











В мире архитектуры данных немногие проблемы столь же устойчивы, как избыточность данных в устаревших системах. По мере того как организации стремятся модернизировать свою инфраструктуру, огромный объем дублирующихся, несогласованных и несвязанных данных часто становится основным узким местом. В этом кейс-стади рассматривается реальный сценарий, в котором подробная диаграмма сущность-связь (ERD) послужила чертежом для решения критических проблем целостности данных во время крупного проекта миграции.
Цель была ясной: перейти от фрагментированной устаревшей среды на основе плоских файлов к надежной реляционной базе данных без потери целостности данных или введения новых несогласованностей. Решение заключалось не в самом инструменте миграции, а в визуальном моделировании и логической структуризации данных до перемещения даже одного байта. Мы исследуем методологию, конкретные вызовы, связанные с нормализацией, и ощутимые результаты дисциплинированного подхода к проектированию схемы.
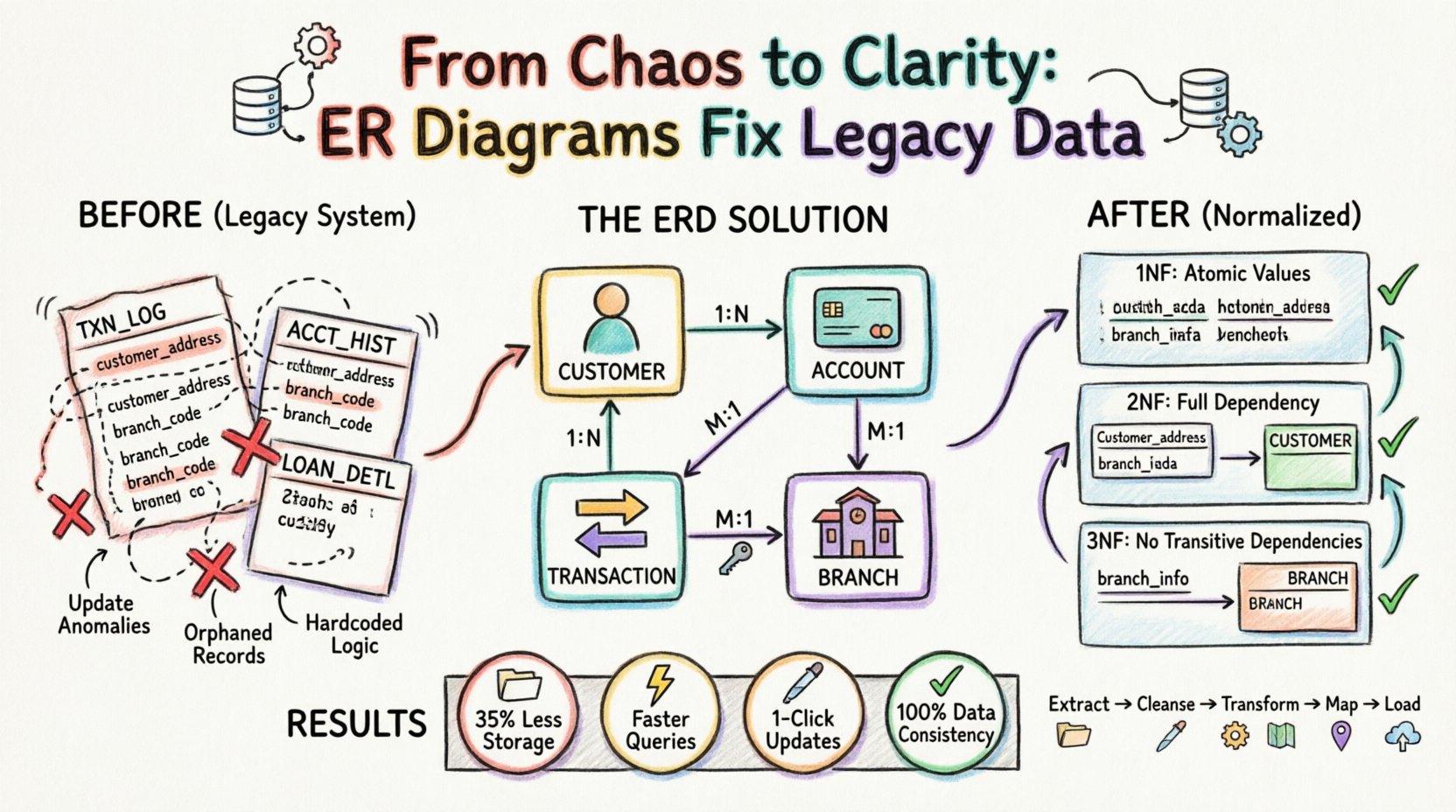
🔍 Проблема структур устаревших данных
Устаревшие системы часто накапливают долг по данным на протяжении десятилетий. Они создавались с учетом конкретных потребностей своего времени, ставя скорость разработки выше долгосрочной поддерживаемости. В анализируемом здесь сценарии исходная система использовала комбинацию иерархических и плоских файловых структур, которые были склеены за годы постепенных обновлений.
