










Diagramas de Relacionamento de Entidades (ERDs) servem como o projeto arquitetônico para a arquitetura de bancos de dados. No entanto, mesmo designers experientes enfrentam dificuldades ao traduzir a lógica de negócios em modelos de dados. A ambiguidade muitas vezes surge de sobreposições de terminologia e distinções sutis entre elementos estruturais. Este guia aborda as perguntas mais persistentes sobre chaves, cardinalidade e relacionamentos.
Compreender esses conceitos evita redundância de dados e garante o desempenho das consultas. Vamos passar por 15 pontos específicos de confusão, dividindo-os em definições claras e acionáveis. Cada seção inclui exemplos práticos e descrições visuais para esclarecer os mecanismos subjacentes.
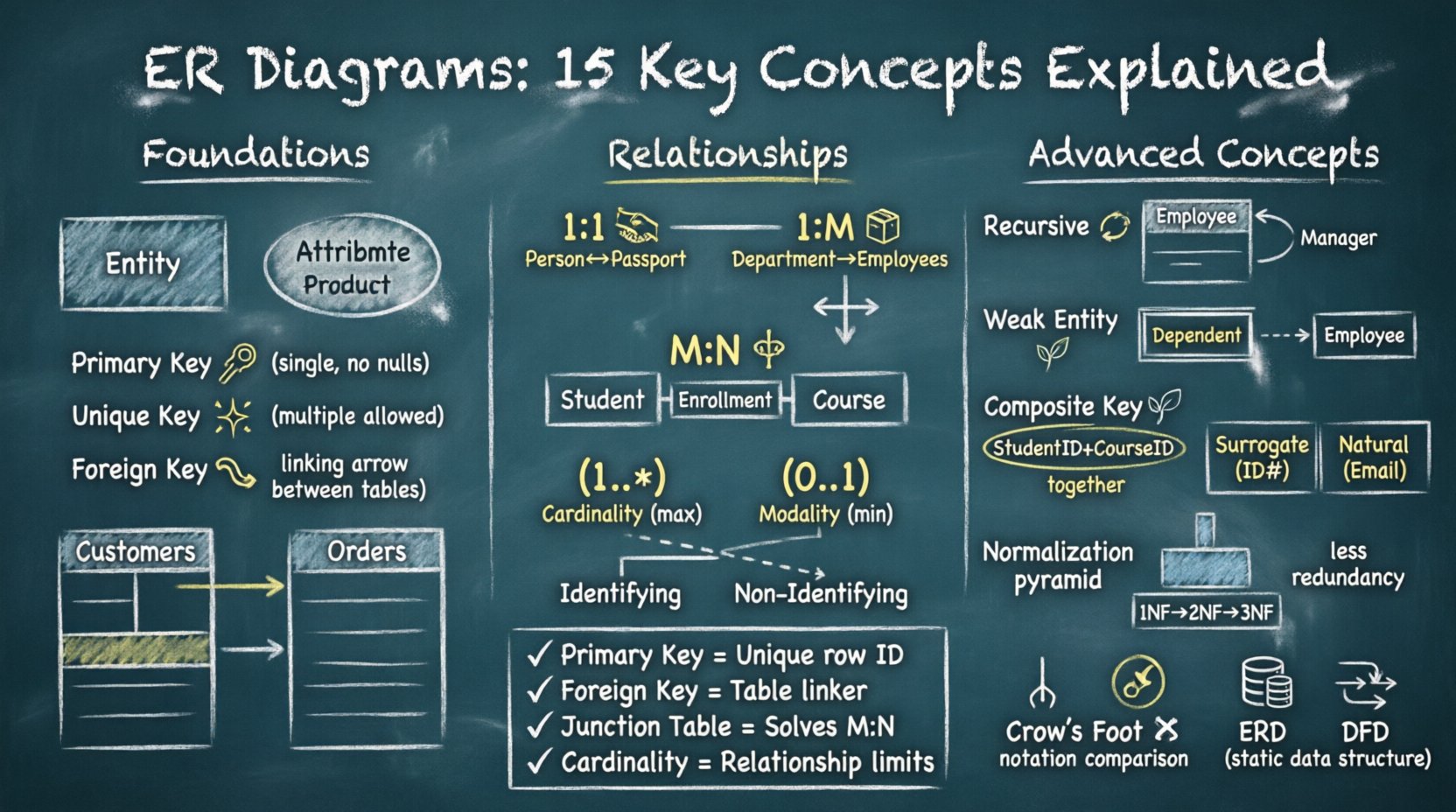
1. Qual é a diferença entre uma Entidade e um Atributo? 🏷️
Um Entidade representa um objeto ou conceito do mundo real sobre o qual são armazenados dados. É geralmente representada por um retângulo. Exemplos incluem Cliente, Produto, ou Pedido.
