











データアーキテクチャの世界において、レガシーシステム内のデータ重複という課題は、ほとんど恒久的なものである。組織がインフラを近代化しようとする中で、重複・不整合・孤立したデータの膨大な量が、しばしば主要なボトルネックとなる。この事例研究では、詳細なエンティティ関係図(ERD)が、大規模なマイグレーションプロジェクト中に重要なデータ整合性の問題を解決するための設計図として機能した実際の状況を検証する。
目標は明確だった。データの整合性を損なわず、新たな不整合を生じさせず、断片化されたフラットファイルベースのレガシーエンバイメントから、堅牢なリレーショナルデータベースへの移行である。解決策は移行ツールそのものにあったのではなく、1バイトも移動する前に、データの視覚的モデリングと論理的構造化にあった。我々は、その手法、具体的に直面した正規化の課題、そしてスキーマ設計に対する厳格なアプローチの結果として得られた実質的な成果を検討する。
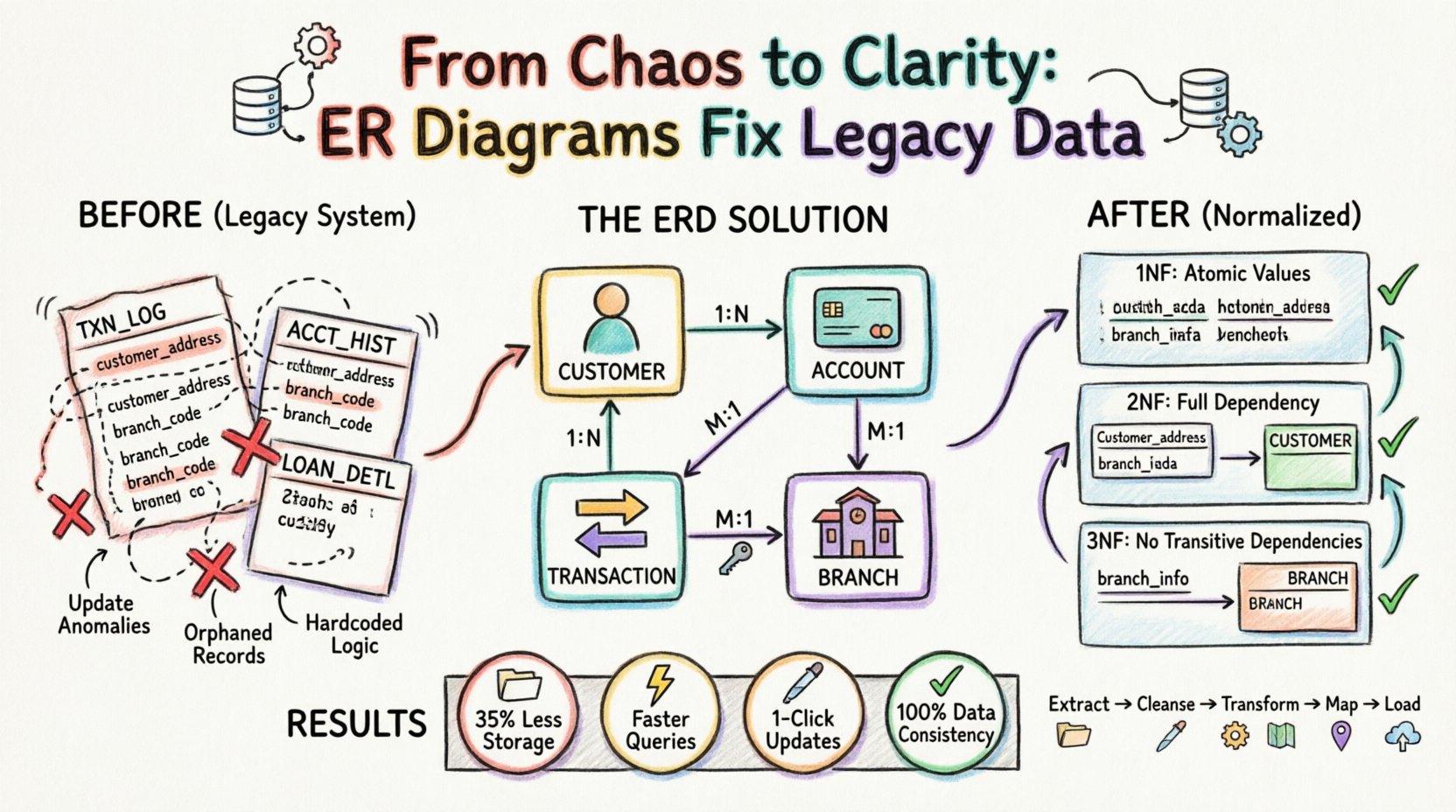
🔍 レガシーデータ構造の課題
レガシーシステムは、数十年にわたってデータ負債を蓄積することが多い。それらは当時の特定のニーズに応じて構築されたもので、長期的な保守性よりも開発スピードを優先していた。ここで分析される状況では、ソースシステムは、年月をかけて段階的に更新されてきた結果、階層的構造とフラットファイル構造が組み合わされたものであった。
レガシー状態の主な特徴には以下が含まれる:
- ハードコードされたロジック:ビジネスルールがアプリケーションコード内に直接埋め込まれており、データベースレベルでの強制は行われていなかった。
- 非正規化ストレージ:現代的なインデックスが存在しないため読み取りパフォーマンスを向上させるために、データが複数のテーブルに頻繁に重複して保存されていた。
- 参照整合性の欠如:外部キー制約がほとんど強制されておらず、孤立したレコードが増加する状態が許容されていた。
- 命名規則の不整合:識別子が大きくばらつき、自動マッピングが手動介入なしではほぼ不可能な状態であった。
このような環境は、高いリスクを生み出した。更新異常。顧客の住所が変更された場合、数十の異なるテーブルにそれぞれ更新しなければならない。すべてのインスタンスを更新しなかった場合、データの不整合が生じる。さらに、挿入異常が、既存のレコードを複製せずに新しいデータを追加することを不可能にし、削除異常関係のないレコードを削除した際に、重要な情報を失うリスクがあった。
🛠️ エンティティ関係図の役割
エンティティ関係図は単なる図面以上のものである。それはデータとそれを消費するアプリケーションとの間の論理的な契約である。このマイグレーションにおいて、ERDは唯一の真実の源として機能した。物理的実装が始まる前に、チームが関係を明確に定義し、主キーを特定し、基数ルールを設定するよう強制した。
なぜこのプロジェクトにおいてERDが重要だったのか?
- 複雑さの可視化:レガシーのデータ関係は不明瞭だった。図によって、隠れていた依存関係が明確になった。
- 正規化の強制:モデルは、チームに正規化ルールを適用させ、冗長性を体系的に排除することを要求した。
- マッピングガイド:従来のカラムを新しい正規化されたテーブルにマッピングする明確な道筋を提供した。
- ステークホルダーとのコミュニケーション:これにより、ビジネスアナリストは論理を現実のビジネスプロセスと照合することができました。
📂 ケーススタディのシナリオ:小規模銀行の統合
