











When organizations transition from monolithic architectures to microservices, the approach to data modeling often becomes a point of significant contention. For decades, the Entity-Relationship Diagram (ERD) served as the blueprint for database design in centralized systems. It mapped tables, columns, keys, and relationships with precision. However, the distributed nature of microservices challenges these traditional conventions. The assumption that a single, unified schema applies across the entire system is a persistent misconception that can lead to tight coupling and operational fragility.
This guide examines the common beliefs surrounding ER diagrams in distributed environments. It separates fact from fiction, focusing on how data boundaries should be defined, how relationships are managed without shared tables, and why the visual representation of data needs to change when moving to a service-oriented architecture. The goal is to provide a clear understanding of data modeling principles that support scalability and resilience.
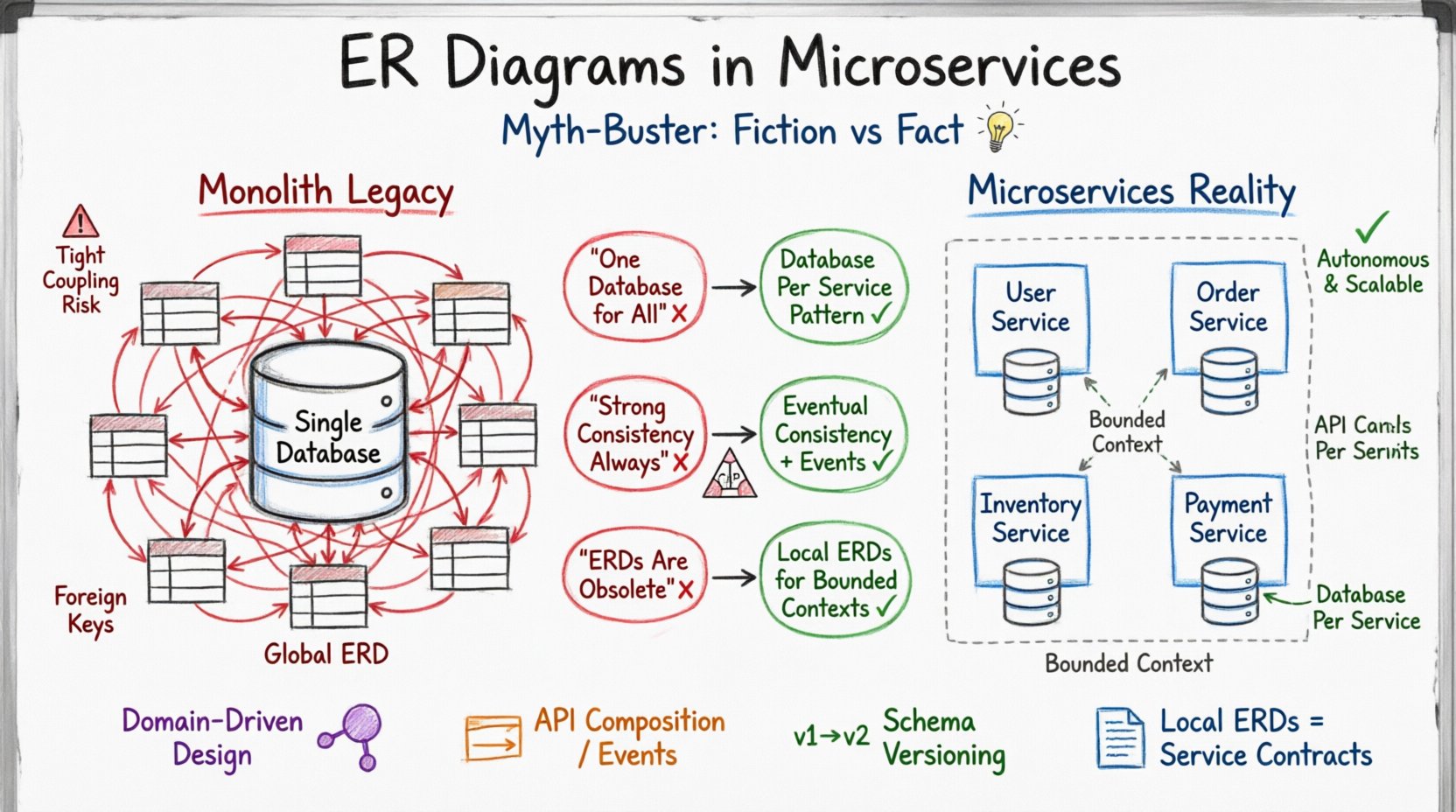
The Monolith Legacy: Why Old ERDs Don’t Fit 🏛️
In a traditional monolithic application, the database acts as the central source of truth. All application logic interacts with a single schema. This environment favors a comprehensive ER diagram that maps every entity and relationship. Designers can rely on foreign keys to enforce referential integrity across the entire system. Transactions span multiple tables within the same database instance, ensuring ACID properties (Atomicity, Consistency, Isolation, Durability) are maintained globally.
