











データベーススキーマがぐちゃぐちゃな糸の玉のように見えるのをじっと見つめることは、どんなデータアーキテクトや開発者にとってもなじみ深い体験です。モデリングツールを開くと、データの明確で論理的な地図ではなく、交差する線、曖昧なラベル、論理に反するように見えるエンティティが目に入ります。この視覚的な混乱は単なる美観の問題ではなく、将来的に時間と資金、システムの安定性を損なう構造的負債の兆候です。📉
エンティティ関係図(ERD)が壊れているように見える場合、それは基盤となる設計原則が損なわれていることを意味します。ボックスの間に線を引くことだけではなく、データ関係の真実を定義することです。壊れた図は壊れたデータベースを生み出し、遅いクエリ、データの不整合、保守が困難なサイクルを引き起こします。幸いなことに、これらの問題は解決可能です。データベース理論の基礎的で永続的な原則に戻ることで、混乱から秩序を取り戻すことができます。このガイドでは、症状の診断、根本原因の理解、検証された戦略の適用を通じて、スキーマを修復する方法を紹介します。🛡️
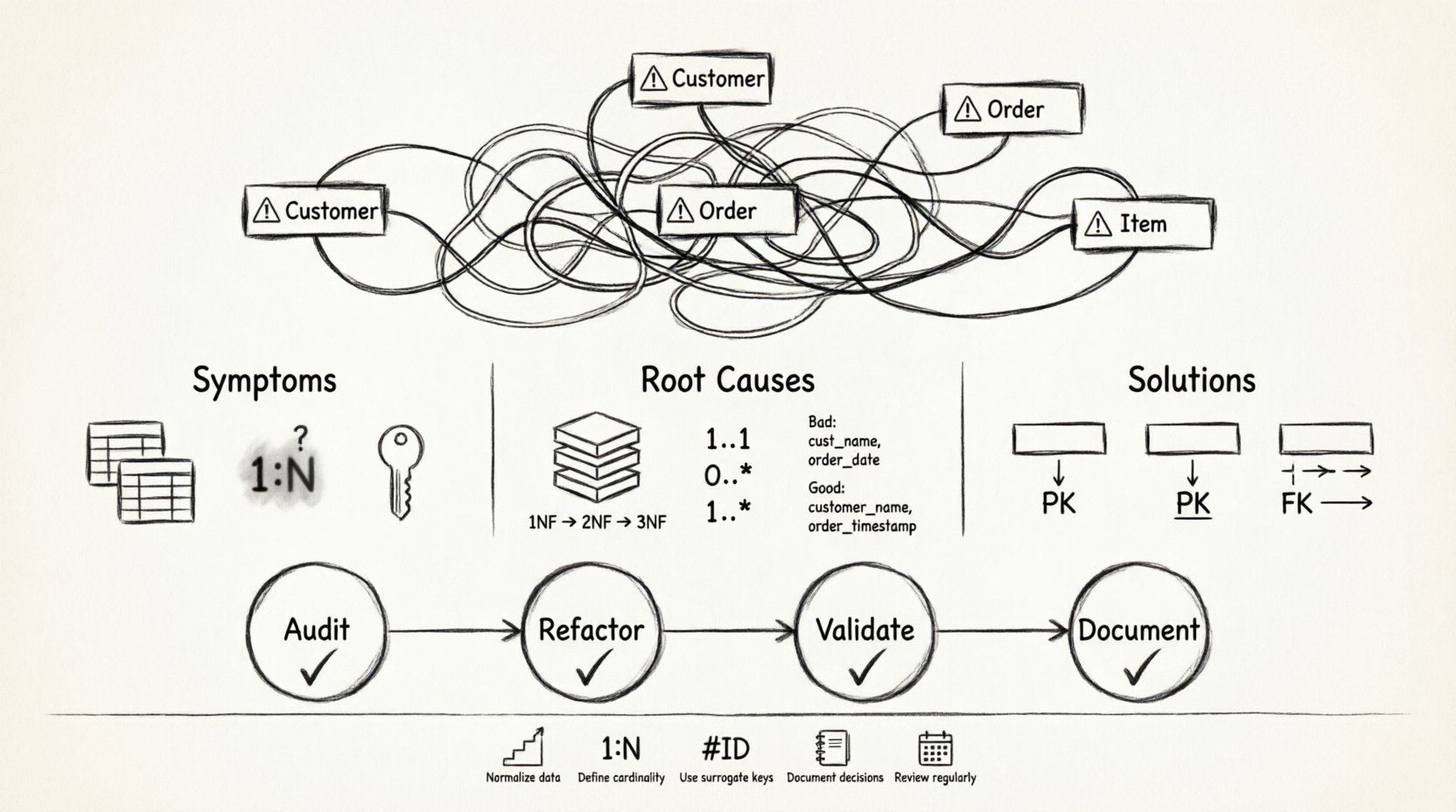
🔍 壊れたER図の兆候を特定する
問題を修復するには、まずその兆候を認識する必要があります。『壊れている』ように見えるデータベースモデルは、特定の視覚的・論理的な赤信号を示すことがよくあります。これらの兆候は、ビジネス要件と物理的ストレージの間の抽象化レイヤーに欠陥があることを示唆しています。
- スパゲッティ関係:線が互いに制御不能に交差し、データの流れを追跡できず迷子になってしまう。これは、明確な階層がないまま外部キーが任意に配置されたときによく起こる。
- 重複するエンティティ: 同じ情報をわずかに異なる名前で格納する2つ以上のテーブルが存在する。たとえば、
CustomerとClientというテーブルが存在し、データ範囲に明確な違いがない場合。 - 曖昧な基数: エンティティを結ぶ線が、関係の種類を明確に定義していない。1対1か?1対多か?多対多か?カラスの足記法が欠けている、または一貫性がない場合、意図が不明瞭になる。
- 循環依存: エンティティAがエンティティBに関係し、エンティティBがエンティティCに関係し、エンティティCが再びエンティティAに戻る。たまに必要になることもあるが、多くの場合、データの正規化が適切に行われていないことを示している。
- キーの欠落: 主キーが存在しない、または外部キーが定義された親にリンクしていない。これにより、参照整合性が破壊される。
- 原子的でない値: 1つのカラムに複数の情報が含まれており、たとえば「名前」と「姓」が1つのフィールドに結合されている、またはタグのリストがカンマ区切りの文字列として保存されているなど。
このような兆候が見られたら、図はデータモデルが実装準備ができていないことを示している。このような図をもとに進むと、技術的負債を招くことになる。次のセクションでは、確立された理論的枠組みを使ってこれらの問題に対処する方法を詳述する。
🧠 根本原因:なぜモデルは失敗するのか
なぜER図が壊れているように見えるのかを理解するには、設計プロセスを検討する必要がある。多くの失敗は、構造よりもスピードを優先することに起因する。開発者が機能を急いで構築するとき、すぐに必要なクエリに合うテーブルを作成しがちだが、広範なデータ整合性の要件を無視してしまう。
