








डेटा प्रत्येक डिजिटल प्रणाली की रीढ़ है, जैसे सरल वेब एप्लिकेशन से लेकर जटिल एंटरप्राइज रिसोर्स प्लानिंग प्लेटफॉर्म तक। इस सूचना को संगठित करने के एक संरचित दृष्टिकोण के बिना, प्रणालियाँ नाजुक, धीमी और रखरखाव में कठिन हो जाती हैं। यहीं पर एंटिटी-रिलेशनशिप डायग्राम, जिसे सामान्यतः ERD कहा जाता है, महत्वपूर्ण हो जाता है। यह डेटाबेस डिजाइन के लिए आधारभूत नक्शा के रूप में कार्य करता है, जो अमूर्त व्यापार आवश्यकताओं को एक ठोस तकनीकी संरचना में बदलता है।
यह मार्गदर्शिका ER मॉडलिंग के तंत्र, डेटा अखंडता के नियमों और स्केलेबल आर्किटेक्चर बनाने के लिए आवश्यक रणनीतियों का अध्ययन करती है। एंटिटीज, संबंधों और नॉर्मलाइजेशन के मूल सिद्धांतों को समझकर, डिजाइनर यह सुनिश्चित कर सकते हैं कि उनकी डेटा परत समय के साथ भी मजबूत और कुशल बनी रहे।
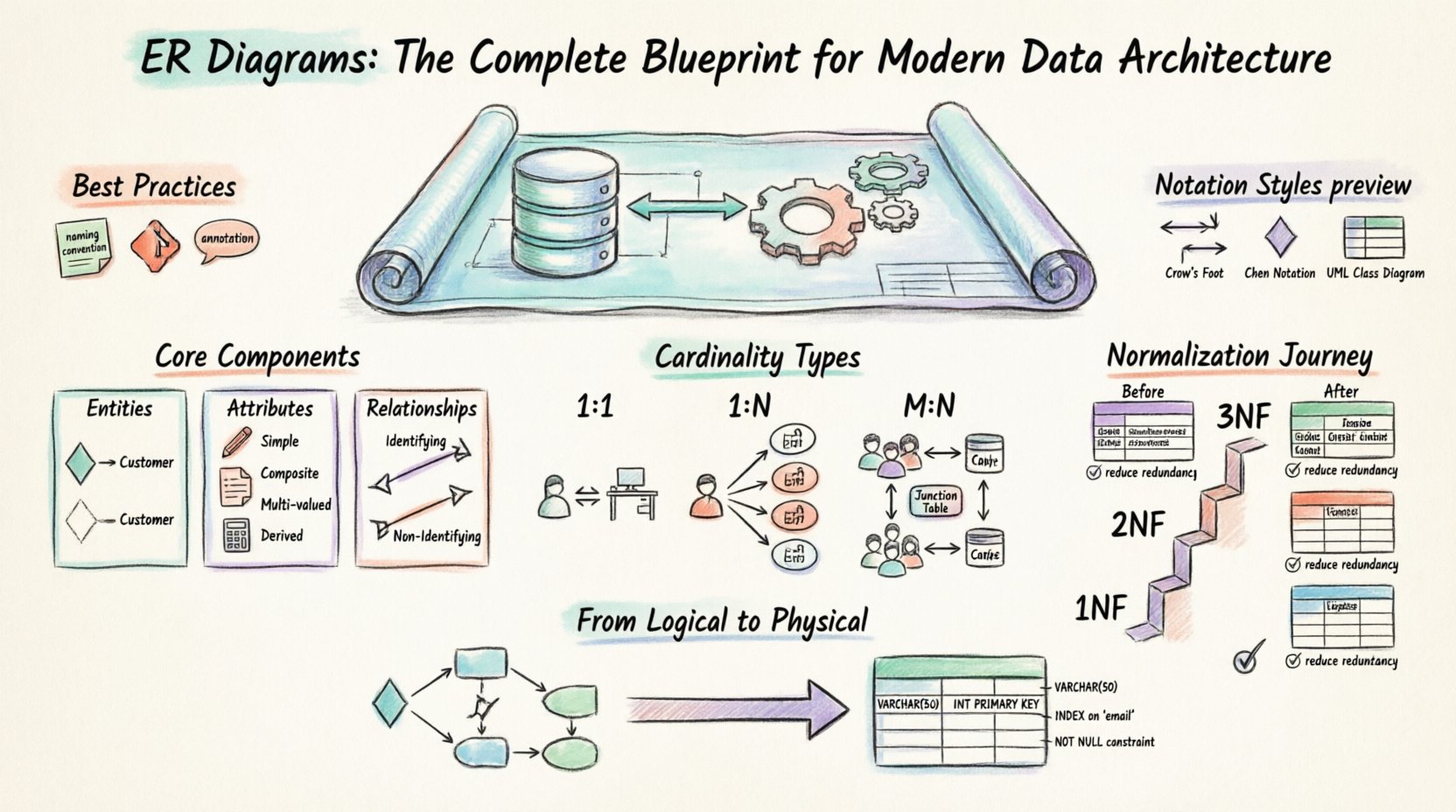
🔍 एक एंटिटी-रिलेशनशिप डायग्राम क्या है?