When this mindset is applied to microservices, friction arises. Microservices are designed to be autonomous. Each service manages its own data persistence layer. This means there is no shared database between services. If a service owns its data, another service cannot directly query it using standard SQL joins. The ERD must therefore shift from a system-wide map to a collection of domain-specific schemas.
- Centralized Control: Monoliths allow a DBA to manage the entire schema.
- Distributed Ownership: Microservices require each team to own their schema definition.
- Global Transactions: Monoliths support single-transaction updates across tables.
- Distributed Transactions: Microservices require coordination patterns like Sagas or eventual consistency.
The first step in modernizing data modeling is accepting that a single ERD spanning the entire application is no longer feasible or desirable. Instead, the focus moves to domain-driven design, where the data model aligns with the business capabilities of each service.
Myth 1: The “One Database” Fallacy 🗄️❌
A common belief among architects new to distributed systems is that they can maintain a single physical database while logically separating data using schema prefixes or distinct tables. This approach is often referred to as the “shared database” anti-pattern. While it appears to simplify the initial design, it introduces significant risks as the system grows.
Why Shared Databases Fail
Even if services do not share code, sharing a database instance creates a physical coupling. If one service requires a schema migration that impacts performance or availability, all other services sharing that database are affected. This violates the core principle of independence in microservices.
- Deployment Blocking: A risky migration for Service A might prevent Service B from deploying.
- Resource Contention: Heavy queries from one service can degrade performance for others.
- Security Risks: One compromised service could potentially access data belonging to another service.
- Technology Lock-in: If Service A needs a different database engine than Service B, they cannot coexist in a shared environment.
The solution is the Database Per Service pattern. Each service provisions its own database. This ensures that schema changes are isolated. The ER diagram for Service A should only reflect the data entities required by Service A, not the global system.
Myth 2: Strong Consistency is Always Required ⚖️
In a monolithic environment, ACID compliance is the standard. Developers expect that once a transaction commits, the data is immediately consistent across the entire system. In microservices, this expectation is often unrealistic. The CAP theorem dictates that a distributed system can only guarantee two out of three properties: Consistency, Availability, and Partition Tolerance.
Understanding Distributed Consistency
When services communicate over a network, latency and potential failures are inevitable. Attempting to enforce strong consistency across service boundaries often leads to high latency or system unavailability. Instead, many systems adopt eventual consistency. This means data may be temporarily inconsistent between services but will converge over time.
- Strong Consistency: Data is updated everywhere immediately. Good for banking, but high latency.
- Eventual Consistency: Data propagates asynchronously. Good for user profiles, inventory counts.
- Base Availability: The system remains operational even during network partitions.
The ER diagram in a microservice does not typically represent relationships that require immediate locking. Instead, it represents the state of data that is locally consistent. Cross-service relationships are handled through events or API calls, not database foreign keys.
Myth 3: ER Diagrams Are Obsolete in Distributed Systems 📉
Some practitioners argue that because microservices decouple data, the concept of an ERD is no longer necessary. This is incorrect. While a global ERD is obsolete, local ERDs are more critical than ever. Without clear documentation of the data structure within a service, the risk of data drift and integration errors increases significantly.
The Role of the Local ERD
An ERD within a microservice context serves a different purpose than in a monolith. It defines the bounded context. It ensures that the service knows exactly what data it owns and how that data is structured internally. It does not need to show relationships to external services.
- Documentation: It acts as a contract for the internal data model.
- Communication: It helps developers understand the domain entities without needing to know external dependencies.
- Maintenance: It simplifies onboarding new team members to the specific service.
- Validation: It helps identify circular dependencies during the design phase.
The diagram should focus on entities, attributes, and primary keys. Foreign keys referencing external services should be removed or abstracted as identifiers, not direct table links.
Best Practices for Data Modeling in Microservices 🛠️
To build a robust system, teams must adopt specific modeling strategies that align with distributed architecture principles. These practices ensure that services remain independent while still cooperating to provide a coherent user experience.
1. Domain-Driven Design (DDD)
Aligning the database schema with the domain model is essential. Each service should represent a specific business capability. For example, a “User Service” should not store order details. An “Order Service” should not store user authentication tokens. This separation ensures that the ERD reflects business logic rather than technical convenience.
- Define aggregates based on transactional boundaries.
- Keep the ERD focused on the service’s responsibility.
- Avoid creating models that span multiple business domains.
