











डेटा आर्किटेक्चर की दुनिया में, लीगेसी सिस्टम में डेटा अतिरेक की समस्या के बराबर कोई चुनौती बहुत कम है। जब संगठन अपने इंफ्रास्ट्रक्चर को आधुनिक बनाने की कोशिश करते हैं, तो डुप्लीकेट, असंगत और अनाथ डेटा की विशाल मात्रा अक्सर प्राथमिक बाधा बन जाती है। यह केस स्टडी एक वास्तविक दुनिया के परिदृश्य का अध्ययन करती है जहां एक विस्तृत एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) एक प्रमुख माइग्रेशन प्रोजेक्ट के दौरान महत्वपूर्ण डेटा इंटीग्रिटी की समस्याओं को हल करने के लिए ब्लूप्रिंट के रूप में काम किया।
उद्देश्य स्पष्ट था: एक टुकड़े-टुकड़े, फ्लैट-फाइल आधारित लीगेसी वातावरण से एक विश्वसनीय संबंधात्मक डेटाबेस में स्थानांतरित करना, बिना डेटा विश्वसनीयता के नुकसान या नए असंगतियों के जोड़े। समाधान न तो माइग्रेशन टूल में था, बल्कि एक बाइट भी नहीं हटाए जाने से पहले डेटा के दृश्य मॉडलिंग और तार्किक संरचना में था। हम विधि का अध्ययन करते हैं, जिसमें विशिष्ट नॉर्मलाइजेशन चुनौतियां आईं, और डेटाबेस स्कीमा डिजाइन के एक अनुशासित दृष्टिकोण के लिए भावी परिणामों का विश्लेषण करते हैं।
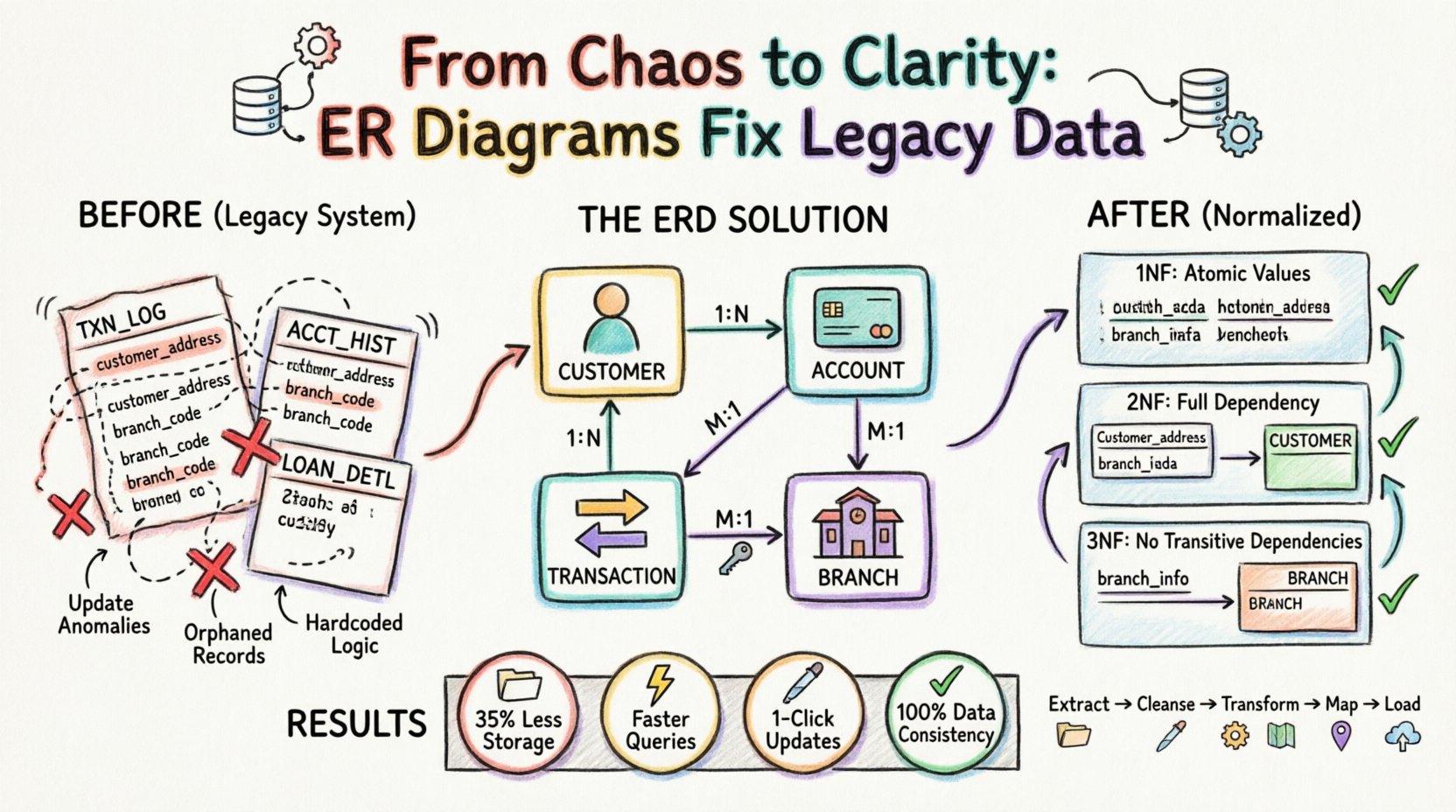
🔍 लीगेसी डेटा संरचनाओं की चुनौती
लीगेसी सिस्टम अक्सर दशकों तक डेटा ऋण जमा करते हैं। उन्हें उनके समय की विशिष्ट आवश्यकताओं के लिए बनाया गया था, जिसमें लंबे समय तक रखरखाव की तुलना में विकास की गति को प्राथमिकता दी गई थी। यहां विश्लेषण किए गए परिदृश्य में, स्रोत सिस्टम ने वर्षों तक बढ़ते अपडेट के दौरान एक जोड़ी वृक्षाकार और फ्लैट-फाइल संरचनाओं का उपयोग किया था।
