











Построение надежной архитектуры бэкенда требует больше, чем просто написание эффективного кода; это требует фундаментального понимания того, как данные структурируются, хранятся и извлекаются под нагрузкой. В центре этой инфраструктуры находится диаграмма сущность-связь (ERD). Хотя ERD часто рассматривается как статический чертеж, созданный на начальном этапе планирования, хорошо спроектированная ERD служит динамическим основанием для систем с высокой нагрузкой. При резком росте трафика схема базы данных определяет производительность, задержку и доступность. Плохо структурированная модель может привести к цепной реакции сбоев, в то время как масштабируемый дизайн позволяет беспрепятственно адаптироваться к росту.
Это руководство исследует технические нюансы построения диаграмм сущность-связь, способных выдерживать высокие нагрузки. Мы выйдем за рамки базовой нормализации и рассмотрим, как взаимодействуют отношения, ограничения и стратегии физического хранения данных в распределенных средах. Независимо от того, проектируете ли вы систему для миллионов одновременных пользователей или просто планируете будущее расширение, принципы, изложенные здесь, создают основу для устойчивого моделирования данных.
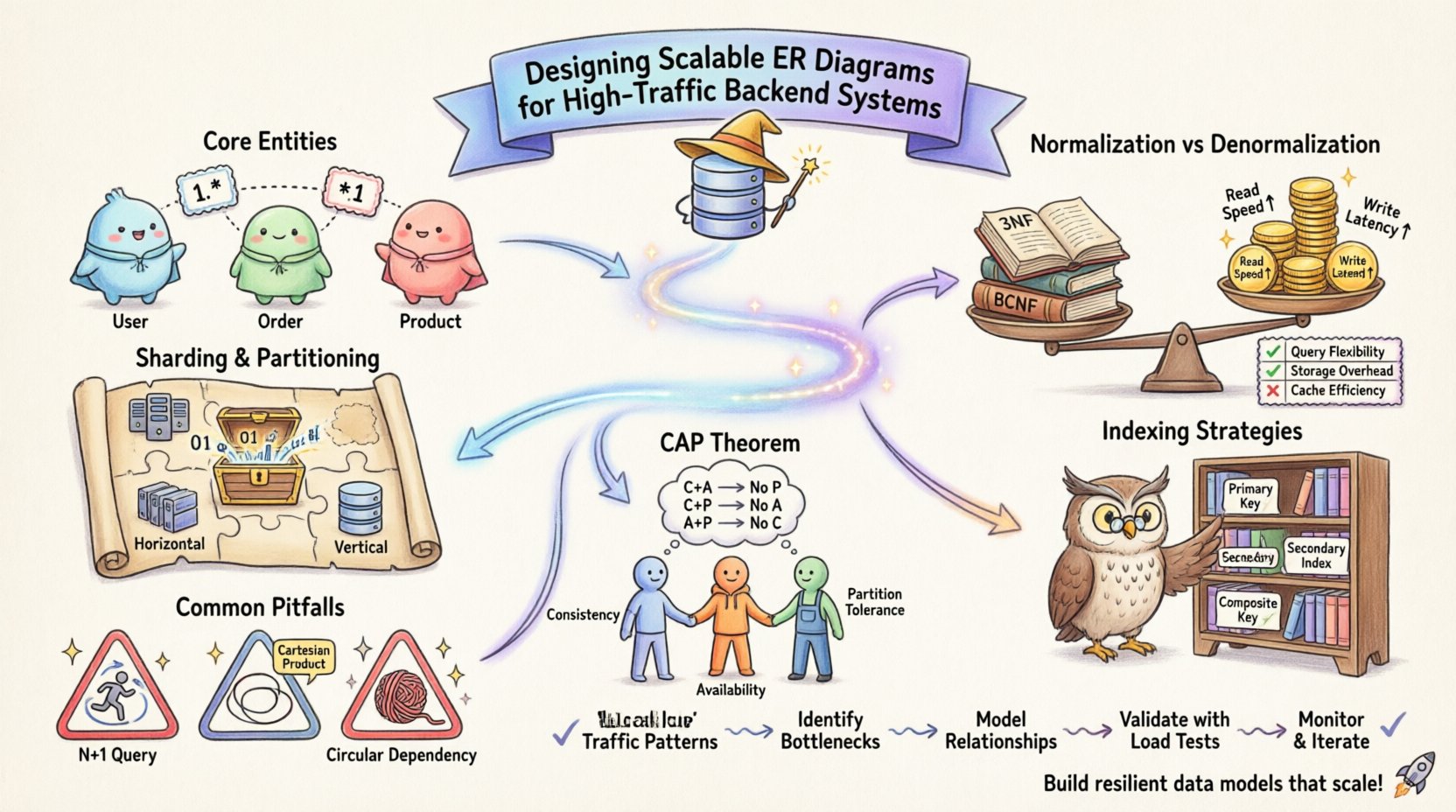
🏗️ Понимание моделирования сущность-связь в масштабе
Основной единицей диаграммы сущность-связь является сущность, представляющая отдельный объект или концепцию в вашей системе. В среде с низкой нагрузкой часто преобладает простота. Однако по мере роста объема транзакций сложность взаимодействий между сущностями возрастает экспоненциально. Системы с высокой нагрузкой требуют смены перспективы: от «как должна выглядеть эта информация?» к «как эта информация будет работать под нагрузкой?».
- Определите основные сущности: Определите, какие объекты данных чаще всего обращаются. Это ваши критические пути.
- Проанализируйте кардинальность: Определите отношения между сущностями. Отношения один-ко-многим, многие-ко-многим и один-к-одному имеют разные последствия для производительности.
- Детализация атрибутов: Определите, насколько детализировано хранить информацию в атрибуте. Чрезмерно детализированные атрибуты могут увеличить размер строк, а чрезмерно общие — затруднить точность запросов.
