











Wenn Organisationen von monolithischen Architekturen zu Microservices wechseln, wird der Ansatz der Datenmodellierung oft zu einem Streitpunkt. Jahrzehntelang diente das Entity-Relationship-Diagramm (ERD) als Bauplan für die Datenbankgestaltung in zentralisierten Systemen. Es zeichnete Tabellen, Spalten, Schlüssel und Beziehungen präzise auf. Doch die verteilte Natur von Microservices stellt diese traditionellen Konventionen in Frage. Die Annahme, dass ein einheitlicher, gemeinsamer Schema über das gesamte System hinweg gilt, ist eine anhaltende Verwechslung, die zu engen Kopplungen und betrieblicher Fragilität führen kann.
Dieser Leitfaden untersucht die verbreiteten Überzeugungen rund um ER-Diagramme in verteilten Umgebungen. Er trennt Fakt von Fiktion und konzentriert sich darauf, wie Daten-Grenzen definiert werden sollten, wie Beziehungen ohne gemeinsame Tabellen verwaltet werden und warum die visuelle Darstellung von Daten sich ändern muss, wenn man zu einer serviceorientierten Architektur wechselt. Ziel ist es, ein klares Verständnis der Datenmodellierungsprinzipien zu vermitteln, die Skalierbarkeit und Widerstandsfähigkeit unterstützen.
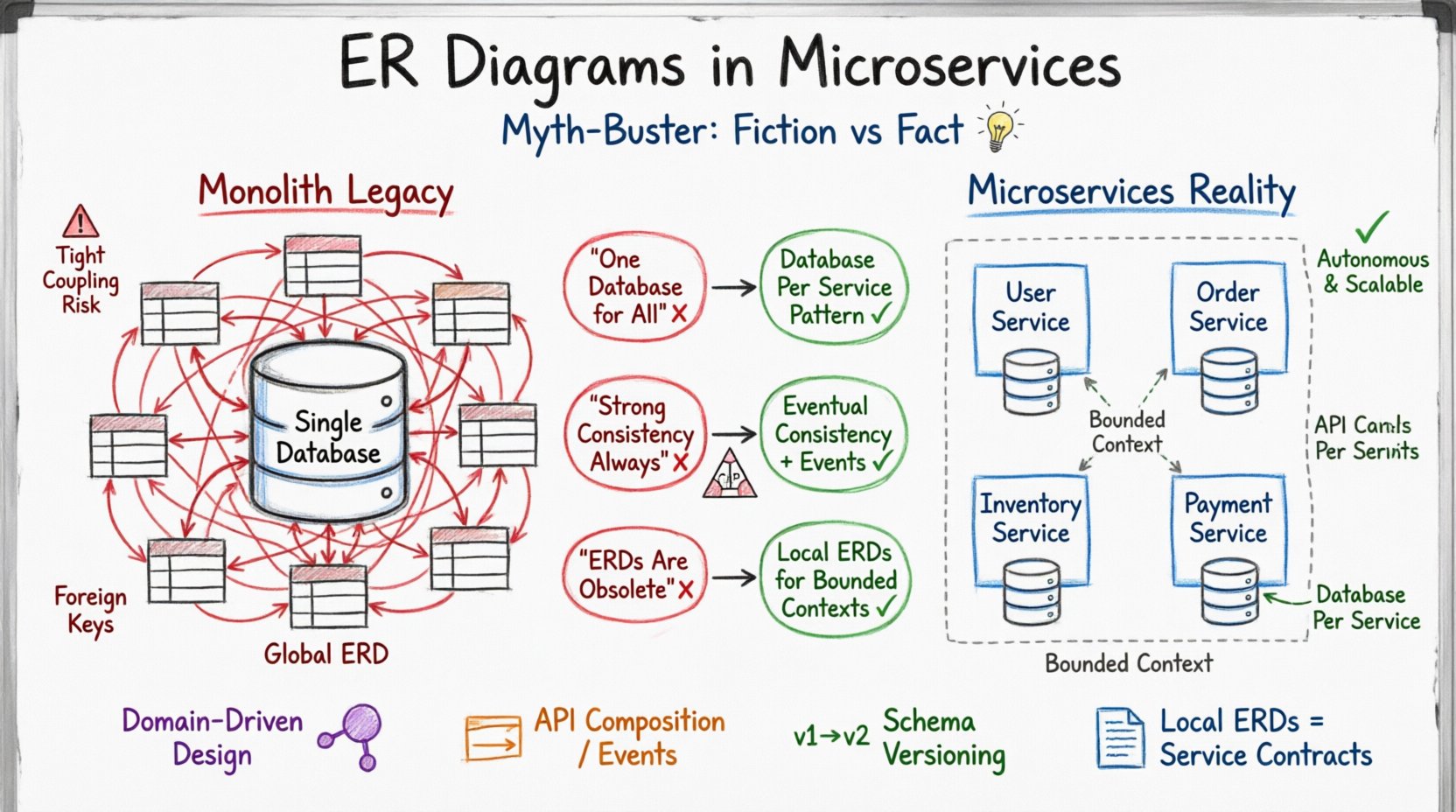
Das Erbe des Monoliths: Warum alte ERDs nicht passen 🏛️
In einer traditionellen monolithischen Anwendung fungiert die Datenbank als zentrale Quelle der Wahrheit. Alle Anwendungslogik interagiert mit einem einzigen Schema. Diese Umgebung begünstigt ein umfassendes ER-Diagramm, das jedes Entität und jede Beziehung abbildet. Designer können auf Fremdschlüssel vertrauen, um die Referenzintegrität über das gesamte System hinweg zu gewährleisten. Transaktionen erstrecken sich über mehrere Tabellen innerhalb derselben Datenbankinstanz und stellen sicher, dass die ACID-Eigenschaften (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) global gewährleistet sind.