लीगेसी स्थिति की मुख्य विशेषताएं शामिल थीं:
- कड़े नियमों का लॉजिक:व्यावसायिक नियमों को एप्लिकेशन कोड के भीतर सीधे एम्बेड किया गया था, बल्कि डेटाबेस स्तर पर लागू नहीं किया गया था।
- अनॉर्मलाइज्ड स्टोरेज:आधुनिक इंडेक्सिंग के अभाव में पढ़ने के प्रदर्शन में सुधार करने के लिए, डेटा को अक्सर कई तालिकाओं में दोहराया जाता था।
- संदर्भात्मक अखंडता की कमी:विदेशी कुंजी सीमाओं को अक्सर लागू नहीं किया जाता था, जिससे अनाथ रिकॉर्ड्स का फैलाव होता रहता था।
- असंगत नामकरण प्रथाएं:पहचानकर्ता बहुत अलग-अलग थे, जिससे स्वचालित मैपिंग करना मैनुअल हस्तक्षेप के बिना लगभग असंभव बन गया।
इस वातावरण ने एक उच्च जोखिम पैदा किया अपडेट विचलन. यदि एक ग्राहक का पता बदल गया, तो इसे दर्जनों अलग-अलग तालिकाओं में अपडेट करना था। हर एक उदाहरण को अपडेट करने में विफलता से डेटा असंगति उत्पन्न होती थी। इसके अलावा, इन्सर्ट विचलन मौजूदा रिकॉर्ड्स की दोहराव के बिना नए डेटा के जोड़ने को रोकता था, और डिलीट विचलन असंबंधित रिकॉर्ड्स को हटाए जाने पर महत्वपूर्ण जानकारी खोने का खतरा था।
🛠️ एंटिटी-रिलेशनशिप डायग्राम की भूमिका
एक एंटिटी-रिलेशनशिप डायग्राम केवल एक ड्राइंग से अधिक है; यह डेटा और उन एप्लिकेशनों के बीच एक तार्किक समझौता है जो इसका उपयोग करते हैं। इस माइग्रेशन में, ईआरडी एकमात्र सच्चाई का स्रोत बन गया। इसने टीम को संबंधों को स्पष्ट रूप से परिभाषित करने, प्राथमिक कुंजियों को पहचानने और भागीदारी के नियमों को बनाने के लिए मजबूर किया, जब तक भौतिक कार्यान्वयन शुरू नहीं हुआ।
इस विशिष्ट प्रोजेक्ट के लिए ईआरडी क्यों महत्वपूर्ण थी?