1. 正規化を無視する
正規化とは、データの重複を減らし、データ整合性を高めるためにデータを整理するプロセスである。このステップを飛ばすことが、スキーマが壊れる最も一般的な理由である。正規化を行わなければ、ある場所で情報を更新しても他の場所に反映されないデータ異常のリスクがある。
- 第一正規形(1NF):すべてのカラムが原子的な値を含むことを保証する。カラムにリストが格納されている場合、そのテーブルは1NFにない。
- 第二正規形(2NF):テーブルが1NFにあることを要求し、すべての非キー属性が主キーに完全に依存していることを保証する。これにより部分的依存を防ぐ。
- 第三正規形(3NF):テーブルが2NFにあることを要求し、推移的依存関係が存在しないことを保証する。言い換えれば、キーでない属性は他のキーでない属性に依存してはならない。
図面にキーではなく他の列に依存する列が表示されている場合、正規化の問題がある。これはしばしば広すぎるテーブルを生じ、効率的なクエリが困難になる。
2. 極性の誤解
基数はエンティティのインスタンス間の数的関係を定義する。これを誤解すると、非効率な結合や複雑なクエリが生じる。よくある誤りは、多対多の関係を2つのテーブル間の直接的なリンクとしてモデル化することである。実際には、中間テーブルが存在しない限り、標準的なリレーショナル構造では直接的なリンクは存在できない。
- 1対1:セキュリティや専用データに使用される。高トラフィックシステムではほとんど使われない。
- 1対多:最も一般的な関係。1つの親が複数の子を持つことができる。
- 多対多:中間テーブルが必要である。この橋渡しテーブルを作成しないと、データ整合性の問題が生じる。
3. 悪い命名規則
読みにくい図は、誤って使われる図である。snake_caseとcamelCaseを混在させたり、”Table1″や”Table2″のような一般的な名前を使用したりすると、一貫性が失われる。Table1 および Table2認知負荷を生じる。開発者がテーブルが何を表しているかすぐに理解できないと、バグを引き起こす仮定をすることになる。
🛠️ 修復のための永続的原則
壊れた図を修正するには、新しいツールやトレンドのメソドロジーは必要ない。リレーショナル理論の核心原則を適用すればよい。これらの原則は、データの本質的な性質に取り組んでいるため、時代を経ても通用している。
1. 原子性と粒度
原子性の原則は、テーブル内の各セルが単一の値を保持すべきであると規定している。たとえば「住所」の列がある場合、理想は「通り名」「市区町村」「都道府県」「郵便番号」に分割することである。これにより、文字列を解析せずに住所の特定部分をクエリできる。この粒度の細かさは、将来のレポート要件に応じたデータの柔軟性を高める。
2. 独自識別
すべてのエンティティには独自の識別子が必要である。それがプライマリキーである。これがないと、特定の行を信頼できるように参照できない。図面に明示的なプライマリキーがなく、変更される可能性のある自然キー(例:メールアドレス)に依存している場合、データのずれのリスクがある。内部的な安定性のために、代替キー(自動増分整数やUUIDなど)を使用する。
