











एक टिकाऊ डेटा संरचना डिज़ाइन करना किसी भी सफल सॉफ्टवेयर एप्लिकेशन की आधारशिला है। जब परियोजनाएं सरल प्रोटोटाइप से आगे बढ़कर मध्यम चरण में प्रवेश करती हैं, तो डेटा संबंधों की जटिलता में काफी वृद्धि होती है। यहीं पर एंटिटी रिलेशनशिप डायग्राम (ERD) संचार और योजना के लिए महत्वपूर्ण उपकरण बन जाते हैं। हालांकि, एक अच्छी तरह से बनाया गया डायग्राम एक अच्छी तरह से काम करने वाले डेटाबेस की गारंटी नहीं देता है। बहुत से डेवलपर्स नॉर्मलाइजेशन प्रक्रिया के दौरान फंदे में फंस जाते हैं, जिसके कारण बाद में विकास के दौरान प्रदर्शन की समस्याएं या डेटा अखंडता की समस्याएं उत्पन्न हो सकती हैं।
यह गाइड ER डायग्राम के लिए आवश्यक सर्वोत्तम प्रथाओं का अध्ययन करता है, विशेष रूप से सामान्य नॉर्मलाइजेशन की खामियों से बचने पर ध्यान केंद्रित करता है। हम डेटा अखंडता और प्रदर्शन के बीच संतुलन बनाने के तरीकों का अध्ययन करेंगे, ताकि आपकी स्कीमा आपके परियोजना के विकास के साथ भी बनाए रखी जा सके। चाहे आप मध्यम आकार के ई-कॉमर्स प्लेटफॉर्म या एक जटिल प्रबंधन प्रणाली के लिए डिज़ाइन कर रहे हों, इन सिद्धांतों की मदद से आप एक ऐसा आधार बना सकते हैं जो समय की परीक्षा में खड़ा रहे।
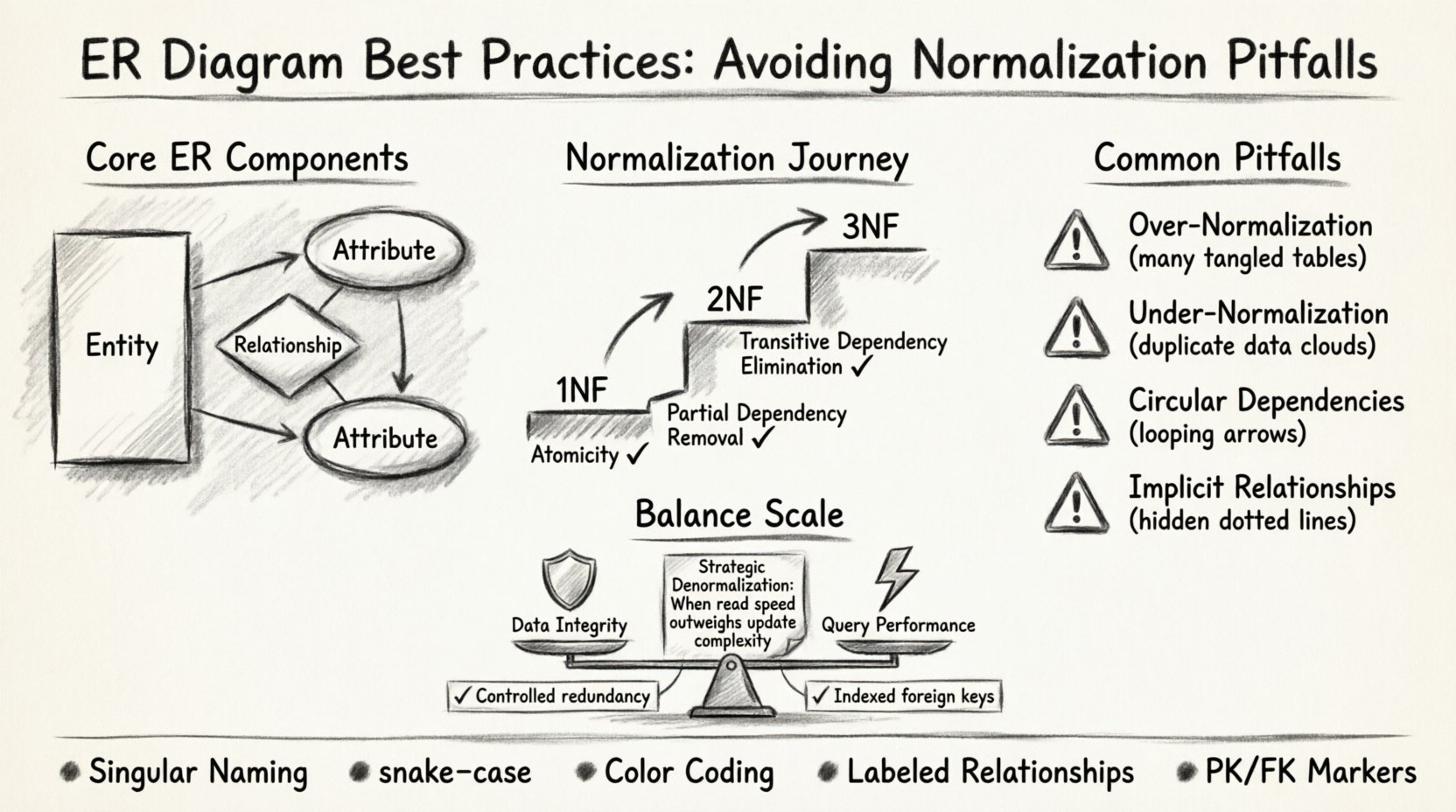
ER मॉडलिंग के मूल घटकों को समझना 🏗️
नॉर्मलाइजेशन में डुबकी लगाने से पहले, मूल निर्माण तत्वों के स्पष्ट समझ को स्थापित करना आवश्यक है। एक ER डायग्राम तीन प्राथमिक तत्वों के माध्यम से डेटाबेस की संरचना को दर्शाता है:
- एंटिटीज:आयताकार आकृति के रूप में दर्शाए जाते हैं, जो डेटाबेस में तालिकाओं के समान होते हैं। इनका उपयोग रुचि के वस्तुओं का वर्णन करने के लिए किया जाता है, जैसे किग्राहक, आदेश, याउत्पाद.
