











Diagramas de Relacionamento de Entidades (ERDs) são frequentemente descartados por alguns como exercícios acadêmicos ou artefatos criados exclusivamente para atender à conformidade documental. No entanto, para desenvolvedores sênior e arquitetos, um diagrama ER é um plano estratégico que define a estabilidade, o desempenho e a manutenibilidade da camada de dados de uma aplicação. O desafio não está em desenhar caixas e linhas, mas em navegar o atrito entre o modelamento teórico de dados e as complexas restrições dos ambientes de produção.
Ao construir sistemas, você está constantemente fazendo concessões. Um esquema perfeitamente normalizado garante a integridade dos dados, mas pode gerar penalidades de desempenho em consultas complexas. Uma estrutura desnormalizada acelera leituras, mas introduz redundância e anomalias de atualização. O objetivo é encontrar o equilíbrio em que o diagrama reflita com precisão o domínio do negócio sem se tornar uma armadilha durante a implantação.
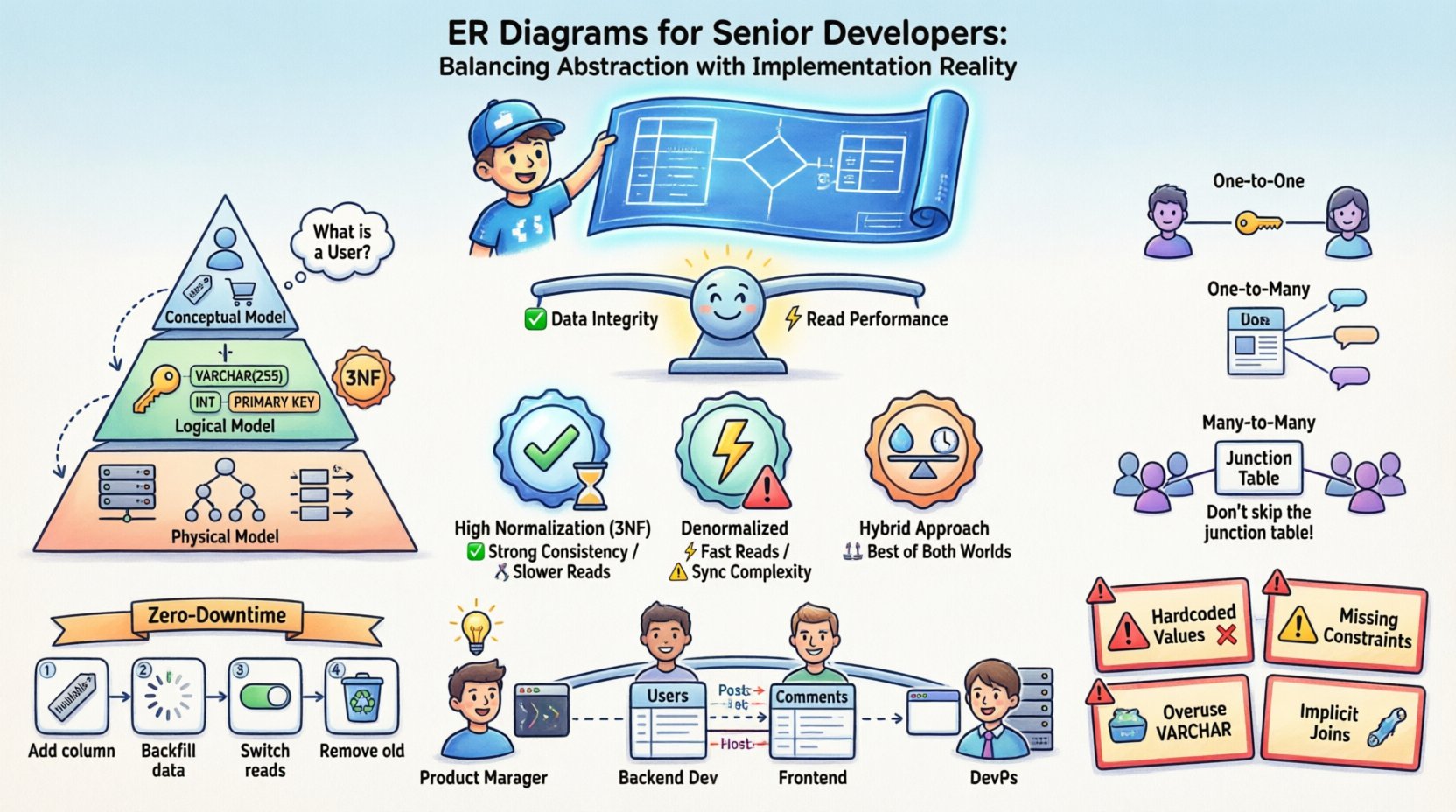
A Natureza Dual dos Diagramas de Relacionamento de Entidades 📐
Compreender o ciclo de vida de um diagrama ER exige reconhecer que ele serve múltiplos mestres. Não é uma imagem estática, mas um documento vivo que evolui junto com o software. Existem três camadas distintas de abstração que devem ser gerenciadas separadamente para evitar confusão entre o que os dados deveriamdeveriam parecer e o que eles realmente sãoparecem na memória.
