











El cambio desde la infraestructura tradicional en instalaciones propias hacia entornos nativos en la nube representa un cambio fundamental en la forma en que se almacena, accede y gestiona la información. Para los administradores de bases de datos (DBAs), esta transición requiere más que simplemente migrar esquemas existentes. Exige una reevaluación de los diagramas entidad-relación (ERD) para alinearse con las restricciones y capacidades únicas de los sistemas distribuidos. Esta guía ofrece una visión completa sobre el diseño de diagramas ER que respalden la escalabilidad, la resiliencia y el rendimiento en arquitecturas de nube modernas. 📊
Entendiendo el cambio en la arquitectura de datos 🔄
El diseño tradicional de bases de datos suele priorizar la normalización estricta y el control centralizado. En contraste, las arquitecturas nativas en la nube enfatizan la disponibilidad, la tolerancia a particiones y la escalabilidad horizontal. La diferencia fundamental radica en la suposición de fallos. En una configuración monolítica, la base de datos es un único punto de fallo. En un entorno nativo en la nube, los nodos fallan con frecuencia, y el sistema debe adaptarse de inmediato.
Al diseñar diagramas ER para este entorno, los DBAs deben considerar:
- Consistencia distribuida:¿Cómo se mantienen las relaciones cuando los datos se dividen entre regiones?
- Latencia:¿Cómo afecta la distancia física entre los nodos de datos al rendimiento de las consultas?
- Costo:¿Cuál es el equilibrio entre la redundancia de almacenamiento y los costos de transacción?
- Complejidad operativa:¿Puede el esquema gestionarse sin intervención manual constante?
Ignorar estos factores puede llevar a sistemas que son difíciles de escalar o mantener. Un diagrama ER bien diseñado actúa como plano de flujo de datos, asegurando que la infraestructura subyacente pueda soportar la lógica de negocio sin cuellos de botella. 🚀
Principios fundamentales de los ERD nativos en la nube ⚙️
Antes de adentrarnos en patrones específicos, es esencial comprender los principios directrices que diferencian el modelado de datos nativos en la nube de los enfoques tradicionales.
1. Desacoplar los datos de la computación
En muchos sistemas heredados, el servidor de bases de datos y el servidor de aplicaciones están estrechamente acoplados. El diseño nativo en la nube separa estas preocupaciones. El ERD debe reflejar esto minimizando las dependencias que requieren comunicación síncrona entre servicios distintos.
2. Aceptar la flexibilidad del esquema
Mientras que las bases de datos SQL son rígidas, los entornos nativos en la nube a menudo utilizan persistencia políglota. Esto significa que tipos de datos diferentes podrían requerir modelos de almacenamiento distintos. El diagrama ER debe visualizar relaciones lógicas incluso si las implementaciones físicas varían (por ejemplo, almacenes JSON junto a tablas relacionales).
3. Optimizar para cargas de trabajo intensivas en lectura
Las aplicaciones en la nube suelen atender a millones de usuarios simultáneamente. El diseño ER debe soportar rutas de lectura eficientes, incluso si eso implica introducir cierta redundancia. La desnormalización se convierte en una herramienta estratégica, más que un pecado.