एक एंटिटी-रिलेशनशिप डायग्राम डेटा संरचनाओं और उनके बीच संबंधों का दृश्य प्रतिनिधित्व है। यह डेटाबेस विकास के डिजाइन चरण के दौरान उपयोग किए जाने वाला एक अवधारणात्मक उपकरण है। डिस्क ब्लॉक या मेमोरी पतों जैसे भौतिक स्टोरेज मैकेनिज्म पर ध्यान केंद्रित करने के बजाय, ERD डेटा के तार्किक संगठन पर ध्यान केंद्रित करता है।
इसे एक घर के आर्किटेक्चरल ब्लूप्रिंट के रूप में सोचें। कंक्रीट डालने या ईंटें रखने से पहले, एक आर्किटेक्ट एक योजना बनाता है जिसमें दीवारों के स्थान, दरवाजों के कमरों से जुड़ने के स्थान और उपयोगिताओं के प्रवाह को दिखाया जाता है। इसी तरह, ERD यह दिखाता है कि डेटा कहाँ रहता है, यह कैसे जुड़ता है और एप्लिकेशन के माध्यम से यह कैसे प्रवाहित होता है।
ER मॉडलिंग के मुख्य उद्देश्य
- संचार:यह तकनीकी टीमों और व्यापार स्टेकहोल्डर्स के बीच के अंतर को पार करता है। दृश्य आरेख अनस्ट्रक्चर्ड कोड या SQL स्क्रिप्ट्स की तुलना में आसानी से समझे जाते हैं।
- योजना बनाना:यह अनुप्रयोग शुरू होने से पहले संभावित समस्याओं को पहचानता है। डिजाइन की त्रुटियाँ कागज पर ठीक करने में उत्पादन में ठीक करने की तुलना में सस्ती होती हैं।
- दस्तावेजीकरण:यह भविष्य के डेवलपर्स के लिए एक संदर्भ के रूप में कार्य करता है, जो डेटा की संरचना और संबंधों को समझाता है।
- अनुकूलन:यह अतिरिक्तता और अकुशलताओं को उजागर करता है जो धीमी क्वेरी प्रदर्शन की ओर जा सकती हैं।
🏗️ ERD के मुख्य घटक
एक वैध आरेख बनाने के लिए, तीन मूल निर्माण तत्वों को समझना आवश्यक है। डेटाबेस में प्रत्येक संबंध और प्रतिबंध इन तत्वों के बीच बातचीत से उत्पन्न होता है।
1. एंटिटीज
एक एंटिटी व्यापार क्षेत्र में एक अलग वस्तु या अवधारणा का प्रतिनिधित्व करती है। डेटाबेस संदर्भ में, एक एंटिटी आमतौर पर एक टेबल से मैप होती है। एंटिटीज हो सकती हैं:
- स्ट्रॉन्ग एंटिटीज: ये स्वतंत्र रूप से अस्तित्व में होती हैं और उनका अपना प्राथमिक कुंजी होता है। उदाहरण के लिए, एक ग्राहक एंटिटी एक जुड़े हुए आदेश.
