











Przejście od tradycyjnej infrastruktury lokalnej do środowisk opartych na chmurze oznacza podstawową zmianę sposobu przechowywania, dostępu i zarządzania danymi. Dla administratorów baz danych (DBA) ten przejście wymaga więcej niż tylko migracji istniejących schematów. Wymaga ponownej oceny diagramów relacji encji (ERD), aby dopasować je do unikalnych ograniczeń i możliwości systemów rozproszonych. Ten przewodnik zapewnia kompleksowy przegląd projektowania diagramów ER wspierających skalowalność, odporność i wydajność w nowoczesnych architekturach opartych na chmurze. 📊
Zrozumienie zmiany w architekturze danych 🔄
Tradycyjny projekt bazy danych często priorytetowo ustawia ściśle znormalizowane dane i centralne zarządzanie. W przeciwieństwie do tego, architektury oparte na chmurze podkreślają dostępność, tolerancję na rozłączenia i skalowanie poziome. Kluczowa różnica polega na założeniu, że awarie są możliwe. W rozwiązaniu monolitycznym baza danych jest jednym punktem awarii. W środowisku opartym na chmurze węzły często ulegają awariom, a system musi natychmiast się dostosować.
Podczas projektowania diagramów ER w tym środowisku administratorzy baz danych muszą wziąć pod uwagę:
- Spójność rozproszona: Jak relacje wytrzymują, gdy dane są rozdzielone między regionami?
- Opóźnienie: Jak odległość fizyczna między węzłami danych wpływa na wydajność zapytań?
- Koszt: Jaka jest wymiana między nadmiarowością przechowywania a kosztami transakcji?
- Złożoność operacyjna: Czy schemat można zarządzać bez ciągłej interwencji ręcznej?
Ignorowanie tych czynników może prowadzić do systemów trudnych w skalowaniu lub utrzymaniu. Dobrze zaprojektowany diagram ER działa jak projekt przepływu danych, zapewniając, że podstawowa infrastruktura może wspierać logikę biznesową bez węzłów zatyczki. 🚀
