











Entitäts-Beziehungs-Diagramme (ERDs) werden von einigen oft als akademische Übungen oder Artefakte abgetan, die ausschließlich zur Dokumentationskonformität erstellt wurden. Für Senior-Entwickler und Architekten ist ein ER-Diagramm jedoch eine strategische Bauplanung, die Stabilität, Leistungsfähigkeit und Wartbarkeit der Datenebene einer Anwendung bestimmt. Die Herausforderung besteht nicht darin, Kästchen und Linien zu zeichnen, sondern darin, die Spannungen zwischen theoretischer Datenmodellierung und den unübersichtlichen Beschränkungen produktiver Umgebungen zu bewältigen.
Beim Aufbau von Systemen treffen Sie ständig Kompromisse. Ein vollständig normalisierter Schema gewährleistet die Datenintegrität, kann aber bei komplexen Abfragen Leistungseinbußen verursachen. Eine denormalisierte Struktur beschleunigt Lesevorgänge, führt aber zu Redundanz und Aktualisierungsanomalien. Das Ziel besteht darin, das Gleichgewicht zu finden, bei dem das Diagramm den Geschäftsdomänen genau entspricht, ohne bei der Bereitstellung zur Last zu werden.
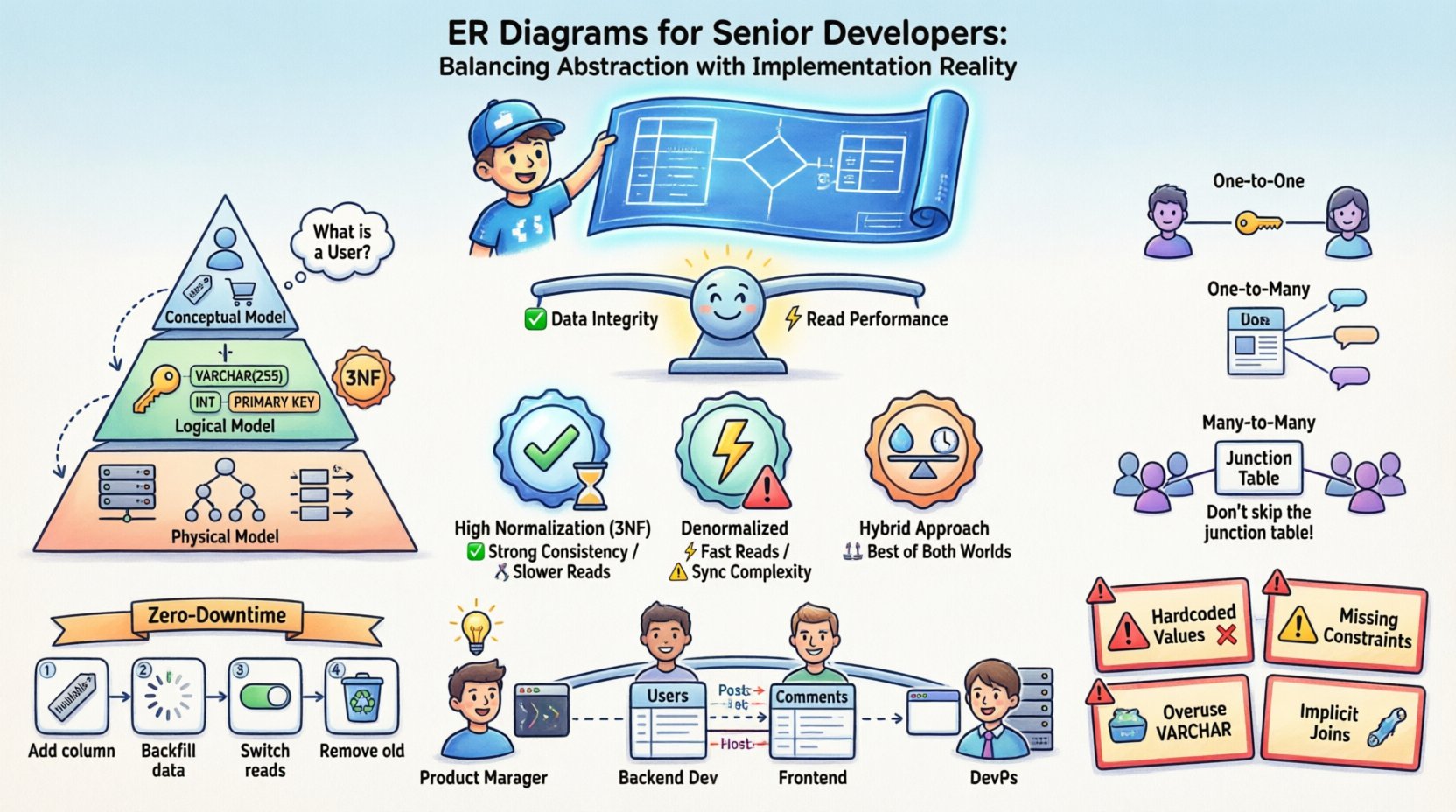
Die zweifache Natur von Entitäts-Beziehungs-Diagrammen 📐
solltensolltenaussehen sollten, und dem, was sie tatsächlichin Speicher aussehen.