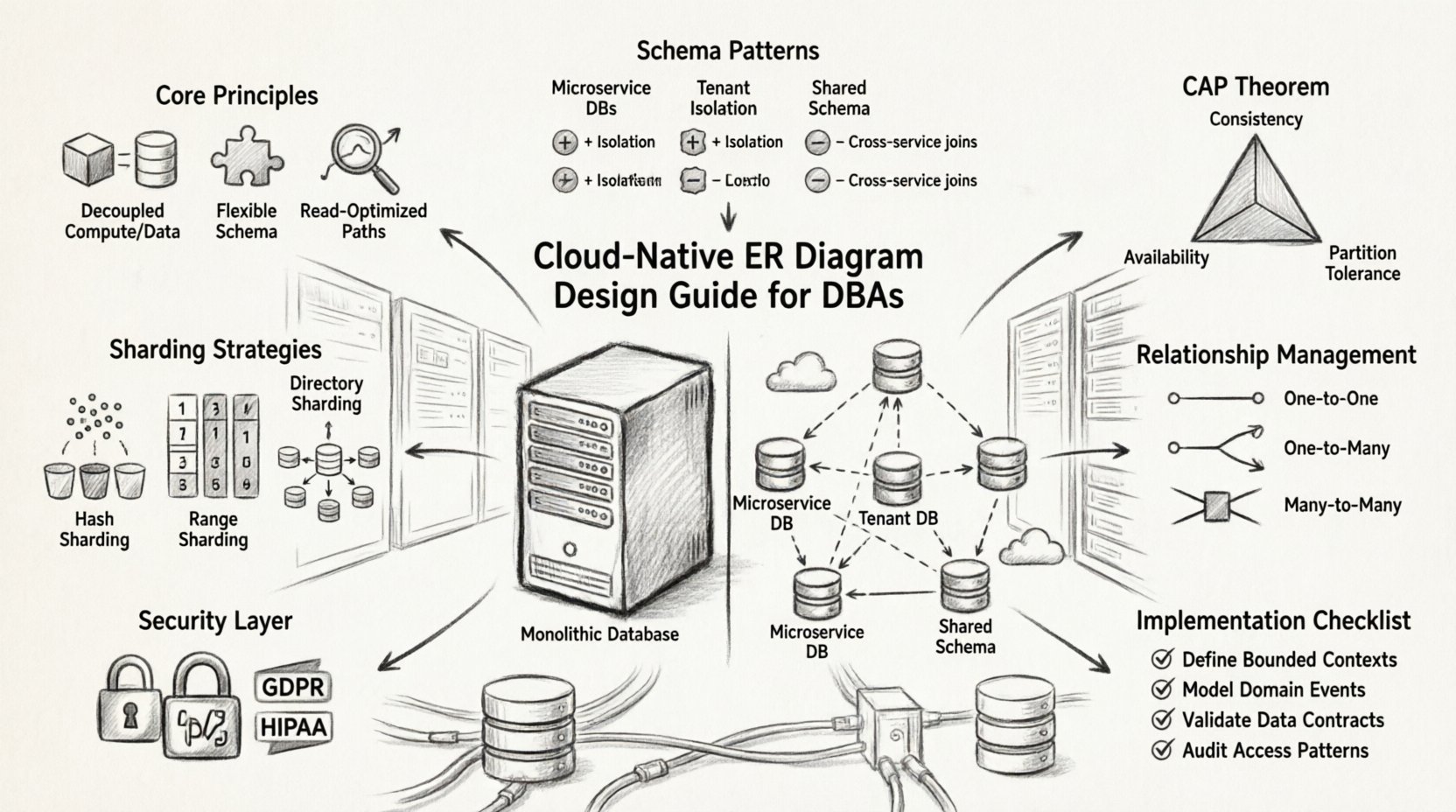
Patrones de diseño de esquemas para escalabilidad 📈
Seleccionar el patrón de esquema adecuado es crucial para el rendimiento. A continuación se presentan enfoques comunes utilizados en sistemas distribuidos.
Base de datos única por servicio
Cada microservicio gestiona su propio esquema de base de datos. Esta aislamiento evita que los fallos de un servicio se propaguen. El diagrama ER del sistema general se convierte en una colección de diagramas más pequeños e independientes conectados mediante referencias lógicas.
Base de datos compartida con separación de esquemas
Varios servicios comparten una única instancia de base de datos, pero mantienen espacios de nombres de esquema separados. Esto reduce los costos de infraestructura, pero introduce riesgos de acoplamiento estrecho. Generalmente se desaconseja para despliegues a gran escala en la nube.
Base de datos por cliente
En aplicaciones SaaS multi-tenant, cada cliente recibe una instancia de base de datos dedicada. El diseño del ERD debe mantenerse consistente en todas las instancias, asegurando que las migraciones y actualizaciones se apliquen de forma uniforme.
Comparación de patrones de esquema
| Patrón | Ventajas | Desventajas | Mejor caso de uso |
|---|---|---|---|
| Base de datos única | Uniones simples, cumplimiento ACID | Punto único de fallo, límites de escalabilidad | Aplicaciones monolíticas, bajo tráfico |
| Base de datos por servicio | Escalabilidad independiente, aislamiento de fallos | Transacciones complejas, uniones distribuidas | Microservicios, alto crecimiento |
| Base de datos por cliente | Aislamiento de datos, facilidad de cumplimiento | Alto costo de infraestructura, sobrecarga de gestión | Plataformas SaaS, industrias reguladas |
| Esquema compartido | Bajo costo, consultas compartidas | Atracción de proveedor, cuellos de botella de escalabilidad | Herramientas internas, MVPs |
Gestión de relaciones entre servicios 🔗
En una arquitectura distribuida, las claves foráneas no siempre son factibles. La integridad referencial debe gestionarse de forma diferente. El diagrama ER debe representar claramente estas relaciones lógicas, incluso si la aplicación física se realiza a nivel de la aplicación o mediante procesos asíncronos.
