sie diesem Workflow, um das Problem genau zu lokalisieren.
5.1 Analysieren von Abfrage-Ausführungsplänen
Der Ausführungsplan zeigt, wie die Datenbankengine die Daten abrufen möchte. Suchen Sie nach spezifischen Indikatoren für Ineffizienz.
- Vollständige Tabellen-Scans:Deutet auf einen fehlenden Index oder eine Abfrage hin, die zu viel Daten anfordert.
- Schlüssel-Abfragen:Deutet darauf hin, dass die Engine wiederholt zwischen dem Index und den Tabellendaten wechseln muss, was die I/O-Auslastung erhöht.
- Sortieroperationen:Das Sortieren großer Ergebnismengen verbraucht erhebliche Speicher- und CPU-Ressourcen.
5.2 Überwachen von Sperrkonflikten
Verwenden Sie Systemwerkzeuge, um Warteereignisse zu überwachen. Hohe Wartezeiten bei Sperrungen deuten darauf hin, dass das Schema die derzeitige Konkurrenzstufe nicht unterstützen kann.
- Wartezeit-Metriken:Verfolgen Sie die Dauer, die Transaktionen für Ressourcen warten müssen.
- Deadlock-Graphen:Überprüfen Sie historische Daten, um festzustellen, welche Abfragen Konflikte verursacht haben.
- Warteschlange für Sperranfragen:Überwachen Sie die Anzahl der Transaktionen, die auf dieselbe Ressource warten.
5.3 Prüfen des I/O-Subsystem-Zustands
Selbst bei einem perfekten Schema verursacht langsamer Speicher Ausfälle. Stellen Sie sicher, dass die zugrundeliegende Infrastruktur den Datenzugriffsmustern entspricht.
- Durchsatz-Grenzen:Überprüfen Sie, ob das Speichergerät durch Lese-/Schreibvorgänge überlastet ist.
- Verzögerungsspitzen:Unregelmäßige Antwortzeiten der Speicherschicht deuten oft auf eine Hardware-Degradation hin.
- Effizienz des Pufferpools:Wenn die Datenbank mehr Zeit damit verbringt, von der Festplatte statt aus dem Speicher zu lesen, ist das Schema oder das Datenvolumen zu groß für den Cache.
6. Behebungsstrategien für die Schema-Optimierung 🛠️
Sobald der Engpass identifiziert ist, wenden Sie gezielte Änderungen an. Die Umgestaltung eines Produktivschemas erfordert Vorsicht, um Datenverlust oder Ausfallzeiten zu vermeiden.
6.1 Verringern der Join-Komplexität
Vereinfachen Sie die Beziehungen, die am meisten Reibung verursachen. Dies erfordert oft eine De-Normalisierung bestimmter Bereiche des Modells.
- Materialisierte Ansichten: Vorab komplexe Verknüpfungen berechnen und das Ergebnis in einer separaten Tabelle speichern, um eine schnelle Abrufung zu ermöglichen.
- Berechnete Spalten: Abgeleitete Daten direkt in der Tabelle speichern, um Berechnungen zur Abfragezeit zu vermeiden.
- Lesereplikat-Weiterleitung: Leseschwere Abfragen an eine Replikat senden, das eine de-normalisierte Kopie der Daten enthält.
6.2 Optimierung der Indexstrategie
Indizes sind das effektivste Werkzeug, um Abfragen zu beschleunigen, haben aber einen Kostenfaktor bei Schreibvorgängen.
- Gefilterte Indizes: Erstellen Sie Indizes nur für Teilmengen von Daten, die häufig abgefragt werden.
- Abdeckende Indizes: Fügen Sie alle Spalten, die für eine Abfrage benötigt werden, in den Index ein, um den Zugriff auf die Haupttabelle zu vermeiden.
- Indexwartung: Rebuilden oder neu organisieren Sie Indizes regelmäßig, um Fragmentierung durch häufige Aktualisierungen zu vermeiden.
6.3 Implementierung von Weichen Löschungen und Archivierung
Aktive Daten sind schneller abfragbar als historische Daten. Das Verschieben alter Daten aus der Primärtabelle verbessert die Leistung.
- Archivtabellen: Verschieben Sie Datensätze, die älter als ein bestimmter Schwellwert sind, in eine separate, kältere Speicherebene.
- Weiche Löschungen: Markieren Sie Datensätze als gelöscht, ohne sie zu entfernen, um die Tabellenstruktur stabil zu halten, während die Daten logisch versteckt werden.
- Datenaufbewahrungsrichtlinien: Automatisieren Sie das Löschen unnötiger Daten, um ein unkontrolliertes Wachstum zu verhindern.
7. Prüfliste zur Bewertung der Schema-Gesundheit ✅
Stellen Sie vor der Bereitstellung von Änderungen sicher, dass Ihr Modell diesen Kriterien entspricht, um sicherzustellen, dass es Produktionsbelastungen standhält.
| Kriterien | Bestehenbedingung | Fehlerbedingung |
|---|---|---|
| Durchschnittliche Abfragezeit | < 50 ms | > 500 ms |
| Wartezeit auf Sperre | < 10 ms | > 100 ms |
| Indexnutzung | > 90% | < 50% |
| Vollständige Tabellen Scans | Null | Häufig |
Durch regelmäßige Überprüfung Ihres Datenmodells anhand dieser Metriken stellen Sie sicher, dass die Gestaltung sich Ihren geschäftlichen Anforderungen anpasst. Ein statisches Schema wird letztendlich zu einer Belastung. Kontinuierliche Überwachung und schrittweise Anpassungen sind die einzige Möglichkeit, Zuverlässigkeit zu gewährleisten.
