











Схемы сущностей и отношений (ERD) часто игнорируются некоторыми как академические упражнения или артефакты, созданные исключительно для соответствия документации. Однако для старших разработчиков и архитекторов схема ER является стратегическим планом, определяющим стабильность, производительность и поддерживаемость слоя данных приложения. Проблема заключается не в рисовании прямоугольников и линий, а в преодолении противоречий между теоретическим моделированием данных и сложными ограничениями производственной среды.
При построении систем вы постоянно делаете компромиссы. Идеально нормализованная схема обеспечивает целостность данных, но может привести к снижению производительности при сложных запросах. Структура с денормализацией ускоряет чтение, но вводит избыточность и аномалии обновления. Цель — найти баланс, при котором схема точно отражает бизнес-домен, не становясь угрозой при развертывании.
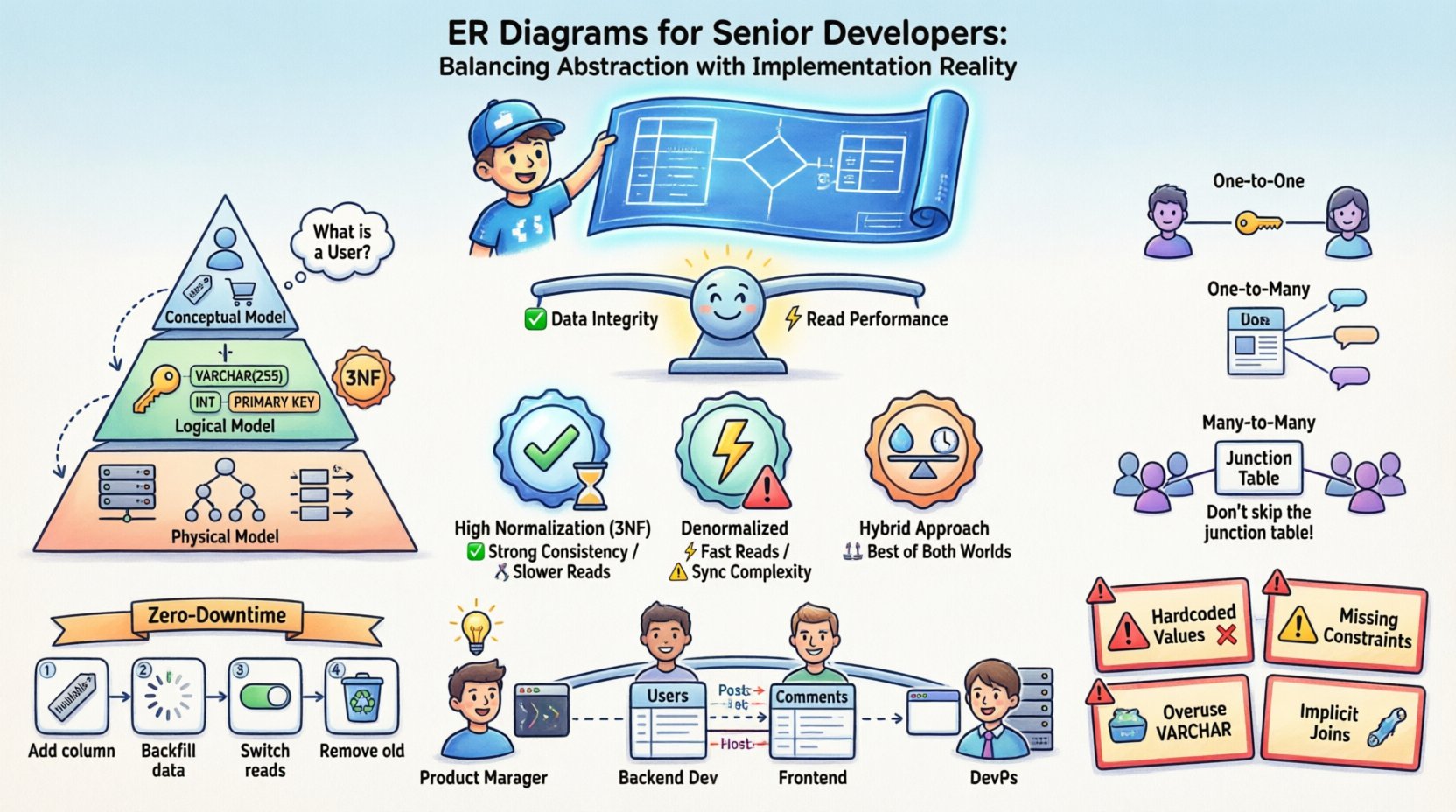
Двойственная природа схем сущностей и отношений 📐
Понимание жизненного цикла схемы ER требует признания того, что она служит нескольким заказчикам. Это не статическое изображение, а живой документ, который развивается вместе с программным обеспечением. Существует три разных уровня абстракции, которые необходимо управлять отдельно, чтобы избежать путаницы между тем, какими должны быть данные,должнывыглядеть, и тем, какими ониявляютсявыглядят в памяти.
