











W świecie architektury danych nieliczne wyzwania są tak trwałe jak problem nadmiarowości danych w systemach dziedziczonej. Gdy organizacje starają się zmodernizować swoją infrastrukturę, ogromna ilość powielonych, niezgodnych i nieprzypisanych danych często staje się głównym węzłem zastojowym. To studium przypadku analizuje rzeczywisty scenariusz, w którym szczegółowy diagram związków encji (ERD) pełnił rolę projektu do rozwiązywania krytycznych problemów integralności danych podczas dużego projektu migracji.
Cel był jasny: przejście od fragmentowanego środowiska dziedziczonego opartego na plikach tekstowych do solidnej bazy danych relacyjnej bez utraty wierności danych ani wprowadzania nowych niezgodności. Rozwiązanie nie tkwiło w narzędziu migracji, lecz w wizualnym modelowaniu i logicznym ustrukturalizowaniu danych przed przesłaniem jednego bajtu. Przeglądamy metodologię, konkretne wyzwania związane z normalizacją oraz rzeczywiste rezultaty dyscyplinarnego podejścia do projektowania schematu.
🔍 Wybór struktur danych dziedziczonej
Systemy dziedziczone często gromadzą dług danych na przestrzeni dekad. Zbudowane były z myślą o specyficznych potrzebach swoich czasów, z uwzględnieniem szybkości rozwoju zamiast długoterminowej utrzymywalności. W analizowanym tutaj scenariuszu system źródłowy wykorzystywał połączenie struktur hierarchicznych i plików tekstowych, które zostały stopniowo sklejone w ciągu wielu lat iteracyjnych aktualizacji.
Kluczowe cechy stanu dziedziczonego obejmowały:
- Zakodowana logika:Zasady biznesowe były bezpośrednio wbudowane w kod aplikacji, a nie wymuszane na poziomie bazy danych.
- Nienormalizowane przechowywanie:Aby poprawić wydajność odczytu w braku nowoczesnego indeksowania, dane były często powielane w wielu tabelach.
- Brak integralności referencyjnej:Ograniczenia kluczy obcych rzadko były wymuszane, co pozwalało na rozprzestrzenianie się nieprzypisanych rekordów.
- Niezgodne konwencje nazewnictwa:Identyfikatory różniły się znacznie, co sprawiało, że automatyczne mapowanie było prawie niemożliwe bez interwencji ręcznej.
Takie środowisko stwarzało wysokie ryzyko anomalii aktualizacji. Jeśli adres klienta ulegał zmianie, musiał zostać zaktualizowany w dziesiątkach różnych tabel. Niepowodzenie aktualizacji każdego wystąpienia prowadziło do niezgodności danych. Ponadto, anomalii wstawiania uniemożliwiało dodawanie nowych danych bez powielania istniejących rekordów, a także anomalii usuwaniapogwałcało ryzyko utraty istotnych informacji, gdy usuwano niepowiązane rekordy.
🛠️ Rola diagramu encji i relacji
Diagram encji i relacji to więcej niż tylko rysunek; jest to kontrakt logiczny między danymi a aplikacjami, które ich używają. W tej migracji ERD pełnił rolę jedynego źródła prawdy. Zmuszał zespół do jasnego zdefiniowania relacji, identyfikacji kluczy głównych oraz ustalenia reguł liczności przed rozpoczęciem implementacji fizycznej.
Dlaczego ERD był kluczowy dla tego konkretnego projektu?
- Wizualizacja złożoności:Relacje danych w systemie dziedziczonej były nieprzezroczyste. Diagram ujawnił ukryte zależności.
- Wymuszanie normalizacji:Model wymagał od zespołu zastosowania reguł normalizacji w celu systematycznego eliminowania nadmiarowości.
- Przewodnik mapowania:Zapewnił jasny sposób mapowania kolumn dziedziczonej na nowe, normalizowane tabele.
- Komunikacja z zainteresowanymi stronami: Pozwoliło analitykom biznesowym zweryfikować logikę w stosunku do rzeczywistych procesów biznesowych.
