











A transição da infraestrutura tradicional em local para ambientes nativos na nuvem representa uma mudança fundamental na forma como os dados são armazenados, acessados e gerenciados. Para Administradores de Banco de Dados (DBAs), essa transição exige mais do que apenas migrar esquemas existentes. Exige uma reavaliação dos Diagramas Entidade-Relacionamento (ERDs) para alinhar-se com as restrições e capacidades únicas de sistemas distribuídos. Este guia oferece uma visão abrangente sobre como projetar diagramas ER que suportem escalabilidade, resiliência e desempenho em arquiteturas de nuvem modernas. 📊
Compreendendo a Mudança na Arquitetura de Dados 🔄
O design tradicional de banco de dados frequentemente prioriza a normalização rigorosa e o controle centralizado. Em contraste, as arquiteturas nativas na nuvem enfatizam disponibilidade, tolerância a partições e escalabilidade horizontal. A diferença fundamental reside na suposição de falhas. Em uma arquitetura monolítica, o banco de dados é um único ponto de falha. Em um ambiente nativo na nuvem, os nós falham com frequência, e o sistema deve se adaptar instantaneamente.
Ao projetar diagramas ER para esse ambiente, os DBAs devem considerar:
- Consistência Distribuída: Como as relações se mantêm quando os dados são divididos entre regiões?
- Latência: Como a distância física entre os nós de dados afeta o desempenho das consultas?
- Custo: Qual é o trade-off entre redundância de armazenamento e custos de transações?
- Complexidade Operacional: O esquema pode ser gerenciado sem intervenção manual constante?
Ignorar esses fatores pode levar a sistemas difíceis de escalar ou manter. Um diagrama ER bem projetado atua como o plano de construção do fluxo de dados, garantindo que a infraestrutura subjacente possa suportar a lógica de negócios sem gargalos. 🚀
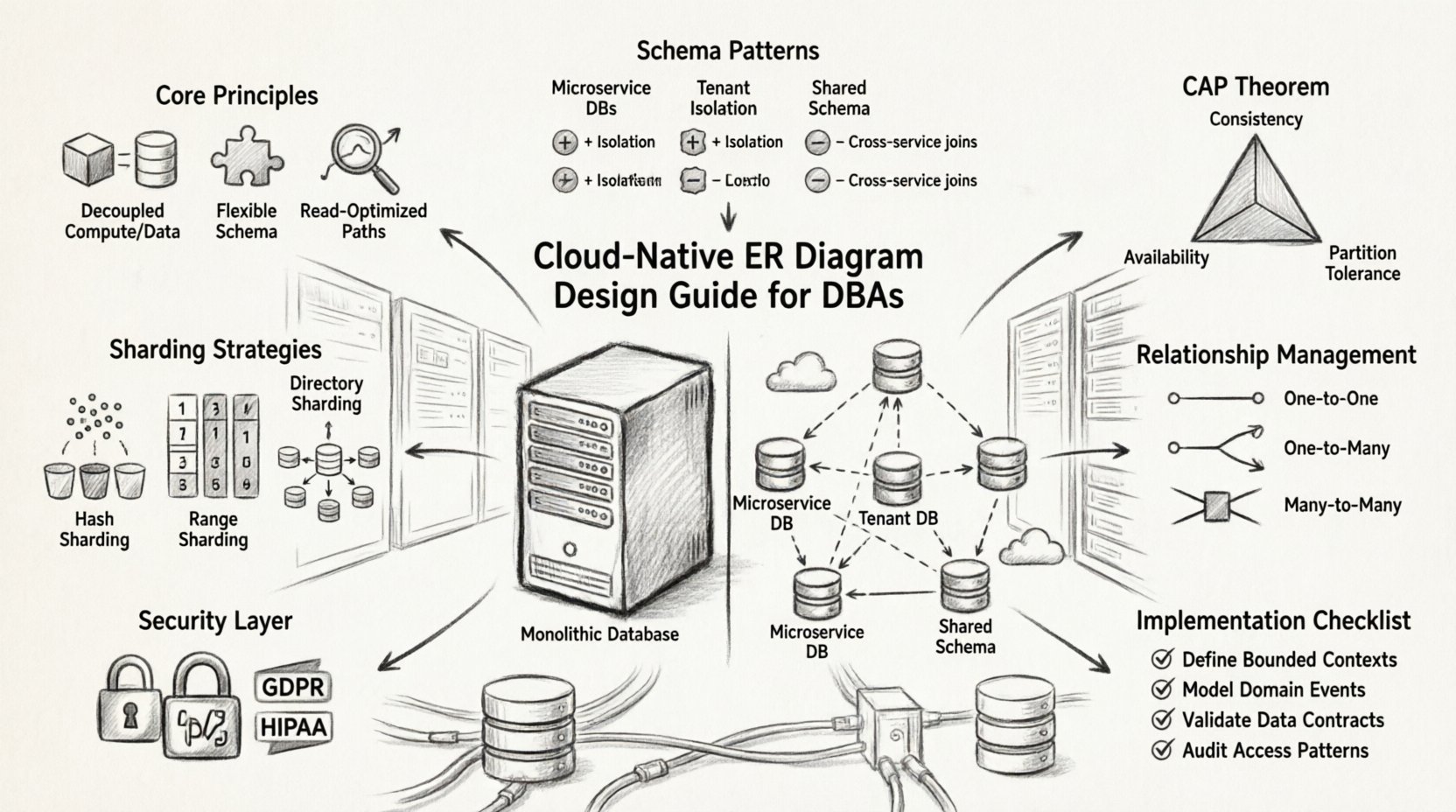
Princípios Fundamentais dos ERDs Nativos na Nuvem ⚙️
Antes de mergulhar em padrões específicos, é essencial compreender os princípios orientadores que diferenciam o modelagem de dados nativa na nuvem das abordagens tradicionais.
1. Desacoplamento de Dados do Computação
Em muitos sistemas legados, o servidor de banco de dados e o servidor de aplicação estão fortemente acoplados. O design nativo na nuvem separa essas preocupações. O ERD deve refletir isso ao minimizar dependências que exigem comunicação síncrona entre serviços distintos.
2. Acolhendo a Flexibilidade do Esquema
Embora bancos de dados SQL sejam rígidos, os ambientes nativos na nuvem frequentemente utilizam persistência poliglota. Isso significa que tipos de dados diferentes podem exigir modelos de armazenamento diferentes. O diagrama ER deve visualizar relações lógicas mesmo que as implementações físicas variem (por exemplo, armazenamento JSON ao lado de tabelas relacionais).