Tipos de relaciones
- Uno a uno:A menudo se maneja mediante la incorporación directa de datos para reducir la latencia de unión.
- Uno a muchos:Requiere una consideración cuidadosa sobre cómo se almacenan los registros secundarios. Si el padre se mueve, ¿los hijos también se mueven?
- Muchos a muchos:Generalmente se implementa mediante una tabla de asociación. En entornos en la nube, esta tabla podría necesitar ser particionada de forma independiente.
Manejo de la integridad referencial
Sin restricciones estrictas de claves foráneas, la consistencia de los datos depende de la lógica de la aplicación. Las estrategias incluyen:
- Eliminaciones suaves:Marcar los registros como inactivos en lugar de eliminarlos para preservar el historial.
- Consistencia eventual:Utilizar flujos de eventos para propagar cambios entre servicios.
- Transacciones compensatorias:Lógica de reversión que maneja los fallos en flujos de trabajo distribuidos.
Estrategias de particionado y fragmentación 🗂️
A medida que crece el volumen de datos, un único nodo de base de datos no puede manejar la carga. El particionado (fragmentación) divide los datos entre múltiples nodos. El diagrama ER debe indicar cómo se distribuyen los datos para evitar puntos calientes.
Claves de fragmentación
La elección de la clave de fragmentación determina cómo se enrutan las consultas. Una buena clave distribuye los datos de forma uniforme y se alinea con los patrones de acceso.
- Basado en hash:Distribuye los datos de forma aleatoria. Bueno para accesos uniformes, malo para consultas de rango.
- Basado en rango:Divide los datos por valor (por ejemplo, fechas o identificadores). Bueno para consultas de rango, con riesgo de distribución desigual.
- Basado en directorio:Mantiene un servicio de mapeo para localizar los datos. Añade latencia, pero permite una colocación flexible.
Impacto en los diagramas ER
Al diseñar el DER, tenga en cuenta que:
- Las tablas que se unen con frecuencia deberían idealmente ubicarse juntas para minimizar el tráfico de red.
- Las tablas globales (como los datos de configuración) deben permanecer sin fragmentar.
- Los índices deben diseñarse para funcionar dentro de los límites de fragmentación.
Modelos de consistencia y teorema CAP ⚖️
El teorema CAP establece que un sistema distribuido solo puede garantizar dos de las tres propiedades: consistencia, disponibilidad y tolerancia a particiones. Los sistemas nativos de la nube priorizan la tolerancia a particiones, lo que obliga a elegir entre consistencia y disponibilidad.
Elección del modelo adecuado
| Modelo | Descripción | Implicación en el DER |
|---|---|---|
| Consistencia fuerte | Todos los nodos ven los mismos datos al mismo tiempo | Requiere escrituras síncronas; limita el rendimiento de escritura |
| Consistencia eventual | Los datos se vuelven consistentes después de un retraso | Permite escrituras asíncronas; requiere manejar lecturas obsoletas |
| Consistencia causal | Mantiene el orden de las operaciones relacionadas causalmente | Seguimiento complejo de dependencias en el diagrama ER |
Para aplicaciones financieras, a menudo es necesario un consistencia fuerte. Para feeds sociales, la consistencia eventual es aceptable. El diagrama ER debe indicar qué tablas requieren un orden estricto y cuáles pueden tolerar retrasos.
Indexación para entornos de alto rendimiento 🏷️
Las estrategias de indexación en la nube difieren de las locales debido a los costos de almacenamiento y el ancho de banda de red. Cada índice consume recursos de escritura y espacio de almacenamiento.
Mejores prácticas de indexación
- Minimice los índices secundarios: Solo indexe las columnas utilizadas en predicados de consulta frecuentes.
- Considere los índices cubiertos: Incluya todas las columnas necesarias en el índice para evitar búsquedas en la tabla.
- Monitoree el uso de índices: Revise periódicamente el rendimiento del índice para eliminar estructuras no utilizadas.
- Índices particionados: Alinee las estructuras de índice con la estrategia de partición de datos.
Índices globales frente a locales
Los índices globales abarcan todas las particiones y pueden ser costosos de mantener. Los índices locales residen dentro de una partición y son más económicos. Al diseñar el diagrama ER, especifique cuáles índices son globales y cuáles son locales para guiar al equipo de infraestructura.