Wenn dieser Denkansatz auf Microservices angewendet wird, entsteht Widerstand. Microservices sind darauf ausgelegt, autark zu sein. Jeder Dienst verwaltet seine eigene Datenspeicherungsschicht. Das bedeutet, dass zwischen Diensten keine gemeinsame Datenbank existiert. Wenn ein Dienst seine Daten besitzt, kann ein anderer Dienst diese nicht direkt über Standard-SQL-Joins abfragen. Das ER-Diagramm muss sich daher von einer systemweiten Karte zu einer Sammlung von domänenspezifischen Schemata verlagern.
- Zentralisierte Kontrolle: Monolithen ermöglichen es einem DBA, das gesamte Schema zu verwalten.
- Verteilte Eigentümerschaft: Microservices erfordern, dass jedes Team seine Schema-Definition verantwortet.
- Globale Transaktionen: Monolithen unterstützen Einzeltransaktions-Updates über Tabellen hinweg.
- Verteilte Transaktionen: Microservices erfordern Koordinationsmuster wie Sagas oder eventual consistency.
Der erste Schritt bei der Modernisierung der Datenmodellierung besteht darin, anzuerkennen, dass ein einzelnes ERD, das die gesamte Anwendung abdeckt, nicht länger möglich oder wünschenswert ist. Stattdessen rückt das domain-driven Design in den Fokus, bei dem das Datenmodell mit den Geschäftsfähigkeiten jedes Dienstes übereinstimmt.
Mythos 1: Der „Eine-Datenbank“-Irrtum 🗄️❌
Eine verbreitete Überzeugung unter Architekten, die neu in verteilten Systemen sind, ist, dass sie eine einzelne physische Datenbank beibehalten können, während sie die Daten logisch durch Schema-Präfixe oder getrennte Tabellen trennen. Dieser Ansatz wird oft als „geteilte Datenbank“-Anti-Pattern bezeichnet. Obwohl er die ursprüngliche Gestaltung zu vereinfachen scheint, führt er bei wachsenden Systemen zu erheblichen Risiken.
Warum geteilte Datenbanken scheitern
Selbst wenn Dienste keinen Code teilen, führt das Teilen einer Datenbank-Instanz zu einer physischen Kopplung. Wenn ein Dienst eine Schema-Migration erfordert, die Leistung oder Verfügbarkeit beeinträchtigt, sind alle anderen Dienste, die diese Datenbank teilen, betroffen. Dies verstößt gegen das zentrale Prinzip der Unabhängigkeit in Microservices.
- Bereitstellungssperre: Eine riskante Migration für Dienst A könnte verhindern, dass Dienst B bereitgestellt wird.
- Ressourcenkonkurrenz: Schwere Abfragen von einem Dienst können die Leistung anderer beeinträchtigen.
- Sicherheitsrisiken: Ein kompromittierter Dienst könnte potenziell auf Daten eines anderen Dienstes zugreifen.
- Technologielock-in: Wenn Dienst A eine andere Datenbank-Engine benötigt als Dienst B, können sie in einer gemeinsamen Umgebung nicht koexistieren.
Die Lösung ist das Muster „Datenbank pro Dienst“. Jeder Dienst stellt seine eigene Datenbank bereit. Dadurch wird sichergestellt, dass Schema-Änderungen isoliert bleiben. Das ER-Diagramm für Dienst A sollte nur die Datenentitäten widerspiegeln, die von Dienst A benötigt werden, nicht das globale System.
