











In der Welt der Datenarchitektur gibt es kaum eine Herausforderung, die so beständig ist wie das Problem der Datenredundanz innerhalb von Legacy-Systemen. Wenn Organisationen daran arbeiten, ihre Infrastruktur zu modernisieren, wird das enorme Volumen an doppelt vorhandenen, inkonsistenten und verwaisten Daten oft zur Hauptengpassstelle. Diese Fallstudie untersucht ein realweltliches Szenario, bei dem ein detailliertes Entity-Relationship-Diagramm (ERD) als Bauplan diente, um kritische Datenintegritätsprobleme während eines großen Migrationprojekts zu lösen.
Das Ziel war klar: Übergang von einer fragmentierten, auf flachen Dateien basierenden Legacy-Umgebung zu einer robusten relationalen Datenbank, ohne die Datenintegrität zu verlieren oder neue Inkonsistenzen einzuführen. Die Lösung lag nicht in dem Migrationstool selbst, sondern in der visuellen Modellierung und logischen Strukturierung der Daten, bevor überhaupt ein einziger Byte verschoben wurde. Wir untersuchen die Methodologie, die spezifischen Normalisierungs-Herausforderungen, die auftraten, und die greifbaren Ergebnisse eines disziplinierten Ansatzes bei der Schema-Design.
🔍 Die Herausforderung von Legacy-Datenstrukturen
Legacy-Systeme sammeln oft Datenverschuldung über Jahrzehnte hinweg. Sie wurden für die spezifischen Anforderungen ihrer Zeit entwickelt und setzten die Geschwindigkeit der Entwicklung gegenüber der langfristigen Wartbarkeit in den Vordergrund. In dem hier analysierten Szenario nutzte das Quellsystem eine Kombination aus hierarchischen und flachen Dateistrukturen, die über Jahre hinweg durch inkrementelle Updates zusammengefügt wurden.
Wichtige Merkmale des Legacy-Zustands waren:
- Hartkodierte Logik:Geschäftsregeln waren direkt im Anwendungscode verankert, anstatt auf Datenbankebene durchgesetzt zu werden.
- Dennormalisierte Speicherung:Um die Leseleistung zu verbessern, ohne moderne Indizierung zu nutzen, wurde die Daten häufig über mehrere Tabellen hinweg dupliziert.
- Fehlende Referenzintegrität:Fremdschlüsselbeschränkungen wurden selten durchgesetzt, was das Auftreten verwaister Datensätze ermöglichte.
- Inkonsistente Namenskonventionen:Die Bezeichner variierten stark, was eine automatisierte Zuordnung nahezu unmöglich machte, ohne manuelle Eingriffe.
Diese Umgebung schuf ein hohes Risiko fürAktualisierungsanomalien. Wenn sich eine Kundenadresse änderte, musste sie in Dutzenden verschiedener Tabellen aktualisiert werden. Der Fehler, jede Instanz zu aktualisieren, führte zu Dateninkonsistenzen. Außerdem verhindertenEinfügeanomalien die Hinzufügung neuer Daten ohne Duplizierung bestehender Datensätze, undLöschanomaliendas Risiko, wichtige Informationen zu verlieren, wenn unzusammenhängende Datensätze entfernt wurden.
🛠️ Die Rolle des Entity-Relationship-Diagramms
Ein Entity-Relationship-Diagramm ist mehr als nur eine Zeichnung; es ist ein logischer Vertrag zwischen den Daten und den Anwendungen, die sie nutzen. Bei dieser Migration fungierte das ERD als einzige Quelle der Wahrheit. Es zwang das Team, Beziehungen explizit zu definieren, Primärschlüssel zu identifizieren und Kardinalitätsregeln festzulegen, bevor die physische Implementierung begann.
Warum war das ERD für dieses spezifische Projekt entscheidend?
- Komplexität visualisieren: Die Beziehungen der Legacy-Daten waren undurchsichtig. Das Diagramm machte versteckte Abhängigkeiten sichtbar.
- Durchsetzung der Normalisierung:Das Modell zwang das Team, Normalisierungsregeln anzuwenden, um Redundanz systematisch zu beseitigen.
- Zuordnungsleitfaden:Es bot einen klaren Weg, um die alten Spalten auf neue, normalisierte Tabellen abzubilden.
- Kommunikation mit Stakeholdern: Es ermöglichte den Business-Analysten, die Logik anhand der realen Geschäftsprozesse zu überprüfen.