Um Atributo descreve uma propriedade de uma entidade. É representado por um oval conectado à entidade. Por exemplo, NomeCliente ou PrecoProduto são atributos das entidades mencionadas acima.
- Entidade: O substantivo (Quem/Qual).
- Atributo: O adjetivo (O que o descreve).
A confusão surge frequentemente quando um atributo contém várias partes de informação. Se Endereço for um atributo, pode ser melhor dividi-lo em Rua, Cidade, e CEP para uma melhor normalização.
2. Como as Chaves Primárias diferem das Chaves Únicas? 🔑
Ambas garantem a integridade dos dados, mas seu uso varia.
- Chave Primária: Identifica unicamente cada linha em uma tabela. Uma tabela pode ter apenas uma chave primária. Ela não pode conter valores nulos.
- Chave Única: Garante que todos os valores em uma coluna sejam distintos. Uma tabela pode ter várias chaves únicas. Valores nulos são frequentemente permitidos (dependendo da implementação).
Pense na Chave Primária como um número de Seguro Social para um registro. Uma Chave Única é como um número de passaporte — também único, mas você pode ter mais de um identificador único disponível para uma pessoa.
3. O que é uma Chave Estrangeira e como ela liga tabelas? 🔗
Uma Chave Estrangeira é um campo (ou conjunto de campos) em uma tabela que faz referência à Chave Primária em outra tabela. Ela estabelece uma ligação entre as duas tabelas.
Considere uma Pedidos tabela. Ela precisa saber qual Cliente fez o pedido. O IDCliente na tabela Pedidos é a Chave Estrangeira.
| Tabela | Coluna | Função |
|---|---|---|
| Clientes | IDCliente | Chave Primária |
| Pedidos | IDCliente | Chave Estrangeira |
Essa relação permite que o banco de dados impeça a integridade referencial, garantindo que não exista nenhum pedido sem um cliente válido.
4. Quando uma relação é One-to-One? 🤝
Uma relação One-to-One (1:1) ocorre quando um único registro na Tabela A está relacionado a exatamente um registro na Tabela B, e vice-versa.
- Exemplo: Um Pessoa e um Passaporte.
- Implementação:Muitas vezes implementado colocando a Chave Primária de uma tabela como Chave Estrangeira na outra tabela.
Isso é comum quando se divide uma entidade para otimizar desempenho ou segurança. Por exemplo, mover dados sensíveis como Número da Seguridade Social para uma tabela separada vinculada 1:1.
5. Como funciona uma relação One-to-Many? 📦
Este é o tipo de relação mais comum. Um único registro na Tabela A está relacionado a múltiplos registros na Tabela B, mas um registro na Tabela B está relacionado a apenas um registro na Tabela A.
- Exemplo: Departamento para Funcionário.
- Direção:Um Departamento tem Muitos Funcionários.
No diagrama ER, isso é representado com uma linha conectando as duas entidades. O lado com o “Muitos” recebe a Chave Estrangeira.
6. Por que as relações Many-to-Many são problemáticas? ⚖️
Uma relação Many-to-Many (M:N) existe quando múltiplos registros na Tabela A estão relacionados a múltiplos registros na Tabela B. Implementar isso diretamente em um banco de dados relacional não é possível sem uma ponte.
- Problema:Você não pode simplesmente adicionar uma Chave Estrangeira em uma tabela, pois uma linha precisaria armazenar múltiplos IDs.
- Solução: Crie uma tabela de junção (entidade associativa).
Para Aluno e Curso, crie uma Matrícula tabela contendo StudentID e CourseID. Isso converte a relação M:N em duas relações 1:Várias.
7. Qual é a diferença entre Cardinalidade e Modalidade? ⚖️
Esses termos descrevem as restrições de uma relação, frequentemente confundidos devido à notação semelhante.
- Cardinalidade: O número máximo de instâncias. (por exemplo, Um-Para-Muitos).
- Modalidade: O número mínimo de instâncias. (por exemplo, Obrigatório ou Opcional).
Exemplo: Um Funcionário deve ter um Departamento (Modalidade: Obrigatório/1). Um Departamento pode existir sem um Funcionário (Modalidade: Opcional/0).
8. Relações Identificadoras vs. Não Identificadoras 🧩
A diferença reside na dependência da entidade filha.
- Identificando: A entidade filha não pode existir sem a entidade pai. A Chave Estrangeira faz parte da Chave Primária da entidade filha. Frequentemente mostrada com uma linha sólida.
- Não Identificando: A entidade filha pode existir de forma independente. A Chave Estrangeira não faz parte da Chave Primária. Frequentemente mostrada com uma linha tracejada.