При проектировании с учетом масштабирования физическое расположение данных становится таким же важным, как и логическая структура. ERD должна отражать не только бизнес-логику, но и операционные ограничения движка хранения. Например, некоторые системы обрабатывают блокировку на уровне строк иначе, чем на уровне страниц. Ваша диаграмма должна учитывать эти ограничения, минимизируя точки конкуренции.
📊 Нормализация против денормализации: компромисс производительности
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя традиционно она преподается как универсальный лучший подход, системы с высокой нагрузкой часто требуют сбалансированного подхода. Строгое следование Третьей нормальной форме (3NF) может привести к избыточному количеству операций соединения. В распределенной или высоконагруженной среде соединения между несколькими таблицами могут стать серьезными узкими местами.
Напротив, денормализация предполагает дублирование данных для уменьшения необходимости в соединениях. Этот подход улучшает производительность чтения, но усложняет операции записи. Вам необходимо поддерживать согласованность в дублирующихся полях, что добавляет логики на уровень приложения.
| Стратегия | Производительность чтения | Производительность записи | Согласованность данных | Стоимость хранения |
|---|---|---|---|---|
| Полная нормализация | Низкая (множественные соединения) | Высокая (одна запись) | Высокая | Низкая |
| Частичная денормализация | Высокая (меньше соединений) | Средняя (обновление дублирования) | Средняя | Средняя |
| Полная денормализация | Очень высокий | Низкий (сложная логика) | Низкий (требует синхронизации) | Высокий |
Выбор правильного баланса зависит от соотношения чтения к записи. Если ваша система ориентирована на чтение, например, лента контента или новостная платформа, денормализация часто необходима. Если ваша система ориентирована на запись, например, журнал транзакций, нормализация помогает предотвратить аномалии.
🌐 Стратегии оптимизации чтения и записи
Оптимизация для высокой нагрузки включает специфические техники, влияющие на форму вашей ERD. Эти стратегии направлены на сокращение времени, необходимого для получения или хранения информации.