- जटिलता को दृश्याकरण करना: लीगेसी डेटा संबंध अस्पष्ट थे। डायग्राम ने छिपे हुए निर्भरताओं को स्पष्ट कर दिया।
- नॉर्मलाइजेशन के लागू करना: मॉडल ने टीम को अतिरेक को व्यवस्थित ढंग से दूर करने के लिए नॉर्मलाइजेशन नियमों को लागू करने की आवश्यकता महसूस कराई।
- मैपिंग गाइड: इसने पुराने, नॉर्मलाइज्ड तालिकाओं में लीगेसी कॉलम को मैप करने के लिए स्पष्ट मार्ग प्रदान किया।
- हितधारक संचार: इसने व्यापार विश्लेषकों को वास्तविक व्यापार प्रक्रियाओं के विरुद्ध तर्क की पुष्टि करने में सक्षम बनाया।
📂 केस स्टडी स्थिति: रिटेल बैंकिंग संगठन
इस विश्लेषण के लिए, हम एक रिटेल बैंकिंग संस्था को एक मेनफ्रेम युग के प्रणाली से क्लाउड-आधारित संबंधात्मक डेटाबेस में स्थानांतरित करने के बारे में विचार करते हैं। पुरानी प्रणाली ग्राहक खातों, लेनदेन और ऋण रिकॉर्ड का प्रबंधन करती थी। हालांकि, प्रणाली के उम्र के कारण, ग्राहक की जानकारी लेनदेन लॉग में बार-बार संग्रहीत की जाती थी।
ERD विश्लेषण से पहले:
| तालिका नाम | मुख्य कुंजी | आवर्धित डेटा | समस्या |
|---|---|---|---|
| TXN_LOG | TXN_ID | ग्राहक का नाम, पता | पते में बदलाव करने के लिए हजारों पंक्तियों को अपडेट करने की आवश्यकता होती है। |
| ACCT_HIST | HIST_ID | शाखा कोड, शाखा स्थान | शाखा बंद होने से डेटा संघर्ष होते हैं। |
| LOAN_DETL | LOAN_ID | ग्राहक आईडी, खाता आईडी | लिंक अक्सर गायब होते हैं या डुप्लीकेट होते हैं। |
इस संरचना ने डेटाबेस डिजाइन के मूल सिद्धांतों का उल्लंघन किया। ERD प्रक्रिया में इन तालिकाओं को परमाणु, स्वतंत्र एकांकी में तोड़ने की आवश्यकता थी।
🧩 चरण 1: एकांकी और संबंधों की पहचान करना
स्थानांतरण के पहले चरण में पुरानी प्रणाली से हर तालिका और कॉलम को निकालना शामिल था। टीम ने इन्हें तार्किक एकांकी में मैप किया। लक्ष्य व्यापार क्षेत्र में अलग-अलग वस्तुओं की पहचान करना था।
- ग्राहक: एक विशिष्ट व्यक्ति या संस्था जो एक खाता रखती है।
- खाता: एक विशिष्ट वित्तीय उत्पाद जो ग्राहक द्वारा रखा जाता है।
- लेनदेन: एक खाते से जुड़े धन के हस्तांतरण।
- शाखा: एक भौतिक स्थान जहाँ बैंकिंग संचालन होते हैं।
जब एकताओं को परिभाषित कर लिया गया, तो संबंध स्थापित किए गए। ईआरडी ने यह बताया कि एक ग्राहक एक से अधिक खातों के साथ हो सकता है। एक खाते में एक से अधिक लेनदेन हो सकते हैं। एक लेनदेन एक विशिष्ट शाखा से जुड़ा होता है। इन संबंधों को आमतौर पर निम्नलिखित रूप में दर्शाया जाता है:
- एक से बहुत अधिक (1:N): एक ग्राहक से बहुत सारे खाते।
- एक से बहुत अधिक (1:N): एक खाता से बहुत सारे लेनदेन।
- बहुत से एक (M:1): बहुत सारे लेनदेन एक शाखा के लिए।
इन संबंधों को दृश्य रूप से मैप करके, टीम ने यह पहचाना कि डेटा कहाँ दोहराया जा रहा था। उदाहरण के लिए, ग्राहक का नाम TXN_LOG तालिका में दिखाई देता था। एक सामान्यीकृत मॉडल में, लेनदेन तालिका केवल ग्राहक तालिका के संदर्भ (विदेशी कुंजी) को ही रखनी चाहिए, डेटा को नहीं।