この分析では、メインフレーム時代のシステムからクラウドベースのリレーショナルデータベースに移行する小規模銀行を想定しています。レガシーシステムは顧客口座、取引、ローン記録を管理していました。しかし、システムの古さのため、顧客情報が取引ログ内に重複して保存されていました。
ERD分析の前:
| テーブル名 | 主キー | 重複データ | 問題点 |
|---|---|---|---|
| TXN_LOG | TXN_ID | 顧客名、住所 | 住所の変更には数千行の更新が必要です。 |
| ACCT_HIST | HIST_ID | 支店コード、支店所在地 | 支店の閉鎖によりデータの衝突が生じます。 |
| LOAN_DETL | LOAN_ID | 顧客ID、口座ID | リンクが頻繁に欠落しているか重複しています。 |
この構造はデータベース設計の基本原則を違反していました。ERDプロセスでは、これらのテーブルを原子的で独立したエンティティに分解する必要がありました。
🧩 ステップ1:エンティティと関係の特定
移行の第一段階では、レガシーシステムからすべてのテーブルとカラムを抽出しました。その後、チームはこれらを論理的エンティティにマッピングしました。目的は、ビジネスドメイン内の明確なオブジェクトを特定することでした。
- 顧客:口座を持つ独自の個人または実体。
- 口座:顧客が保有する特定の金融商品。
- 取引:口座に関連する資金の移動。
- 支店: 銀行業務が行われる実際の場所。
エンティティが定義されると、関係性が確立された。ERDから、1人の顧客が複数の口座を保有できることが明らかになった。口座は複数の取引を持つことができる。取引は特定の支店に関連している。これらの関係は通常、次のように表現される。
- 1対多(1:N): 1人の顧客に対し、複数の口座。
- 1対多(1:N): 1つの口座に対し、複数の取引。
- 多対1(M:1): 複数の取引に対し、1つの支店。
これらの接続を視覚的にマッピングすることで、チームはデータの重複が発生している場所を特定した。例えば、顧客名はTXN_LOGテーブルに存在していた。正規化されたモデルでは、取引テーブルは顧客テーブルへの参照(外部キー)のみを保持すべきであり、データそのものを保持すべきではない。
📐 ステップ2:正規化ルールの適用
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスである。ERDモデルが、チームが標準的な正規形を順に進むのをガイドした。
第1正規形(1NF)
レガシーシステムには繰り返しグループが含まれていた。例えば、レガシーカスタマーテーブルの1行に、1つの列に複数の電話番号が記録されていた(例:「555-0199, 555-0200」)。
- 問題: これにより、特定の電話番号を検索することが難しくなり、原子性を損なう。
- ERDの解決策: 別のContact_Informationエンティティを作成し、顧客エンティティと関連付ける。この新しいテーブルの各行には、正確に1つの電話番号が格納される。
第2正規形(2NF)
2NFでは、テーブルが1NFにあり、すべての非キー属性が主キーに完全関数従属していることが求められる。レガシーTXN_LOGテーブルは、TXN_IDとDATEという複合キーを持っていた。しかし、顧客の詳細情報は、顧客ID、取引日付ではなく
- 問題点:顧客データがすべての取引ごとに繰り返されており、更新異常を引き起こしていた。
- ERDの解決策: 取引テーブルから顧客詳細を削除する。それらを専用の顧客テーブルに格納し、外部キーでリンクする。
第三正規形(3NF)