- Konzeptuelles Modell: Diese Ebene konzentriert sich auf Geschäftsentitäten und ihre Beziehungen ohne technische Details. Sie beantwortet Fragen wie „Was ist ein Benutzer?“ und „Wie steht ein Benutzer zu einer Bestellung in Beziehung?“. Sie ist technologieunabhängig.
- Logisches Modell: Hier führen Sie Datentypen, Schlüssel und Normalisierungsregeln ein. Sie definieren Primär- und Fremdschlüssel, aber Sie verpflichten sich noch nicht zu einem bestimmten Speicher-Engine oder Indexstrategie eines Datenbank-Engines.
- Physisches Modell: Dies ist die Realität der Implementierung. Es umfasst Tabellennamen, Spaltendatentypen, Partitionierungsstrategien, Indizierung und Einschränkungen, die spezifisch für das Ziel-Datenbanksystem sind. Hier trifft die Theorie auf die Praxis.
Verwirrung entsteht oft, wenn diese Ebenen vermischt werden. Ein Senior-Entwickler weiß, dass im physischen Modell die Fehler lauern. Eine konzeptionelle Beziehung von „Viele-zu-Viele“ muss im physischen Modell in spezifische Fremdschlüsselbeschränkungen umgesetzt werden, was oft die Erstellung von Zwischentabellen erfordert, die im ursprünglichen Geschäftslogikmodell nicht existieren.
Abstraktionsebenen im Datenmodellieren 🧩
Die Verwaltung dieser Ebenen erfordert Disziplin. Wenn ein Stakeholder eine Funktion anfordert, beschreibt er sie in geschäftssprachlichen Begriffen. Der Entwickler muss dies in ein logisches Schema übersetzen und schließlich in ein physisches Schema. Das Überspringen dieser Schritte führt zu technischem Schulden.
1. Konzeptuelles Modellieren: Die Sprache des Geschäfts
In diesem Stadium ist das Diagramm ein Kommunikationsinstrument. Es stellt sicher, dass das Engineering-Team und das Produktteam sich auf das Domänenmodell einigen. Wenn das Diagramm zeigt, dass ein „Kunde“ mehrere „Adressen“ haben kann, stimmt jeder darauf ein, bevor eine einzige Zeile SQL geschrieben wird.
2. Logisches Modellieren: Die Regeln der Zusammenarbeit
Hier wenden Sie Normalisierungsregeln an. Sie entscheiden, dass ein „Kunde“ seine „Adresse“ nicht direkt speichern sollte, wenn diese Adresse häufig geändert wird und zu anderen Entitäten gehören könnte. Sie führen Normalisierung ein, um Redundanz zu reduzieren. Gleichzeitig identifizieren Sie jedoch Daten, die stark gelesen werden und möglicherweise später denormalisiert werden müssen.