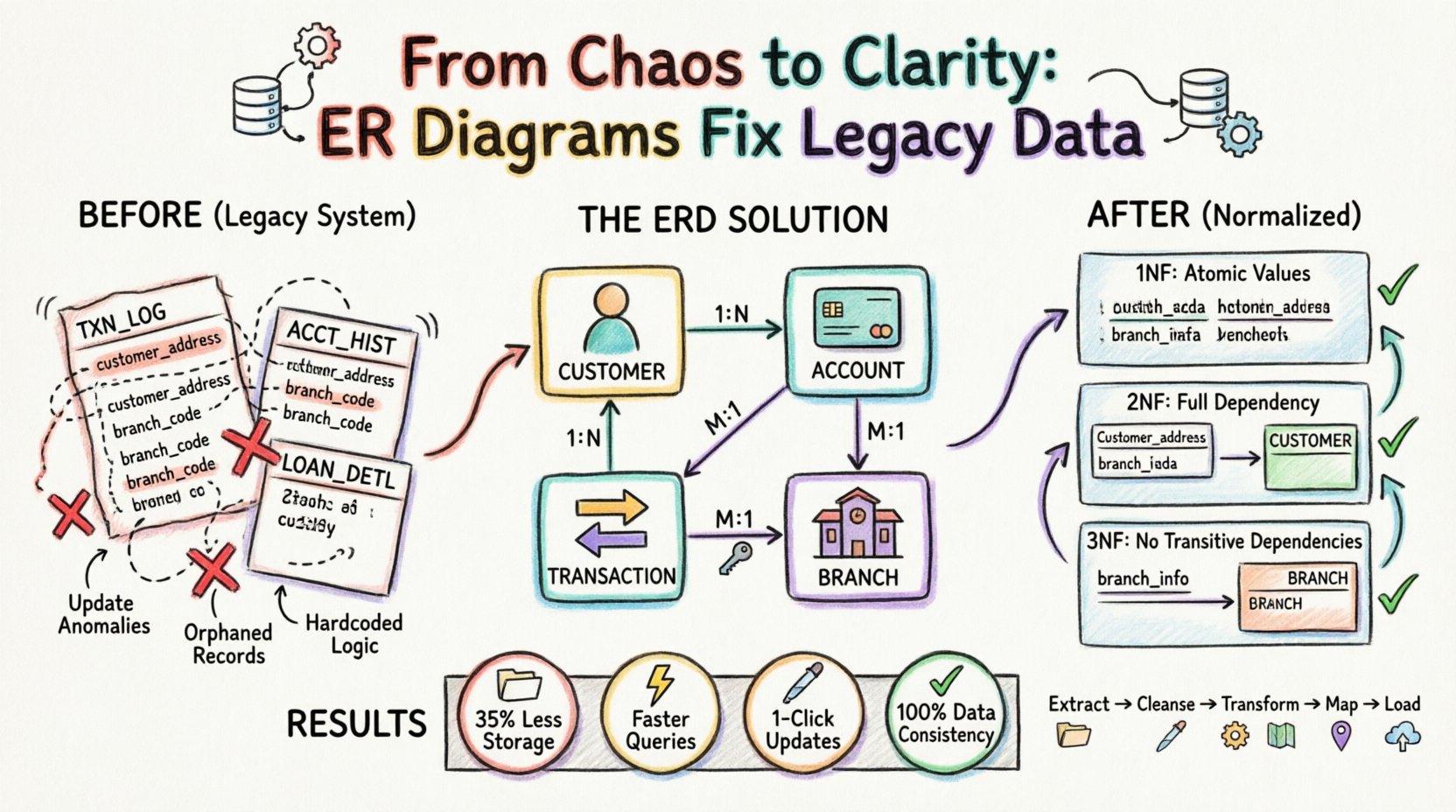
📂 Fallstudie: Konsolidierung der Einzelhandelsbank
Für diese Analyse betrachten wir eine Einzelhandelsbank, die von einem Mainframe-System in eine cloudbasierte relationale Datenbank wechselt. Das veraltete System verwaltete Kundenguthaben, Transaktionen und Kreditdaten. Aufgrund des Alters des Systems war Kundendaten jedoch redundant in den Transaktionsprotokollen gespeichert.
