










Les données constituent le pilier de tout système d’information moderne. Toutefois, les données sans structure ne sont que du bruit. Pour transformer l’information brute en intelligence exploitée, nous comptons sur des modèles de données structurés. Le diagramme Entité-Relation (ERD) sert de plan architectural pour ces structures. Il comble le fossé entre les exigences métiers abstraites et la mise en œuvre technique concrète. Ce guide explore les mécanismes du modélisation des données, en se concentrant sur la manière de traduire avec précision la logique opérationnelle en définitions de schémas.
🏗️ Comprendre les composants fondamentaux
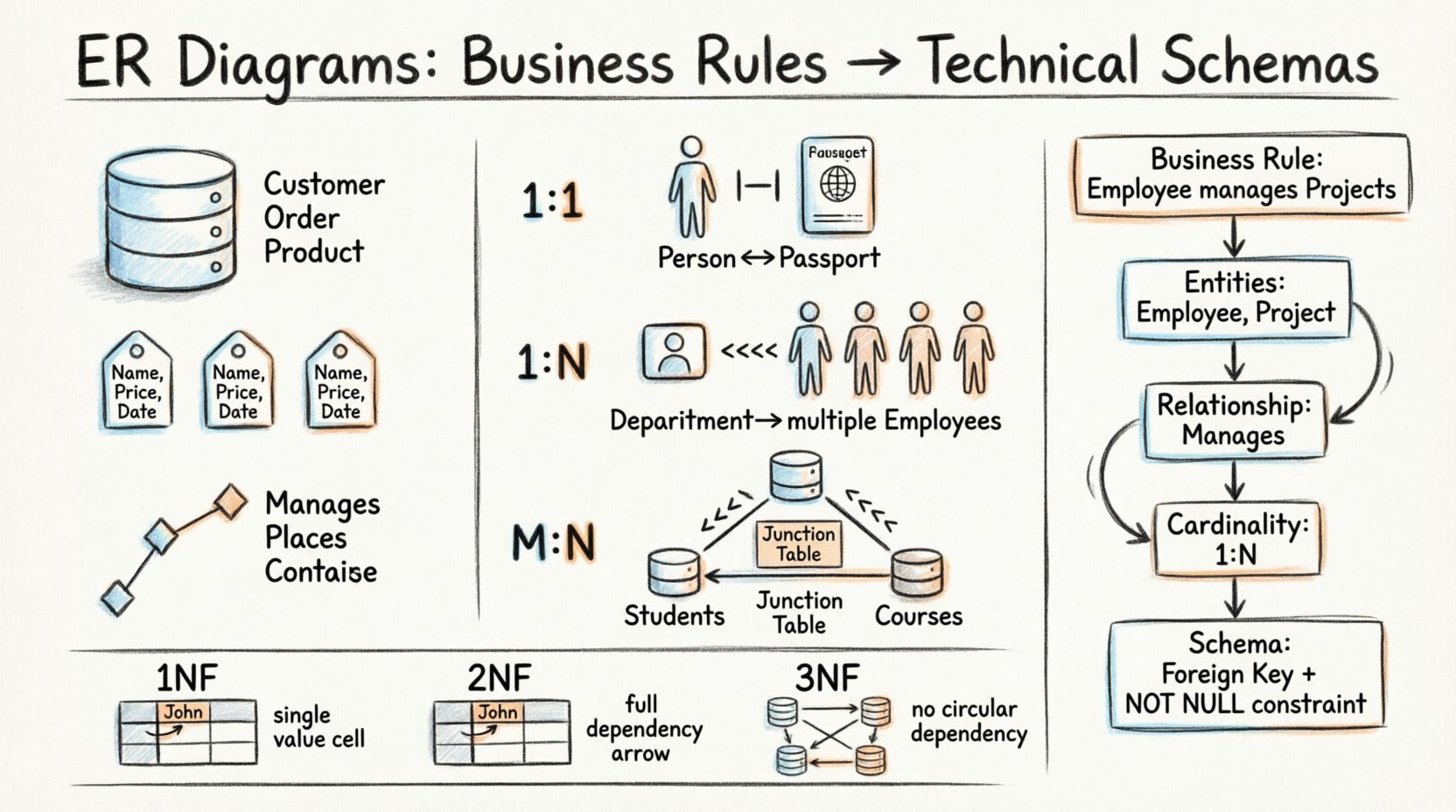
Un diagramme ER se compose de trois blocs de construction fondamentaux. Chaque bloc représente un aspect spécifique du stockage et des relations des données. Maîtriser ces composants permet de construire des bases de données robustes qui répondent aux besoins organisationnels.
- Entités : Elles représentent les objets ou les concepts dont les données sont collectées. Dans un contexte métier, il s’agit souvent de noms tels que Client, Commande, ou Produit. Dans le schéma, les entités deviennent des tables.
- Attributs : Ils décrivent les propriétés d’une entité. Des exemples incluent Nom, Prix, ou Date. Les attributs deviennent des colonnes au sein des tables correspondantes.