3. Physisches Modellieren: Die Realität der Implementierung
Hier kommen die Beschränkungen der Datenbank-Engine ins Spiel. Sie müssen möglicherweise zwischen einer JSON-Spalte und einer separaten relationalen Tabelle für flexible Attribute wählen. Sie entscheiden sich für Indexstrategien basierend auf Abfragemustern. Sie könnten sich dafür entscheiden, eine bestimmte Speicher-Engine zu verwenden, die schnellere Schreibvorgänge, aber langsamere Lesevorgänge unterstützt.
Normalisierungsstrategien und Leistungsabwägungen ⚖️
Normalisierung ist ein grundlegendes Konzept im Datenbankdesign. Sie organisiert Daten, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. In hochskalierbaren Systemen kann jedoch eine strikte Einhaltung der Normalisierungsregeln zu einer Engstelle werden. Senior-Entwickler müssen verstehen, wann die Regeln gebrochen werden müssen.
Die Kosten der Normalisierung
Wenn Sie Daten normalisieren, erstellen Sie oft mehr Tabellen. Das bedeutet mehr Joins bei Abfragen. In einem verteilten System oder einer hochbelasteten Webanwendung ist jeder Join ein potenzieller Latenzpunkt. Wenn eine Tabelle partitioniert ist, kann das Verknüpfen über Partitionen kostspielig sein.
Wann man denormalisiert
Die Denormalisierung ist die bewusste Einführung von Redundanz, um die Leseleistung zu optimieren. Es ist kein Fehler, sondern eine strategische Entscheidung. Sie sollten die Denormalisierung in Betracht ziehen, wenn:
- Lesevorgänge überwiegen deutlich Schreibvorgänge.
- Komplexe Joins verursachen Timeouts oder hohe CPU-Auslastung.
- Sie erstellen eine Berichts- oder Analyseebene, bei der Echtzeitkonsistenz weniger kritisch ist.
- Sie müssen Daten de-normalisieren, um Caching-Ebenen zu erstellen und die Datenbanklast zu reduzieren.
Normalisierung im Vergleich zur Leistungsmatrix
| Strategie | Datenintegrität | Schreibleistung | Leseleistung | Wartbarkeit |
|---|---|---|---|---|
| Hohe Normalisierung (3NF) | Hoch | Schnell (geringer Redundanz) | Langsam (erfordert Joins) | Hoch (einfache Aktualisierungen) |
| De-normalisiert | Niedriger (manuelle Synchronisierung erforderlich) | Langsam (mehr Daten zum Schreiben) | Schneller (weniger Joins) | Niedriger (Risiko von Inkonsistenzen) |
| Hybrider Ansatz | Mäßig | Mäßig | Mäßig bis schnell | Mäßig (erfordert klare Logik) |
Das Verständnis dieser Matrix ermöglicht es Ihnen, fundierte Entscheidungen zu treffen. Sie normalisieren nicht einfach „alles“ oder „alles de-normalisieren“. Sie analysieren die spezifischen Zugriffsmuster Ihrer Anwendung.
Modellierung komplexer Beziehungen 🔗
Beziehungen sind das Herzstück eines ER-Diagramms. Sie definieren, wie Datenentitäten miteinander interagieren. Während Eins-zu-Eins- und Eins-zu-Viele-Beziehungen einfach sind, erfordern Viele-zu-Viele-Beziehungen oft sorgfältige Behandlung, um Skalierbarkeit zu gewährleisten.
Eins-zu-Eins-Beziehungen
Diese sind in der Praxis selten, existieren aber. Zum Beispiel ein Benutzerprofil und eine Tabelle mit Benutzerprofil-Einstellungen. Sie können dies durch Platzieren eines Fremdschlüssels in einer Tabelle oder durch Aufteilen der Daten in zwei Tabellen umsetzen. Die Entscheidung hängt von den Zugriffsmustern ab. Wenn Einstellungen häufig zusammen mit dem Profil abgerufen werden, sollten sie zusammenbleiben. Wenn sie selten abgerufen werden, sollten sie getrennt werden, um die Größe der Haupttabelle zu reduzieren.
