











В стремительном мире разработки программного обеспечения разрыв между большой идеей и реализуемой функцией часто охватывает сложную последовательность задач. Когда одна пользовательская история становится слишком большой, она превращается в узкое место. Это замедляет прогресс, маскирует риски и превращает тестирование в кошмар. Это явление часто называютспайкомилиэпикомприкрытым подобием истории. Проблема заключается в том, чтобы разбить их на управляемые части, не теряя первоначального намерения или повествовательного потока, который их соединяет.
Это руководство исследует искусство и науку эффективного разделения крупных пользовательских историй. Мы рассмотрим стратегии для сохранения контекста, обеспечения того, чтобы каждый фрагмент приносил ценность, и поддержания единства команды. Освоив механику декомпозиции, команды смогут повысить предсказуемость и качество, не жертвуя целостным видением продукта.
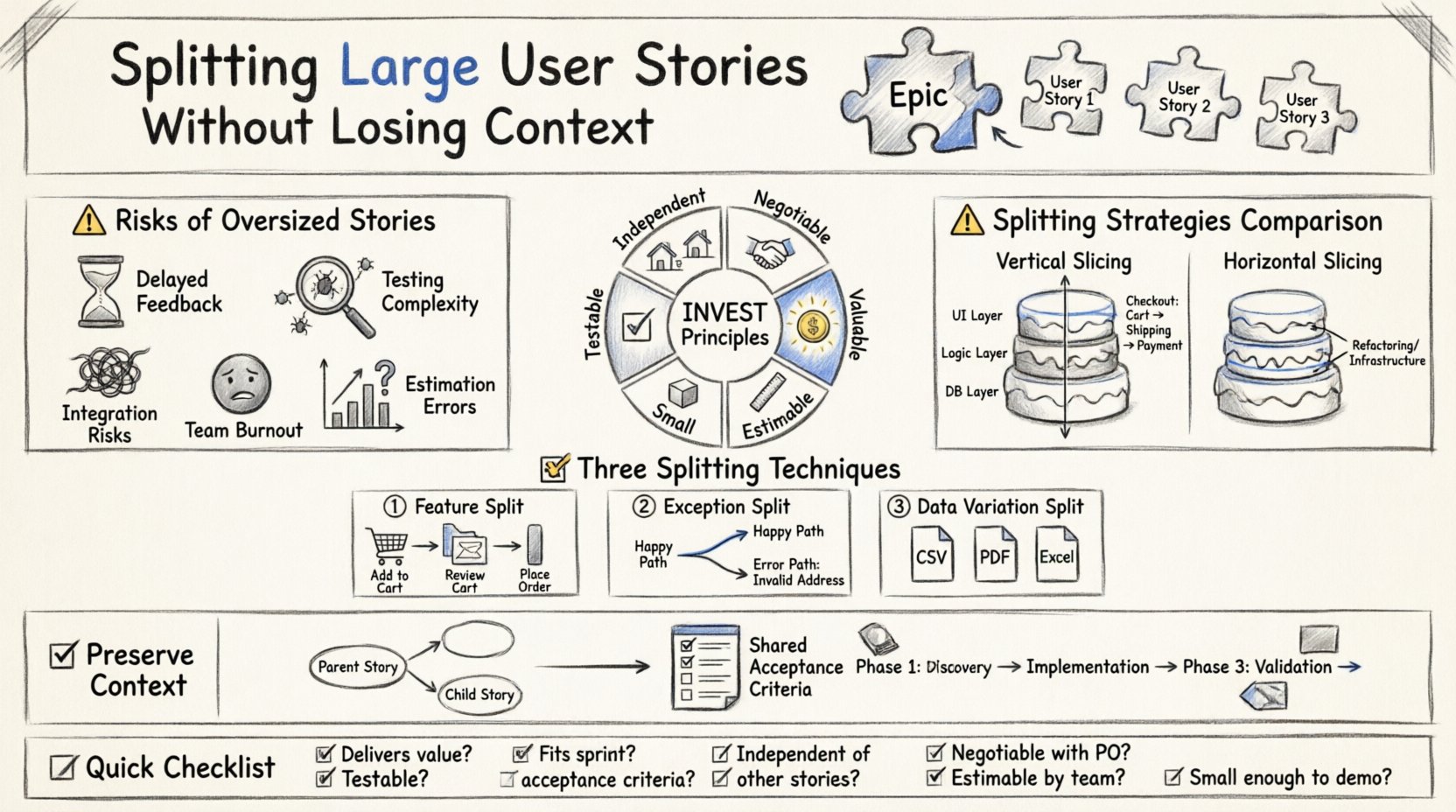
⚠️ Скрытая стоимость слишком крупных историй
Прежде чем приступать к решениям, крайне важно понять, почему крупные истории проблематичны. История, слишком большая, не выдерживает испытания временем. Она не может быть завершена за один спринт, что приводит к незавершённой работе, находящейся в состоянии неопределённости. Это создаёт технический долг и неопределённость.