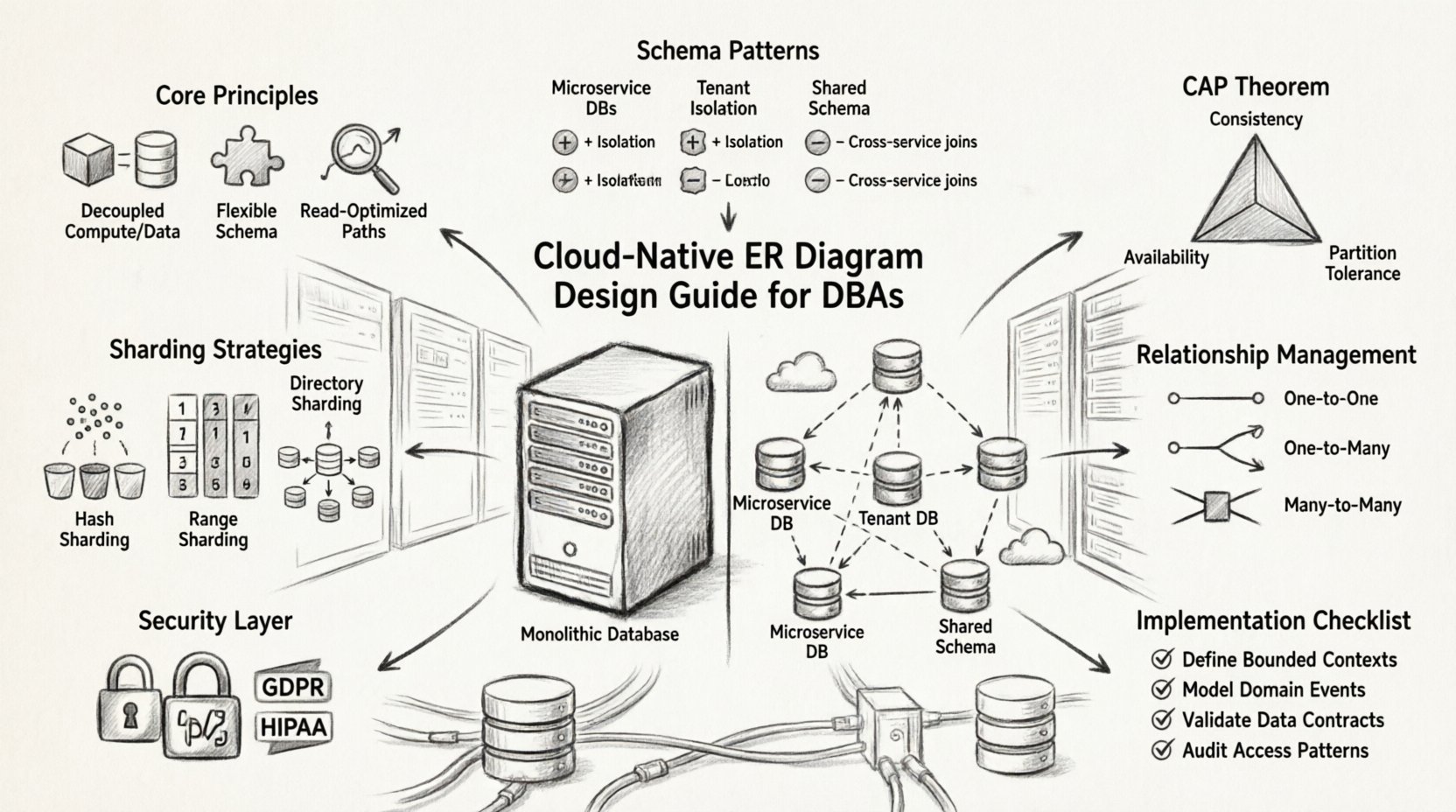
Podstawowe zasady diagramów ER dla architektur opartych na chmurze ⚙️
Zanim przejdziemy do konkretnych wzorców, istotne jest zrozumienie zasad kierujących, które różnią modelowanie danych oparte na chmurze od podejść tradycyjnych.
1. Odłączenie danych od obliczeń
W wielu systemach dziedziczonych serwer bazy danych i serwer aplikacji są ściśle powiązane. Projektowanie oparte na chmurze rozdziela te aspekty. Diagram ERD powinien to odzwierciedlać, minimalizując zależności wymagające synchronicznego komunikowania się między różnymi usługami.
2. Przyjęcie elastyczności schematu
Choć bazy danych SQL są sztywne, środowiska oparte na chmurze często wykorzystują wielojęzyczne przechowywanie danych. Oznacza to, że różne typy danych mogą wymagać różnych modeli przechowywania. Diagram ER powinien wizualizować relacje logiczne, nawet jeśli implementacje fizyczne się różnią (np. magazyny JSON obok tabel relacyjnych).
3. Optymalizacja dla obciążeń zdominowanych odczytami
Aplikacje oparte na chmurze często obsługują miliony użytkowników jednocześnie. Projekt ER musi wspierać skuteczne ścieżki odczytu, nawet jeśli oznacza to wprowadzenie pewnej nadmiarowości. Denormalizacja staje się narzędziem strategicznym, a nie grzechem.
Wzorce projektowania schematów dla skalowalności 📈
Wybór odpowiedniego wzorca schematu jest kluczowy dla wydajności. Poniżej znajdują się typowe podejścia stosowane w systemach rozproszonych.
Jedna baza danych na usługę
Każda mikro-usługa zarządza własnym schematem bazy danych. Ta izolacja zapobiega rozprzestrzenianiu się awarii usług. Diagram ER dla całego systemu staje się zbiorem mniejszych, niezależnych diagramów połączonych odniesieniami logicznymi.