📐 चरण 2: सामान्यीकरण नियमों के लागू करना
सामान्यीकरण डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता कम होती है और अखंडता में सुधार होता है। ईआरडी मॉडल ने टीम को मानक सामान्य रूपों के माध्यम से गाइड किया।
पहला सामान्य रूप (1NF)
पुराना सिस्टम में दोहराए जाने वाले समूह थे। उदाहरण के लिए, पुराने ग्राहक तालिका में एक ही पंक्ति में एक ही कॉलम में कई फोन नंबर हो सकते थे (उदाहरण के लिए, “555-0199, 555-0200”)।
- समस्या: इससे एक विशिष्ट फोन नंबर के लिए प्रश्न पूछना मुश्किल हो जाता है और परमाणुता का उल्लंघन होता है।
- ईआरडी समाधान: एक अलग संपर्क_जानकारी एकता जो ग्राहक एकता से जुड़ी है। इस नई तालिका में प्रत्येक पंक्ति में बिल्कुल एक फोन नंबर होता है।
दूसरा सामान्य रूप (2NF)
2NF की आवश्यकता है कि तालिका 1NF में हो और सभी गैर-कुंजी विशेषताएं मुख्य कुंजी पर पूरी तरह निर्भर हों। पुराने TXN_LOG तालिका में TXN_ID और दिनांक के संयुक्त कुंजी थी। हालांकि, ग्राहक विवरण केवल ग्राहक_आईडी, लेनदेन की तारीख नहीं।
- समस्या: ग्राहक डेटा प्रत्येक लेनदेन के लिए दोहराया जाता था, जिससे अपडेट विचलन होते थे।
- ERD समाधान: लेनदेन तालिका से ग्राहक विवरण हटाएं। उन्हें एक समर्पित ग्राहक तालिका में संग्रहीत करें और उन्हें एक विदेशी कुंजी के माध्यम से जोड़ें।
तृतीय सामान्य रूप (3NF)
3NF की आवश्यकता है कि सभी गुणधर्म केवल मुख्य कुंजी पर निर्भर करें, कोई अंतरित निर्भरता न हो। पुरानी प्रणाली में, शाखा का नाम और पता खाता तालिका में संग्रहीत था, लेकिन वे शाखा_आईडी, नहीं खाता_आईडी.
- समस्या: यदि कोई शाखा स्थान बदलती है, तो उस शाखा से जुड़े सभी खाता रिकॉर्ड को अपडेट करने की आवश्यकता होती है।
- ERD समाधान: एक स्वतंत्र शाखा तालिका बनाएं।
खातातालिका अब केवलशाखा_आईडी.
🔄 चरण 3: माइग्रेशन क्रियान्वयन रणनीति
नए ERD को परिभाषित करने के बाद, माइग्रेशन योजना नए स्कीमा के चारों ओर संरचित थी। प्रक्रिया सरल कॉपी-पेस्ट नहीं थी; यह एक रूपांतरण था।
- डेटा निकासी:पुराने स्रोत प्रणालियों से ब्राउज़ किया गया डेटा एक स्टेजिंग क्षेत्र में खींचा गया था।
- सफाई:दोहरे रिकॉर्ड की पहचान की गई और एरडी में परिभाषित व्यावसायिक कुंजियों के आधार पर इन्हें मिलाया गया।
- रूपांतरण:1NF, 2NF और 3NF नियमों के अनुसार अनियमित कॉलम को नए तालिकाओं में विभाजित करने के लिए स्क्रिप्ट लिखी गईं।
- मैपिंग:नए तालिकाओं को जोड़ने के लिए विदेशी कुंजियाँ बनाई गईं। अनुकूल कुंजियाँ (सिस्टम-उत्पन्न आईडी) का उपयोग इस बात की गारंटी करने के लिए किया गया जो पुरानी व्यावसायिक कुंजियों से स्वतंत्र स्थिरता सुनिश्चित हो।
- लोडिंग:डेटा को रेफरेंशियल इंटीग्रिटी (माता-पिता पहले, बच्चे बाद में) का सम्मान करते हुए एक विशिष्ट क्रम में लक्षित डेटाबेस में डाला गया।
एरडी यहाँ निर्णायक थी। इसने लोड क्रम का निर्धारण किया। उदाहरण के लिए, ग्राहक तालिका को पहले भरना था, फिर खाता तालिका, जिसे पहले भरना था, फिर लेनदेन तालिका। किसी अन्य क्रम में लोड करने की कोशिश करने पर नियम उल्लंघन होगा।