Mythos 2: Starke Konsistenz ist immer erforderlich ⚖️
In einer monolithischen Umgebung ist die ACID-Konformität die Norm. Entwickler erwarten, dass, sobald eine Transaktion commitiert ist, die Daten sofort konsistent über das gesamte System hinweg sind. In Microservices ist diese Erwartung oft unrealistisch. Der CAP-Satz besagt, dass ein verteiltes System nur zwei von drei Eigenschaften garantieren kann: Konsistenz, Verfügbarkeit und Partitionstoleranz.
Verständnis verteilter Konsistenz
Wenn Dienste über ein Netzwerk kommunizieren, sind Latenz und mögliche Ausfälle unvermeidbar. Versuche, starke Konsistenz über Dienstgrenzen hinweg durchzusetzen, führen oft zu hoher Latenz oder Systemunzugänglichkeit. Stattdessen übernehmen viele Systeme die spätere Konsistenz. Das bedeutet, dass Daten zwischen Diensten vorübergehend inkonsistent sein können, sich aber im Laufe der Zeit ausgleichen werden.
- Starke Konsistenz:Daten werden überall sofort aktualisiert. Gut für Bankgeschäfte, aber hohe Latenz.
- Eventuelle Konsistenz:Daten werden asynchron propagiert. Gut für Benutzerprofile, Bestandszahlen.
- Grundlegende Verfügbarkeit:Das System bleibt auch während Netzwerkpartitionen betriebsbereit.
Das ER-Diagramm in einem Microservice stellt die Beziehungen in der Regel nicht dar, die sofortige Sperrung erfordern. Stattdessen zeigt es den Zustand der Daten an, die lokal konsistent sind. Querverbindungen zwischen Diensten werden über Ereignisse oder API-Aufrufe, nicht über Datenbank-Fremdschlüssel, behandelt.
Mythos 3: ER-Diagramme sind in verteilten Systemen veraltet 📉
Einige Praktiker argumentieren, dass aufgrund der Datenentkopplung durch Microservices das Konzept eines ERD nicht mehr notwendig sei. Das ist falsch. Während ein globales ERD veraltet ist, sind lokale ERDs wichtiger denn je. Ohne klare Dokumentation der Datenstruktur innerhalb eines Dienstes steigt das Risiko von Datenabweichungen und Integrationsfehlern erheblich.
Die Rolle des lokalen ERD
Ein ERD im Kontext eines Microservices erfüllt eine andere Funktion als in einer Monolith-Architektur. Er definiert den begrenzten Kontext. Er stellt sicher, dass der Dienst genau weiß, welche Daten er besitzt und wie diese intern strukturiert sind. Er muss keine Beziehungen zu externen Diensten darstellen.
- Dokumentation:Er fungiert als Vertrag für das interne Datenmodell.
- Kommunikation:Er hilft Entwicklern, die Domänenentitäten zu verstehen, ohne externe Abhängigkeiten kennen zu müssen.
- Wartung:Er vereinfacht die Einarbeitung neuer Teammitglieder in den jeweiligen Dienst.
- Validierung:Er hilft, zirkuläre Abhängigkeiten in der Entwurfsphase zu erkennen.
Das Diagramm sollte sich auf Entitäten, Attribute und Primärschlüssel konzentrieren. Fremdschlüssel, die auf externe Dienste verweisen, sollten entfernt oder als Identifikatoren abstrahiert werden, nicht als direkte Tabellenverknüpfungen.
Best Practices für die Datenmodellierung in Microservices 🛠️
Um ein robustes System zu bauen, müssen Teams spezifische Modellierungsstrategien übernehmen, die mit den Prinzipien verteilter Architekturen übereinstimmen. Diese Praktiken stellen sicher, dass Dienste unabhängig bleiben, während sie dennoch zusammenarbeiten, um eine konsistente Benutzererfahrung zu bieten.
1. Domain-Driven Design (DDD)
Die Ausrichtung des Datenbank-Schemas am Domänenmodell ist entscheidend. Jeder Dienst sollte eine spezifische Geschäftsfähigkeit darstellen. Zum Beispiel sollte ein „Benutzerdienst“ keine Bestelldetails speichern. Ein „Bestelldienst“ sollte keine Benutzer-Authentifizierungstoken speichern. Diese Trennung stellt sicher, dass das ERD die Geschäftslogik widerspiegelt und nicht technische Bequemlichkeit.