Współdzielona baza danych z rozdzielonymi schematami
Wiele usług współdzieli jedną instancję bazy danych, ale utrzymuje osobne przestrzenie nazw schematów. To zmniejsza koszty infrastruktury, ale wprowadza ryzyko silnej zależności. Jest to ogólnie nie zalecane w dużych projektach opartych na chmurze.
Baza danych na klienta
W aplikacjach SaaS wieloklientowych każdy klient otrzymuje dedykowaną instancję bazy danych. Projekt diagramu ERD musi być spójny we wszystkich instancjach, zapewniając jednolite stosowanie migracji i aktualizacji.
Porównanie wzorców schematów
| Wzorzec | Zalety | Wady | Najlepsze zastosowanie |
|---|---|---|---|
| Jeden bazę danych | Proste łączenia, zgodność z ACID | Jedno miejsce awarii, ograniczenia skalowania | Aplikacje monolityczne, niski ruch |
| Baza danych na usługę | Niezależne skalowanie, izolacja błędów | Złożone transakcje, rozproszone łączenia | Usługi mikroserwisowe, wysokie tempo wzrostu |
| Baza danych na klienta | Izolacja danych, uproszczenie zgodności | Wysokie koszty infrastruktury, wysokie obciążenie zarządzania | Platformy SaaS, regulowane branże |
| Współdzielony schemat | Niski koszt, wspólne zapytania | Zależność od dostawcy, przepływy skalowania | Narzędzia wewnętrzne, MVP |
Zarządzanie relacjami między usługami 🔗
W architekturze rozproszonej klucze obce nie zawsze są możliwe. Integralność referencyjna musi być zarządzana inaczej. Diagram ER powinien jasno przedstawiać te relacje logiczne, nawet jeśli fizyczne zapewnienie odbywa się na poziomie aplikacji lub za pomocą procesów asynchronicznych.
Rodzaje relacji
- Jeden do jednego: Często obsługiwane przez osadzanie danych bezpośrednio, aby zmniejszyć opóźnienie łączenia.
- Jeden do wielu: Wymaga dokładnej analizy, jak są przechowywane rekordy potomne. Jeśli rodzic się przemieszcza, czy dzieci się przemieszczają?
- Wiele do wielu: Zazwyczaj realizowane za pomocą tabeli pośredniej. W środowiskach chmurowych ta tabela może wymagać niezależnego shardowania.
Obsługa integralności referencyjnej
Bez ściśle określonych ograniczeń kluczy obcych spójność danych opiera się na logice aplikacji. Strategie obejmują:
- Miękkie usuwanie: Oznaczanie rekordów jako nieaktywnych zamiast ich usuwania w celu zachowania historii.
- Końcowa spójność: Używanie strumieni zdarzeń do propagowania zmian między usługami.
- Transakcje kompensacyjne: Logika cofania, która obsługuje błędy w rozproszonych przepływach pracy.
Strategie partycjonowania i shardingu 🗂️
Wraz ze wzrostem objętości danych pojedynczy węzeł bazy danych nie może obsłużyć obciążenia. Partycjonowanie (sharding) dzieli dane na wielu węzłach. Diagram ER musi wskazywać sposób dystrybucji danych, aby uniknąć punktów przepływu.
Klucze shardingu
Wybór klucza shardingu decyduje o tym, jak są kierowane zapytania. Dobry klucz równomiernie dystrybuuje dane i dopasowuje się do wzorców dostępu.
- Oparte na skrócie (hash): Dystrybuuje dane losowo. Dobrze nadaje się do dostępu jednolitego, źle do zapytań zakresowych.
- Oparte na zakresie: Dzieli dane według wartości (np. daty lub identyfikatory). Dobrze nadaje się do zapytań zakresowych, ale może prowadzić do nierównomiernego rozkładu.
- Oparte na katalogu: Przechowuje usługę mapowania do lokalizacji danych. Zwiększa opóźnienie, ale pozwala na elastyczne rozmieszczenie.
Wpływ na diagramy ER
Podczas projektowania ERD należy zwrócić uwagę, że:
- Tabele, które często są łączone, powinny być idealnie położone obok siebie, aby zmniejszyć ruch sieciowy.