1. Стратегии кэширования, отраженные в схеме
При проектировании модели данных учитывайте, как будет происходить кэширование данных. Часто используемые сущности должны быть структурированы так, чтобы обеспечить простую сериализацию. Избегайте хранения больших переменных блобов в таблицах, которые часто объединяются. Вместо этого храните ссылочный ключ и извлекайте блоб отдельно, когда это необходимо. Это снижает нагрузку на основной уровень кэша.
2. Ключи партиционирования и шардинга
По мере роста данных хранение в одной таблице становится неэффективным. Шардинг разделяет данные между несколькими узлами. Ваша ERD должна четко определять ключ шардинга. Этот ключ определяет, как строки распределяются. Если ключ шардинга выбран неудачно, может возникнуть ситуация «горячих партиций», когда один узел обрабатывает значительно больше трафика, чем другие.
- Горизонтальное шардинг: Разделяет строки на основе ключа. ERD должна показывать, как распределяется ключ.
- Вертикальное шардинг: Разделяет столбцы между таблицами. Полезно для разделения тяжелых столбцов (например, журналов) от основных транзакционных данных.
🔗 Управление отношениями в разделяемых данных
Отношения — это связующее звено, которое объединяет базу данных, но в распределенной системе они могут стать источником задержек. Внешние ключи обеспечивают целостность ссылок, но в среде с шардингом проверка этих ограничений между узлами является дорогостоящей операцией.
Обработка отношений «многие ко многим»
Отношения «многие ко многим» требуют промежуточной таблицы. В условиях высокой нагрузки эта таблица может стать узким местом. Если запросы выполняются часто, рассмотрите возможность денормализации отношения. Вместо объединения с промежуточной таблицей храните идентификатор отношения непосредственно в родительской сущности, если позволяет кардинальность. Это снижает глубину запроса.
Самоссылающиеся сущности
Некоторые сущности ссылаются сами на себя, например, категории или иерархические комментарии. Тщательно проектируйте такие отношения. Глубокая рекурсия в запросах может исчерпать системные ресурсы. Ограничьте глубину цепочек самоссылок в вашей логике или упростите структуру, где возможно, используя материализованные пути.
🔍 Стратегии индексации для производительности
ERD определяет логическую структуру, но индексы определяют физическую скорость извлечения данных. Хотя сама диаграмма не показывает индексы, решения по проектированию влияют на то, какие индексы являются целесообразными.
- Первичные ключи: В многих системах они кластеризованы, то есть данные физически сортируются по этому ключу. Выберите первичный ключ, который минимизирует фрагментацию и обеспечивает равномерное распределение.
- Вторичные индексы: Каждый индекс потребляет производительность при записи. Слишком много индексов замедляет операции вставки и обновления. Индексируйте только те столбцы, которые часто используются в выражениях `WHERE`, `JOIN` или `ORDER BY`.
- Составные индексы: Когда несколько столбцов запрашиваются вместе, составной индекс может быть более эффективным. Порядок столбцов в индексе имеет значение и должен соответствовать наиболее распространённым шаблонам запросов.
⚖️ Согласованность против доступности в распределенных схемах
Теория баз данных часто обсуждает теорему CAP, которая предполагает, что система может гарантировать только две из трех характеристик: согласованность, доступность и устойчивость к разделению. Ваше проектирование ERD влияет на то, какие из этих характеристик вы будете приоритизировать.
Если вы приоритетом ставите согласованность, вы будете проектировать с жесткими внешними ключами и транзакциями ACID. Это обеспечивает целостность данных, но может привести к задержкам во время сетевых разделений. Если вы приоритетом ставите доступность, вы можете ослабить ограничения, допуская временные несогласованности. В этом случае ваша ERD должна поддерживать паттерны конечной согласованности, например, наличие столбца «версия» или «статус» для отслеживания состояния данных.
🔄 Эволюция схемы и версионирование
Требования к программному обеспечению меняются. Схема базы данных должна эволюционировать без простоя. В системах с высокой нагрузкой вы не можете просто удалить и заново создать таблицы. Стратегии миграции должны быть заложены в процесс проектирования ERD.
- Совместимость с предыдущими версиями: При добавлении столбца сначала сделайте его допускающим значение NULL. Это позволит старому коду продолжать работать, пока новый код заполняет данные.