- Definieren Sie Aggregatgruppen basierend auf transaktionalen Grenzen.
- Halten Sie das ERD auf die Verantwortung des Dienstes fokussiert.
- Vermeiden Sie das Erstellen von Modellen, die mehrere Geschäftsdomänen umfassen.
2. Behandlung von Beziehungen über Grenzen hinweg
Wenn Dienst A Daten benötigt, die von Dienst B besessen werden, sollte er nicht direkt auf die Datenbank von Dienst B zugreifen. Stattdessen sollte er eines der folgenden Muster verwenden:
- API-Zusammensetzung:Dienst A ruft die API von Dienst B auf, um die erforderlichen Daten abzurufen.
- Eventuelle Replikation:Dienst A hält eine Kopie der erforderlichen Daten in seiner eigenen Datenbank aufrecht, die über Ereignisse aktualisiert wird.
- Verknüpfung über Lese-Modell:Ein spezialisierter Lese-Dienst fasst Daten aus mehreren Quellen zusammen, um die Abfrage-Optimierung zu ermöglichen.
3. Schema-Versionierung
In einem verteilten System entwickeln sich Dienste mit unterschiedlichen Geschwindigkeiten. Eine Änderung im Schema eines Dienstes sollte den Verbraucher dieses Dienstes nicht brechen. Die Implementierung von Schema-Versionierung ermöglicht rückwärtskompatible Änderungen.
- Verwenden Sie versionierte Endpunkte für API-Verträge.
- Erlauben Sie mehrere Versionen eines Daten-Schemas, während der Migration nebeneinander zu existieren.
- Veralten Sie alte Schema-Versionen schrittweise, anstatt sofortige Aktualisierungen zu erzwingen.
Vergleich: Monolith vs. Mikroservice-Datenarchitektur 📊
Um die Unterschiede zu klären, zeigt die folgende Tabelle die wesentlichen Unterschiede im Datenmodell zwischen zentralisierten und verteilten Architekturen auf.
| Funktion | Monolithische Architektur | Mikroservice-Architektur |
|---|---|---|
| Daten-Speicherung | Einzelne Datenbank-Instanz | Datenbank pro Dienst |
| ER-Diagramm-Umfang | Globale Systemansicht | Dienst-spezifische Ansicht |
| Beziehungen | Fremdschlüssel (SQL-Joins) | API-Aufrufe oder Ereignisse |
| Konsistenzmodell | Starke Konsistenz (ACID) | Eventuelle Konsistenz (BASE) |
| Bereitstellung | Monolithische Bereitstellung | Unabhängige Dienstbereitstellung |
| Schemaänderungen | Zentralisierte Migration | Wird vom Dienstteam betrieben |
| Abfragen | Direktes SQL | Lesemodelle / CQRS |
Verwaltung von Datenbeziehungen über Grenzen hinweg 🔗
Einer der schwierigsten Aspekte von Microservices ist die Verwaltung von Datenbeziehungen. In einem Monolithen stellt ein Fremdschlüssel sicher, dass eine Bestellung einem Benutzer gehört. In Microservices befindet sich die Tabelle „Benutzer“ im Benutzerdienst und die Tabelle „Bestellung“ im Bestelldienst. Der Bestelldienst kann keinen Fremdschlüssel auf die Datenbank des Benutzerdienstes haben.
Muster für Referenzintegrität
Um die Referenzintegrität ohne gemeinsame Tabellen aufrechtzuerhalten, können Teams spezifische Muster verwenden:
- Logische Referenzen: Speichern Sie die Benutzer-ID als Zeichenkette oder Zahl, überprüfen Sie jedoch die Existenz über eine API-Aufruf bei der Erstellung.
- Datenbanktrigger: Nicht empfohlen über Dienste hinweg, aber innerhalb eines Dienstes gültig.
- Validierungsereignisse: Der Benutzerdienst veröffentlicht ein „Benutzer erstellt“-Ereignis. Der Bestelldienst verarbeitet dieses Ereignis, um die Beziehung zu bestätigen.
Das Problem von Joins
Joins über Dienstgrenzen hinweg sind ein Leistungsengpass. Sie führen zu Netzwerklatenz und potenziellen Ausfallpunkten. Wenn der Benutzerdienst ausgefallen ist, kann der Bestelldienst die Bestelldetails nicht abrufen, wenn er auf einen Join angewiesen ist. Stattdessen sollte der Bestelldienst die erforderlichen Benutzerdaten (wie Name) bei der Bestellungsanlage redundant speichern. Dies ist ein Kompromiss zwischen Normalisierung und Verfügbarkeit.