- Tabele globalne (np. dane konfiguracyjne) powinny pozostać niepodzielone.
- Indeksy muszą być zaprojektowane tak, aby działały w obrębie granic shardów.
Modele spójności i twierdzenie CAP ⚖️
Twierdzenie CAP mówi, że system rozproszony może gwarantować tylko dwa z trzech własności: spójność, dostępność i odporność na rozłączenia. Systemy oparte na chmurze priorytetowo wybierają odporność na rozłączenia, co wymusza wybór między spójnością a dostępnością.
Wybieranie odpowiedniego modelu
| Model | Opis | Skutki dla diagramu ER |
|---|---|---|
| Silna spójność | Wszystkie węzły widzą te same dane w tym samym czasie | Wymaga zapisów synchronicznych; ogranicza przepustowość zapisu |
| Konsystencja ostateczna | Dane stają się spójne po opóźnieniu | Zezwala na zapisy asynchroniczne; wymaga obsługi przestarzałych odczytów |
| Konsystencja przyczynowa | Zachowuje kolejność operacji powiązanych przyczynowo | Złożone śledzenie zależności w diagramie ERD |
Dla aplikacji finansowych często konieczna jest silna spójność. Dla kanałów społecznościowych akceptowalna jest konsystencja ostateczna. Diagram ERD powinien zawierać adnotacje dotyczące tabel, które wymagają ściślego porządkowania, oraz tych, które mogą tolerować opóźnienia.
Indeksowanie w środowiskach o wysokiej przepustowości 🏷️
Strategie indeksowania w chmurze różnią się od lokalnych z powodu kosztów przechowywania i przepustowości sieciowej. Każdy indeks zużywa zasoby zapisu i przestrzeń pamięci.
Najlepsze praktyki indeksowania
- Minimalizuj indeksy pomocnicze: Indeksuj tylko kolumny używane w częstych predykatach zapytań.
- Rozważ indeksy pokrywające: Włącz wszystkie niezbędne kolumny do indeksu, aby uniknąć wyszukiwań w tabeli.
- Monitoruj używanie indeksów: Regularnie audytuj wydajność indeksów w celu usunięcia nieużywanych struktur.
- Indeksy partycjonowane: Dopasuj struktury indeksów do strategii partycjonowania danych.
Indeksy globalne vs. lokalne
Indeksy globalne obejmują wszystkie shardy i mogą być kosztowne w utrzymaniu. Indeksy lokalne znajdują się w ramach shardu i są tańsze. Podczas projektowania diagramu ERD określ, które indeksy są globalne, a które lokalne, aby wspomóc zespół infrastrukturalny.
Rozważania dotyczące bezpieczeństwa i zgodności 🛡️
Bezpieczeństwo danych w chmurze obejmuje szyfrowanie, kontrolę dostępu oraz zgodność z przepisami takimi jak GDPR lub HIPAA. Diagram ERD powinien odzwierciedlać poziomy wrażliwości danych.
Klasyfikacja danych
Oznacz jednostki danych w zależności od wrażliwości:
- Publiczne: Nie wymagane żadne szczególne zabezpieczenia.
- Wewnętrzne: Dostępne wyłącznie dla pracowników.
- Ograniczone: Wymaga szyfrowania i szczegółowego rejestrowania dostępu.
Szyfrowanie w spoczynku i w tranzycji
Wszystkie wrażliwe pola powinny być oznaczone do szyfrowania. ERD nie powinien przechowywać niezaszyfrowanych danych wrażliwych. Zamiast tego powinien odwoływać się do zaszyfrowanych kolumn lub tokenów.
Zgodność i trwałość danych
Niektóre dane muszą być przechowywane przez określone okresy lub całkowicie usunięte. Projekt ER powinien zawierać pola metadanych dla zasad przechowywania i śladów audytu.