- Modelo Conceitual: Esta camada foca nas entidades de negócios e suas relações, sem detalhes técnicos. Responde perguntas como “O que é um Usuário?” e “Como um Usuário se relaciona com um Pedido?”. É independente de tecnologia.
- Modelo Lógico: Aqui, você introduz tipos de dados, chaves e regras de normalização. Define chaves primárias e estrangeiras, mas ainda não se compromete com o motor de armazenamento ou a estratégia de indexação específica de um banco de dados.
- Modelo Físico: Este é a realidade da implementação. Inclui nomes de tabelas, tipos de dados de colunas, estratégias de particionamento, indexação e restrições específicas do sistema de banco de dados-alvo. É aqui que a teoria se encontra com a prática.
A confusão surge frequentemente quando essas camadas são confundidas. Um desenvolvedor sênior sabe que o modelo físico é onde os bugs se escondem. Uma relação conceitual do tipo “Muitos para Muitos” deve ser resolvida em restrições de chaves estrangeiras específicas no modelo físico, frequentemente exigindo tabelas de junção que não existem na lógica de negócios original.
Camadas de Abstração na Modelagem de Dados 🧩
Gerenciar essas camadas exige disciplina. Quando um interessado solicita um recurso, ele o descreve em termos de negócios. O desenvolvedor deve traduzir isso em um esquema lógico e, finalmente, em um esquema físico. Pular etapas aqui gera dívida técnica.
1. Modelagem Conceitual: A Linguagem do Negócio
Nesta fase, o diagrama é uma ferramenta de comunicação. Garante que a equipe de engenharia e a equipe de produto concordem com o modelo de domínio. Se o diagrama mostra que um “Cliente” pode ter múltiplos “Endereços”, todos concordam com esse fato antes de qualquer linha de SQL ser escrita.
2. Modelagem Lógica: As Regras de Engajamento
É aqui que você aplica as regras de normalização. Você determina que um “Cliente” não deve armazenar seu “Endereço” diretamente se esse endereço puder mudar frequentemente e pertencer a outras entidades. Introduz a normalização para reduzir a redundância. No entanto, também identifica quais dados serão intensamente lidos e podem exigir desnormalização posteriormente.
3. Modelagem Física: A Realidade da Implementação
É aqui que as limitações do motor de banco de dados entram em ação. Você pode precisar escolher entre uma coluna JSON e uma tabela relacional separada para atributos flexíveis. Decide sobre estratégias de indexação com base nos padrões de consulta. Pode decidir usar um motor de armazenamento específico que suporte gravações mais rápidas, mas leituras mais lentas.
Estratégias de Normalização e Compromissos de Desempenho ⚖️
A normalização é um conceito fundamental no design de bancos de dados. Organiza os dados para reduzir a redundância e melhorar a integridade dos dados. No entanto, em sistemas de grande escala, a aderência rígida às regras de normalização pode se tornar um gargalo. Desenvolvedores sênior precisam entender quando quebrar as regras.
O Custo da Normalização
Quando você normaliza os dados, frequentemente cria mais tabelas. Isso significa mais junções ao consultar. Em um sistema distribuído ou em uma aplicação web de alta tráfego, cada junção é um ponto potencial de latência. Se uma tabela for particionada, fazer junções entre partições pode ser cara.