Ключевые особенности устаревшего состояния включали:
- Жестко закодированная логика:Бизнес-правила были непосредственно встроены в код приложения, а не обеспечивались на уровне базы данных.
- Ненормализованное хранение: Для повышения производительности чтения в отсутствие современных индексов данные часто дублировались в нескольких таблицах.
- Отсутствие ссылочной целостности: Ограничения внешних ключей редко применялись, что позволяло множиться несвязанным записям.
- Несогласованные соглашения об именовании: Идентификаторы сильно различались, что делало автоматическое сопоставление почти невозможным без ручного вмешательства.
Такая среда создавала высокую вероятность аномалий обновления. Если изменялся адрес клиента, его нужно было обновить в десятках разных таблиц. Неудача обновить каждую запись приводила к несогласованности данных. Более того, аномалий вставки мешала добавлению новых данных без дублирования существующих записей, а также аномалий удаления создавала риск потери важной информации при удалении несвязанных записей.
🛠️ Роль диаграммы сущность-связь
Диаграмма сущность-связь — это не просто рисунок; это логическое соглашение между данными и приложениями, которые их используют. В рамках этой миграции ERD выступила единственным источником истины. Она заставила команду явно определить отношения, выявить первичные ключи и установить правила кардинальности до начала физической реализации.
Почему ERD была критически важна для этого конкретного проекта?
- Визуализация сложности: Связи данных в устаревшей системе были неясными. Диаграмма сделала скрытые зависимости видимыми.
- Принудительная нормализация: Модель обязывала команду применять правила нормализации для систематического устранения избыточности.
- Руководство по сопоставлению: Она предоставила четкий путь для сопоставления столбцов устаревших таблиц с новыми нормализованными таблицами.
- Связь со заинтересованными сторонами:Это позволило бизнес-аналитикам проверить логику на соответствие реальным бизнес-процессам.
📂 Сценарий кейса: Консолидация розничного банкинга
Для этого анализа мы рассматриваем розничный банк, переходящий от системы эпохи мейнфреймов к облачной реляционной базе данных. Устаревшая система управляла клиентскими счетами, операциями и записями по кредитам. Однако из-за возраста системы информация о клиентах хранится избыточно в журналах операций.
До анализа ERD:
| Имя таблицы | Первичный ключ | Избыточные данные | Проблема |
|---|---|---|---|
| ЖУРНАЛ_ОПЕРАЦИЙ | ID_ОПЕРАЦИИ | Имя клиента, Адрес | Изменение адреса требует обновления тысяч строк. |
| ИСТОРИЯ_СЧЕТА | ID_ИСТОРИИ | Код филиала, Местоположение филиала | Закрытие филиалов приводит к конфликтам данных. |
| ДЕТАЛИ_КРЕДИТА | ID_КРЕДИТА | ID клиента, ID счета | Ссылки часто отсутствуют или дублируются. |
Эта структура нарушала фундаментальные принципы проектирования баз данных. Процесс ERD потребовал разбить эти таблицы на атомарные, независимые сущности.
🧩 Шаг 1: Определение сущностей и связей
Первая фаза миграции включала извлечение каждой таблицы и столбца из устаревшей системы. Затем команда сопоставила их логическим сущностям. Целью было выявить отдельные объекты в бизнес-области.
- Клиент: Уникальное лицо или юридическое лицо, владеющее счетом.
- Счет: Конкретный финансовый продукт, находящийся на счете клиента.
- Операция: Перемещение средств, связанное со счетом.
- Филиал: Физическое место, где происходят банковские операции.