Considere um Fatura (Pai) e ItemDaFatura (Filho). O item da linha é identificando porque um item é sem sentido sem uma fatura.
9. O que é uma Relação Recursiva? 🔄
Uma relação recursiva ocorre quando uma entidade se relaciona consigo mesma. Isso é comum em dados hierárquicos.
- Exemplo: Uma Funcionário tabela em que um funcionário é o Gerente de outros.
- Implementação: Uma Chave Estrangeira na mesma tabela apontando para a Chave Primária da mesma tabela.
Esta estrutura suporta organogramas ou categorias de produtos com subcategorias.
10. Como as Entidades Fracas diferem das Entidades Fortes? 🌱
Uma Entidade Forte tem uma Chave Primária que é independente de outras entidades. Uma Entidade Fraca não pode ser identificada de forma única sem a Chave Primária de uma entidade pai.
- Visual: As entidades fracas são frequentemente desenhadas com retângulos duplos.
- Dependência: Elas dependem de uma Relação Identificadora.
Exemplo: Um Dependente (cônjuge/filho) em um sistema de empresa. Um registro de dependente geralmente não possui um ID único próprio; ele depende do EmployeeID para ser identificado.
11. Quando você deve usar uma Chave Composta? 🧩
Uma Chave Composta consiste em duas ou mais colunas que juntas identificam unicamente uma linha. É usada quando nenhuma coluna única fornece unicidade.
- Cenário: Uma StudentCourse tabela.
- Chaves: StudentID + CourseID.
Nenhum dos IDs é único por si só neste contexto, mas a combinação é. Tenha cuidado, pois chaves compostas podem complicar as relações de chave estrangeira em outras tabelas.
12. Chave Artificial versus Chave Natural: Qual escolher? 🔢
Esta é uma decisão estratégica de design.
- Chave Natural: Um atributo do mundo real (por exemplo, E-mail, CPF). Vantagens: Significativo. Desvantagens: Pode mudar, pode ser longo ou conter informações sensíveis.
- Chave Artificial: Um ID gerado pelo sistema (por exemplo, inteiro autoincrementado). Vantagens: Estável, curto, rápido. Desvantagens: Sem significado comercial.
A melhor prática geralmente favorece chaves artificiais para a estrutura interna da tabela, enquanto chaves naturais permanecem úteis para busca e relatórios.
13. Como a Normalização afeta o ERD? 📉
A normalização é o processo de organizar dados para reduzir a redundância. O ERD evolui conforme você normaliza.
- 1FN: Eliminar grupos repetidos.
- 2FN: Remover dependências parciais.
- 3FN: Remover dependências transitivas.
A normalização mais alta geralmente aumenta o número de tabelas e relacionamentos. Embora melhore a integridade dos dados, pode complicar as consultas. Equilibre o nível de normalização com as necessidades de desempenho das consultas.
14. Notação Pata de Corvo vs. Notação Chen: Qual é a padrão? 👣
Notação refere-se à forma como os relacionamentos são representados visualmente.
- Pata de Corvo: Usa símbolos como linhas, cruzes e círculos nas extremidades das linhas. Muito comum em ferramentas modernas.
- Chen: Usa losangos para relacionamentos e retângulos para entidades. Mais acadêmico.
A notação Pata de Corvo é geralmente preferida para implementação porque se mapeia mais diretamente para restrições SQL. No entanto, a notação Chen é excelente para modelagem conceitual de alto nível.
15. Diagrama Entidade-Relacionamento (DER) vs. Diagramas de Fluxo de Dados (DFD) 📊
Eles servem para propósitos diferentes no ciclo de vida do projeto de sistema.
- DER: Foca em estrutura de dados e armazenamento. Visão estática dos relacionamentos.
- DFD: Foca em movimentação de dados e processos. Visão dinâmica de como os dados fluem pelo sistema.
Não confunda os dois. Um DER diz o que dados existem. Um DFD diz como esses dados são processados. Ambos são necessários para uma especificação completa do sistema.
Resumo dos Conceitos Principais 📝
| Conceito | Ponto-Chave |
|---|---|
| Chave Primária | ID único para uma linha. Nulos não são permitidos. |
| Chave Estrangeira | Link para a Chave Primária de outra tabela. |
| Cardinalidade | Máximo de relacionamentos (1, 1..N). |
| Tabela de junção | Resolve relacionamentos muitos para muitos. |
Dominar essas distinções permite um design de banco de dados robusto. O objetivo é clareza, integridade e escalabilidade. Revise seus diagramas com base nesses pontos para garantir que seu modelo reflita com precisão a realidade do negócio.
Ao resolver essas 15 confusões comuns, você constrói uma base para sistemas fáceis de manter e expandir. Foque nos significados semânticos dos dados, e a implementação técnica seguirá naturalmente.