- गुणधर्म:ओवल के रूप में दर्शाए जाते हैं, ये एक एंटिटी के विशिष्ट गुण होते हैं। एक ग्राहकके लिए, गुणधर्म में शामिल हो सकते हैंग्राहकआईडी, नाम, औरईमेलपता.
- संबंध:हीरे या जोड़ने वाली रेखाओं के रूप में दर्शाए जाते हैं, ये एंटिटीज के बीच बातचीत को परिभाषित करते हैं। एक संबंध यह दर्शाता है कि एक तालिका में डेटा दूसरी तालिका में डेटा से कैसे जुड़ता है।
मध्यम परियोजनाओं में, जटिलता अक्सर संबंधों में होती है। एक सरल एक-से-एक संबंध स्पष्ट होता है, लेकिन बहुत-से-बहुत संबंधों को बारीकी से संभालने की आवश्यकता होती है ताकि अतिरेक से बचा जा सके। दृश्य स्पष्टता तार्किक सही होने के बराबर महत्वपूर्ण है। एक भारी या अस्पष्ट डायग्राम डेवलपर्स द्वारा गलत व्याख्या करने के कारण वास्तविकीकरण के दौरान स्कीमा असंगतियों का कारण बन सकता है।
नॉर्मलाइजेशन प्रक्रिया: गहन अध्ययन 🔍
नॉर्मलाइजेशन डेटाबेस में डेटा को व्यवस्थित करने की व्यवस्थित प्रक्रिया है, जिसका उद्देश्य अतिरेक को कम करना और डेटा अखंडता में सुधार करना है। जबकि इसे अक्सर कठोर नियमों के सेट के रूप में पढ़ाया जाता है, वास्तव में यह एक संतुलन का खेल है। मध्यम परियोजनाओं में लक्ष्य अनिवार्य रूप से सर्वोच्च नॉर्मल रूप तक पहुंचना नहीं है, बल्कि विशिष्ट उपयोग के लिए सबसे कुशल संरचना प्राप्त करना है।
पहला सामान्य रूप (1NF): आधार
पहला चरण परमाणुता सुनिश्चित करना है। एक तालिका में प्रत्येक कॉलम में केवल एक ही मान होना चाहिए। एक ही सेल में दोहराए जाने वाले समूह या ऐरे की अनुमति नहीं है।
- जांचें: क्या प्रत्येक पंक्ति का एक अद्वितीय पहचानकर्ता (प्राथमिक कुंजी) है?