Wersjonowanie i ewolucja schematu 🔄
W środowiskach opartych na chmurze, przestój spowodowany zmianami schematu jest rzadkością. Migracje muszą być wykonywane online. ERD powinien wspierać strategie wersjonowania.
Zgodność wsteczna
Nowe wersje schematu powinny być zgodne wstecznie z logiką aplikacji. Pozwala to na stopniowe wdrażanie zmian.
Wzorce migracji
- Dodaj kolumnę: Dodaj nowe pola bez zmiany istniejących danych.
- Podwójne zapisywanie: Zapisuj do obu struktur — starej i nowej — podczas przejścia.
- Przełączenie: Przełącz ruch odczytu i zapisu po zakończeniu migracji danych.
- Usuń kolumnę: Usuń nieużywane pola dopiero po potwierdzeniu braku zależności.
Typowe pułapki do uniknięcia ⚠️
Nawet doświadczeni DBA mogą się pomylić podczas dostosowywania się do projektów opartych na chmurze. Oto najczęstsze błędy.
- Zbyt duża normalizacja: Zbyt wiele połączeń zwiększa opóźnienia w systemach rozproszonych.
- Ignorowanie danych chłodnych: Niearchiwizowanie danych historycznych może zwiększać koszty i spowalniać aktywne zapytania.
- Ustawione stałe limity: Ustawianie dowolnych limitów wierszy w aplikacji, które obejmują ograniczenia bazy danych.
- Ignorowanie opóźnień: Projektowanie zapytań, które zakładają lokalny dostęp do danych, podczas gdy dane są faktycznie zdalne.
- Jedno punktowe miejsce awarii Projektowanie podstawowego węzła bazy danych, którego utrata spowoduje zatrzymanie całego systemu.
Lista kontrolna wdrożenia ✅
Zanim wdrożysz schemat bazy danych opartej na chmurze, przejrzyj poniższą listę kontrolną.
| Zadanie | Priorytet | Status |
|---|---|---|
| Zdefiniuj strategię shardingu | Wysoki | Nie rozpoczęto |
| Zidentyfikuj wzorce odczytu/zapisu | Wysoki | Nie rozpoczęto |
| Zaplanuj spójność ostateczną | Średni | Nie rozpoczęto |
| Zaprojektuj kopie zapasowe i odtwarzanie | Wysoki | Nie rozpoczęto |
| Skonfiguruj powiadomienia monitorowania | Średni | Nie rozpoczęto |
| Przejrzyj polityki bezpieczeństwa | Wysoki | Nie rozpoczęto |
Utrzymanie i monitorowanie 🔍
Baza danych oparta na chmurze wymaga ciągłego monitorowania. Diagram ERD nie jest dokumentem statycznym; ewoluuje wraz z aplikacją.
Kluczowe metryki
- Opóźnienie zapytania: Śledź średnie i czas odpowiedzi p99.
- Wykorzystanie puli połączeń: Upewnij się, że aplikacja może radzić sobie z szczytowymi obciążeniami.
- Wzrost pojemności magazynowania: Przewiduj potrzeby przyszłej pojemności.
- Stawki błędów: Monitoruj niepowodzenia transakcji i cofania operacji.
Automatyzacja
Używaj narzędzi automatyzacji do wykrywania rozbieżności schematów i zapewniania standardów. Zmiany ręczne w schematach produkcyjnych należy minimalizować, aby zmniejszyć błędy ludzkie.
Wnioski 🏁
Projektowanie diagramów ER dla architektur typu cloud-native to skomplikowane zadanie, które równoważy ograniczenia techniczne z celami biznesowymi. Skupiając się na skalowalności, modelach spójności i bezpieczeństwie, administratorzy baz danych mogą tworzyć systemy, które wytrzymają wzrost i zmiany. Kluczem jest traktowanie modelowania danych jako ciągłego procesu, a nie jednorazowego ustawienia. Regularne przeglądy i przestrzeganie najlepszych praktyk zapewniają, że baza danych pozostaje niezawodną podstawą aplikacji. 🌐