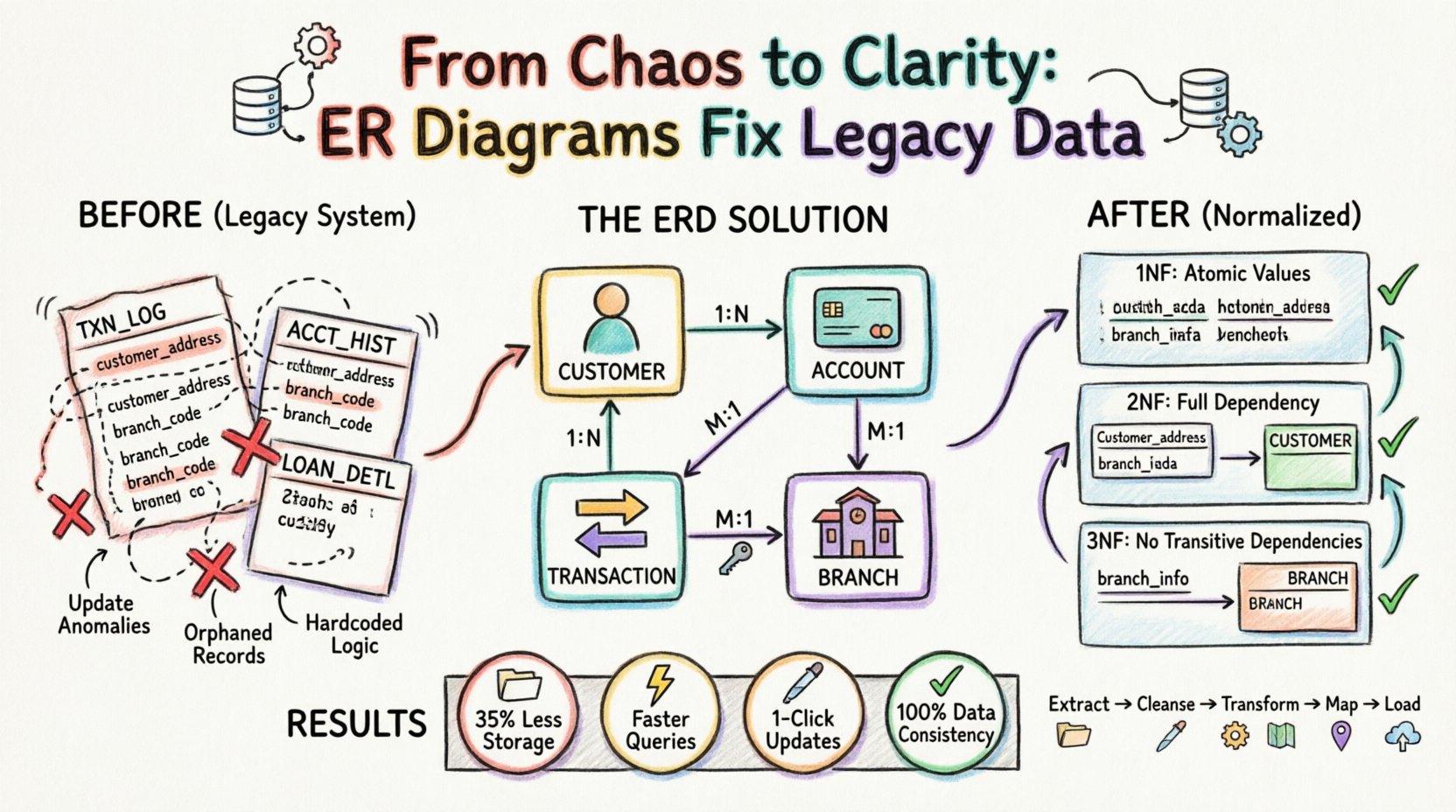
📂 Przypadek badawczy: Konsolidacja bankowości detalicznej
W ramach tej analizy rozważamy instytucję bankowości detalicznej przechodzącą z systemu erze mainframe’a do relacyjnej bazy danych opartej na chmurze. System dziedziczony zarządzał kontami klientów, transakcjami i rekordami kredytów. Jednak ze względu na wiek systemu informacje o klientach były przechowywane redundantnie w dziennikach transakcji.