- जांचें: क्या सभी कॉलम में केवल एकल मान ही हैं?
- उदाहरण: एक उत्पादों तालिका में ऐसे कॉलम का होना नहीं चाहिए जैसे रंग में “लाल, नीला, हरा” शामिल हो। इसके बजाय, अलग से एक उत्पाद रंग तालिका बनाएं।
दूसरा मानक रूप (2NF): आंशिक निर्भरताओं को दूर करना
जब तक एक तालिका 1NF में नहीं होती, तब तक उसे 2NF में भी होना चाहिए। इसका मतलब है आंशिक निर्भरताओं को दूर करना। प्रत्येक गैर-कुंजी विशेषता को पूरी प्राथमिक कुंजी पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं। यह संयुक्त कुंजी के साथ काम करते समय बहुत महत्वपूर्ण है।
- नियम: यदि एक तालिका में संयुक्त प्राथमिक कुंजी (A + B) है, तो प्रत्येक अन्य कॉलम को A और B दोनों पर निर्भर होना चाहिए, केवल A पर नहीं।
- अनुप्रयोग: एक आदेश विवरण तालिका में संयुक्त कुंजी के साथ आदेश आईडी और उत्पाद आईडी, तालिका में मात्रा दोनों पर निर्भर है। हालांकि, उत्पाद नाम केवल उत्पाद आईडी। ले जाना उत्पाद का नाम एक उत्पाद तालिका इस समस्या का समाधान करती है।
तृतीय सामान्य रूप (3NF): प्रत्यक्ष निर्भरता को हटाना
3NF मध्यम परियोजनाओं के लिए सबसे आम लक्ष्य है। इसमें यह आवश्यकता है कि कोई भी गैर-कुंजी विशेषता दूसरी गैर-कुंजी विशेषता पर निर्भर न हो। सभी गैर-कुंजी विशेषताओं को प्राथमिक कुंजी पर सीधे निर्भर होना चाहिए।
- परिदृश्य: एक कर्मचारी तालिका में हैकर्मचारी आईडी, विभाग आईडी, और विभाग का नाम.
- समस्या: विभाग का नाम पर निर्भर हैविभाग आईडी, नहींकर्मचारी आईडी.
- समाधान: स्थानांतरित करेंविभाग का नाम एक विभाग तालिका जो विभाग आईडी.