Quando Desnormalizar
A desnormalização é a introdução intencional de redundância para otimizar o desempenho de leitura. Não é um erro; é uma decisão estratégica. Você deve considerar a desnormalização quando:
- As operações de leitura superam significativamente as operações de escrita.
- Junções complexas estão causando tempos limite ou uso elevado de CPU.
- Você está construindo uma camada de relatórios ou análise em que a consistência em tempo real é menos crítica.
- Você precisa desnormalizar dados para camadas de cache para reduzir a carga no banco de dados.
Matriz de Normalização versus Desempenho
| Estratégia | Integridade dos Dados | Desempenho de Escrita | Desempenho de Leitura | Manutenibilidade |
|---|---|---|---|---|
| Alta Normalização (3FN) | Alto | Rápido (menos redundância) | Mais lento (requer junções) | Alto (atualizações fáceis) |
| Desnormalizado | Mais baixo (sincronização manual necessária) | Mais lento (mais dados para gravar) | Mais rápido (menos junções) | Mais baixo (risco de inconsistência) |
| Abordagem Híbrida | Moderado | Moderado | Moderado a Rápido | Moderado (requer lógica clara) |
Compreender esta matriz permite que você tome decisões informadas. Você não simplesmente ‘normaliza tudo’ ou ‘desnormaliza tudo’. Você analisa os padrões específicos de acesso da sua aplicação.
Modelagem de Relacionamentos Complexos 🔗
Relacionamentos são o núcleo de um diagrama ER. Eles definem como entidades de dados interagem. Embora os relacionamentos Um para Um e Um para Muitos sejam diretos, os relacionamentos Muitos para Muitos frequentemente exigem um manejo cuidadoso para garantir escalabilidade.
Relacionamentos Um para Um
Esses são raros na prática, mas existem. Por exemplo, um perfil de usuário e uma tabela de configurações do perfil de usuário. Você pode implementar isso colocando uma chave estrangeira em uma tabela ou dividindo os dados em duas tabelas. A decisão depende dos padrões de acesso. Se as configurações forem acessadas frequentemente junto com o perfil, mantenha-as juntas. Se forem raramente acessadas, separe-as para reduzir o tamanho da tabela principal.
Relações Um-Para-Muitos
Este é o padrão mais comum. Uma Publicação de Blog tem muitos Comentários. A chave estrangeira fica no lado “Muitos” (Comentários). Isso é eficiente para consultas que recuperam todos os comentários de uma publicação específica.
Relações Muitos-Para-Muitos
Um Usuário pode seguir muitos Usuários, e um Usuário pode ser seguido por muitos Usuários. Isso exige uma tabela intermediária de junção. Essa tabela geralmente armazena as chaves estrangeiras de ambos os lados, além de qualquer metadado específico para a relação, como uma marca de tempo de quando a conexão foi feita.
- Não pule a tabela de junção: Isso permite que você indexe a relação e faça consultas de forma eficiente.
- Considere chaves compostas: A chave primária da tabela de junção pode ser uma combinação das duas chaves estrangeiras.
- Fique atento à cardinalidade: Certifique-se de lidar com casos em que a relação é opcional versus obrigatória.
Evolução e Migração de Esquemas 🔄
Uma das partes mais difíceis de ser um desenvolvedor sênior é perceber que o diagrama ER nunca está terminado. Os requisitos mudam, a lógica de negócios muda e os dados crescem. Seu esquema deve evoluir sem quebrar a funcionalidade existente.
Versionamento do Esquema
Nunca assuma que uma migração é um evento único. Trate seu esquema como código. Use controle de versão para seus scripts de migração. Isso permite que você reverta alterações se uma nova coluna causar um problema. Também fornece um histórico de auditoria de como a estrutura de dados mudou ao longo do tempo.
Migrações Sem Tempo de Inatividade
Em sistemas de produção, o tempo de inatividade geralmente é inaceitável. Isso exige uma abordagem em fases para as alterações no esquema:
- Adicione colunas primeiro: Adicione a nova coluna como nula. Implante o código que escreve nela.
- Preencha os dados de volta: Execute um trabalho em segundo plano para preencher a nova coluna.