Рассмотрим риски, связанные с сохранением крупных историй:
- Задержка обратной связи:Заинтересованные стороны не видят рабочего программного обеспечения до самого конца цикла. К тому времени направление может уже измениться.
- Сложность тестирования:Команды тестирования испытывают трудности при проверке огромного набора функций за один раз. Крайние случаи увеличиваются экспоненциально.
- Риски интеграции:Соединение нескольких непроверенных компонентов увеличивает вероятность конфликтов в кодовой базе.
- Выгорание команды:Работа над монолитной задачей в течение нескольких недель истощает мотивацию. Отсутствие небольших побед деморализует команду.
- Ошибки оценки:Крупные истории по своей природе трудно точно оценить. Это приводит к пропущенным дедлайнам и снижению скорости.
Чтобы смягчить эти проблемы, команды должны принять дисциплинированный подход к декомпозиции. Цель не просто уменьшить задачи, а сделать их ценными.
🧱 Основные принципы эффективного разделения
Разделение не является случайным. Оно требует соблюдения конкретных принципов, которые гарантируют, что полученные истории остаются полезными. Наиболее широко признанной моделью для этого являетсяINVESTмодель. При разделении каждая новая история должна, как правило, соответствовать этим критериям:
- IНезависимость: история не должна зависеть от других историй для своей функциональности.
- N
- VЦенность: каждый фрагмент должен приносить ценность пользователю или заинтересованной стороне.
- Е
- SМаленький: он должен умещаться в спринт.
- TОпределенный: должны существовать четкие критерии приемки.
Когда история разбивается, тоЦенностькритерий является наиболее важным. История, разбитая на части, которая не может существовать самостоятельно, не имеет ценности. Если пользователь не может использовать функцию, значит, разбиение было ошибочным.
📊 Сравнение критериев разбиения
| Критерий | Фокус | Пример применения |
|---|---|---|
| Вертикальная нарезка | Функциональность от начала до конца | Добавление одного нового поля в форму и его отображение. |
| Горизонтальная нарезка | Реализация по уровням | Рефакторинг схемы базы данных для всей системы. |
| Обработка исключений | Крайние случаи и ошибки | Обработка таймаутов сети или некорректного ввода данных. |
| Вариации данных | Различия в содержании | Поддержка различных валют или языков. |
🔪 Стратегии вертикальной нарезки
Вертикальная нарезка — это золотой стандарт для разбиения пользовательских историй. Она предполагает разрезание всех уровней приложения (база данных, бизнес-логика, пользовательский интерфейс), чтобы доставить конкретный, рабочий фрагмент функциональности. Это гарантирует, что каждая история порождает развертываемый прирост.
1. Разделение функции
Если история описывает сложный рабочий процесс, разбейте ее на конкретные действия, которые может выполнять пользователь. Вместо того чтобы сразу строить весь процесс оформления заказа, выделите отдельные этапы.
- Оригинальная история: Как покупатель, я хочу завершить покупку, чтобы купить товары.
- Раздел 1: Как покупатель, я хочу добавить товары в корзину, чтобы просмотреть свой выбор.
- Раздел 2: Как покупатель, я хочу ввести данные доставки, чтобы перейти к оплате.
- Раздел 3: Как покупатель, я хочу выбрать способ оплаты, чтобы завершить заказ.
Каждый из этих элементов — самостоятельная ценность. Корзина работает без доставки. Доставка работает без оплаты (для предварительного просмотра). Это позволяет постепенно выпускать функции.
2. Разделение по исключениям
Часто основной путь прост, но крайние случаи делают историю большой. Разделение основного пути и пути исключений может прояснить требования и снизить риски.