मध्यम प्रोजेक्ट्स में सामान्य नॉर्मलाइजेशन की गलतियाँ ⚠️
जबकि नॉर्मलाइजेशन शक्तिशाली है, इसे अनजाने में लागू करने से महत्वपूर्ण समस्याएँ उत्पन्न हो सकती हैं। मध्यम प्रोजेक्ट्स के अक्सर विशिष्ट आवश्यकताएँ होती हैं जिनके लिए व्यावहारिक दृष्टिकोण की आवश्यकता होती है। नीचे स्कीमा डिजाइन के दौरान सबसे अक्सर आने वाली गलतियाँ दी गई हैं।
| गलती | परिणाम | समाधान |
|---|---|---|
| अत्यधिक नॉर्मलाइजेशन | बहुत सारी टेबलें और जटिल जॉइन्स पढ़ने के ऑपरेशन को धीमा कर देते हैं। | रणनीतिक रूप से अनॉर्मलाइज़ करें: अक्सर प्राप्त किए जाने वाले पढ़ने-पर आधारित डेटा के लिए टेबलों को जोड़ें। |
| अपर्याप्त नॉर्मलाइजेशन | डेटा अतिरेक सम्पादन विचलनों और बर्बाद स्टोरेज के कारण बनता है। | 3NF को लागू करें: सुनिश्चित करें कि गैर-की विशेषताएँ अन्य गैर-की विशेषताओं पर निर्भर न हों। |
| चक्रीय निर्भरता | विदेशी कीज़ लूप बनाती हैं जो डेटा के हटाने को कठिन बनाती हैं। | संबंधों की समीक्षा करें: चक्रों के लिए सभी विदेशी की सीमाओं की समीक्षा करें। |
| अप्रत्यक्ष संबंध | तर्क एप्लिकेशन कोड में छिपा होता है, स्कीमा के बजाय। | इसे स्पष्ट बनाएं: डेटाबेस में संबंधों को बल देने के लिए विदेशी कीज़ का उपयोग करें। |
गलती 1: प्रदर्शन की जाल
सबसे आम गलतियों में से एक यह है कि प्रश्न के प्रदर्शन को ध्यान में रखे बिना सही नॉर्मलाइजेशन की खोज करना। एक मध्यम प्रोजेक्ट में आपके करोड़ों रिकॉर्ड हो सकते हैं। एक उपयोगकर्ता के प्रोफाइल को प्राप्त करने के लिए पांच अलग-अलग टेबलों को जोड़ने वाला प्रश्न धीमा हो सकता है।
- हॉट पाथ की पहचान करें:यह तय करें कि कौन से प्रश्न सबसे अधिक बार चलते हैं।
- पढ़ना बनाम लिखना:यदि आपकी एप्लिकेशन पढ़ने पर अधिक निर्भर है, तो कुछ विशिष्ट कॉलम को अनॉर्मलाइज़ करने के बारे में सोचें।
- सामग्री दृश्य:जटिल संघनन के लिए पूर्व-गणना किए गए परिणामों को स्टोर करने के लिए डेटाबेस दृश्यों का उपयोग करें।
गलती 2: कार्डिनैलिटी प्रतिबंधों को नजरअंदाज करना
कार्डिनैलिटी एक एकाकी इकाई के उन उदाहरणों की संख्या को परिभाषित करती है जो दूसरी एकाकी इकाई के प्रत्येक उदाहरण के साथ जुड़ सकते हैं या जुड़ने चाहिए। एरडी में इसकी सही परिभाषा न करने से डेटा त्रुटियाँ होती हैं।
- एक से एक: एक उपयोगकर्ता के पास ठीक एक प्रोफ़ाइल होती है। (उदाहरण के लिए, उपयोगकर्ता और उपयोगकर्ता प्रोफ़ाइल).
- एक से बहुत अधिक: एक विभाग में कई कर्मचारी होते हैं। (उदाहरण के लिए, विभाग और कर्मचारी).
- बहुत से से बहुत से: एक छात्र बहुत से कोर्स में दाखिला ले सकता है, और एक कोर्स में बहुत से छात्र होते हैं। इसके लिए एक जंक्शन टेबल की आवश्यकता होती है।
जब एर आर आर डायग्राम डिज़ाइन कर रहे हों, तो इन प्रतिबंधों को स्पष्ट रूप से चिह्नित करें। यहाँ अस्पष्टता अक्सर ऐप्लिकेशन बग के कारण होती है जहाँ कोड एक संबंध के बारे में मान लेता है जो डेटाबेस में मौजूद नहीं है।
स्पष्टता के लिए दृश्य डिज़ाइन मानक 📊
एक स्कीमा जो तार्किक रूप से काम करती है लेकिन दृश्य रूप से भ्रमित करती है, एक जोखिम है। मध्यम स्तर के प्रोजेक्ट में अक्सर अलग-अलग मॉड्यूल पर काम करने वाले कई डेवलपर्स शामिल होते हैं। एर डायग्राम को एक साझा भाषा के रूप में काम करना चाहिए।
- संगत नामकरण प्रणाली: टेबल के लिए एकवचन संज्ञा का उपयोग करें (उदाहरण के लिए, ग्राहक नहीं ग्राहक) और कॉलम नामों के लिए स्नेक_केस (उदाहरण के लिए, पहला_नाम).