3. 参照整合性
この原則は、テーブル間のリンクが有効な状態を保つことを保証する。顧客を削除した場合、その顧客の注文はどうなるか? 図面は削除や更新のルールを反映すべきである。これは通常、外部キーによって管理される。壊れた図では、外部キーが何にも指向していない、または許されない場所でnull値を許可していることがよくある。
4. 必要な機能の分離
異なる概念を別々のテーブルに保持する。ユーザーのプロフィールデータと認証資格情報を、特に明確な理由がない限り、同じテーブルに混在させてはならない。この分離により、データの異なる部分を独立してスケーリングおよびセキュリティ対策を施すことができる。
📊 一般的な落とし穴と標準的な解決策
以下の表は、設計が不十分なERDで見られる一般的な誤りと、データベース理論に基づく標準的な是正措置を要約したものである。
| 落とし穴 | 視覚的な症状 | 根本原因 | 標準的な解決策 |
|---|---|---|---|
| 重複データ | 複数のテーブルに同じ情報が存在する | 3NFの違反 | テーブルを正規化する;重複する列を削除する |
| 欠落している関係性 | 孤立したボックス | 仮定された論理 | 明示的な外部キーを定義する |
| 多対多の直接リンク | 複数側のエンティティ同士をつなぐ線 | 関係制約 | 結合テーブルを導入する |
| 複合キー | 複数の列を主キーとして使用する | 複雑さのリスク | 可能な限り擬似キーを使用する |
| NULL値が多い列 | 列に多くの空セルがある | オプションデータの管理不全 | オプション属性用に別テーブルを作成する |
| スパゲッティロジック | あちこちで線が交差している | リファクタリングが省略された | エンティティをドメインごとにグループ化する;論理的に再描画する |
🔄 修復プロセス:ステップバイステップのフレームワーク
破損した図を修正することは体系的なプロセスです。忍耐力と再構築する意欲が必要です。すぐに修正を適用しようとしないでください。まず現在の状態を理解しましょう。
ステップ1:監査
まず、存在するものを文書化することから始めましょう。すべてのテーブルの機能を既に把握していると仮定しないでください。各カラムの目的と想定されるデータ型を記述するデータ辞書を作成してください。これにより、スキーマの現実に向き合うことになります。リストを格納しているカラム、文字列として日付が保存されているカラム、テキストと混在したIDを確認してください。
- すべてのエンティティとその属性をリストアップしてください。
- すべての既存の関係性とその種類を特定してください。
- 重複しているか曖昧に見えるデータを強調してください。
ステップ2:リファクタリング
監査が終わったら、正規化ルールを適用してください。広いテーブルをより狭いテーブルに分割します。繰り返しグループを別々のテーブルに移動します。すべてのテーブルに主キーがあることを確認してください。Many-to-Many関係がブリッジテーブルなしで存在する場合、ブリッジテーブルを作成してください。このステップで本格的な作業が行われます。