Consideraciones de seguridad y cumplimiento 🛡️
La seguridad de los datos en la nube implica cifrado, control de acceso y cumplimiento con regulaciones como el RGPD o la HIPAA. El diagrama ER debe reflejar los niveles de sensibilidad de los datos.
Clasificación de datos
Etiquete las entidades de datos según su sensibilidad:
- Público: No se requiere protección especial.
- Interno: Accesible únicamente por empleados.
- Restringido: Requiere cifrado y registro estricto de acceso.
Cifrado en reposo y en tránsito
Todos los campos sensibles deben marcarse para cifrado. El diagrama ER no debe almacenar datos sensibles en texto plano. En su lugar, debe hacer referencia a columnas cifradas o tokens.
Cumplimiento y retención
Algunos datos deben conservarse durante períodos específicos o eliminarse por completo. El diseño ER debe incluir campos de metadatos para políticas de retención y rastros de auditoría.
Versionado y evolución de esquemas 🔄
En entornos nativos en la nube, los tiempos de inactividad para cambios en el esquema son raros. Las migraciones deben realizarse en línea. El diagrama ER debe admitir estrategias de versionado.
Compatibilidad hacia atrás
Las nuevas versiones de esquema deben ser compatibles hacia atrás con la lógica de la aplicación. Esto permite la implementación gradual de cambios.
Patrones de migración
- Agregar columna: Agregar nuevos campos sin modificar los datos existentes.
- Escritura doble: Escribir en ambas estructuras, antigua y nueva, durante la transición.
- Cambio: Cambiar el tráfico de lectura y escritura una vez que los datos se hayan migrado.
- Eliminar columna: Eliminar campos no utilizados solo después de confirmar que no hay dependencias.
Errores comunes que deben evitarse ⚠️
Incluso los DBAs experimentados pueden cometer errores al adaptarse a diseños nativos en la nube. Aquí hay errores comunes.
- Sobrenormalización:Demasiadas uniones aumentan la latencia en sistemas distribuidos.
- Ignorar datos fríos:No archivar datos históricos puede aumentar los costos y ralentizar las consultas activas.
- Límites codificados: Establecer límites arbitrarios de filas en la aplicación que evitan las restricciones de la base de datos.
- Ignorar la latencia: Diseñar consultas que asumen acceso a datos locales cuando los datos son en realidad remotos.
- Puntos únicos de fallo Diseñando un nodo principal de base de datos que, si se pierde, detiene todo el sistema.
Lista de verificación de implementación ✅
Antes de implementar un esquema de base de datos nativa en la nube, revise la siguiente lista de verificación.
| Tarea | Prioridad | Estado |
|---|---|---|
| Definir la estrategia de particionamiento | Alta | No iniciado |
| Identificar los patrones de lectura/escritura | Alta | No iniciado |
| Planificar la consistencia eventual | Media | No iniciado |
| Diseñar respaldo y recuperación | Alta | No iniciado |
| Configurar alertas de monitoreo | Media | No iniciado |
| Revisar las políticas de seguridad | Alta | No iniciado |
Mantenimiento y monitoreo 🔍
Una base de datos nativa en la nube requiere monitoreo continuo. El diagrama ER no es un documento estático; evoluciona con la aplicación.
Métricas clave
- Latencia de consulta: Monitorear los tiempos promedio y el percentil p99 de respuesta.
- Utilización del grupo de conexiones:Asegúrese de que la aplicación pueda manejar cargas máximas.
- Crecimiento del almacenamiento:Prediga las necesidades futuras de capacidad.
- Tasas de error:Monitoree los fallos de transacciones y los reembolsos.
Automatización
Utilice herramientas automatizadas para detectar desviaciones en el esquema y hacer cumplir las normas. Se deben minimizar los cambios manuales en los esquemas de producción para reducir los errores humanos.
Conclusión 🏁
Diseñar diagramas ER para arquitecturas nativas en la nube es una tarea compleja que equilibra las restricciones técnicas con los objetivos empresariales. Al centrarse en la escalabilidad, los modelos de consistencia y la seguridad, los DBAs pueden construir sistemas que resisten el crecimiento y el cambio. La clave consiste en tratar el modelado de datos como un proceso continuo en lugar de una configuración única. Las revisiones periódicas y el cumplimiento de las mejores prácticas garantizan que la base de datos siga siendo una fundación confiable para la aplicación. 🌐