Przed analizą ERD:
| Nazwa tabeli | Klucz podstawowy | Dane redundantne | Problem |
|---|---|---|---|
| DZIENNIK_TRANS | ID_TRANS | Imię i nazwisko klienta, Adres | Zmiany adresu wymagają aktualizacji tysięcy wierszy. |
| HIST_KONTA | ID_HIST | Kod oddziału, Lokalizacja oddziału | Zamknięcie oddziału prowadzi do konfliktów danych. |
| SZCZEGÓŁY_KREDYTU | ID_KREDYTU | ID klienta, ID konta | Połączenia często brakują lub są powielone. |
Ta struktura naruszała podstawowe zasady projektowania baz danych. Proces ERD wymagał rozbicia tych tabel na atomowe, niezależne jednostki.
🧩 Krok 1: Identyfikacja encji i relacji
Pierwsza faza migracji polegała na wyodrębnieniu każdej tabeli i kolumny z systemu dziedziczonego. Zespół następnie przypisał je do jednostek logicznych. Celem było zidentyfikowanie odrębnych obiektów w dziedzinie biznesowej.
- Klient: Unikalna osoba lub jednostka posiadająca konto.
- Konto: Pewien produkt finansowy posiadany przez klienta.
- Transakcja: Przepływ środków związany z kontem.
- Oddział: Fizyczne miejsce, w którym odbywają się operacje bankowe.
Po zdefiniowaniu encji ustalono relacje. Diagram ERD ujawnił, że jeden Klient może posiadać wiele Kont. Konto może mieć wiele Transakcji. Transakcja była powiązana z konkretnym Oddziałem. Te relacje zwykle przedstawia się jako:
- Jeden do wielu (1:N): Jeden Klient do wielu Kont.
- Jeden do wielu (1:N): Jedno Konto do wielu Transakcji.
- Wiele do jednego (M:1): Wiele Transakcji do jednego Oddziału.
Poprzez wizualne odwzorowanie tych połączeń zespół wykrył, gdzie dane były powielane. Na przykład, Imię Klienta pojawiało się w tabeliTXN_LOG tabela. W modelu znormalizowanym tabela transakcji powinna zawierać tylko odniesienie (klucz obcy) do tabeli Klienta, a nie same dane.
📐 Krok 2: Stosowanie reguł normalizacji
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Model ERD prowadził zespół przez standardowe formy normalne.
Pierwsza forma normalna (1NF)
Stary system zawierał powtarzające się grupy. Na przykład, pojedynczy wiersz w tabeli klientów z systemu dziedziczonego mógł zawierać wiele numerów telefonów w jednym polu (np. „555-0199, 555-0200”).
- Problem: Sprawia to, że wyszukiwanie konkretnego numeru telefonu jest trudne i narusza atomowość.
- Rozwiązanie ERD: Utwórz osobnąContact_Information encję powiązaną z encją Klienta. Każdy wiersz w tej nowej tabeli zawiera dokładnie jeden numer telefonu.
Druga forma normalna (2NF)
2NF wymaga, aby tabela była w 1NF oraz aby wszystkie atrybuty niekluczowe były całkowicie zależne od klucza głównego. Tabela z systemu dziedziczonegoTXN_LOG miała klucz złożony zTXN_ID iDATA. Jednak dane dotyczące klienta zależały wyłącznie odID_Klienta, a nie data transakcji.
- Problem: Dane klienta były powtarzane dla każdej transakcji, co powodowało anomalie aktualizacji.
- Rozwiązanie ERD: Usuń szczegóły klienta z tabeli transakcji. Przechowuj je w odrębnejKlient tabeli i łączy je za pomocą klucza obcego.
Trzecia postać normalna (3NF)
3NF wymaga, aby wszystkie atrybuty były zależne wyłącznie od klucza głównego, bez zależności przechodnich. W systemie dziedzicznymOddział nazwa i adres były przechowywane w tabeliKonto tabela, ale zależały odID_Oddziału, a nie odID_Konta.