- Исходная история: Как пользователь, я хочу сбросить пароль, чтобы восстановить доступ.
- Раздел 1 (основной путь): Как пользователь, я хочу получить ссылку для сброса пароля по электронной почте, чтобы изменить пароль.
- Раздел 2 (исключение): Как пользователь, я хочу получать уведомление, если мой email не найден, чтобы исправить ввод.
- Раздел 3 (исключение): Как пользователь, я хочу заблокировать свой аккаунт после нескольких неудачных попыток, чтобы он оставался защищённым.
3. Разделение по вариациям данных
Поддержка различных типов данных часто увеличивает объём истории. Изолируя типы данных, команды могут упростить проверку и логику.
- Исходная история: Как администратор, я хочу загружать отчёты в форматах CSV, PDF и Excel.
- Раздел 1: Как администратор, я хочу загружать отчёты в формате CSV.
- Раздел 2: Как администратор, я хочу загружать отчёты в формате PDF.
- Раздел 3: Как администратор, я хочу загружать отчёты в формате Excel.
🏗️ Когда использовать горизонтальное разделение
Вертикальное разделение не всегда является решением. Иногда необходимо горизонтальное разделение. Это предполагает построение функциональности слой за слоем на всём протяжении системы. Хотя это не даёт немедленной ценности для пользователя, оно полезно для технической основы.
Используйте горизонтальное разделение, когда:
- Рефакторинг: Вам нужно обновить библиотеку, используемую каждым функциональным элементом.
- Инфраструктура: Вы настраиваете новую схему базы данных или шлюз API.
- Безопасность: Вы реализуете аутентификацию на всей платформе приложения.
- Производительность: Вы оптимизируете слой кэширования для всех конечных точек.
Даже при использовании горизонтальных срезов, постарайтесь делать их достаточно малыми, чтобы их можно было тестировать независимо. Горизонтальный срез, затрагивающий каждый модуль, всё равно должен рассматриваться как одна история.
🧭 Сохранение контекста при декомпозиции
Наиболее значительный риск при разделении — потеря контекста. Если член команды берёт небольшую историю, не понимая, как она вписывается в общую картину, реализация может отклониться от первоначальной идеи. Это известно как смена контекста или фрагментация.
1. Связывание историй
Используйте родительско-дочерние отношения в системе управления бэклогом. Обозначьте исходную крупную историю как эпик или родитель. Каждая разбитая история должна ссылаться на идентификатор родителя. Это создаёт цепочку отслеживаемости.
- Эпик: Реализовать управление профилем пользователя.
- История A: Добавить загрузку фотографии профиля.
- История B: Обновить контактную информацию.
- История C: Изменить параметры пароля.
Эта структура обеспечивает, что при рассмотрении истории A разработчик видит, что следует история B и история C. Это дает карту всего функционала.
2. Общие критерии приемки
Некоторые правила применяются ко всему функционалу, а не только к отдельному фрагменту. Определите их в общем документе или в общей части шаблона истории. Это обеспечивает согласованность.
- Безопасность: Все обновления профиля должны требовать повторной аутентификации.
- Производительность: Время загрузки страницы должно оставаться менее 2 секунд.
- Доступность: Все поля формы должны иметь правильные метки для экранного доступа.
Перечисляя эти требования глобально, каждая разбитая история наследует ограничения. Это предотвращает появление уязвимости в одной части, которая повлияет на весь функционал.
3. Визуальное картирование
Картирование пользовательских историй — это мощный способ визуализации потока. Создайте список пользовательских действий по горизонтальной оси и истории, которые их поддерживают, по вертикальной оси. Это создает скелет функционала.
Эта карта служит визуальным договором. При разбиении истории команда может посмотреть на карту, чтобы понять, что идет до и после. Это предотвращает создание истории в изоляции, которая нарушит поток пользовательского пути.
🚫 Распространенные ошибки, которых следует избегать
Даже с хорошими намерениями разбиение может пойти не так. Вот распространенные ошибки, которые команды допускают, пытаясь уменьшить размер истории.
- Чрезмерное разбиение: Делать истории настолько маленькими, что они занимают всего 2 часа. Это увеличивает накладные расходы на встречи и обновления. Стремитесь к историям, которые занимают от 1 до 3 дней.