- Расширяемые типы: По возможности избегайте типов с фиксированной длиной. Используйте строки переменной длины или поля JSON для атрибутов, структура которых может меняться со временем.
- Логическое удаление: Вместо физического удаления строк помечайте их как неактивные. Это сохраняет целостность ссылок для исторических данных и избегает каскадных операций удаления, которые могут блокировать большие участки таблицы.
🛑 Распространённые структурные ловушки
Даже опытные архитекторы сталкиваются с ловушками при масштабировании. Осознание этих распространённых проблем может сэкономить значительное время на этапе проектирования.
1. Проблема N+1 запросов
Это происходит, когда приложение получает список записей, а затем выполняет отдельный запрос для каждой записи, чтобы получить связанную информацию. В вашей ERD выделите отношения, которые часто используются вместе. Если вы ожидаете частого получения связанной информации, рассмотрите возможность денормализации или создания специализированных представлений для чтения.
2. Декартово произведение
При соединении нескольких больших таблиц без правильной фильтрации размер результирующего набора может расти экспоненциально. Убедитесь, что ваша ERD включает ограничения, которые ограничивают возможный размер результатов соединения. Используйте фильтры по внешним ключам, чтобы ограничить охват отношений.
3. Циклические зависимости
Сущности не должны зависеть друг от друга в цикле. Например, сущность A нуждается в сущности B, а сущность B нуждается в сущности A для инициализации. Это создаёт сценарий взаимоблокировки при запуске или загрузке данных. Разорвите такие циклы, введя промежуточную сущность или инициализируя данные в определённом порядке.
📝 Обслуживание и мониторинг
Проектирование — это не одноразовое событие. Как только система запущена, вы должны мониторить состояние вашей структуры данных. Показатели производительности должны направлять будущие корректировки ERD.
- Анализ запросов: Регулярно проверяйте журналы медленных запросов. Если конкретное соединение постоянно медленное, пересмотрите ERD, чтобы увидеть, можно ли оптимизировать это отношение.
- Проверки фрагментации: Со временем удаления и обновления могут привести к фрагментации хранилища. Планируйте периоды обслуживания, когда будут перестроены индексы или оптимизированы таблицы.
- Планирование ёмкости: По мере роста данных изменяются требования к хранилищу. Оцените темп роста ваших самых больших таблиц и заранее спланируйте шардинг или партиционирование, чтобы не достигнуть пределов ёмкости.
🛠️ Практическое применение: масштабируемый рабочий процесс
Чтобы реализовать эти принципы, при создании диаграммы следуйте структурированному рабочему процессу.
- Сбор требований: Определите соотношение чтения/записи и ожидаемые паттерны трафика.
- Логическое моделирование: Создайте диаграмму ERD, сосредоточившись на бизнес-сущностях и отношениях, не беспокоясь о физических ограничениях.
- Физическое моделирование: Преобразуйте логическую модель в физическую схему. Добавьте индексы, определите типы данных и рассмотрите стратегии партиционирования.
- Обзор и валидация: Симулируйте запросы с высокой нагрузкой против модели. Выявите потенциальные узкие места в операциях соединения или блокировок.
- Документация: Документируйте обоснование выбора архитектуры. Это поможет будущим разработчикам понять, почему был выбран конкретный уровень нормализации.
🔮 Защита вашей архитектуры от будущих изменений
Технологии быстро развиваются. То, что работает сегодня, может перестать работать через пять лет. Проектируйте с учетом гибкости. Избегайте слишком тесной привязки схемы к конкретной особенности движка хранения, которая может устареть. Сосредоточьтесь на логических отношениях и правилах целостности данных, поскольку они остаются неизменными даже при изменении базовой технологии.
Следуя этим рекомендациям, вы создадите модель данных, которая будет не только функциональной для текущих потребностей, но и достаточно устойчивой, чтобы справляться с непредсказуемостью сред с высокой нагрузкой. Цель — построить систему, которая будет стабильно работать, масштабироваться горизонтально и оставаться поддерживаемой в течение длительного времени.