✅ चरण 4: पुष्टीकरण और परीक्षण
पोस्ट-माइग्रेशन पुष्टीकरण व्यापक था। लक्ष्य यह सुनिश्चित करना था कि डेटा का योग संरचना बदलने के बावजूद स्थिर रहे। टीम ने डेटा की अपेक्षित स्थिति को परिभाषित करने के लिए एरडी का उपयोग किया।
इंटीग्रिटी जांच
- रेफरेंशियल इंटीग्रिटी: सुनिश्चित करें कि प्रत्येक
ग्राहक_आईडीखाता तालिका में ग्राहक तालिका में मौजूद है। - पूर्णता:सुनिश्चित करें कि रूपांतरण प्रक्रिया के दौरान कोई रिकॉर्ड नहीं गुम हुआ।
- एकाकीपन:सुनिश्चित करें कि प्राथमिक कुंजियाँ अद्वितीय हैं और नए तालिकाओं में कोई दोहराव नहीं है।
तुलना मापदंड
निम्नलिखित मापदंडों का उपयोग स्रोत और लक्षित प्रणालियों की तुलना के लिए किया गया:
| सत्यापन मापदंड | लक्ष्य मानक | विधि |
|---|---|---|
| रिकॉर्ड गिनती | स्रोत गिनती = लक्ष्य गिनती | प्रति सामान्यीकृत एकाई पंक्ति गिनती |
| मानों का योग | कुल बैलेंस स्रोत = कुल बैलेंस लक्ष्य | संख्यात्मक क्षेत्रों का संग्रह |
| नॉल चेक | NOT NULL कॉलम में अप्रत्याशित शून्य NULLs | प्रश्न सीमाएँ |
| दोहराए गए चेक | प्राथमिक कुंजियों पर शून्य दोहराए गए | GROUP BY विश्लेषण |
📉 अतिरिक्तता कमी का प्रभाव
पुरानी संरचना से सामान्यीकृत ERD मॉडल में स्थानांतरण ने प्रदर्शन और रखरखाव में मापने योग्य सुधार किया।
- स्टोरेज दक्षता: ग्राहक के दोहराए गए पते और शाखा विवरण हटाकर, स्टोरेज की आवश्यकता लगभग 35% तक कम हो गई।
- प्रश्न प्रदर्शन: पहले बड़ी, असामान्य तालिकाओं को स्कैन करने की आवश्यकता वाले प्रश्नों को छोटी, सूचीबद्ध तालिकाओं के जोड़कर तेज कर दिया गया।
- अद्यतन गति: एक ग्राहक के पते के अद्यतन के लिए अब केवल एक पंक्ति के अद्यतन की आवश्यकता होती है ग्राहक तालिका, लेनदेन लॉग में हजारों अद्यतन के बजाय।
- डेटा सुसंगतता: विरोधाभासी डेटा के जोखिम (उदाहरण के लिए, एक ही ग्राहक के दो अलग-अलग पते) को एकमात्र सत्य स्रोत के बल पर दूर कर दिया गया।
🛡️ किनारे के मामलों और पुराने डेटा का प्रबंधन
पुराने मार्ग के आधार पर आगे बढ़ने के सबसे कठिन पहलू में से एक है पुराने डेटा का प्रबंधन जो नए मॉडल में फिट नहीं होता है। ERD ने इन अपवादों को बेहतर तरीके से संभालने के तरीके को परिभाषित करने में मदद की।
- अनाथ रिकॉर्ड: उन लेनदेन को चिह्नित किया गया जो उन ग्राहकों से जुड़े थे जो स्रोत में अब मौजूद नहीं थे। टीम ने इन्हें एक तालिका में संग्रहीत करने का निर्णय लिया ताकि निरीक्षण के ट्रेल बनाए रखे बिना नए संबंधों को नष्ट न किया जाए।ऐतिहासिक_पुरानातालिका ताकि नए संबंधों को नष्ट न किया जाए बल्कि निरीक्षण के ट्रेल बनाए रखे जा सकें।
- गायब कुंजियाँ: ऐसे मामलों में जहां पुराने सिस्टम में ग्राहक आईडी गायब थी, माइग्रेशन स्क्रिप्ट ने एक अस्थायी स्थानापन्न आईडी बनाई और रिकॉर्ड को मैन्युअल समीक्षा के लिए चिह्नित कर दिया।
- मृदु डिलीट: भौतिक रूप से रिकॉर्ड को हटाने के बजाय, नए स्कीमा में एक शामिल था