- Relations : Elles définissent les associations entre les entités. Une relation indique comment les instances d’une entité sont connectées aux instances d’une autre. Dans la base de données, les relations sont souvent contraintes par des clés.
🔄 Traduire les règles métiers en éléments de schéma
La phase de traduction est la plus critique dans la modélisation des données. Les parties prenantes métiers parlent en termes de processus et de politiques. Les ingénieurs parlent en termes de tables et de contraintes. Le modélisateur doit agir comme interprète entre ces deux langues.
Considérez une règle métier : « Un seul employé peut gérer plusieurs projets, mais un projet doit avoir au moins un responsable. » Comment cela devient-il un schéma ?
- Identifier les entités : Employé et Projet.
- Identifiez la relation : Gère.
- Définissez la cardinalité : Un employé à plusieurs projets (1:N). Un projet à au moins un employé (1:1 ou 1:N selon l’interprétation).
- Imposer l’optionnalité : Le projet doitavoir un responsable. Cela devient une contrainte NON NULL sur la clé étrangère.
Ce processus nécessite une analyse soigneuse du langage naturel fourni par les utilisateurs métiers. L’ambiguïté est l’ennemi de l’intégrité des données. Si une règle stipule « Un client peut passer des commandes », cela implique-t-il qu’ils peuvent passent zéro commande, ou doivent-ils en passer au moins une ? Cette distinction change la mise en œuvre des clés étrangères.
📏 Cardinalité et optionnalité
La cardinalité définit le nombre d’instances d’une entité qui peuvent ou doivent être associées à chaque instance d’une autre entité. C’est la fondation mathématique de la relation.
Un à un (1:1)
Cette relation se produit lorsque d’un enregistrement dans une table est lié à exactement un enregistrement dans une autre. Cela est courant lorsqu’on divise les tables pour des raisons de sécurité ou de performance, bien que ce soit moins fréquent dans la logique métier générale.
- Exemple : Une personne possède un passeport. Un passeport appartient à une seule personne.
- Implémentation : Une clé étrangère dans l’une des deux tables qui fait référence à la clé primaire de l’autre.
Un à plusieurs (1:N)
C’est le type de relation le plus courant dans les bases de données relationnelles. Un enregistrement dans la table A est lié à plusieurs enregistrements dans la table B. La table B contient la clé étrangère.
- Exemple : Un département a plusieurs employés. Un employé appartient à un seul département.
- Implémentation : Le Employé table contient une DepartmentID colonne.
Plusieurs à plusieurs (M:N)
Deux enregistrements dans la table A peuvent être liés à plusieurs enregistrements dans la table B, et inversement. Une implémentation directe de cela n’est pas possible dans les schémas relationnels standards sans une étape intermédiaire.
- Exemple : Les étudiants s’inscrivent à des cours. Un étudiant suit de nombreux cours. Un cours a de nombreux étudiants.
- Implémentation : Créez une table de jonction (entité associative) contenant des clés étrangères provenant des deux tables parentes.
| Type de relation | Notation visuelle (concept) | Implémentation du schéma | Cas d’utilisation courant |
|---|---|---|---|
| Un à un (1:1) | |—| | Clé étrangère dans l’une des deux tables | Personne ↔ Passeport |
| Un à plusieurs (1:N) | |—<<< | Clé étrangère dans la table « plusieurs » | Département ↔ Employés |
| Plusieurs à plusieurs (M:N) | <<<—<<< | Table de jonction avec deux clés étrangères | Étudiants ↔ Cours |
🧩 Principes de normalisation
Une fois que les entités et les relations sont définies, le schéma doit être normalisé. La normalisation est un processus systématique d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité des données. Elle consiste à décomposer les tables en composants plus petits et bien structurés.
Première forme normale (1NF)
Chaque colonne doit contenir des valeurs atomiques. Il ne doit pas y avoir de groupes répétitifs ou de tableaux dans une seule cellule. Chaque ligne doit être unique.
- Violation : Un Compétences colonne contenant « SQL, Python, Java » dans une seule cellule.
- Correction : Séparez les compétences dans une table distincte liée par une relation.
Deuxième forme normale (2NF)
Le tableau doit être en 1NF, et toutes les attributs non clés doivent dépendre entièrement de la clé primaire. Cela élimine les dépendances partielles.
- Scénario : Un tableau combinant Commande et Ligne de commande où NomProduit dépend uniquement de la IDArticle, pas de la IDCommande.
- Correction : Déplacez NomProduit vers une table Articles table.
Troisième forme normale (3FN)
La table doit être en 2FN, et il ne doit pas y avoir de dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés.
- Scénario : Un Client table contenant Ville et Pays, où Pays est déterminé par Ville.
- Correction : Créez une Localisation table pour stocker les données de Ville et de Pays.
🛡️ Gestion des contraintes et de l’intégrité
Un schéma n’est bon que par les règles qui le protègent. Les contraintes assurent que les données restent précises et cohérentes au fil du temps.