Vor der ERD-Analyse:
| Tabellenname | Primärschlüssel | Redundante Daten | Problem |
|---|---|---|---|
| TXN_LOG | TXN_ID | Kundenname, Adresse | Adressänderungen erfordern die Aktualisierung von Tausenden von Zeilen. |
| ACCT_HIST | HIST_ID | Filialcode, Filialstandort | Filialschließungen führen zu Datenkonflikten. |
| LOAN_DETL | LOAN_ID | Kunden-ID, Kontonummer | Verknüpfungen fehlen häufig oder sind doppelt vorhanden. |
Diese Struktur verletzte die grundlegenden Prinzipien der Datenbankgestaltung. Der ERD-Prozess erforderte die Aufteilung dieser Tabellen in atomare, unabhängige Entitäten.
🧩 Schritt 1: Identifizierung von Entitäten und Beziehungen
Die erste Phase der Migration umfasste die Extraktion jeder Tabelle und jedes Feldes aus dem veralteten System. Das Team ordnete diese anschließend logischen Entitäten zu. Ziel war es, eindeutige Objekte im Geschäftsbereich zu identifizieren.
- Kunde: Eine eindeutige Person oder Einheit, die ein Konto besitzt.
- Konto: Ein bestimmtes Finanzprodukt, das ein Kunde besitzt.
- Transaktion: Eine Geldbewegung, die mit einem Konto verbunden ist.
- Filiale: Ein physischer Ort, an dem Bankgeschäfte stattfinden.
Sobald Entitäten definiert waren, wurden Beziehungen hergestellt. Das ERD zeigte, dass ein einzelner Kunde mehrere Konten führen konnte. Ein Konto konnte mehrere Transaktionen haben. Eine Transaktion war einer bestimmten Filiale zugeordnet. Diese Beziehungen werden typischerweise wie folgt dargestellt:
- Ein-zu-Viele (1:N): Ein Kunde zu vielen Konten.
- Ein-zu-Viele (1:N): Ein Konto zu vielen Transaktionen.
- Viele-zu-Eins (M:1): Viele Transaktionen zu einer Filiale.
Durch die visuelle Abbildung dieser Verbindungen identifizierte das Team, wo Daten dupliziert wurden. Zum Beispiel erschien der Kundename in derTXN_LOGTabelle. In einem normalisierten Modell sollte die Transaktionstabelle nur einen Verweis (Fremdschlüssel) auf die Kundentabelle enthalten, nicht die Daten selbst.
📐 Schritt 2: Anwendung der Normalisierungsregeln
Normalisierung ist der Prozess der Datenorganisation, um Redundanz zu reduzieren und die Integrität zu verbessern. Das ERD-Modell führte das Team durch die Standardnormalformen.
Erste Normalform (1NF)
Das Legacy-System enthielt wiederholte Gruppen. Zum Beispiel könnte eine einzelne Zeile in der alten Kundentabelle mehrere Telefonnummern in einer einzigen Spalte enthalten (z. B. „555-0199, 555-0200“).
- Problem: Dies macht die Abfrage einer bestimmten Telefonnummer schwierig und verstößt gegen die Atomarität.
- ERD-Lösung: Erstellen Sie eine separateKontaktinformationEntität, die mit der Kundentität verknüpft ist. Jede Zeile in dieser neuen Tabelle enthält genau eine Telefonnummer.
Zweite Normalform (2NF)
2NF erfordert, dass die Tabelle in 1NF ist und dass alle nichtschlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Die alteTXN_LOGTabelle hatte einen zusammengesetzten Schlüssel ausTXN_ID undDATUM. Allerdings waren Kundendaten nur abhängig vomKunden_ID, nicht das Transaktionsdatum.
- Problem:Kundendaten wurden für jede Transaktion wiederholt, was Aktualisierungsanomalien verursachte.
- ERD-Lösung:Entfernen Sie Kundendetails aus der Transaktionstabelle. Speichern Sie sie in einer dediziertenKundeTabelle und verknüpfen Sie sie über einen Fremdschlüssel.
Dritte Normalform (3NF)
3NF erfordert, dass alle Attribute nur vom Primärschlüssel abhängen, ohne transitive Abhängigkeiten. In dem veralteten System wurden derFilialeName und die Adresse in derKontoTabelle gespeichert, aber sie hingen vomFilial_ID, nicht vomKonto_ID.
- Problem:Wenn eine Filiale ihren Standort wechselte, musste jedes Kontorecord, das mit dieser Filiale verbunden war, aktualisiert werden.