- Problem: Jeśli oddział zmienił lokalizację, wszystkie rekordy kont powiązanych z tym oddziałem wymagały aktualizacji.
- Rozwiązanie ERD: Utwórz odrębnąOddział tabelę. Tabela
Kontoteraz zawiera tylkoID_Oddziału.
🔄 Krok 3: Strategia wykonywania migracji
Po zdefiniowaniu nowego ERD plan migracji został sformułowany wokół nowego schematu. Proces nie był prostym kopiowaniem i wklejaniem; był przekształceniem.
- Wyodrębnianie danych:Dane surowe zostały pobrane z systemów źródłowych z poprzednich wersji do obszaru tymczasowego.
- Czyszczenie:Zduplikowane rekordy zostały zidentyfikowane i połączone na podstawie kluczy biznesowych zdefiniowanych w ERD.
- Przekształcanie:Napisano skrypty do podziału kolumn znormalizowanych na nowe tabele zgodnie z zasadami 1NF, 2NF i 3NF.
- Mapowanie:Zostały wygenerowane klucze obce w celu połączenia nowych tabel. Klucze zastępcze (identyfikatory generowane przez system) zostały użyte w celu zapewnienia stabilności niezależnie od kluczy biznesowych z poprzednich wersji.
- Wgrywanie:Dane zostały wstawione do bazy danych docelowej w określonej kolejności, aby zachować integralność referencyjną (rodzice przed dziećmi).
ERD było tutaj kluczowe. Określało kolejność wgrywania. Na przykład tabelaKlientmusiała zostać wypełniona przedKontoktóra musiała zostać wypełniona przedTransakcjatabelą. Próba załadowania w innej kolejności spowodowałaby naruszenie ograniczeń.
✅ Krok 4: Weryfikacja i testowanie
Weryfikacja po migracji była szczegółowa. Celem było zapewnienie, że suma danych pozostaje stała, mimo zmiany struktury. Zespół wykorzystał ERD do określenia oczekiwanego stanu danych.
Sprawdzanie integralności
- Integralność referencyjna:Upewnij się, że każdy
Customer_IDw tabeli Konto istnieje w tabeli Klient. - Pełność:Upewnij się, że żaden rekord nie został utracony podczas procesu przekształcania.
- Unikalność:Potwierdź, że klucze główne są unikalne i nie ma duplikatów w nowych tabelach.
Metryki porównawcze
Następujące metryki zostały użyte do porównania systemów źródłowych i docelowych:
| Metryka walidacji | Standard docelowy | Metoda |
|---|---|---|
| Liczba rekordów | Liczba źródeł = Liczba docelowa | Liczba wierszy na znormalizowaną jednostkę |
| Suma wartości | Całkowity stan źródła = Całkowity stan docelowy | Agregacja pól numerycznych |
| Sprawdzanie wartości NULL | Zerowe nieoczekiwane wartości NULL w kolumnach NOT NULL | Ograniczenia zapytań |
| Sprawdzanie duplikatów | Zerowe duplikaty w kluczach głównych | Analiza GROUP BY |
📉 Wpływ redukcji nadmiarowości
Przejście od struktury dziedzicznej do znormalizowanego modelu ERD przyniosło mierzalne poprawy w wydajności i utrzymaniu.
- Efektywność przechowywania: Usunięcie powtarzających się adresów klientów i szczegółów oddziałów spowodowało zmniejszenie wymagań przechowywania o około 35%.
- Wydajność zapytań: Zapytania, które wcześniej wymagały przeszukiwania dużych, nieznormalizowanych tabel, stały się szybsze dzięki łączeniu mniejszych, indeksowanych tabel.
- Szybkość aktualizacji: Aktualizacja adresu klienta wymaga teraz jednego aktualizowania wiersza w tabeli Klient tabeli, zamiast tysięcy aktualizacji w dziennikach transakcji.
- Spójność danych: Ryzyko sprzecznych danych (np. dwa różne adresy dla tego samego klienta) zostało usunięte poprzez wprowadzenie jednego źródła prawdy.
