











従来のオンプレミスインフラからクラウドネイティブ環境への移行は、データの保存、アクセス、管理の仕方において根本的な変化をもたらす。データベース管理者(DBA)にとって、この移行は既存のスキーマを単に移行するだけでは不十分である。分散システムの独自の制約と機能に合わせてエンティティ関係図(ERD)を再評価する必要がある。このガイドは、現代のクラウドアーキテクチャにおけるスケーラビリティ、レジリエンス、パフォーマンスを支えるER図の設計について包括的に解説する。 📊
データアーキテクチャの変化を理解する 🔄
従来のデータベース設計は、厳格な正規化と集中型の制御を重視する傾向がある。一方、クラウドネイティブアーキテクチャは可用性、パーティション耐性、水平スケーリングを重視する。その核心的な違いは、障害を前提とする点にある。モノリシックな構成では、データベースが単一障害点となる。クラウドネイティブ環境ではノードの障害が頻発し、システムは即座に適応しなければならない。
この環境向けにER図を設計する際、DBAは以下の点を検討しなければならない:
- 分散整合性:データが地域を跨いで分割された場合、関係性はどのように維持されるのか?
- レイテンシ:データノード間の物理的な距離がクエリパフォーマンスにどのように影響するか?
- コスト:ストレージの冗長性とトランザクションコストの間のトレードオフは何か?
- 運用の複雑さ:常に手動での介入がなければスキーマを管理できないのか?
これらの要因を無視すると、スケーリングや保守が困難なシステムに陥る。適切に設計されたER図は、データフローの設計図として機能し、基盤インフラがビジネスロジックをブロッキングなしで支えられるようにする。 🚀
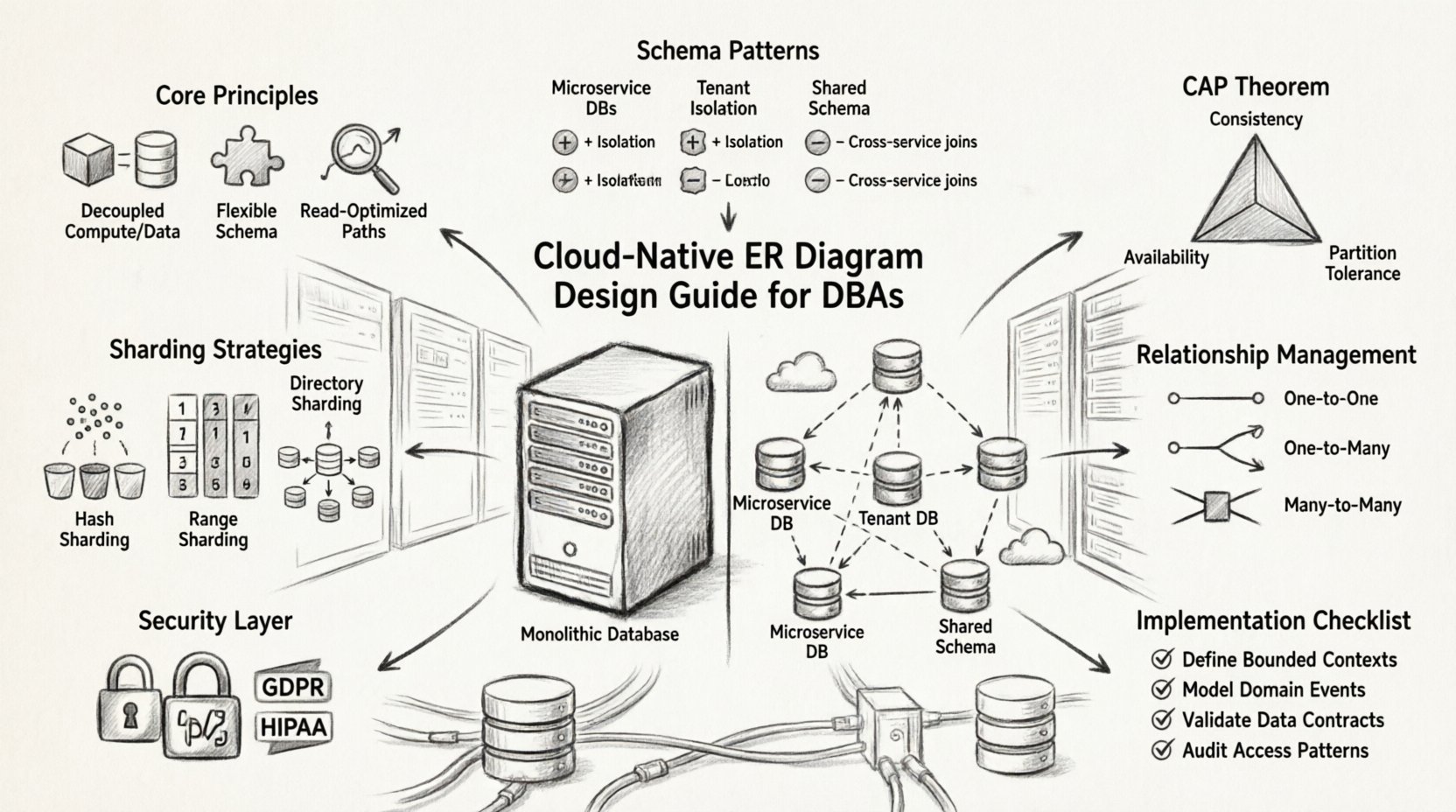
クラウドネイティブERDの基本原則 ⚙️
特定のパターンに深入りする前に、クラウドネイティブなデータモデリングと従来のアプローチを分ける指針を理解することが不可欠である。
1. データとコンピューティングの分離
多くのレガシーシステムでは、データベースサーバーとアプリケーションサーバーが密接に結合されている。クラウドネイティブ設計では、これらを分離する。ER図は、異なるサービス間で同期通信を必要とする依存関係を最小限に抑えることで、この分離を反映すべきである。
2. スキーマの柔軟性の受容
SQLデータベースは厳格である一方、クラウドネイティブ環境ではポリグロット永続化を頻繁に利用する。これは、異なるデータタイプが異なるストレージモデルを必要とする可能性があることを意味する。物理的な実装が異なっていても(例:リレーショナルテーブルと併用されたJSONストア)、ER図は論理的な関係を可視化すべきである。