- दुर्बल एंटिटीज: ये अपने अस्तित्व के लिए एक स्ट्रॉन्ग एंटिटी पर निर्भर होती हैं। एक आदेश_आइटम मातृका आदेश.
एंटिटीज को सामान्य प्रतीकों में आमतौर पर आयत के रूप में दर्शाया जाता है। उन्हें वस्तुओं के वर्ग का प्रतिनिधित्व करने के लिए एकवचन संज्ञा का उपयोग करके नामित किया जाता है।
2. गुण
गुण एक एंटिटी के गुण या विशेषताओं का वर्णन करते हैं। वे एक तालिका के अंदर कॉलम हैं। गुण कई श्रेणियों में आते हैं:
- सरल गुण: अविभाज्य मान, जैसे एक पहला_नाम या उम्र.
- मिश्रित गुण: उपभागों में विभाजित किए जा सकने वाले गुण, जैसे एक पता (सड़क, शहर, जिप)।
- बहु-मूल्य वाले गुण: बहुमूल्य वाले गुण, जैसे फ़ोन_नंबर या कौशल.
- व्युत्पन्न गुण: अन्य गुणों से गणना किए गए मान, जैसे उम्र से व्युत्पन्नजन्म_तिथि.
सबसे महत्वपूर्ण गुण है प्राथमिक कुंजी। यह एक अद्वितीय पहचानकर्ता एक एंटिटी के भीतर एक रिकॉर्ड को दूसरे से अलग करता है। प्राथमिक कुंजी के बिना, डेटा अखंडता को गारंटी नहीं दी जा सकती है।
3. संबंध
संबंध यह निर्धारित करते हैं कि संस्थाएँ एक दूसरे के साथ कैसे बातचीत करती हैं। वे डेटा बिंदुओं के बीच प्रतिबंधों और संबंधों को इंगित करते हैं। संबंध डेटाबेस का संयोजक ऊतक हैं।
- संबंधों की पहचान करना: एक कमजोर संस्था एक मजबूत संस्था पर निर्भर होती है। संबंध कमजोर संस्था के अस्तित्व को निर्धारित करता है।
- पहचान नहीं करने वाले संबंध: संस्थाएँ स्वतंत्र हैं। संबंध मौजूद है लेकिन अस्तित्व को निर्धारित नहीं करता है।
🔗 कार्डिनैलिटी और मोडैलिटी को समझना
कार्डिनैलिटी एक संस्था के उन उदाहरणों की संख्या को परिभाषित करती है जो दूसरी संस्था के प्रत्येक उदाहरण के साथ जुड़ सकते हैं या जुड़ने चाहिए। इसे अक्सर “एक से एक”, “एक से बहुत”, या “बहुत से बहुत” संरचना के रूप में जाना जाता है।
मोडैलिटी यह बताती है कि क्या संबंध अनिवार्य है या वैकल्पिक है। क्या एक रिकॉर्ड को एक संबंधित रिकॉर्ड की आवश्यकता है, या क्या इसके बिना भी अस्तित्व में रहने की अनुमति है?अनिवार्य है एक संबंधित रिकॉर्ड के साथ हो, या क्या इसे बिना एक के अस्तित्व में रहने की अनुमति है?