Clés primaires
Chaque table doit avoir un identifiant unique. Cela garantit que deux lignes ne sont pas identiques et permet une récupération précise. Dans de nombreux systèmes, il s’agit d’un entier auto-incrémenté. Dans d’autres, il peut s’agir d’un UUID ou d’une clé naturelle.
Clés étrangères
Les clés étrangères maintiennent l’intégrité référentielle. Elles garantissent qu’un enregistrement dans la table enfant ne peut exister sans un enregistrement correspondant dans la table parente. Cela empêche les données orphelines.
- Sur suppression en cascade : Si le parent est supprimé, l’enfant est automatiquement supprimé.
- Sur suppression restreinte : Empêche la suppression du parent s’il existe des enfants.
- Sur suppression en réglant à null : Supprime le parent mais laisse l’enregistrement enfant avec une clé étrangère nulle.
Contraintes de vérification
Elles imposent une logique métier spécifique directement dans la base de données. Les exemples incluent la garantie qu’une Prix est supérieur à zéro ou une Date de début est antérieure à une Date de fin.
⚠️ Pièges courants dans la modélisation des données
Même les architectes expérimentés peuvent négliger des détails cruciaux. Être conscient des erreurs courantes aide à concevoir des systèmes plus résilients.
- Sur-normalisation :Diviser les tables de manière trop agressive peut entraîner des jointures complexes qui dégradent les performances des requêtes. Parfois, une dénormalisation est acceptable pour les charges de travail intensives en lecture.
- Ignorer les suppressions douces : Les règles métier exigent souvent de conserver les données historiques. Supprimer un enregistrement de manière permanente supprime la traçabilité. Un indicateur EstSupprimé est souvent nécessaire.
- Supposer l’unicité : Le simple fait qu’une règle métier implique l’unicité (par exemple, Email) ne signifie pas que la base de données l’applique. Une contrainte d’unicité doit être définie explicitement.
- Ignorer le temps : La plupart des données métier ont une composante temporelle. Enregistrer Quand un enregistrement a été créé ou mis à jour est essentiel pour l’audit et le débogage.
- Durcir les valeurs : Utiliser des valeurs spécifiques dans les requêtes SQL au lieu de faire référence à des tables de référence rend le système rigide et difficile à maintenir.
🔄 Le processus itératif de conception
La modélisation des données est rarement un processus linéaire. Elle est itérative. Le diagramme initial est une hypothèse qui doit être testée par rapport aux modèles d’utilisation réels et aux retours.
- Conception conceptuelle : Concentrez-vous sur les entités et les relations de haut niveau. Ignorez les détails techniques tels que les types de données.
- Conception logique : Ajoutez des attributs, définissez les types de données et établissez les clés. Normalisez la structure.
- Conception physique :Optimisez pour le moteur de base de données spécifique. Prenez en compte les stratégies d’indexation, le partitionnement et le stockage.
- Revue :Validez le modèle avec les parties prenantes. Assurez-vous qu’il soutient la croissance future de l’entreprise.
Pendant la phase de revue, il est fréquent de constater qu’une relation a été mal comprise. Par exemple, une Nombreux-à-nombreux relation pourrait en réalité être une hiérarchie ou une chaîne de Un-à-nombreux relations une fois des questions plus approfondies posées. La flexibilité pendant la phase de conception permet d’économiser un effort considérable pendant la phase d’implémentation.
📈 Montée en charge et évolution
Les schémas évoluent. Les exigences changent. Ce qui convient aujourd’hui peut ne pas convenir demain. Un schéma ER bien conçu anticipe la croissance.
- Extensibilité :Évitez de coder en dur des fonctionnalités spécifiques dans le schéma. Utilisez des tables génériques ou des modèles d’attributs (comme EAV) lorsque cela est approprié pour des exigences hautement dynamiques.
- Gestion des versions :Suivez les modifications du schéma. Les scripts de migration doivent être gérés sous version, aux côtés du code de l’application.
- Documentation : Le diagramme est la documentation. Si le diagramme ne correspond pas à la base de données, faites confiance à la base de données, mais mettez à jour le diagramme immédiatement.
🔍 Conclusion sur l’intégrité structurelle
La qualité d’un schéma de base de données influence directement la fiabilité des applications qui en dépendent. Un diagramme ER est bien plus qu’un dessin ; c’est un contrat entre la logique métier et l’infrastructure technique. En cartographiant rigoureusement les règles métier vers des schémas techniques, en assurant une normalisation adéquate et en maintenant des contraintes d’intégrité strictes, nous construisons des systèmes résilients et efficaces.
Concentrez-vous sur la clarté de vos diagrammes. Utilisez une notation standard pour garantir que tout ingénieur peut lire la conception. Priorisez l’intégrité des données plutôt que les gains de performance à court terme, car corriger les problèmes d’intégrité plus tard est bien plus coûteux que d’optimiser les requêtes dès le départ. L’objectif est un schéma qui soutient l’entreprise aujourd’hui et peut s’adapter à ses évolutions futures.