3. Otimização para Cargas de Trabalho com Leituras Intensivas
Aplicações em nuvem frequentemente atendem milhões de usuários simultaneamente. O design ER deve suportar caminhos de leitura eficientes, mesmo que isso signifique introduzir alguma redundância. A desnormalização torna-se uma ferramenta estratégica, e não um pecado.
Padrões de Design de Esquema para Escalabilidade 📈
Selecionar o padrão de esquema adequado é crítico para o desempenho. Abaixo estão abordagens comuns utilizadas em sistemas distribuídos.
Banco de Dados Único por Serviço
Cada microsserviço gerencia seu próprio esquema de banco de dados. Essa isolamento evita que falhas de serviço se propaguem. O diagrama ER para o sistema geral torna-se uma coleção de diagramas menores e independentes conectados por referências lógicas.
Banco de Dados Compartilhado com Separação de Esquema
Vários serviços compartilham uma única instância de banco de dados, mas mantêm namespaces de esquema separados. Isso reduz os custos de infraestrutura, mas introduz riscos de acoplamento rígido. Geralmente é desencorajado para implantações em grande escala na nuvem.
Banco de Dados por Cliente
Em aplicações SaaS multi-inquilinos, cada cliente recebe uma instância de banco de dados dedicada. O design do ERD deve permanecer consistente em todas as instâncias, garantindo que migrações e atualizações sejam aplicadas de forma uniforme.
Comparação de Padrões de Esquema
| Padrão | Vantagens | Desvantagens | Melhor Caso de Uso |
|---|---|---|---|
| Banco de Dados Único | Junções simples, conformidade ACID | Ponto único de falha, limitações de escalabilidade | Aplicações monolíticas, baixo tráfego |
| Banco de Dados por Serviço | Escalabilidade independente, isolamento de falhas | Transações complexas, junções distribuídas | Microserviços, alto crescimento |
| Banco de Dados por Inquilino | Isolamento de dados, facilitação de conformidade | Alto custo de infraestrutura, sobrecarga de gestão | Plataformas SaaS, indústrias regulamentadas |
| Esquema Compartilhado | Baixo custo, consultas compartilhadas | Vínculo com fornecedor, gargalos de escalabilidade | Ferramentas internas, MVPs |
Gerenciamento de Relacionamentos entre Serviços 🔗
Em uma arquitetura distribuída, chaves estrangeiras nem sempre são viáveis. A integridade referencial deve ser gerenciada de forma diferente. O diagrama ER deve representar essas relações lógicas de forma clara, mesmo que a aplicação física do controle ocorra na camada de aplicação ou por meio de processos assíncronos.