- तार्किक समूहन: एक रेखाचित्र पर संबंधित एंटिटी को एक साथ समूहित करें। रखें आदेश, आर्डरआइटम, और उत्पाद एक दूसरे के पास।
- रंग कोडिंग: त्वरित पहचान में सहायता के लिए विभिन्न प्रकार के संस्थानों (उदाहरण के लिए, मुख्य तालिकाओं बनाम विन्यास तालिकाओं) के लिए अलग-अलग रंगों का उपयोग करें।
- संबंधों को लेबल करें: कभी भी तालिकाओं के बीच कोई लाइन बिना लेबल के छोड़ें नहीं। प्रकार बताएं (उदाहरण के लिए, “बहुत सारे हैं”, “एक हिस्सा है”)।
अपने आरेख को अंतिम रूप देने से पहले निम्नलिखित चेकलिस्ट को ध्यान में रखें:
- क्या सभी प्राथमिक कुंजियाँ स्पष्ट रूप से चिह्नित हैं?
- क्या विदेशी कुंजियों को स्थिर रूप से लेबल किया गया है?
- क्या संबंध की दिशा स्पष्ट है (पिता से बच्चे तक)?
- क्या वैकल्पिक बनाम अनिवार्य संबंधों के बीच अंतर किया गया है?
बहु-से-बहु संबंधों का प्रबंधन 🔄
बहु-से-बहु संबंध ईआर मॉडलिंग का सबसे जटिल हिस्सा हैं। उन्हें एकल विदेशी कुंजी द्वारा प्रतिनिधित्व नहीं किया जा सकता है। इसके बजाय, उन्हें एक सहयोगी तालिका की आवश्यकता होती है, जिसे अक्सर जंक्शन तालिका या ब्रिज तालिका कहा जाता है।
इन तालिकाओं के डिजाइन के दौरान, सरल स्थानापन्न बनाने से बचें। जंक्शन तालिका को संबंध के स्वयं के संबंध में महत्वपूर्ण डेटा रखना चाहिए।
- खराब डिजाइन: केवल उपयोगकर्ताID और समूहID.
- अच्छा डिजाइन: एक तालिका जिसमें उपयोगकर्ताID, समूहID, जॉइनतारीख, और भूमिका.
इस दृष्टिकोण के द्वारा आप संबंध के बारे में मेटाडेटा संग्रहीत कर सकते हैं बिना नॉर्मलाइजेशन नियमों के उल्लंघन किए। इससे ऐसे प्रश्नों को संभव बनाता है जैसे “ग्रुप एक्स में तारीख वाई के बाद शामिल हुए सभी उपयोगकर्ताओं को खोजें”।
प्रदर्शन बनाम अखंडता के विकल्प 🛡️
एक संपूर्ण डेटाबेस स्कीमा की बात नहीं है। प्रत्येक डिजाइन निर्णय में एक विकल्प शामिल होता है। मध्यम स्तर के प्रोजेक्ट्स में, जोखिम प्रोटोटाइप्स की तुलना में अधिक होता है लेकिन एंटरप्राइज सिस्टम्स की तुलना में कम होता है। आपको व्यवसाय की आवश्यकताओं के आधार पर प्राथमिकता देनी होगी।
डेटा अखंडता
नॉर्मलाइजेशन अखंडता सुनिश्चित करता है। यदि आप पूरी तरह से नॉर्मलाइज करते हैं, तो आप डुप्लीकेट डेटा को रोकते हैं और सुसंगतता सुनिश्चित करते हैं। हालांकि, इसका मूल्य अधिक जटिल जॉइन्स के रूप में आता है।
- विदेशी कीज़: उन्हें संदर्भात्मक अखंडता को बनाए रखने के लिए उपयोग करें।
- सीमाएँ: उपयोग करें यूनीक, नॉट नल, और चेक सीमाएँ डेटा के स्रोत पर वैधता की जांच करने के लिए।
प्रश्न प्रदर्शन