- ERD-Lösung:Erstellen Sie eine eigenständigeFilialeTabelle. Die
KontoTabelle enthält nun nur noch dieFilial_ID.
🔄 Schritt 3: Die Ausführungsstrategie für die Migration
Mit dem neuen ERD definiert wurde der Migrationsplan um das neue Schema herum aufgebaut. Der Prozess war kein einfaches Kopieren und Einfügen; es war eine Transformation.
- Datenextraktion:Rohdaten wurden aus den veralteten Quellsystemen in einen Stagingbereich übertragen.
- Bereinigung:Doppelte Datensätze wurden identifiziert und basierend auf den im ERD definierten Geschäftsschlüsseln zusammengeführt.
- Transformation:Skripte wurden geschrieben, um die de-normalisierten Spalten gemäß den Regeln der 1NF, 2NF und 3NF in neue Tabellen aufzuteilen.
- Zuordnung:Fremdschlüssel wurden generiert, um die neuen Tabellen zu verknüpfen. Ersatzschlüssel (systemgenerierte IDs) wurden verwendet, um Stabilität unabhängig von den veralteten Geschäftsschlüsseln zu gewährleisten.
- Laden:Die Daten wurden in einer bestimmten Reihenfolge in die Ziel-Datenbank eingefügt, um die Referenzintegrität zu wahren (Eltern vor Kindern).
Das ERD war hier entscheidend. Es bestimmte die Lade-Reihenfolge. Zum Beispiel musste die Tabelle Kunde zuerst mit Daten gefüllt werden, bevor die Tabelle Konto gefüllt wurde, die wiederum vor der Tabelle Transaktiongefüllt wurde. Versuche, in einer anderen Reihenfolge zu laden, würden zu Einschränkungsverletzungen führen.
✅ Schritt 4: Validierung und Testen
Die Validierung nach der Migration war umfangreich. Ziel war es sicherzustellen, dass die Summe der Daten konstant blieb, auch wenn die Struktur sich geändert hatte. Das Team nutzte das ERD, um den erwarteten Zustand der Daten zu definieren.
Integritätsprüfungen
- Referenzielle Integrität: Stellen Sie sicher, dass jeder
Kunden_IDin der Tabelle Konto in der Tabelle Kunde vorhanden ist. - Vollständigkeit:Stellen Sie sicher, dass während des Transformationsprozesses keine Datensätze verloren gingen.
- Einzigartigkeit:Bestätigen Sie, dass Primärschlüssel eindeutig sind und in den neuen Tabellen keine Duplikate existieren.
Vergleichs-Metriken
Die folgenden Metriken wurden verwendet, um die Quell- und Zielsysteme zu vergleichen:
| Validierungsmaßstab | Zielstandard | Methode |
|---|---|---|
| Datensatzanzahl | Quellanzahl = Zielanzahl | Zeilenanzahl pro normalisierte Entität |
| Summe der Werte | Gesamtbetrag Quelle = Gesamtbetrag Ziel | Aggregation numerischer Felder |
| Null-Prüfungen | Keine unerwarteten NULL-Werte in NOT NULL-Spalten | Abfragebeschränkungen |
| Doppelte Prüfungen | Keine Duplikate in Primärschlüsseln | GROUP BY-Analyse |
📉 Auswirkungen der Redundanzreduzierung
Der Wechsel von der veralteten Struktur zum normalisierten ERD-Modell brachte messbare Verbesserungen in Leistung und Wartung.
- Speichereffizienz: Durch die Beseitigung doppelter Kundendaten und Filialinformationen verringerten sich die Speicheranforderungen um etwa 35%.
- Abfrageleistung: Abfragen, die zuvor das Scannen großer, nicht normalisierter Tabellen erforderten, wurden schneller, indem kleinere, indizierte Tabellen verbunden wurden.
- Aktualisierungsgeschwindigkeit: Die Aktualisierung einer Kundenadresse erfordert nun einen einzelnen Zeilenupdate in der Kunde Tabelle, anstatt Tausende von Aktualisierungen über Transaktionsprotokolle hinweg.
- Datenkonsistenz: Das Risiko widersprüchlicher Daten (z. B. zwei verschiedene Adressen für denselben Kunden) wurde durch die Durchsetzung einer einzigen Quelle der Wahrheit beseitigt.