2. Handling Relationships Across Boundaries
When Service A needs data owned by Service B, it should not query Service B’s database directly. Instead, it should use one of the following patterns:
- API Composition: Service A calls Service B’s API to retrieve the necessary data.
- Eventual Replication: Service A maintains a copy of the necessary data in its own database, updated via events.
- Join via Read Model: A dedicated read service aggregates data from multiple sources for query optimization.
3. Schema Versioning
In a distributed system, services evolve at different speeds. A change in the schema of one service should not break the consumer of that service. Implementing schema versioning allows for backward compatibility.
- Use versioned endpoints for API contracts.
- Allow multiple versions of a data schema to coexist during migration.
- Deprecate old schema versions gradually rather than forcing immediate updates.
Comparison: Monolith vs. Microservice Data Architecture 📊
To clarify the differences, the following table outlines the key distinctions between data modeling in centralized versus distributed architectures.
| Feature | Monolithic Architecture | Microservices Architecture |
|---|---|---|
| Data Storage | Single Database Instance | Database Per Service |
| ER Diagram Scope | Global System View | Service-Specific View |
| Relationships | Foreign Keys (SQL Joins) | API Calls or Events |
| Consistency Model | Strong Consistency (ACID) | Eventual Consistency (BASE) |
| Deployment | Monolithic Deployment | Independent Service Deployment |
| Schema Changes | Centralized Migration | Owned by Service Team |
| Querying | Direct SQL | Read Models / CQRS |
Handling Data Relationships Across Boundaries 🔗
One of the most difficult aspects of microservices is managing data relationships. In a monolith, a foreign key ensures that an Order belongs to a User. In microservices, the “User” table resides in the User Service, and the “Order” table resides in the Order Service. The Order Service cannot hold a foreign key to the User Service’s database.
Referential Integrity Patterns
To maintain referential integrity without shared tables, teams can use specific patterns:
- Logical References: Store the User ID as a string or number, but validate existence via API call during creation.
- Database Triggers: Not recommended across services, but valid within a service.
- Validation Events: The User Service publishes a “User Created” event. The Order Service consumes this to acknowledge the relationship.
The Problem of Joins
Joins across service boundaries are a performance bottleneck. They introduce network latency and potential points of failure. If the User Service is down, the Order Service cannot retrieve order details if it relies on a join. Instead, the Order Service should store the necessary user details (like Name) redundantly at the time of order creation. This is a trade-off between normalization and availability.
Schema Evolution and Versioning 🔄
Schema evolution is inevitable. As business requirements change, data structures must adapt. In a microservices environment, changing a schema is more complex because multiple services may depend on the data structure of another.
Strategies for Evolution
- Additive Changes: Adding a new column is generally safe if the application handles missing fields gracefully.
- Removal of Fields: This requires a deprecation period where the field is hidden but still present, then removed later.
- Type Changes: Changing a data type (e.g., String to Integer) requires a coordinated migration strategy.
Using a schema registry can help manage these changes. It acts as a central source of truth for the structure of data being exchanged between services, ensuring that producers and consumers agree on the format.
Common Pitfalls to Avoid 🚧
Even with a solid understanding of the principles, teams often fall into traps during implementation. Identifying these pitfalls early can save significant technical debt.
- Over-Normalization: Trying to maintain a single source of truth across all services leads to complex distributed transactions. Embrace redundancy where necessary.
- Ignoring Idempotency: Network calls can fail or retry. Data operations must be designed to handle duplicate requests without creating duplicates.
- Choreography Overload: Relying solely on events for data consistency can become unmanageable. Use orchestration for complex workflows.
- Underestimating Latency: Cross-service data fetching adds milliseconds to every request. Aggregate data locally where possible.
- Lack of Documentation: Without clear ERDs for each service, integration becomes a guessing game.
Final Thoughts on Architectural Clarity 🧠
The transition from monolithic to microservice data modeling requires a shift in mindset. It is not merely about breaking a database into smaller pieces. It is about redefining how data ownership and relationships are conceptualized. The ER diagram remains a vital tool, but its scope narrows to the service boundary.
By avoiding the myths of shared databases and global consistency, architects can build systems that are resilient and scalable. The key is to prioritize service autonomy over data normalization. This means accepting that some data will be duplicated to ensure that services can function independently. It means understanding that strong consistency is a luxury, not a requirement, for every operation.
When designing the data architecture, focus on the domain. Let the business capabilities dictate the boundaries. Use ERDs to clarify the internal state of each service. Use events and APIs to manage the connections between them. This approach ensures that the system can evolve without breaking the underlying data integrity.
Ultimately, the goal is not to replicate the monolith in a distributed form. It is to create a system where data is managed with the same flexibility and speed as the code that processes it. This balance is the foundation of a successful microservices strategy.