- Разбиение по технологии: Не разбивайте историю только потому, что она включает задачу на бэкенде и задачу на фронтенде. Если задача на фронтенде требует выполнения бэкенда в первую очередь, это зависимость, а не разбиение по ценности. Это создает водопад внутри спринта.
- Потеря пользователя: Разбиение историй на технические задачи (например, «Создать таблицу базы данных») без заявления о ценности для пользователя (например, «Как пользователь, я хочу сохранить свой прогресс»).
- Пренебрежение зависимостями: Не проверять, не блокирует ли одна разбитая история другую. Это приводит к простаиванию членов команды.
- Дублирование критериев приемки: Копирование и вставка критериев приемки без их обновления для конкретного фрагмента. Это приводит к путанице при тестировании.
📋 Чек-лист для разбиения историй
Перед окончательным завершением разбиения пройдитесь по этому чек-листу, чтобы обеспечить качество и ясность.
- ☐ Дает ли эта разбитая история независимую ценность?
- ☐ Можно ли её протестировать изолированно?
- ☐ Оценка усилий реалистична для спринта?
- ☐ Зависимости четко определены?
- ☐ История связана с родительским эпиком?
- ☐ Критерии приемки конкретны для этой части?
- ☐ Сохраняется ли контекст пользовательского потока?
- ☐ Учтены ли исключительные пути?
🔄 Техники уточнения
Разбиение — это не одноразовое событие. Это постоянный диалог во время уточнения бэклога. По мере того как команда узнает больше о проблеме, истории могут потребовать дальнейшего разделения или объединения.
1. Дебаты «Как» против «Что»
Убедитесь, что история фокусируется на что (ценность для пользователя), а не на как (технической реализации). Если история большая, потому что команда не знает, как её реализовать, это спайк, а не история. Выделите спайк как исследовательскую задачу.
- Плохо: Как пользователь, я хочу, чтобы система использовала кэширование Redis для более быстрого чтения.
- Хорошо: Как пользователь, я хочу, чтобы панель управления загружалась за менее чем 1 секунду.
- Исследовательский спайк: Оцените варианты реализации Redis и оцените усилия.
2. Итеративное уточнение
Начните с грубого разделения. По мере начала спринта команда может понять, что часть всё ещё слишком большая. Допустимо разбивать историю во время спринта, если риск слишком высок. Однако это должно быть редким случаем. Регулярные сессии уточнения до планирования спринта помогают избежать этого.
🤔 Часто задаваемые вопросы
Вот распространённые вопросы, которые команды задают при работе с большими историями.
В: Как я узнаю, когда история слишком большая?
О: Если команда не может прийти к согласию по оценке, или если история требует более одного спринта для завершения, она слишком большая. Также, если тестирование кажется непосильным, вероятно, она слишком большая.
В: Следует ли разбивать истории в зависимости от того, кто выполняет работу?
О: Нет. Разбиение по роли (например, «Задача для фронтенда», «Задача для бэкенда») создаёт зависимости. Разбивайте по ценности или функциональности, чтобы любой член команды мог взять на себя работу и продвинуть её вперёд.
В: Что делать, если клиент хочет всю функцию сразу?
О: Объясните риски. Поясните, что поставка по частям позволяет получать обратную связь раньше и снижает вероятность создания неправильного продукта. Предложите сначала самую маленькую часть, которая предоставляет основную пользу.
В: Все истории должны быть вертикальными?
О: Большинство должны быть такими. Вертикальные фрагменты приносят ценность. Горизонтальные фрагменты — это технический долг или инфраструктура. Если горизонтальный фрагмент слишком большой, разбейте его по компонентам или модулям, но убедитесь, что он остается технической историей.
🏁 Заключительные мысли
Разделение крупных пользовательских историй — это баланс. Требуется опыт, здравый смысл и четкая коммуникация. Цель — не просто уменьшить объем работы, а сделать ее более ценной. При правильном выполнении разделение снижает риски, улучшает качество и помогает команде сосредоточиться на том, что важно для пользователя.
Соблюдая принципы вертикального разделения, сохраняя контекст с помощью связывания и сопоставления, и избегая распространенных ошибок, команды могут уверенно работать с сложными функциями. Результат — постоянный поток рабочего программного обеспечения и удовлетворенный заинтересованный стороной. Продолжайте совершенствовать свой подход, и позволяйте данные из ваших спринтов направлять ваши будущие решения по разделению.