🛡️ Umgang mit Randfällen und historischen Daten
Einer der schwierigsten Aspekte der Migration von veralteten Systemen ist der Umgang mit historischen Daten, die nicht in das neue Modell passen. Das ERD half dabei, festzulegen, wie diese Ausnahmen geschmeidig behandelt werden können.
- Verwaiste Datensätze: Transaktionen, die Kunden zugeordnet waren, die im Quellsystem nicht mehr existierten, wurden markiert. Das Team entschied sich, diese in einer Historical_Legacy Tabelle zu archivieren, um Audit-Verläufe aufrechtzuerhalten, ohne die neuen Beziehungen zu stören.
- Fehlende Schlüssel: In Fällen, in denen eine Kunden-ID im alten System fehlte, generierte das Migrations-Skript eine temporäre Platzhalter-ID und markierte den Datensatz zur manuellen Überprüfung.
- Weiche Löschungen: Anstatt Datensätze physisch zu löschen, enthielt das neue Schema eine
is_activeKennzeichnung. Dadurch wurde die Historie erhalten, während sichergestellt wurde, dass aktive Berichte nur aktuelle Daten abfragten.
🚀 Zukunftssicherung des Schemas
Der ERD wurde nicht allein für die aktuelle Migration entworfen; er wurde so gestaltet, dass er zukünftiges Wachstum berücksichtigen kann. Durch die Einhaltung der Normalisierungsprinzipien wurde das Schema flexibel genug, um neue Funktionen zu unterstützen, ohne eine strukturelle Umgestaltung vornehmen zu müssen.
- Skalierbarkeit: Die Trennung der Entitäten ermöglicht eine horizontale Skalierung. Beispielsweise kann die Transaction Tabelle nach Datum partitioniert werden, ohne die Customer Tabelle zu beeinträchtigen.
- Erweiterbarkeit: Wenn ein neuer Produkttyp (z. B. eine Hypothek) hinzugefügt wird, kann er an die bestehenden Customer und Account Entitäten angekoppelt werden, ohne das Kernschema zu verändern.
- Dokumentation: Der ERD dient als lebendige Dokumentation. Neue Entwickler können das Datenmodell sofort verstehen, indem sie die Darstellung überprüfen, wodurch die Einarbeitungszeit verkürzt wird.
💡 Wichtige Erkenntnisse für Datenarchitekten
Diese Fallstudie hebt mehrere entscheidende Lektionen für Teams hervor, die ähnliche Migrationen durchführen.
- Modellieren Sie vor der Migration: Versuchen Sie niemals, Daten in ein neues System zu übertragen, ohne ein validiertes Schema-Design vorliegen zu haben. Der ERD ist der Bauplan.
- Normalisieren, um Redundanz zu lösen: Fürchten Sie die Normalisierung nicht. Sie ist der wichtigste Schutz gegen Dateninkonsistenzen.
- Ständig validieren: Der Test sollte bei jedem Schritt der Migration stattfinden, nicht nur am Ende.
- Beziehungen dokumentieren: Verstehen Sie die Kardinalität. Wenn Sie wissen, ob eine Beziehung 1:1 oder 1:N ist, vermeiden Sie logische Fehler im Datenmodell.
- Die Vergangenheit bewahren:Die Migration geht nicht nur um aktuelle Daten; es geht darum, die Integrität der Vergangenheit zu bewahren.
🔗 Schlussfolgerung zur Datenintegrität
Der Übergang von einem veralteten System zu einer modernen Datenbank ist selten ein einfaches Hochheben und Verschieben. Es erfordert eine grundlegende Neubewertung der Datenaufbereitung. Das Entity-Relationship-Diagramm erwies sich als wertvollster Bestandteil dieses Prozesses. Es bot die notwendige Klarheit, um redundante Strukturen aufzulösen und sie mit Integrität neu aufzubauen.
Durch die Priorisierung logischer Gestaltung gegenüber sofortiger Umsetzung erreichte die Organisation eine stabile, skalierbare und konsistente Datenumgebung. Die Reduzierung von Redundanz beseitigte eine erhebliche Quelle betrieblicher Risiken und legte eine solide Grundlage für zukünftige Analysen und Geschäftsintelligenzinitiativen.
Datenredundanz ist nicht nur ein Speicherproblem; es ist ein geschäftliches Risiko. Die Behandlung durch strenges Modellieren stellt sicher, dass die Daten als zuverlässiges Gut für die Entscheidungsfindung erhalten bleiben, anstatt eine Last zu sein, die den Fortschritt behindert.