3. 読み込み中心のワークロードへの最適化
クラウドアプリケーションはしばしば数百万のユーザーを同時に処理する。ER設計は、多少の冗長性を導入しても、効率的な読み込みパスをサポートしなければならない。正規化の解除は罪ではなく、戦略的なツールとなる。
スケーラビリティのためのスキーマ設計パターン 📈
適切なスキーマパターンの選定はパフォーマンスにとって極めて重要である。以下は分散システムでよく用いられるアプローチである。
サービスごとに単一のデータベース
各マイクロサービスが独自のデータベーススキーマを管理する。この分離により、サービス障害の連鎖を防ぐ。全体システムのER図は、論理的な参照で結ばれた、より小さな独立した図の集合となる。
スキーマ分離を伴う共有データベース
複数のサービスが単一のデータベースインスタンスを共有するが、それぞれ別々のスキーマ名空間を維持する。これによりインフラコストを削減できるが、強い結合のリスクが生じる。大規模なクラウド展開では一般的に推奨されない。
テナントごとのデータベース
マルチテナントSaaSアプリケーションでは、各顧客に専用のデータベースインスタンスが割り当てられる。ERD設計はすべてのインスタンスで一貫性を保たれ、マイグレーションや更新が均一に適用されることを保証しなければならない。
スキーマパターンの比較
| パターン | 長所 | 短所 | 最適な使用ケース |
|---|---|---|---|
| 単一データベース | シンプルな結合、ACID準拠 | 単一障害ポイント、スケーラビリティの限界 | モノリシックアプリ、低トラフィック |
| サービスごとのデータベース | 独立したスケーリング、障害の隔離 | 複雑なトランザクション、分散結合 | マイクロサービス、急成長 |
| テナントごとのデータベース | データの隔離、コンプライアンスの容易さ | 高いインフラコスト、管理負荷 | SaaSプラットフォーム、規制業界 |
| 共有スキーマ | 低コスト、共有クエリ | ベンダー固定、スケーリングのボトルネック | 社内ツール、MVP |
サービス間の関係性の管理 🔗
分散アーキテクチャでは、外部キーが常に実行可能とは限りません。参照整合性は別の方法で管理しなければなりません。物理的な整合性の確保がアプリケーション層または非同期プロセスで行われる場合でも、ER図はこれらの論理的関係を明確に表現するべきです。
関係の種類
- 1対1:結合の遅延を減らすために、データを直接埋め込むことで処理されることが多い。
- 1対多:子レコードの格納方法について慎重な検討が必要です。親が移動した場合、子も移動するのでしょうか?