Tipos de Relacionamentos
- Um para Um:Geralmente tratado pela incorporação direta de dados para reduzir a latência de junção.
- Um para Muitos: Exige consideração cuidadosa sobre como os registros filhos são armazenados. Se o pai se mover, os filhos também se moverão?
- Muitos para Muitos: Geralmente implementado por meio de uma tabela de associação. Em ambientes em nuvem, essa tabela pode precisar ser particionada de forma independente.
Tratamento da Integridade Referencial
Sem restrições estritas de chave estrangeira, a consistência dos dados depende da lógica da aplicação. Estratégias incluem:
- Exclusão Suave:Marcando registros como inativos em vez de removê-los para preservar o histórico.
- Consistência Eventual:Usando fluxos de eventos para propagar mudanças entre serviços.
- Transações Compensatórias:Lógica de rollback que trata falhas em fluxos de trabalho distribuídos.
Estratégias de Particionamento e Sharding 🗂️
À medida que o volume de dados cresce, um único nó de banco de dados não consegue lidar com a carga. O particionamento (sharding) divide os dados entre múltiplos nós. O diagrama ER deve indicar como os dados são distribuídos para evitar pontos quentes.
Chaves de Sharding
A escolha da chave de sharding determina como as consultas são roteadas. Uma boa chave distribui os dados de forma uniforme e alinha-se aos padrões de acesso.
- Baseado em Hash:Distribui os dados aleatoriamente. Bom para acesso uniforme, ruim para consultas em faixa.
- Baseado em Faixa:Divide os dados por valor (por exemplo, datas ou IDs). Bom para consultas em faixa, mas corre o risco de distribuição desigual.
- Baseado em Diretório:Mantém um serviço de mapeamento para localizar os dados. Adiciona latência, mas permite posicionamento flexível.
Impacto nos Diagramas ER
Ao projetar o ERD, observe que:
- Tabelas que são frequentemente unidas devem, idealmente, ser localizadas juntas para minimizar o tráfego de rede.
- Tabelas globais (como dados de configuração) devem permanecer não particionadas.
- Os índices devem ser projetados para funcionar dentro dos limites dos shards.
Modelos de Consistência e Teorema CAP ⚖️
O teorema CAP afirma que um sistema distribuído só pode garantir duas das três propriedades: Consistência, Disponibilidade e Tolerância a Partições. Sistemas nativos da nuvem priorizam a Tolerância a Partições, forçando uma escolha entre Consistência e Disponibilidade.
Escolha do Modelo Correto
| Modelo | Descrição | Implicação no ERD |
|---|---|---|
| Consistência Forte | Todos os nós veem os mesmos dados ao mesmo tempo | Requer gravações síncronas; limita a taxa de gravação |
| Consistência eventual | Os dados tornam-se consistentes após um atraso | Permite gravações assíncronas; exige tratamento de leituras obsoletas |
| Consistência causal | Preserva a ordem de operações causalmente relacionadas | Rastreamento complexo de dependências no diagrama ER |
Para aplicações financeiras, a consistência forte é frequentemente necessária. Para feeds sociais, a consistência eventual é aceitável. O diagrama ER deve indicar quais tabelas exigem ordenação rigorosa e quais podem tolerar atrasos.
Indexação para ambientes de alta taxa de transferência 🏷️
Estratégias de indexação na nuvem diferem das locais devido aos custos de armazenamento e largura de banda de rede. Cada índice consome recursos de gravação e espaço de armazenamento.
Melhores práticas de indexação
- Minimize os índices secundários: Indexe apenas colunas usadas em predicados de consulta frequentes.
- Considere índices cobrindo: Inclua todas as colunas necessárias no índice para evitar pesquisas na tabela.
- Monitore o uso de índices: Audite regularmente o desempenho dos índices para remover estruturas não utilizadas.
- Índices particionados: Alinhe as estruturas de índice com a estratégia de particionamento de dados.
Índices globais versus locais
Índices globais abrangem todas as partições e podem ser caros para manter. Índices locais residem dentro de uma partição e são mais baratos. Ao projetar o diagrama ER, especifique quais índices são globais e quais são locais para orientar a equipe de infraestrutura.