После определения сущностей были установлены связи. Диаграмма ER показала, что один клиент может иметь несколько счетов. Счет может иметь несколько транзакций. Транзакция была связана с конкретным филиалом. Эти отношения обычно представляются следующим образом:
- Один ко многим (1:N): Один клиент к нескольким счетам.
- Один ко многим (1:N): Один счет к нескольким транзакциям.
- Многие к одному (M:1): Множество транзакций к одному филиалу.
Визуально отобразив эти связи, команда определила, где происходит дублирование данных. Например, имя клиента присутствовало в таблицеTXN_LOG таблице. В нормализованной модели таблица транзакций должна содержать только ссылку (внешний ключ) на таблицу клиентов, а не сами данные.
📐 Шаг 2: Применение правил нормализации
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Диаграмма ER направляла команду через стандартные нормальные формы.
Первая нормальная форма (1NF)
Устаревшая система содержала повторяющиеся группы. Например, одна строка в устаревшей таблице клиентов могла содержать несколько номеров телефонов в одном столбце (например, «555-0199, 555-0200»).
- Проблема: Это затрудняет поиск конкретного номера телефона и нарушает атомарность.
- Решение с помощью диаграммы ER: Создайте отдельнуюContact_Information сущность, связанную с сущностью Клиент. Каждая строка в этой новой таблице содержит ровно один номер телефона.
Вторая нормальная форма (2NF)
2NF требует, чтобы таблица находилась в 1NF, и чтобы все атрибуты, не являющиеся ключевыми, полностью зависели от первичного ключа. УстаревшаяTXN_LOG таблица имела составной ключ изTXN_ID иDATE. Однако данные о клиенте зависели только отCustomer_ID, а не дата транзакции.
- Проблема:Данные клиента повторялись для каждой транзакции, что приводило к аномалиям обновления.
- Решение ERD: Удалите данные клиента из таблицы транзакций. Храните их в отдельной Customer таблице и свяжите их с помощью внешнего ключа.
Третья нормальная форма (3NF)
3NF требует, чтобы все атрибуты зависели только от первичного ключа, без транзитивных зависимостей. В устаревшей системе имя и адрес филиала хранились в таблице Branch имя и адрес хранились в таблице Account таблице, но они зависели от Branch_ID, а не от Account_ID.
- Проблема: Если филиал перемещался, необходимо было обновить каждую запись счета, связанную с этим филиалом.
- Решение ERD: Создайте отдельную Branch таблицу. Таблица
Accountтеперь хранит толькоBranch_ID.
🔄 Шаг 3: Стратегия выполнения миграции
После определения новой ERD план миграции был структурирован вокруг новой схемы. Процесс не был простым копированием и вставкой; это была трансформация.
- Извлечение данных:Необработанные данные были извлечены из устаревших систем источников в промежуточную зону.
- Очистка:Дублирующиеся записи были идентифицированы и объединены на основе бизнес-ключей, определенных в ERD.
- Преобразование:Были написаны скрипты для разделения денормализованных столбцов на новые таблицы в соответствии с правилами 1НФ, 2НФ и 3НФ.
- Сопоставление:Были сгенерированы внешние ключи для связи новых таблиц. Суррогатные ключи (идентификаторы, генерируемые системой) использовались для обеспечения стабильности независимо от устаревших бизнес-ключей.
- Загрузка:Данные были вставлены в целевую базу данных в определённом порядке для соблюдения целостности ссылок (родители до детей).
ERD был здесь критически важен. Он определял порядок загрузки. Например, таблица Клиент должна была быть заполнена до таблицы Счёт, которая, в свою очередь, должна была быть заполнена до таблицы Транзакция таблицы. Попытка загрузки в любом другом порядке привела бы к нарушению ограничений.
✅ Шаг 4: Проверка и тестирование
Постмиграционная проверка была обширной. Целью было обеспечить, чтобы сумма данных оставалась неизменной, несмотря на изменения структуры. Команда использовала ERD для определения ожидаемого состояния данных.
Проверки целостности
- Целостность ссылок: Убедитесь, что каждый
Customer_IDв таблице Счёт существует в таблице Клиент. - Полнота: Убедитесь, что во время процесса преобразования не было утеряно никаких записей.
- Уникальность: Подтвердите, что первичные ключи уникальны и в новых таблицах нет дубликатов.