डेनॉर्मलाइजेशन पढ़ने को तेज करता है लेकिन लेखन को जटिल बना देता है। यदि आपके एप्लिकेशन को रियल-टाइम विश्लेषण की आवश्यकता है, तो आपको डेटा की प्रतिलिपि बनाने की आवश्यकता हो सकती है।
- रीड रिप्लिका: रिपोर्टिंग के लिए अनुकूलित एक अलग स्कीमा को विचार में रखें।
- कैशिंग: अक्सर प्राप्त की जाने वाली नॉर्मलाइज्ड डेटा के लिए कैशिंग लेयर का उपयोग करें।
- इंडेक्सिंग: सुनिश्चित करें कि विदेशी की कॉलम को इंडेक्स किया गया हो ताकि जॉइन ऑपरेशन को तेज किया जा सके।
रखरखाव और विकास 📝
डेटाबेस स्कीमा अक्सर स्थिर नहीं होते हैं। जैसे-जैसे व्यवसाय की आवश्यकताएँ बदलती हैं, ईआर आरेख को विकसित होना चाहिए। कई महीनों पहले बनाए गए डिजाइन के कठोर रूप से पालन करना प्रगति को रोक सकता है।
- संस्करण नियंत्रण: अपने स्कीमा परिभाषाओं को कोड के रूप में लें। बदलावों को ट्रैक करने के लिए माइग्रेशन स्क्रिप्ट का उपयोग करें।
- दस्तावेज़ीकरण: वास्तविक डेटाबेस के साथ ईआर आरेख को समकालीन रखें। अद्यतन नहीं आरेख बिना आरेख से भी बदतर है।
- पुनर्गठन: नियमित रूप से स्कीमा की समीक्षा करें। क्या ऐसी तालिकाएं हैं जो अब उपयोग में नहीं हैं? क्या ऐसे कॉलम हैं जो हमेशा खाली हैं?
बदलाव करते समय हमेशा मौजूदा डेटा पर प्रभाव को ध्यान में रखें। कॉलम का नाम बदलने से एप्लिकेशन कोड टूट सकता है। नॉन-नल की सीमा जोड़ने से मौजूदा खाली मानों पर विफलता हो सकती है। माइग्रेशन की योजना ध्यान से बनाएं।
स्कीमा डिज़ाइन पर निष्कर्ष ⚖️
उच्च गुणवत्ता वाला ईआर आरेख बनाना एक आवर्ती प्रक्रिया है जिसमें तकनीकी ज्ञान और व्यावहारिक निर्णय लेने की आवश्यकता होती है। नॉर्मलाइज़ेशन सिद्धांतों को समझने और उनकी सीमाओं को पहचानने से आप मध्यम स्तर के प्रोजेक्टों को छूते आम त्रुटियों से बच सकते हैं। स्पष्टता, संगतता और अपने एप्लिकेशन की विशिष्ट प्रदर्शन आवश्यकताओं पर ध्यान केंद्रित करें।
याद रखें कि लक्ष्य केवल डेटा संग्रहीत करना नहीं है, बल्कि उसे कुशलता से प्राप्त करना और समय के साथ उसकी सटीकता बनाए रखना है। अपने वास्तविक प्रश्नों के बारे में अपने आरेख की नियमित समीक्षा करने से आपका प्रोजेक्ट स्वस्थ रहेगा। इन बेस्ट प्रैक्टिस को लागू करें, और आपकी डेटाबेस आर्किटेक्चर आपके एप्लिकेशन के विकास को प्रभावी ढंग से समर्थन करेगी।
- समीक्षा करें अपने संबंधों की नियमित समीक्षा करें।
- संतुलन बनाएं नॉर्मलाइज़ेशन और प्रदर्शन की आवश्यकताओं के बीच।
- दस्तावेज़ीकरण करें अपने निर्णयों को स्पष्ट रूप से।
- प्रमाणित करें अपने स्कीमा को वास्तविक दुनिया के डेटा परिदृश्यों के साथ।