8. Verständnis von Abfragemustern und Workloads 📈
Leistung geht nicht nur um das Schema; es geht darum, wie dieses Schema genutzt wird. Das Verständnis des Workload-Profil ist entscheidend für die Optimierung des Modells.
- OLTP gegenüber OLAP:Online-Transaktionsverarbeitung (OLTP) erfordert schnelle, kleine Schreibvorgänge. Online-Analytische Verarbeitung (OLAP) erfordert schnelle, große Lesevorgänge. Ein Schema, das für eines optimiert ist, hat oft Schwierigkeiten mit dem anderen.
- Schreibintensive Muster: Wenn Ihre Anwendung häufig schreibt, sollten Sie die Effizienz von Indizes priorisieren und die Sperren bei Schreibvorgängen minimieren.
- Leseeintensive Muster: Wenn Ihre Anwendung häufig liest, sollten Sie Caching-Strategien und Lese-Replicas priorisieren.
9. Die Rolle der Anwendungslogik für die Datenbankleistung 💻
Oft liegt der Fehler nicht in der Datenbank, sondern darin, wie die Anwendung mit ihr interagiert. N+1-Abfrageprobleme sind ein klassisches Beispiel für ineffiziente Anwendungslogik, die sich als Datenbankausfall äußert.
- Massenoperationen:Das Senden von Tausenden einzelner Einfügeanweisungen ist langsamer als eine einzelne Batch-Operation.
- Lazy Loading:Das Abrufen von Daten in kleinen Teilen kann zu übermäßigen Rundreisen zur Datenbank führen.
- Verbindungspooling:Ineffizientes Management von Datenbankverbindungen kann die verfügbaren Ressourcen während Spitzenlast erschöpfen.
Die Optimierung der Anwendungsebene verringert den Druck auf das Schema und ermöglicht es der Datenbank, innerhalb ihrer vorgesehenen Parameter zu funktionieren.
10. Zukunftssicherung Ihrer Datenarchitektur 🚀
Die Gestaltung für die Zukunft erfordert die Berücksichtigung von Wachstum. Obwohl Sie keine genauen Verkehrsanzahlen vorhersagen können, können Sie für Elastizität gestalten.
- Schema-Evolution: Verwenden Sie Migrationsstrategien, die nicht störungsfreie Änderungen am Datenmodell ermöglichen.
- Horizontale Skalierbarkeit: Gestalten Sie Tabellen von Anfang an so, dass sie Sharding unterstützen.
- Entkoppelte Speicherung: Trennen Sie die Speicherschicht von der Rechenschicht, um sie unabhängig zu skalieren.
Durch die Einhaltung dieser Prinzipien bauen Sie eine Grundlage, die den Anforderungen der Produktion standhält. Das Ziel ist nicht nur, aktuelle Probleme zu beheben, sondern ein widerstandsfähiges System zu schaffen, das sich zukünftigen Herausforderungen anpassen kann.
11. Zusammenfassung der wichtigsten Diagnose-Schritte 📝
Zusammenfassend: Die Diagnose von Lastfehlern in der Produktion erfordert einen mehrschichtigen Ansatz.
- Überprüfen Sie das ERD: Prüfen Sie auf übermäßig komplexe Beziehungen und fehlende Indizes.
- Analysieren Sie Abfragen: Suchen Sie nach vollständigen Tabellen-Scans und ineffizienten Join-Wegen.
- Überwachen Sie Sperrungen: Identifizieren Sie Konkurrenzpunkte, die zu Timeouts führen.
- Überprüfen Sie die Hardware: Stellen Sie sicher, dass Speicher und Arbeitsspeicher keine Engpässe darstellen.
- Optimieren Sie das Schema: Wenden Sie Partitionierungs- und Indizierungsstrategien an.
- Refaktorisieren Sie die Anwendung: Verringern Sie die Anzahl der Datenbankaufrufe und optimieren Sie die Transaktionsverwaltung.
Durch die Einhaltung dieses strukturierten Ansatzes stellen Sie sicher, dass Sie die Ursache, nicht nur die Symptome, angehen. Die Leistungsoptimierung ist ein iterativer Prozess, der Geduld und Präzision erfordert.
12. Abschließende Gedanken zur Schema-Resilienz 🧠
Ein robustes Datenmodell ist die Grundlage jeder hochleistungsfähigen Anwendung. Es erfordert ständige Aufmerksamkeit und die Bereitschaft, sich an veränderte Verkehrsströme anzupassen. Durch das Verständnis der Feinheiten von Beziehungen, Indizierung und Konkurrenz können Sie die häufigen Fallen vermeiden, die zu Produktionsausfällen führen.
Denken Sie daran, dass das Diagramm ein Werkzeug ist, kein System. Der echte Test Ihres Designs findet in der Live-Umgebung statt. Halten Sie Ihre Überwachung eng, Ihre Indizes sauber und Ihre Transaktionen kurz. Mit diesen Praktiken wird Ihre Datenarchitektur eine zuverlässige Grundlage für Ihr Geschäftswachstum bilden.
Bleiben Sie wachsam. Überwachen Sie Ihre Metriken. Refaktorisieren Sie, wenn nötig. Ihr System wird es Ihnen danken.