- 多対多:通常、関連テーブルを介して実装されます。クラウド環境では、このテーブルを独立してシャーディングする必要がある場合があります。
参照整合性の取り扱い
厳格な外部キー制約がない場合、データの一貫性はアプリケーションロジックに依存する。戦略には以下がある:
- ソフトデリート:履歴を保持するために、レコードを削除するのではなく非アクティブとしてマークする。
- 最終的整合性:イベントストリームを使用して、変更を複数のサービス間で伝播する。
- 補償トランザクション:分散ワークフローでの障害を処理するロールバックロジック。
パーティショニングおよびシャーディング戦略 🗂️
データ量が増えるにつれて、単一のデータベースノードでは負荷を処理できなくなる。パーティショニング(シャーディング)はデータを複数のノードに分割する。ER図は、ホットスポットを避けるためにデータがどのように分散されているかを示す必要がある。
シャーディングキー
シャーディングキーの選択は、クエリがどのようにルーティングされるかを決定する。良いキーはデータを均等に分散させ、アクセスパターンと整合する。
- ハッシュベース:データをランダムに分散する。均一なアクセスには適しているが、範囲クエリには不向き。
- 範囲ベース:値(例:日付やID)でデータを分割する。範囲クエリには適しているが、不均一な分散のリスクがある。
- ディレクトリベース:データの位置を特定するためのマッピングサービスを維持する。遅延が増えるが、配置の柔軟性が得られる。
ER図への影響
ERDを設計する際は、以下の点に注意する:
- 頻繁に結合されるテーブルは、ネットワークトラフィックを最小限に抑えるために、理想的には同じ場所に配置されるべきである。
- グローバルテーブル(例:設定データ)はシャーディングせずに保持すべきである。
- インデックスはシャード境界内で動作するように設計しなければならない。
整合性モデルとCAP定理 ⚖️
CAP定理は、分散システムは3つの特性(整合性、可用性、パーティション耐性)のうち2つしか保証できないと述べている。クラウドネイティブシステムはパーティション耐性を優先するため、整合性と可用性のどちらかを選ばなければならない。
適切なモデルの選択
| モデル | 説明 | ER図への影響 |
|---|---|---|
| 強整合性 | すべてのノードは同じ時刻に同じデータを確認する | 同期書き込みを必要とする;書き込みスループットに制限がある |
| 最終的整合性 | データは遅延後に整合性を保つ | 非同期書き込みを許可する;古くなった読み取りの処理が必要 |
| 因果整合性 | 因果関係のある操作の順序を保持する | ER図における依存関係の複雑な追跡 |
金融アプリケーションでは、強整合性がしばしば必要である。ソーシャルフィードでは、最終的整合性が許容可能である。ER図は、厳密な順序が必要なテーブルと、遅延を許容できるテーブルを明示すべきである。
高スループット環境向けのインデックス作成 🏷️
クラウドにおけるインデックス戦略は、ストレージコストとネットワーク帯域幅のため、オンプレミスとは異なる。すべてのインデックスは書き込みリソースとストレージスペースを消費する。
インデックス作成のベストプラクティス
- 補助インデックスを最小限に抑える:頻繁にクエリの条件に使用されるカラムのみをインデックス化する。
- カバーインデックスを検討する:テーブル参照を避けるために、必要なすべてのカラムをインデックスに含める。
- インデックス使用状況をモニタリングする:定期的にインデックスのパフォーマンスを監査し、使用されていない構造を削除する。
- パーティショニングされたインデックス:インデックス構造をデータパーティショニング戦略と一致させる。
グローバルインデックス vs. ローカルインデックス
グローバルインデックスはすべてのシャードをカバーし、維持が高コストになることがある。ローカルインデックスはシャード内に存在し、安価である。ER図を設計する際には、どのインデックスがグローバルで、どのインデックスがローカルであるかを明記し、インフラチームを支援する。
セキュリティおよびコンプライアンスの考慮事項 🛡️