कार्डिनैलिटी प्रकार
| कार्डिनैलिटी | प्रतीक | उदाहरण परिदृश्य |
|---|---|---|
| एक से एक (1:1) | एक ─── एक | एक कर्मचारी के एक कार्यालय का डेस्क होता है |
| एक से बहुत (1:N) | एक ─── बहुत | एक ग्राहक बहुत सारे आदेश देता है |
| बहुत से बहुत (M:N) | बहुत ─── बहुत | बहुत से छात्र बहुत से कोर्स में दाखिला लेते हैं |
बहुत से बहुत संबंधों को विशेष रूप से ध्यान में रखना महत्वपूर्ण है। एक भौतिक डेटाबेस में, एक सीधे बहुत से बहुत संबंध का समर्थन नहीं किया जाता है। इसे एक सह-संबंधित संस्था (जंक्शन टेबल) के माध्यम से हल किया जाना चाहिए, जो संबंध को दो एक से बहुत संबंधों में तोड़ता है।
⚖️ नॉर्मलाइजेशन सिद्धांत
नॉर्मलाइजेशन डेटा को कम अतिरिक्तता और डेटा अखंडता में सुधार करने के लिए व्यवस्थित करने की प्रक्रिया है। इसमें बड़ी टेबलों को छोटी, तार्किक रूप से जुड़ी टेबलों में विभाजित करना और उनके बीच संबंधों को परिभाषित करना शामिल है। लक्ष्य यह सुनिश्चित करना है कि प्रत्येक डेटा के एक ही स्थान पर भंडारण हो।
पहला सामान्य रूप (1NF)
नॉर्मलाइजेशन का पहला चरण यह सुनिश्चित करने में शामिल है कि:
- सभी कॉलम मान परमाणु (अविभाज्य) हैं।
- एक ही कॉलम के भीतर कोई दोहराए जाने वाले समूह या ऐरे नहीं हैं।
- प्रत्येक स्तंभ में प्रत्येक पंक्ति में केवल एक मान होता है।
उदाहरण के लिए, एक कौशलस्तंभ जिसमें “Java, SQL, Python” है, 1NF के उल्लंघन करता है। इसे अलग-अलग पंक्तियों या अलग तालिका में विभाजित करना चाहिए।
द्वितीय सामान्य रूप (2NF)
एक तालिका 2NF में होती है यदि वह 1NF में है और सभी गैर-कुंजी विशेषताएं प्राथमिक कुंजी पर पूरी तरह निर्भर हैं। इससे आंशिक निर्भरता को दूर किया जाता है। यदि एक तालिका में संयुक्त प्राथमिक कुंजी है, तो प्रत्येक गैर-कुंजी स्तंभ को पूरी कुंजी पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं।
तृतीय सामान्य रूप (3NF)
एक तालिका 3NF में होती है यदि वह 2NF में है और कोई अनुक्रमिक निर्भरता नहीं है। इसका अर्थ है कि गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए। उदाहरण के लिए, यदि शहर पर निर्भर हैपिन कोड, और पिन कोड पर निर्भर हैग्राहक क्रमांक, संग्रहीत करना शहर में ग्राहक तालिका में अतिरेक उत्पन्न करता है। एक अलग पिन कोड तालिका होना बेहतर है।
📐 नोटेशन मानक
ERD को दर्शाने के लिए विभिन्न नोटेशन मौजूद हैं। जबकि आधारभूत तर्क एक जैसा रहता है, दृश्य प्रतीक भिन्न होते हैं। एक मानक का चयन दस्तावेज़ीकरण में संगतता सुनिश्चित करता है।
- क्राउ का पैर: आधुनिक डेटाबेस डिज़ाइन में सबसे आम नोटेशन। इसमें विशिष्ट अंत वाली रेखाओं (जैसे पक्षी के पैर की तरह) का उपयोग कार्डिनैलिटी को दर्शाने के लिए किया जाता है। यह स्पष्ट और डिज़ाइन टूल्स द्वारा व्यापक रूप से समर्थित है।
- चेन: एक पुराना नोटेशन जहां संबंध आयताकार और एकता आयताकार होती हैं। यह संबंध की प्रकृति के बारे में बहुत स्पष्ट है, लेकिन जटिल मॉडल में भारी हो सकता है।
- UML: समन्वित मॉडलिंग भाषा। अक्सर सॉफ्टवेयर इंजीनियरिंग में उपयोग की जाती है, यह ER अवधारणाओं को व्यवस्था डिज़ाइन के लिए व्यापक UML ढांचे में फिट करने के लिए अनुकूलित करती है।
🔄 तार्किक से भौतिक डिज़ाइन में
एक सारांश आरेख से कार्यात्मक डेटाबेस तक की यात्रा में तार्किक मॉडल से भौतिक मॉडल में जाना शामिल होता है।
तार्किक डेटा मॉडल
इस मॉडल का ध्यान डेटा की संरचना पर होता है, जिसमें विशिष्ट डेटाबेस प्रबंधन प्रणाली के बारे में ध्यान नहीं दिया जाता है। इसमें सामान्य शब्दों का उपयोग करके प्रतिनिधित्व, गुण, और संबंधों को परिभाषित किया जाता है। यह प्रौद्योगिकी-निरपेक्ष है। इस चरण में प्रश्न का उत्तर दिया जाता है: “हमें कौन-से डेटा की आवश्यकता है और वे एक-दूसरे से कैसे संबंधित हैं?”