3NFでは、すべての属性が主キーにのみ依存し、推移的依存がないことが求められる。レガシーシステムでは、支店名と住所が口座テーブルに格納されていたが、それらは支店IDに依存しており、口座ID.
- 問題点:支店が移転した場合、その支店に関連するすべての口座レコードを更新する必要があった。
- ERDの解決策:単独の支店テーブルを作成する。
口座テーブルは now は支店ID.
🔄 ステップ3:移行実行戦略
新しいERDが定義された後、移行計画は新しいスキーマを中心に構築された。このプロセスは単純なコピー&ペーストではなく、変換であった。
- データ抽出:元のソースシステムから生データが抽出され、ステージング領域に取り込まれました。
- クリーニング:重複レコードがERDに定義されたビジネスキーに基づいて識別され、統合されました。
- 変換:1NF、2NF、3NFのルールに従って、正規化されていないカラムを新しいテーブルに分割するスクリプトが作成されました。
- マッピング:外部キーが生成され、新しいテーブルをリンクしました。サロゲートキー(システム生成ID)が使用され、旧来のビジネスキーとは無関係に安定性を確保しました。
- ロード:参照整合性(親レコードを子レコードより先に)を尊重するため、特定の順序でデータがターゲットデータベースに挿入されました。
ERDはここでの鍵となりました。ロード順序を決定しました。たとえば、Customerテーブルは、Accountテーブルより先に、Transactionテーブルより先に、データを入力しなければなりません。他の順序でロードしようとすると、制約違反が発生します。
✅ ステップ4:検証とテスト
移行後の検証は広範囲にわたりました。構造が変更されたとしても、データの合計値が一定であることを確認することが目的でした。チームはERDを使用して、データの期待される状態を定義しました。
整合性チェック
- 参照整合性:すべての
Customer_IDがAccountテーブルに存在する場合、Customerテーブルにも存在していることを確認します。 - 完全性:変換プロセス中にレコードが失われていないことを確認します。
- 一意性:主キーが一意であり、新しいテーブルに重複が存在しないことを確認します。
比較指標
以下の指標が、ソースシステムとターゲットシステムを比較するために使用されました:
| 検証メトリクス | ターゲット標準 | 手法 |
|---|---|---|
| レコード数 | ソース数 = ターゲット数 | 正規化されたエンティティごとの行数 |
| 値の合計 | 合計残高(ソース) = 合計残高(ターゲット) | 数値フィールドの集計 |
| NULLチェック | NOT NULL列に予期しないNULLがゼロ件 | クエリ制約 |
| 重複チェック | プライマリキーに重複がゼロ件 | GROUP BY分析 |
📉 冗長性削減の影響
レガシーシステム構造から正規化されたERDモデルへの移行により、パフォーマンスおよび保守性において測定可能な改善が実現された。
- ストレージ効率: 重複する顧客住所および支店詳細を削除することで、ストレージ要件は約35%削減された。
- クエリパフォーマンス: 以前は大規模な非正規化テーブルをスキャンする必要があったクエリが、より小さなインデックス付きテーブルを結合することで高速化された。
- 更新速度: 顧客の住所を更新するには、以前はトランザクションログに数千件の更新が必要だったが、現在は顧客 テーブルで単一の行更新で済むようになった。
- データ一貫性: 同じ顧客に対して異なる住所が存在するなどのデータの衝突リスクは、単一の真実のソースを強制することで排除された。