クラウドにおけるデータセキュリティは、暗号化、アクセス制御、GDPRやHIPAAなどの規制への準拠を含む。ER図はデータの機密性レベルを反映すべきである。
データ分類
機密性に基づいてデータエンティティにタグを付ける:
- 公開:特別な保護は不要。
- 社内用:社員のみがアクセス可能。
- 制限済み:暗号化と厳格なアクセスログ記録が必要です。
静的および送信中での暗号化
すべての機密フィールドは暗号化対象としてマークする必要があります。ERDは平文の機密データを保存してはいけません。代わりに、暗号化されたカラムまたはトークンを参照すべきです。
コンプライアンスおよび保持
一部のデータは特定の期間保持するか、完全に削除する必要があります。ER設計には保持ポリシーおよび監査トレース用のメタデータフィールドを含めるべきです。
バージョン管理とスキーマの進化 🔄
クラウドネイティブ環境では、スキーマ変更に伴うダウンタイムは稀です。マイグレーションはオンラインで実行しなければなりません。ERDはバージョン管理戦略をサポートしているべきです。
後方互換性
新しいスキーマバージョンはアプリケーションロジックと後方互換性を持つべきです。これにより、変更を段階的に展開できます。
マイグレーションパターン
- カラム追加:既存のデータを変更せずに新しいフィールドを追加する。
- ダブル書き込み:移行中は古い構造と新しい構造の両方に書き込む。
- 切り替え:データのマイグレーションが完了したら、読み取りおよび書き込みトラフィックを切り替える。
- カラム削除:依存関係がないことを確認した後、使用されていないフィールドのみを削除する。
避けるべき一般的な落とし穴 ⚠️
経験豊富なDBAでさえ、クラウドネイティブ設計に適応する際に誤りを犯すことがあります。以下は一般的なミスです。
- 過剰正規化:多すぎる結合は分散システムにおける遅延を増加させる。
- 冷データを無視する:履歴データをアーカイブしないとコストが増加し、アクティブなクエリが遅くなる。
- ハードコードされた制限:アプリケーション内でデータベースの制約を回避する任意の行数制限を設定する。
- 遅延を無視する:実際にはリモートにあるデータをローカルアクセスを前提としてクエリを設計する。
- 単一障害点: システム全体を停止させる可能性があるプライマリデータベースノードの設計。
実装チェックリスト ✅
クラウドネイティブなデータベーススキーマをデプロイする前に、以下のチェックリストを確認してください。
| タスク | 優先度 | 状態 |
|---|---|---|
| シャーディング戦略の定義 | 高 | 未着手 |
| 読み取り/書き込みパターンの特定 | 高 | 未着手 |
| 最終的整合性のための計画 | 中 | 未着手 |
| バックアップおよび復旧の設計 | 高 | 未着手 |
| モニタリングアラートの設定 | 中 | 未着手 |
| セキュリティポリシーのレビュー | 高 | 未着手 |
保守とモニタリング 🔍
クラウドネイティブなデータベースは継続的なモニタリングを必要とします。ERDは静的な文書ではなく、アプリケーションと共に進化します。
重要なメトリクス
- クエリ遅延: 平均応答時間およびp99応答時間を追跡する。
- コネクションプールの利用状況: アプリケーションがピーク負荷を処理できるようにする。
- ストレージの増加:将来の容量ニーズを予測する。
- エラーレート:トランザクションの失敗とロールバックを監視する。
自動化
自動化ツールを使用してスキーマのずれを検出し、標準を強制する。本番環境のスキーマに対する手動変更は最小限に抑えることで、人的ミスを減らす。
結論 🏁
クラウドネイティブアーキテクチャ向けにER図を設計することは、技術的制約とビジネス目標のバランスを取る複雑な作業である。スケーラビリティ、一貫性モデル、セキュリティに注力することで、成長や変化に耐えるシステムを構築できる。鍵は、データモデリングを一度限りのセットアップではなく、継続的なプロセスとして捉えることである。定期的なレビューとベストプラクティスの遵守により、データベースがアプリケーションの信頼できる基盤のまま保たれる。 🌐