भौतिक डेटा मॉडल
इस मॉडल में तार्किक डिज़ाइन को डेटाबेस प्रणाली के विशिष्ट विवरण में बदला जाता है। इसमें डेटा प्रकार (उदाहरण के लिए, पूर्णांक, वर्चर, समय-स्टैम्प), इंडेक्स, सीमाएं और विभाजन रणनीतियां परिभाषित की जाती हैं। यह प्रश्न का उत्तर देता है: “हम इसे कैसे कुशलतापूर्वक संग्रहीत करें?”
इस संक्रमण के दौरान विशिष्ट निर्णय लिए जाते हैं:
- डेटा प्रकार: चुनाव करना
पूर्णांकबनामबड़ा पूर्णांकअपेक्षित आयतन के आधार पर। - इंडेक्स: खोज की शर्तों में अक्सर उपयोग किए जाने वाले कॉलम में इंडेक्स जोड़ना ताकि प्राप्त करना तेज हो।
- सीमाएं: लागू करना
NOT NULLनियम याUNIQUEडेटाबेस स्तर पर सीमाएं। - नामकरण प्रथाएं: एक मानक जैसे अपनाना
स्नेक_केसताबलों और कॉलम के लिए पठनीयता सुनिश्चित करने के लिए।
🛡️ डेटा मॉडलिंग में आम चुनौतियां
यहां तक कि अनुभवी वास्तुकार भी ईआर आरेख बनाते समय बाधाओं का सामना करते हैं। इन चुनौतियों को जल्दी से पहचानने से महंगे पुनर्निर्माण से बचा जा सकता है।
1. व्यापार नियमों में अस्पष्टता
स्टेकहोल्डर अक्सर डेटा की आवश्यकताओं का स्पष्ट वर्णन नहीं करते हैं। “हमें उपयोगकर्ताओं को ट्रैक करने की आवश्यकता है” का अर्थ एक सरल सूची या भूमिकाओं, अनुमतियों और लॉग रिकॉर्ड के साथ एक जटिल प्रणाली हो सकती है। आरेख पर रेखाएं खींचने से पहले इन अस्पष्टताओं को स्पष्ट करने के लिए स्पष्ट संचार आवश्यक है।
2. अत्यधिक सामान्यीकरण
जबकि सामान्यीकरण अतिरेक को कम करता है, अत्यधिक सामान्यीकरण डेटा को बहुत सारी टेबलों में फैला सकता है। इससे जटिल जॉइन्स की स्थिति बनती है जो प्रश्न प्रदर्शन को धीमा कर देती है। डेटा अखंडता और पढ़ने के प्रदर्शन के बीच संतुलन बनाए रखना आवश्यक है।
3. भविष्य के विकास को नजरअंदाज करना
डिजाइन अक्सर वर्तमान आवश्यकताओं पर केंद्रित होते हैं। हालांकि, डेटा मॉडल को भविष्य के परिवर्तनों को स्वीकार करना चाहिए। एक फोन नंबर के लिए डिज़ाइन की गई टेबल में बहुत से नंबर या अंतरराष्ट्रीय प्रारूपों की संभावना को ध्यान में रखना चाहिए।
4. अनुपस्थित संबंध
एकता को परिभाषित करना आम है, लेकिन उन्हें जोड़ना भूल जाना भी आम है। एक उत्पाद टेबल बिना किसी संबंध के एक श्रेणी टेबल के कारण वर्गीकरण संभव नहीं होता है। प्रत्येक एंटिटी की समीक्षा करनी चाहिए ताकि यह सुनिश्चित किया जा सके कि यह स्कीमा के बाकी हिस्सों से तार्किक रूप से जुड़ी हो।
📋 दस्तावेज़ीकरण के लिए सर्वोत्तम प्रथाएं