ビジネスルールを検討してください。ユーザーが複数の住所を持つことができる場合、AddressテーブルはUserテーブルとは独立して存在しなければなりません。関係性は、特定の制約に応じてリンクテーブルまたは外部キーによって管理されます。
ステップ3:検証
リファクタリング後は、新しい設計を検証してください。循環依存関係がないか確認してください。レコードの削除が意図しない場合、他のレコードを孤立させないことを確認してください。すべての外部キーが有効な主キーを指していることを確認してください。元の要件と照らし合わせて健全性チェックを行い、新しい構造が必要なクエリを引き続きサポートしていることを確認してください。
ステップ4:ドキュメント化
文書化されていない図は、再び壊れる図です。エンティティにコメントを追加してください。複雑な関係性の背後にあるビジネスロジックを説明してください。これにより、将来の開発者が構造の「なぜ」を理解できるようになります。単に「何」なのかだけではなく、その理由を理解できるようにします。
🛡️ 長期的な整合性の維持
完璧に設計された図であっても、時間の経過とともに劣化する可能性があります。要件が変化し、新しい機能が追加され、手抜きが行われる中で、健全なスキーマを維持するには、メンテナンス戦略が必要です。
- 定期的なレビュー:スキーマの定期的なレビューをスケジュールしてください。エントロピーの兆候を探してください。新しいテーブルは同じ命名規則に従っていますか?関係性は一貫していますか?
- バージョン管理:ERDをコードのように扱いましょう。バージョン管理システムに保存してください。これにより、変更履歴を追跡でき、変更によってエラーが発生した場合に元に戻すことができます。
- 制約の強制:データベースの制約を使って、図で定義したルールを強制してください。無効なデータを防ぐためにアプリケーションロジックにのみ頼ってはいけません。図でフィールドが必須とされている場合、データベースがその制約を強制すべきです。
- コミュニティ標準:組織内で標準を採用してください。命名規則、キーの種類、関係性の表記方法に関わらず、一貫性があることで摩擦が減少します。
📝 最良の実践の要約
堅牢なデータベーススキーマを構築することは、規律の問題です。長期的な安定性を犠牲にして、すぐに動くようにすることに誘惑に抵抗することです。これらの原則に従うことで、データモデルが柔軟かつ信頼性を保つことを確実にできます。
- 常にデータを正規化して、重複を減らしてください。
- すべての関係性に対して明確な基数を定義してください。
- 安定性を保つために、サーロゲートキーを使用してください。
- あなたの意思決定とビジネスルールを文書化してください。
- 劣化を防ぐために、スキーマを定期的に見直してください。
破損したER図は失敗ではなく、データに対する理解を洗練する機会です。これらの永続的な原則を適用することで、混沌とした状態を、アプリケーションの成長を支える構造化された資産に変えることができます。今日図を整理するための努力は、明日のデバッグに何時間も費やすことを防ぎます。🚀
思い出してください。目的は単にボックスの間に線を引くことではありません。目的は、ビジネスデータの現実を正確に反映する地図を作成することです。図が整合性、正規化、明確性の原則に合致しているとき、データベースは自信を持って構築できる基盤になります。