Метрики сравнения
Были использованы следующие метрики для сравнения исходной и целевой систем:
| Метрика проверки | Целевой стандарт | Метод |
|---|---|---|
| Количество записей | Количество источников = Количество целей | Количество строк на нормализованную сущность |
| Сумма значений | Общий баланс источника = Общий баланс цели | Агрегирование числовых полей |
| Проверка на пустые значения | Нулевых неожиданных значений NULL в столбцах NOT NULL | Ограничения запросов |
| Проверка дубликатов | Нулевые дубликаты в первичных ключах | Анализ по GROUP BY |
📉 Влияние сокращения избыточности
Переход от устаревшей структуры к нормализованной модели ERD принес измеримые улучшения в производительности и обслуживании.
- Эффективность хранения: Удаление дублирующихся адресов клиентов и сведений о филиалах привело к сокращению потребностей в хранилище примерно на 35%.
- Производительность запросов: Запросы, которые ранее требовали сканирования больших, денормализованных таблиц, стали быстрее за счет объединения меньших, индексированных таблиц.
- Скорость обновления: Обновление адреса клиента теперь требует одного обновления строки в таблице Клиент таблице, а не тысяч обновлений по журналам транзакций.
- Согласованность данных: Риск противоречивых данных (например, два разных адреса для одного и того же клиента) был устранён за счёт обеспечения единого источника истины.
🛡️ Обработка крайних случаев и исторических данных
Одной из самых сложных задач при миграции с устаревшей системы является обработка исторических данных, которые не соответствуют новой модели. Модель ERD помогла определить, как грамотно обрабатывать такие исключения.
- Заброшенные записи: Транзакции, связанные с клиентами, которые больше не существовали в исходной системе, были отмечены. Команда решила архивировать их в Исторический_наследие таблице, чтобы сохранить следы аудита, не нарушая новых связей.
- Отсутствующие ключи: В случаях, когда идентификатор клиента отсутствовал в унаследованной системе, скрипт миграции сгенерировал временный идентификатор-заглушку и пометил запись для ручного обзора.
- Мягкое удаление: Вместо физического удаления записей новая схема включала
is_activeфлаг. Это сохранило историю, одновременно обеспечивая, что активные отчеты извлекали только текущие данные.
🚀 Защита схемы от будущих изменений
ERD не был разработан исключительно для текущей миграции; он был создан для поддержки будущего роста. Соблюдение принципов нормализации сделало схему достаточно гибкой, чтобы поддерживать новые функции без структурной переработки.
- Масштабируемость: Разделение сущностей позволяет горизонтальное масштабирование. Например, таблица Transaction может быть разделена по дате без влияния на таблицу Customer таблицу.
- Расширяемость: Если добавляется новый тип продукта (например, ипотека), он может быть связан с существующими сущностями Customer и Account сущностями без изменения основной схемы.
- Документация: ERD служит живой документацией. Новые разработчики могут сразу понять модель данных, изучив диаграмму, что сокращает время адаптации.
💡 Ключевые выводы для архитекторов данных
Этот кейс-стади подчеркивает несколько важных уроков для команд, занимающихся подобными миграциями.
- Моделируйте до миграции: Никогда не пытайтесь перенести данные в новую систему без проверенной схемы. ERD — это чертеж.
- Нормализуйте для решения избыточности: Не бойтесь нормализации. Это основная защита от несогласованности данных.
- Проверяйте непрерывно: Тестирование должно проводиться на каждом этапе миграции, а не только в конце.
- Документируйте отношения: Поймите кардинальность. Знание того, является ли отношение 1:1 или 1:N, предотвращает логические ошибки в модели данных.
- Сохраняйте историю: Миграция — это не только текущие данные; это сохранение целостности прошлого.
🔗 Заключение по целостности данных
Переход от устаревшей системы к современной базе данных редко является простой операцией переноса. Это требует фундаментального переосмысления организации данных. Диаграмма сущность-связь оказалась наиболее ценным активом в этом процессе. Она обеспечила необходимую ясность для разборки избыточных структур и их повторной сборки с соблюдением целостности.
Приоритизация логического проектирования перед немедленной реализацией позволила организации создать стабильную, масштабируемую и согласованную среду данных. Снижение избыточности устранило значительный источник операционных рисков и заложило прочную основу для будущих инициатив аналитики и бизнес-интеллекта.
Избыточность данных — это не просто проблема хранения; это бизнес-риск. Устранение этой проблемы с помощью строгого моделирования гарантирует, что данные остаются надежным активом для принятия решений, а не обременением, которое тормозит прогресс.