Ein-zu-Viele-Beziehungen
Dies ist das häufigste Muster. Ein Blogbeitrag hat viele Kommentare. Der Fremdschlüssel befindet sich auf der „Viele“-Seite (Kommentare). Dies ist effizient für Abfragen, die alle Kommentare für einen bestimmten Beitrag abrufen.
Viele-zu-Viele-Beziehungen
Ein Benutzer kann viele Benutzer folgen, und ein Benutzer kann von vielen Benutzern gefolgt werden. Dazu ist eine Zwischentabelle erforderlich. Diese Tabelle enthält typischerweise die Fremdschlüssel beider Seiten sowie jegliche Metadaten, die spezifisch für die Beziehung sind, wie beispielsweise ein Zeitstempel, wann die Verbindung hergestellt wurde.
- Überspringen Sie die Zwischentabelle nicht: Es ermöglicht Ihnen, die Beziehung zu indizieren und effizient abzufragen.
- Berücksichtigen Sie zusammengesetzte Schlüssel: Der Primärschlüssel der Zwischentabelle könnte eine Kombination der beiden Fremdschlüssel sein.
- Achten Sie auf die Kardinalität: Stellen Sie sicher, dass Sie Fälle behandeln, in denen die Beziehung optional ist im Gegensatz zu obligatorisch.
Schema-Evolution und Migration 🔄
Einer der schwierigsten Aspekte, ein Senior-Entwickler zu sein, ist die Erkenntnis, dass das ER-Diagramm niemals abgeschlossen ist. Anforderungen ändern sich, Geschäftslogik verschiebt sich und Daten wachsen. Ihr Schema muss sich entwickeln, ohne bestehende Funktionalität zu brechen.
Versionierung des Schemas
Gehen Sie niemals davon aus, dass eine Migration ein einmaliger Vorgang ist. Behandeln Sie Ihr Schema wie Code. Verwenden Sie Versionskontrolle für Ihre Migrations-Skripte. Dadurch können Sie Änderungen rückgängig machen, falls eine neue Spalte ein Problem verursacht. Es bietet außerdem eine Prüfungs- und Nachverfolgungsspur, wie sich die Datenstruktur im Laufe der Zeit verändert hat.
Downtime-freie Migrationen
Für Produktivsysteme ist Downtime oft unakzeptabel. Dies erfordert einen schrittweisen Ansatz für Schemaänderungen:
- Fügen Sie zuerst Spalten hinzu: Fügen Sie die neue Spalte als nullable hinzu. Stellen Sie den Code bereit, der in sie schreibt.
- Füllen Sie die Daten nach: Führen Sie eine Hintergrundaufgabe aus, um die neue Spalte zu füllen.
- Wechseln Sie die Leseoperationen: Aktualisieren Sie die Anwendung, um von der neuen Spalte zu lesen.
- Entfernen Sie alte Spalten: Sobald das System stabil ist, löschen Sie die alte Spalte.
Umgang mit Sperrungen
Das Hinzufügen eines Indexes oder einer Einschränkung auf einer großen Tabelle kann die Tabelle sperren und das Schreiben stoppen. Sie müssen Online-Schema-Änderungswerkzeuge oder Partitionierungsstrategien verwenden, um die Sperrdauer zu minimieren. Das Verständnis der Sperrmechanismen der zugrundeliegenden Datenbankengine ist hier entscheidend.
Häufige Fallen in Produktionsumgebungen 🚧
Sogar erfahrene Entwickler machen Fehler, wenn sie ERDs in SQL übersetzen. Die Kenntnis häufiger Fallen hilft Ihnen, sie zu vermeiden, bevor sie zu kritischen Problemen werden.
- Hartkodierte Werte: Vermeiden Sie es, `INT`-Spalten ohne explizite Einschränkungen zu verwenden, um boolesche Flags (0/1) zu speichern. Verwenden Sie `BOOLEAN`-Typen oder aufzählbare Typen, wenn unterstützt.