- Концептуальная модель: Этот уровень фокусируется на бизнес-сущностях и их отношениях без технических деталей. Он отвечает на вопросы, такие как «Что такое Пользователь?» и «Как Пользователь связан с Заказом?». Он не зависит от технологии.
- Логическая модель: Здесь вы вводите типы данных, ключи и правила нормализации. Вы определяете первичные и внешние ключи, но еще не привязываетесь к конкретной системе хранения или стратегии индексации базы данных.
- Физическая модель: Это реальность реализации. Включает имена таблиц, типы данных столбцов, стратегии партиционирования, индексацию и ограничения, специфичные для целевой системы баз данных. Именно здесь начинается практическая реализация.
Зачастую возникает путаница, когда эти уровни смешиваются. Старший разработчик знает, что в физической модели прячутся ошибки. Концептуальная связь «многие ко многим» должна быть преобразована в конкретные ограничения внешнего ключа в физической модели, часто требуя вспомогательных таблиц, которых не существует в исходной бизнес-логике.
Уровни абстракции в моделировании данных 🧩
Управление этими уровнями требует дисциплины. Когда заинтересованная сторона запрашивает функцию, она описывает её на бизнес-языке. Разработчик должен перевести это в логическую схему, а затем — в физическую. Пропуск этапов приводит к накоплению технического долга.
1. Концептуальное моделирование: язык бизнеса
На этом этапе схема является инструментом коммуникации. Она обеспечивает согласие между командой разработчиков и командой продукта по модели домена. Если схема показывает, что «Клиент» может иметь несколько «Адресов», все согласны с этим фактом до написания первого SQL-запроса.
2. Логическое моделирование: правила взаимодействия
Это тот этап, где применяются правила нормализации. Вы определяете, что «Клиент» не должен хранить свой «Адрес» напрямую, если этот адрес может часто меняться и принадлежать другим сущностям. Вы вводите нормализацию для уменьшения избыточности. Однако вы также выявляете данные, которые будут часто читаться, и которые могут потребовать денормализации в будущем.
3. Физическое моделирование: реальность реализации
Это тот этап, где проявляются ограничения движка базы данных. Вам может понадобиться выбрать между столбцом JSON и отдельной реляционной таблицей для гибких атрибутов. Вы принимаете решение о стратегиях индексации на основе шаблонов запросов. Возможно, вы решите использовать конкретный движок хранения, который обеспечивает более быструю запись, но медленное чтение.
Стратегии нормализации и компромиссы производительности ⚖️
Нормализация — фундаментальное понятие в проектировании баз данных. Она организует данные для уменьшения избыточности и повышения целостности данных. Однако в масштабных системах строгое следование правилам нормализации может стать узким местом. Старшие разработчики должны понимать, когда нужно нарушать правила.