एक आरेख केवल तभी उपयोगी होता है जब उसे समझा जा सके। दस्तावेज़ीकरण दृश्य मॉडल के साथ पूरक होता है।
- संगत नामकरण:स्पष्ट, वर्णनात्मक नामों का उपयोग करें। संक्षिप्त रूपों से बचें, जब तक वे उद्योग मानक न हों।
- संस्करण नियंत्रण:स्कीमा को कोड की तरह लें। समय के साथ ERD में बदलावों को ट्रैक करें ताकि प्रणाली के विकास को समझा जा सके।
- अनोटेशन:जटिल व्यावसायिक तर्क या विज़ुअल रूप से दिखाए न जा सकने वाले अपवादों को समझाने के लिए आरेख में नोट जोड़ें।
- समीक्षा चक्र:तकनीकी और गैर-तकनीकी टीम सदस्यों के साथ मॉडल की नियमित समीक्षा करें ताकि समन्वय सुनिश्चित हो।
🚀 आधुनिक प्रणालियों में ERD की भूमिका
आधुनिक डेटा संरचना के क्षेत्र में, NoSQL और ग्राफ डेटाबेस के उदय के बावजूद भी ER मॉडलिंग के सिद्धांत प्रासंगिक बने हुए हैं। जबकि संग्रहण तकनीक में परिवर्तन आते हैं, संबंधों और डेटा अखंडता को समझने की आवश्यकता नहीं बदलती है।
SQL-आधारित प्रणालियों के लिए, ERD मुख्य डिज़ाइन अभिलेख है। NoSQL प्रणालियों के लिए, यह दस्तावेज़ संरचना और एम्बेडिंग रणनीतियों को प्रभावित करता है। ग्राफ डेटाबेस के लिए, यह नोड्स और एजेस को स्पष्ट रूप से परिभाषित करता है।
डेटा मॉडलिंग एक बार का कार्य नहीं है। जैसे-जैसे व्यावसायिक आवश्यकताएं विकसित होती हैं, ERD को उसके साथ विकसित होना चाहिए। इस आवर्ती प्रक्रिया से यह सुनिश्चित होता है कि डेटा परत एक रणनीतिक संपत्ति बनी रहे, तकनीकी दायित्व नहीं।
✅ मुख्य बातों का सारांश
- आधार:ERD डेटाबेस डिज़ाइन के लिए नींव हैं, जो तार्किक सुसंगतता सुनिश्चित करते हैं।
- घटक:एंटिटीज, गुणधर्म और संबंध किसी भी मॉडल के मूल त्रिकोण का निर्माण करते हैं।
- कार्डिनैलिटी:1:1, 1:N और M:N संबंधों को समझना सटीक डेटा मैपिंग के लिए महत्वपूर्ण है।
- नॉर्मलाइजेशन: अतिरेक को कम करने और अखंडता सुनिश्चित करने के लिए 1NF, 2NF और 3NF लागू करें।
- विकास: कार्यान्वयन की तैयारी के लिए तार्किक मॉडल से भौतिक मॉडल में स्थानांतरित करें।
- दस्तावेज़ीकरण: लंबे समय तक रखरखाव के लिए स्पष्ट नामकरण प्रणाली और संस्करण नियंत्रण बनाए रखें।
इन सिद्धांतों का पालन करके, वास्तुकार ऐसे प्रणालियां बनाते हैं जो केवल आज कार्यात्मक ही नहीं होती हैं, बल्कि भविष्य के लिए अनुकूलित करने योग्य होती हैं। ईआर आरेख केवल एक ड्राइंग से अधिक है; यह व्यापार तर्क और तकनीकी कार्यान्वयन के बीच एक संविदा है।