- Fehlende Einschränkungen:Es ist riskant, sich allein auf die Anwendungslogik zur Durchsetzung von Fremdschlüsseln zu verlassen. Wenn ein Fehler einen ungültigen Einfügungsvorgang zulässt, ist die Datenintegrität beschädigt. Setzen Sie Einschränkungen auf Datenbankebene durch.
- Übermäßiger Einsatz von VARCHAR:Obwohl `VARCHAR` flexibel ist, kann es für bestimmte Daten langsamer sein als feste Längentypen wie `CHAR`. Verwenden Sie `CHAR` für Daten mit fester Länge, wie z. B. UUIDs oder Postleitzahlen.
- Ignorieren von Zeichensätzen:Wenn Ihre Anwendung internationale Zeichen unterstützt, stellen Sie sicher, dass Ihre Datenbank und Tabellen von Anfang an UTF-8 unterstützen. Eine Änderung hierzu später ist schwierig.
- Implizite Verknüpfungen:Vermeiden Sie Abfragen, die Tabellen ohne explizite Indizes verknüpfen. Überprüfen Sie immer den Abfrageausführungsplan.
Kommunikation zwischen Teams 🤝
Ein ER-Diagramm ist ein Kommunikationswerkzeug. Es schließt die Lücke zwischen Datenbankadministratoren, Backend-Entwicklern, Frontend-Entwicklern und Produktmanagern. Ein klares Diagramm verhindert Annahmen.
- Für Produktmanager:Es hilft ihnen, die Datenanforderungen für eine Feature-Anfrage zu verstehen.
- Für Frontend-Entwickler:Es klärt die Struktur der Daten, die sie von APIs erhalten werden.
- Für DevOps:Es informiert über die Kapazitätsplanung und Backup-Strategien.
Wenn das Diagramm unklar ist, wird das Team raten. Raten führt zu Fehlern. Ein Senior-Entwickler stellt sicher, dass das Diagramm genau, aktuell und für alle Beteiligten im Projektzyklus zugänglich ist.
Werkzeuge vs. Denken 💡
Es gibt viele Werkzeuge, um ER-Diagramme zu zeichnen. Obwohl sie zur Visualisierung nützlich sind, sollten sie nicht kritisches Denken ersetzen. Ein Werkzeug kann SQL aus einem Diagramm generieren, kann aber nicht das Geschäftslogik hinter der Existenz einer Beziehung verstehen.
- Fokus auf Logik:Verbringen Sie mehr Zeit am Whiteboard oder in Texteditoren, um das Modell zu diskutieren, als auf Knöpfe in einem Zeichenwerkzeug zu klicken.
- Validieren Sie mit SQL:Sobald das Diagramm gezeichnet ist, schreiben Sie die SQL-Anweisungen. Wenn die SQL-Anweisungen verwirrend sind, ist das Diagramm wahrscheinlich fehlerhaft.
- Halten Sie es einfach:Übertreiben Sie das Diagramm nicht. Wenn eine Beziehung erschlossen werden kann, erzwingen Sie keine komplexe Struktur.
Abschließende Gedanken zur Datenmodellierung 🏁
Ein robustes Datenebenenmodell ist eine Balance aus Theorie und Praxis. Ein ER-Diagramm ist nicht nur ein Bild; es ist ein Vertrag zwischen Ihrer Anwendung und Ihren Daten. Wenn Sie die Abstraktionsebenen respektieren, die Abwägungen zwischen Normalisierung und Leistung verstehen und von Anfang an für die Entwicklung planen, schaffen Sie Systeme, die widerstandsfähig und skalierbar sind.
Die effektivsten Senior-Entwickler sind jene, die auf ein Kasten-und-Linien-Diagramm blicken und sofort potenzielle Abfragen, wahrscheinliche Engpässe und den Migrationsweg erkennen. Sie zeichnen nicht nur Linien; sie gestalten Systeme. Indem Sie sich auf diese Prinzipien konzentrieren, stellen Sie sicher, dass Ihre Datenarchitektur Ihre Geschäftsziele unterstützt, ohne zu einer Belastung zu werden.