Стоимость нормализации
Когда вы нормализуете данные, вы часто создаете больше таблиц. Это означает больше соединений при запросах. В распределенной системе или в веб-приложении с высокой нагрузкой каждое соединение может стать точкой потенциальной задержки. Если таблица партиционирована, соединение между партициями может быть дорогостоящим.
Когда следует денормализовать
Денормализация — это сознательное введение избыточности для оптимизации производительности чтения. Это не ошибка, а стратегическое решение. Вы должны рассмотреть денормализацию, когда:
- Операции чтения значительно превосходят операции записи.
- Сложные соединения вызывают тайм-ауты или высокую загрузку ЦП.
- Вы строите слой отчетности или аналитики, где согласованность в реальном времени менее важна.
- Вам нужно денормализовать данные для слоев кэширования, чтобы снизить нагрузку на базу данных.
Матрица нормализации против производительности
| Стратегия | Целостность данных | Производительность записи | Производительность чтения | Поддерживаемость |
|---|---|---|---|---|
| Высокая нормализация (3НФ) | Высокая | Быстро (меньше избыточности) | Медленнее (требуются соединения) | Высокая (простые обновления) |
| Денормализовано | Ниже (требуется ручная синхронизация) | Медленнее (больше данных для записи) | Быстрее (меньше соединений) | Ниже (риски несогласованности) |
| Гибридный подход | Умеренно | Умеренно | Умеренно до быстро | Умеренно (требуется четкая логика) |
Понимание этой матрицы позволяет принимать обоснованные решения. Вы не просто «нормализуете всё» или «денормализуете всё». Вы анализируете конкретные паттерны доступа к вашему приложению.
Моделирование сложных отношений 🔗
Отношения являются основой диаграммы ER. Они определяют, как взаимодействуют между собой сущности данных. Хотя отношения один-к-одному и один-ко-многим просты, отношения многие-ко-многим часто требуют тщательного подхода для обеспечения масштабируемости.
Отношения один-к-одному
На практике они редки, но существуют. Например, профиль пользователя и таблица настроек профиля пользователя. Вы можете реализовать это, поместив внешний ключ в одну из таблиц или разделив данные на две таблицы. Решение зависит от паттернов доступа. Если настройки часто используются вместе с профилем, храните их вместе. Если они редко используются, разделяйте их, чтобы уменьшить размер основной таблицы.
Соотношения один ко многим
Это наиболее распространённый шаблон. Пост блога имеет много комментариев. Внешний ключ находится на стороне «многих» (комментарии). Это эффективно для запросов, которые извлекают все комментарии для конкретного поста.
Соотношения многие ко многим
Пользователь может следить за многими пользователями, и пользователь может быть следуем многими пользователями. Для этого требуется промежуточная таблица соединения. Эта таблица обычно хранит внешние ключи с обеих сторон, а также любую специфическую информацию о связи, например, метку времени, когда была установлена связь.
- Не пропускайте таблицу соединения: Это позволяет вам индексировать связь и эффективно выполнять запросы.
- Рассмотрите составные ключи: Первичный ключ таблицы соединения может быть комбинацией двух внешних ключей.
- Обратите внимание на кардинальность: Убедитесь, что вы обрабатываете случаи, когда связь является необязательной или обязательной.
Эволюция схемы и миграция 🔄
Одной из самых сложных задач для старшего разработчика является осознание того, что диаграмма ER никогда не будет завершена. Требования меняются, бизнес-логика трансформируется, а данные растут. Ваша схема должна эволюционировать без нарушения существующей функциональности.
Версионирование схемы
Никогда не предполагайте, что миграция — это одноразовое событие. Воспринимайте свою схему как код. Используйте систему контроля версий для скриптов миграции. Это позволяет откатить изменения, если новый столбец вызовет проблему. Это также обеспечивает аудиторский журнал изменений структуры данных с течением времени.
Миграции без простоя
Для систем в продакшене простои часто неприемлемы. Это требует поэтапного подхода к изменениям схемы:
- Сначала добавьте столбцы: Добавьте новый столбец как разрешённый к NULL. Разверните код, который записывает в него.