Schema-Evolution und Versionierung 🔄
Die Schema-Evolution ist unvermeidlich. Wenn sich die Geschäftsanforderungen ändern, müssen die Datenstrukturen sich anpassen. In einer Microservices-Umgebung ist die Änderung eines Schemas komplexer, da mehrere Dienste von der Datenstruktur eines anderen abhängen können.
Strategien für die Evolution
- Additive Änderungen:Das Hinzufügen einer neuen Spalte ist im Allgemeinen sicher, wenn die Anwendung fehlende Felder reibungslos behandelt.
- Entfernung von Feldern: Dies erfordert eine Ablaufphase, in der das Feld ausgeblendet, aber weiterhin vorhanden ist, und später entfernt wird.
- Typänderungen: Die Änderung eines Datentyps (z. B. String zu Integer) erfordert eine koordinierte Migrierungsstrategie.
Die Verwendung eines Schema-Registries kann bei der Verwaltung dieser Änderungen helfen. Er fungiert als zentrale Quelle der Wahrheit für die Struktur der zwischen Diensten ausgetauschten Daten und stellt sicher, dass Produzenten und Verbraucher sich auf das Format einigen.
Häufige Fehler, die vermieden werden sollten 🚧
Selbst mit einem soliden Verständnis der Prinzipien geraten Teams oft in Fallen während der Umsetzung. Die frühzeitige Erkennung dieser Fehler kann erhebliche technische Schulden vermeiden.
- Über-Normalisierung:Der Versuch, eine einheitliche Quelle der Wahrheit über alle Dienste hinweg aufrechtzuerhalten, führt zu komplexen verteilten Transaktionen. Akzeptieren Sie Redundanz dort, wo sie notwendig ist.
- Ignorieren der Idempotenz:Netzwerkaufrufe können fehlschlagen oder wiederholt werden. Datenvorgänge müssen so gestaltet sein, dass sie doppelte Anfragen verarbeiten können, ohne Doppelungen zu erzeugen.
- Überlastung durch Choreografie:Die alleinige Abhängigkeit von Ereignissen zur Datenkonsistenz kann unübersichtlich werden. Verwenden Sie Orchestrierung für komplexe Workflows.
- Unterschätzung der Latenz:Das Abrufen von Daten über Dienste hinweg fügt jeder Anfrage Millisekunden hinzu. Aggregieren Sie Daten lokal, wo immer möglich.
- Mangel an Dokumentation:Ohne klare ER-Diagramme für jeden Dienst wird die Integration zu einem Ratespiel.
Abschließende Gedanken zur architektonischen Klarheit 🧠
Der Übergang von monolithischer zu mikroservice-basierter Datenmodellierung erfordert eine Veränderung des Denkens. Es geht nicht nur darum, eine Datenbank in kleinere Teile zu zerlegen. Es geht vielmehr darum, neu zu definieren, wie Datenbesitz und -beziehungen konzeptualisiert werden. Das ER-Diagramm bleibt ein wichtiges Werkzeug, doch sein Geltungsbereich verengt sich auf die Dienstgrenze.
Durch die Vermeidung der Mythen von gemeinsam genutzten Datenbanken und globaler Konsistenz können Architekten Systeme schaffen, die widerstandsfähig und skalierbar sind. Der Schlüssel liegt darin, die Unabhängigkeit der Dienste gegenüber der Daten-Normalisierung zu priorisieren. Das bedeutet, dass man akzeptieren muss, dass bestimmte Daten dupliziert werden, um sicherzustellen, dass Dienste unabhängig funktionieren können. Es bedeutet auch, dass man versteht, dass starke Konsistenz eine Luxus-Eigenschaft ist, keine Voraussetzung für jeden Vorgang.
Beim Entwerfen der Datenarchitektur konzentrieren Sie sich auf das Domänenmodell. Lassen Sie die Geschäftsleistungen die Grenzen festlegen. Verwenden Sie ER-Diagramme, um den internen Zustand jedes Dienstes zu klären. Verwenden Sie Ereignisse und APIs, um die Verbindungen zwischen ihnen zu verwalten. Dieser Ansatz stellt sicher, dass das System sich weiterentwickeln kann, ohne die zugrundeliegende Datenintegrität zu gefährden.
Letztendlich geht es nicht darum, das Monolithen-Modell in verteilter Form zu replizieren. Es geht darum, ein System zu schaffen, in dem Daten mit derselben Flexibilität und Geschwindigkeit verwaltet werden wie der Code, der sie verarbeitet. Diese Balance ist die Grundlage einer erfolgreichen Mikroservices-Strategie.