Considerações de segurança e conformidade 🛡️
A segurança de dados na nuvem envolve criptografia, controle de acesso e conformidade com regulamentações como GDPR ou HIPAA. O diagrama ER deve refletir os níveis de sensibilidade dos dados.
Classificação de dados
Marque entidades de dados com base na sensibilidade:
- Público: Nenhuma proteção especial necessária.
- Interno: Acessível apenas por funcionários.
- Restrito: Exige criptografia e registro rigoroso de acesso.
Criptografia em Repouso e em Trânsito
Todos os campos sensíveis devem ser sinalizados para criptografia. O ERD não deve armazenar dados sensíveis em texto claro. Em vez disso, deve fazer referência a colunas criptografadas ou tokens.
Conformidade e Retenção
Algumas informações devem ser retidas por períodos específicos ou excluídas por completo. O design ER deve incluir campos de metadados para políticas de retenção e rastreamento de auditoria.
Versionamento e Evolução de Esquema 🔄
Em ambientes nativos em nuvem, o tempo de inatividade para alterações de esquema é raro. As migrações devem ser realizadas online. O ERD deve suportar estratégias de versionamento.
Compatibilidade com Versões Anteriores
Novas versões de esquema devem ser compatíveis com versões anteriores com a lógica do aplicativo. Isso permite a implantação gradual das alterações.
Padrões de Migração
- Adicionar Coluna: Adicionar novos campos sem alterar os dados existentes.
- Escrita Dupla: Escrever em ambas as estruturas antigas e novas durante a transição.
- Mudança: Alternar o tráfego de leitura e escrita assim que os dados forem migrados.
- Remover Coluna: Remover campos não utilizados apenas após confirmar que não há dependências.
Armadilhas Comuns para Evitar ⚠️
Mesmo DBAs experientes podem cometer erros ao se adaptar a designs nativos em nuvem. Aqui estão erros comuns.
- Sobrenormalização: Muitos joins aumentam a latência em sistemas distribuídos.
- Ignorar Dados Inativos: Falhar em arquivar dados históricos pode aumentar os custos e atrasar consultas ativas.
- Limites Codificados: Definir limites arbitrários de linhas no aplicativo que ignoram as restrições do banco de dados.
- Ignorar Latência: Projetar consultas que assumem acesso local aos dados quando os dados são, na verdade, remotos.
- Pontos Únicos de FalhaProjetando um nó principal de banco de dados que, se perdido, interrompe todo o sistema.
Lista de verificação de implementação ✅
Antes de implantar um esquema de banco de dados nativo em nuvem, revise a seguinte lista de verificação.
| Tarefa | Prioridade | Status |
|---|---|---|
| Definir a estratégia de particionamento | Alta | Não Iniciado |
| Identificar padrões de leitura/escrita | Alta | Não Iniciado |
| Planejar a consistência eventual | Média | Não Iniciado |
| Projetar backup e recuperação | Alta | Não Iniciado |
| Configurar alertas de monitoramento | Média | Não Iniciado |
| Revisar políticas de segurança | Alta | Não Iniciado |
Manutenção e Monitoramento 🔍
Um banco de dados nativo em nuvem exige monitoramento contínuo. O diagrama ER não é um documento estático; ele evolui com o aplicativo.
Métricas-Chave
- Latência de Consulta:Monitorar tempos médios e de resposta p99.
- Utilização do Pool de Conexões:Garanta que o aplicativo possa lidar com cargas máximas.
- Crescimento de Armazenamento:Prediga as necessidades futuras de capacidade.
- Taxas de Erro:Monitore falhas de transações e rollback.
Automação
Use ferramentas automatizadas para detectar desvios de esquema e garantir padrões. As alterações manuais em esquemas de produção devem ser minimizadas para reduzir erros humanos.
Conclusão 🏁
Projetar diagramas ER para arquiteturas nativas em nuvem é uma tarefa complexa que equilibra restrições técnicas com objetivos de negócios. Ao focar na escalabilidade, modelos de consistência e segurança, os DBAs podem construir sistemas que resistam ao crescimento e às mudanças. A chave é tratar o modelamento de dados como um processo contínuo, e não como uma configuração única. Revisões regulares e o cumprimento das melhores práticas garantem que o banco de dados permaneça uma base confiável para o aplicativo. 🌐