- Заполните данные: Запустите фоновую задачу для заполнения нового столбца.
- Переключите чтение: Обновите приложение, чтобы оно читало из нового столбца.
- Удалите старые столбцы: Как только система станет стабильной, удалите старый столбец.
Обработка блокировок
Добавление индекса или ограничения на большую таблицу может заблокировать таблицу, останавливая запись. Вам необходимо использовать инструменты изменения схемы в режиме онлайн или стратегии партиционирования, чтобы минимизировать продолжительность блокировки. Понимание механизма блокировок базы данных, лежащей в основе, здесь критически важно.
Распространённые ошибки в производственных средах 🚧
Даже опытные разработчики допускают ошибки при преобразовании ERD в SQL. Осознание распространённых ловушек помогает избежать их до того, как они станут критическими проблемами.
- Жёстко закодированные значения: Избегайте использования столбцов `INT` для хранения булевых флагов (0/1) без явных ограничений. Используйте типы `BOOLEAN` или перечисляемые типы, если они поддерживаются.
- Отсутствующие ограничения:Опора исключительно на логику приложения для обеспечения внешних ключей опасна. Если ошибка позволит выполнить некорректную вставку, данные будут повреждены. Обеспечьте ограничения на уровне базы данных.
- Чрезмерное использование VARCHAR:Хотя гибкий, `VARCHAR` может быть медленнее, чем типы фиксированной длины, такие как `CHAR`, для определённых данных. Используйте `CHAR` для данных фиксированной длины, таких как UUID или почтовые индексы.
- Пренебрежение наборами символов:Если ваше приложение поддерживает международные символы, убедитесь, что ваша база данных и таблицы настроены на поддержку UTF-8 с самого начала. Изменение этого позже затруднительно.
- Неявные соединения:Избегайте запросов, которые соединяют таблицы без явных индексов. Всегда проверяйте план выполнения запроса.
Общение между командами 🤝
Схема ER — это инструмент коммуникации. Она устраняет разрыв между администраторами баз данных, разработчиками бэкенда, разработчиками фронтенда и менеджерами продуктов. Чёткая схема предотвращает предположения.
- Для менеджеров продуктов:Это помогает им понять требования к данным при запросе функции.
- Для разработчиков фронтенда:Она уточняет структуру данных, которые они получат от API.
- Для DevOps:Она информирует о планировании ёмкости и стратегиях резервного копирования.
Если схема неясна, команда будет догадываться. Догадки приводят к ошибкам. Старший разработчик обеспечивает точность, актуальность и доступность схемы для всех, кто участвует в жизненном цикле проекта.
Инструменты против мышления 💡
Существует множество инструментов для создания схем ER. Хотя они полезны для визуализации, они не должны заменять критическое мышление. Инструмент может сгенерировать SQL из схемы, но он не может понять бизнес-логику, лежащую в основе существования связи.
- Фокус на логике:Тратьте больше времени на доске или в текстовых редакторах, обсуждая модель, чем на клики по кнопкам в инструменте рисования.
- Проверяйте с помощью SQL:Как только схема нарисована, напишите SQL. Если SQL неясен, схема, скорее всего, неудачна.
- Держите всё просто:Не усложняйте схему. Если связь может быть выведена, не навязывайте сложную структуру.
Заключительные мысли о моделировании данных 🏁
Создание надёжного слоя данных — это баланс теории и практики. Схема ER — это не просто рисунок; это договор между вашим приложением и данными. Когда вы уважаете уровни абстракции, понимаете компромиссы между нормализацией и производительностью и планируете эволюцию с первого дня, вы создаёте системы, устойчивые к сбоям и масштабируемые.
Самые эффективные старшие разработчики — те, кто может взглянуть на схему из прямоугольников и линий и сразу увидеть потенциальные запросы, вероятные узкие места и путь миграции. Они не просто рисуют линии; они проектируют системы. Сосредоточившись на этих принципах, вы обеспечиваете, чтобы ваша архитектура данных поддерживала бизнес-цели, не превращаясь в бремя.