🛡️ Obsługa przypadków granicznych i danych historycznych
Jednym z najtrudniejszych aspektów migracji z systemu dziedziczonego jest obsługa danych historycznych, które nie mieszczą się w nowym modelu. Model ERD pomógł określić sposób łagodnej obsługi tych wyjątków.
- Zamordowane rekordy: Transakcje powiązane z klientami, którzy już nie istniejący w źródle, zostały oznaczone. Zespół zdecydował się archiwizować je w Historical_Legacy tabeli w celu zachowania śladów audytowych bez naruszania nowych relacji.
- Brakujące klucze: W przypadkach, gdy identyfikator klienta brakował w systemie dziedzicznym, skrypt migracji wygenerował tymczasowy identyfikator zastępczy i oznaczył rekord do ręcznej analizy.
- Miękkie usuwanie: Zamiast fizycznie usuwać rekordy, nowa struktura zawierała flagę
is_activeflagę. Zapewniło to zachowanie historii, jednocześnie gwarantując, że aktywne raporty pobierały tylko aktualne dane.
🚀 Przyszłościowe zabezpieczenie schematu
ERD nie został zaprojektowany wyłącznie dla obecnej migracji; został stworzony w celu dopasowania się do przyszłego rozwoju. Przestrzeganie zasad normalizacji sprawiło, że schemat stał się wystarczająco elastyczny, aby wspierać nowe funkcje bez konieczności zmian strukturalnych.
- Skalowalność: Oddzielenie encji umożliwia skalowanie poziome. Na przykład tabela Transaction może być podzielona według daty bez wpływu na tabelę Customer tabeli.
- Rozszerzalność: Jeśli zostanie dodany nowy typ produktu (np. kredyt hipoteczny), może być powiązany z istniejącymi encjami Customer i Account encji bez zmiany podstawowego schematu.
- Dokumentacja: ERD pełni rolę żywej dokumentacji. Nowi programiści mogą natychmiast zrozumieć model danych, przeglądając diagram, co skraca czas wdrażania.
💡 Kluczowe wnioski dla architektów danych
Ten przypadek pokazuje kilka istotnych lekcji dla zespołów prowadzących podobne migracje.
- Modeluj przed migracją: Nigdy nie próbuj przenieść danych do nowego systemu bez zwalidowanego projektu schematu. ERD to projekt.
- Normalizuj, aby rozwiązać nadmiarowość:Nie bój się normalizacji. Jest to podstawowa obrona przed niezgodnością danych.
- Weryfikuj ciągle:Testowanie powinno odbywać się na każdym etapie migracji, a nie tylko na końcu.
- Dokumentuj relacje:Zrozum hierarchię. Znając rodzaj relacji – czy jest to 1:1 czy 1:N – unikniesz błędów logicznych w modelu danych.
- Zachowaj historię:Migracja to nie tylko o danych obecnych; chodzi o zachowanie integralności przeszłości.
🔗 Wnioski dotyczące integralności danych
Przejście od systemu dziedziczonego do nowoczesnej bazy danych rzadko jest prostym przesunięciem. Wymaga fundamentalnego przemyślenia sposobu organizacji danych. Diagram relacji encji okazał się najcenniejszym środkiem w tym procesie. Zapewnił jasność potrzebną do rozbicia nadmiarowych struktur i ich ponownego zbudowania z zachowaniem integralności.
Poprzez priorytet nadaniem projektowania logicznego przed natychmiastową implementacją organizacja osiągnęła stabilne, skalowalne i spójne środowisko danych. Zmniejszenie nadmiarowości usunęło istotny źródło ryzyka operacyjnego i stworzyło solidną podstawę dla przyszłych inicjatyw analizy danych i inteligencji biznesowej.
Nadmiarowość danych to nie tylko problem przechowywania; to ryzyko dla biznesu. Przeciwdziałanie jej poprzez szczegółowe modelowanie gwarantuje, że dane pozostaną wiarygodnym aktywem wspierającym podejmowanie decyzji, a nie obciążeniem hamującym postęp.