सक्रिय हैझंडी। इसने इतिहास को बनाए रखा जबकि सक्रिय रिपोर्ट्स को केवल वर्तमान डेटा के लिए प्रश्न पूछने की गारंटी दी।
🚀 स्कीमा को भविष्य के लिए तैयार करना
ईआरडी को केवल वर्तमान माइग्रेशन के लिए नहीं डिज़ाइन किया गया था; इसे भविष्य के विकास को स्वीकार करने के लिए बनाया गया था। नॉर्मलाइजेशन सिद्धांतों का पालन करके, स्कीमा इतनी लचीली हो गई कि नई सुविधाओं का समर्थन करने के लिए संरचनात्मक पुनर्संरचना के बिना भी उपयोग किया जा सकता था।
- स्केलेबिलिटी: एंटिटीज के अलगाव के कारण क्षैतिज स्केलिंग संभव हो जाती है। उदाहरण के लिए, लेनदेन तालिका को तारीख के आधार पर शेड किया जा सकता है बिना ग्राहक तालिका के प्रभाव के बिना।
- विस्तार्यता: यदि एक नया उत्पाद प्रकार (उदाहरण के लिए, मोर्टगेज) जोड़ा जाता है, तो इसे मौजूदा ग्राहक और खाता एंटिटीज से जोड़ा जा सकता है बिना मूल स्कीमा के बदले।
- दस्तावेज़ीकरण: ईआरडी जीवंत दस्तावेज़ीकरण के रूप में कार्य करता है। नए डेवलपर्स आरेख की समीक्षा करके डेटा मॉडल को तुरंत समझ सकते हैं, जिससे ऑनबोर्डिंग समय कम हो जाता है।
💡 डेटा आर्किटेक्ट्स के लिए मुख्य बातें
यह केस स्टडी समान प्रकार के माइग्रेशन कर रही टीमों के लिए कई महत्वपूर्ण पाठों को उजागर करती है।
- माइग्रेशन से पहले मॉडल बनाएं: कभी भी एक प्रमाणित स्कीमा डिज़ाइन के बिना डेटा को एक नए सिस्टम में ले जाने की कोशिश न करें। ईआरडी ब्लूप्रिंट है।
- पुनरावृत्ति को हल करने के लिए नॉर्मलाइज़ करें: नॉर्मलाइजेशन से डरें नहीं। यह डेटा असंगति के खिलाफ मुख्य रक्षा है।
- निरंतर वैधता की जांच करें: परिवर्तन के हर चरण पर परीक्षण किया जाना चाहिए, अंत में नहीं।
- संबंधों को दस्तावेज़ करें: कार्डिनैलिटी को समझें। यह जानना कि कोई संबंध 1:1 है या 1:N, डेटा मॉडल में तार्किक त्रुटियों को रोकता है।
- इतिहास को सुरक्षित रखें: परिवर्तन केवल वर्तमान डेटा के बारे में नहीं है; यह अतीत की अखंडता को बनाए रखने के बारे में है।
🔗 डेटा अखंडता पर निष्कर्ष
पुराने सिस्टम से आधुनिक डेटाबेस में संक्रमण अक्सर एक सरल लिफ्ट-एंड-शिफ्ट नहीं होता है। इसमें डेटा के व्यवस्थापन के तरीके के आधारभूत पुनर्विचार की आवश्यकता होती है। एंटिटी-रिलेशनशिप डायग्राम इस प्रक्रिया में सबसे मूल्यवान संपत्ति साबित हुआ। इसने अतिरिक्त संरचनाओं को तोड़ने और अखंडता के साथ उन्हें फिर से बनाने के लिए आवश्यक स्पष्टता प्रदान की।
त्वरित कार्यान्वयन के बजाय तार्किक डिज़ाइन को प्राथमिकता देकर, संगठन ने एक स्थिर, स्केलेबल और संगत डेटा वातावरण प्राप्त किया। अतिरिक्तता में कमी ने संचालन जोखिम के एक महत्वपूर्ण स्रोत को समाप्त कर दिया और भविष्य के विश्लेषण और व्यापार बुद्धिमत्ता पहलों के लिए एक मजबूत आधार रखा।
डेटा अतिरिक्तता केवल स्टोरेज समस्या नहीं है; यह एक व्यापार जोखिम है। तीव्र मॉडलिंग के माध्यम से इसका समाधान सुनिश्चित करता है कि डेटा निर्णय लेने के लिए एक विश्वसनीय संपत्ति बनी रहे, बल्कि उन्नति को रोकने वाली एक दायित्व नहीं।