🛡️ 異常ケースおよび履歴データの取り扱い
レガシーマイグレーションにおける最も難しい点の一つは、新しいモデルに適合しない履歴データの取り扱いである。ERDは、これらの例外をスムーズに処理する方法を定義するのに役立った。
- 孤立レコード: ソースに存在しなくなった顧客に関連付けられた取引は、警告が表示されました。チームはこれらのデータをアーカイブすることを決定しました。Historical_Legacy テーブルに保存することで、新しい関係性を損なうことなく監査証跡を維持しました。
- 欠落しているキー: 旧システムに顧客IDが存在しない場合、移行スクリプトは一時的なプレースホルダIDを生成し、該当レコードを手動レビュー用にマークしました。
- ソフト削除: 物理的にレコードを削除する代わりに、新しいスキーマには
is_activeフラグが含まれていました。これにより履歴が保持されつつ、アクティブなレポートは常に最新のデータのみを照会するよう確保されました。
🚀 スキーマの将来対応性の強化
ERDは現在の移行のために設計されたものではなく、将来の成長に対応できるように構築されました。正規化の原則に従ったことで、構造的な再設計なしに新しい機能をサポートできる柔軟なスキーマとなりました。
- スケーラビリティ: エンティティの分離により、水平スケーリングが可能になります。たとえば、Transaction テーブルは日付単位でシャーディング可能ですが、Customer テーブルには影響を与えません。
- 拡張性: 新しい製品タイプ(例:住宅ローン)を追加する場合、既存のCustomer およびAccount エンティティにリンクできるため、コアスキーマを変更せずに済みます。
- ドキュメント化: ERDは動的なドキュメントとして機能します。新規開発者は図面を確認することで、データモデルを即座に理解でき、オンボーディング時間を短縮できます。
💡 データアーキテクト向けの主な教訓
この事例は、類似の移行を実施するチームに向けたいくつかの重要な教訓を浮き彫りにしています。
- 移行前にモデル化する: 検証されたスキーマ設計がなければ、新しいシステムにデータを移行しようとしないでください。ERDが設計図です。
- 正規化して冗長性を解消する: 正規化を恐れるな。それはデータの不整合に対する主な防御手段である。
- 継続的に検証する: テストは移行のすべての段階で行われるべきであり、最終段階だけではない。
- 関係を文書化する: カーディナリティを理解する。関係が1:1か1:Nかを把握することで、データモデルにおける論理エラーを防げる。
- 履歴を保持する: 移行は現在のデータだけに関することではない。過去の整合性を保つことが目的である。
🔗 データ整合性に関する結論
レガシーシステムから現代のデータベースへの移行は、ほとんどが単純な移行・貼り付けではない。データの構成方法について根本的な見直しが必要となる。エンティティ関係図はこのプロセスにおいて最も価値のある資産であることが証明された。冗長な構造を解体し、整合性を保って再構築するための明確な視点を提供した。
即時の実装よりも論理設計を優先することで、組織は安定的でスケーラブルかつ一貫性のあるデータ環境を達成した。冗長性の削減により、運用リスクの大きな要因が排除され、将来の分析およびビジネスインテリジェンスの取り組みの堅固な基盤が築かれた。
データの冗長性は単なるストレージの問題ではない。それはビジネスリスクである。厳密なモデル化によってこれを対処することで、データが意思決定の信頼できる資産のまま保たれ、進捗を妨げる負債にならないことが保証される。