- Mude as leituras: Atualize o aplicativo para ler da nova coluna.
- Remova as colunas antigas: Uma vez que o sistema esteja estável, remova a coluna antiga.
Gerenciamento de Blocos
Adicionar um índice ou uma restrição em uma tabela grande pode bloquear a tabela, interrompendo as gravações. Você deve usar ferramentas de alteração de esquema online ou estratégias de particionamento para minimizar a duração do bloqueio. Compreender o mecanismo de bloqueio do motor de banco de dados subjacente é crucial aqui.
Armadilhas Comuns em Ambientes de Produção 🚧
Mesmo desenvolvedores experientes cometem erros ao traduzir ERDs para SQL. Estar ciente das armadilhas comuns ajuda a evitá-las antes que se tornem problemas críticos.
- Valores Codificados: Evite usar colunas `INT` para armazenar flags booleanos (0/1) sem restrições explícitas. Use tipos `BOOLEAN` ou tipos enumerados quando suportado.
- Restrições Ausentes:Contar exclusivamente com a lógica da aplicação para garantir chaves estrangeiras é arriscado. Se um erro permitir uma inserção incorreta, os dados ficam corrompidos. Aplicar restrições no nível do banco de dados.
- Sobreuso de VARCHAR:Embora flexível, `VARCHAR` pode ser mais lento que tipos de comprimento fixo, como `CHAR`, para certos dados. Use `CHAR` para dados de comprimento fixo, como UUIDs ou códigos postais.
- Ignorar Conjuntos de Caracteres:Se sua aplicação suporta caracteres internacionais, certifique-se de que o banco de dados e as tabelas estejam configurados para suportar UTF-8 desde o início. Alterar isso posteriormente é difícil.
- Junções Implícitas:Evite consultas que unem tabelas sem índices explícitos. Revise sempre o plano de execução da consulta.
Comunicação Entre Equipes 🤝
Um diagrama ER é uma ferramenta de comunicação. Ele fecha a lacuna entre administradores de banco de dados, desenvolvedores de back-end, desenvolvedores de front-end e gerentes de produto. Um diagrama claro evita suposições.
- Para Gerentes de Produto:Ajuda-os a entender os requisitos de dados para uma solicitação de recurso.
- Para Desenvolvedores de Frontend:Deixa claro a estrutura dos dados que eles receberão das APIs.
- Para DevOps:Informa o planejamento de capacidade e estratégias de backup.
Se o diagrama não estiver claro, a equipe vai chutar. Chutar leva a erros. Um desenvolvedor sênior garante que o diagrama seja preciso, atualizado e acessível a todos envolvidos no ciclo de vida do projeto.
Ferramentas vs. Pensamento 💡
Existem muitas ferramentas disponíveis para desenhar diagramas ER. Embora sejam úteis para visualização, não devem substituir o pensamento crítico. Uma ferramenta pode gerar SQL a partir de um diagrama, mas não consegue entender a lógica de negócios por trás da existência de uma relação.
- Foque na Lógica:Passe mais tempo no quadro-negro ou em editores de texto discutindo o modelo do que clicando em botões em uma ferramenta de desenho.
- Valide com SQL:Assim que o diagrama for desenhado, escreva o SQL. Se o SQL estiver confuso, o diagrama provavelmente está incorreto.
- Mantenha Simples:Não sobredesigne o diagrama. Se uma relação puder ser inferida, não force uma estrutura complexa.
Pensamentos Finais sobre Modelagem de Dados 🏁
Construir uma camada de dados robusta é um equilíbrio entre teoria e prática. Um diagrama ER não é apenas uma imagem; é um contrato entre sua aplicação e seus dados. Quando você respeita as camadas de abstração, entende os trade-offs entre normalização e desempenho e planeja a evolução desde o primeiro dia, cria sistemas resilientes e escaláveis.
Os desenvolvedores sênior mais eficazes são aqueles que conseguem olhar para um diagrama de caixas e linhas e imediatamente visualizar as consultas potenciais, os gargalos prováveis e o caminho de migração. Eles não apenas desenham linhas; projetam sistemas. Ao focar nesses princípios, você garante que sua arquitetura de dados apoie seus objetivos de negócios sem se tornar uma carga.

