











W nowoczesnej infrastrukturze dane nie są tylko przechowywane; przepływają. Architektura schematu bazy danych bezpośrednio wpływa na stabilność całego rozproszonego ekosystemu. Gdy diagram relacji encji (ERD) jest projektowany bez uwzględnienia subtelności obliczeń rozproszonych, wynikiem często jest niewytrzymałość. Awaria jednego węzła może się rozprzestrzenić, powodując szerokie zakłamanie lub uszkodzenie danych. Ten przewodnik omawia, jak projektować modele danych, które wytrzymują inherentną niestabilność środowisk rozproszonych.
🧩 Zrozumienie związku między schematem a stabilnością
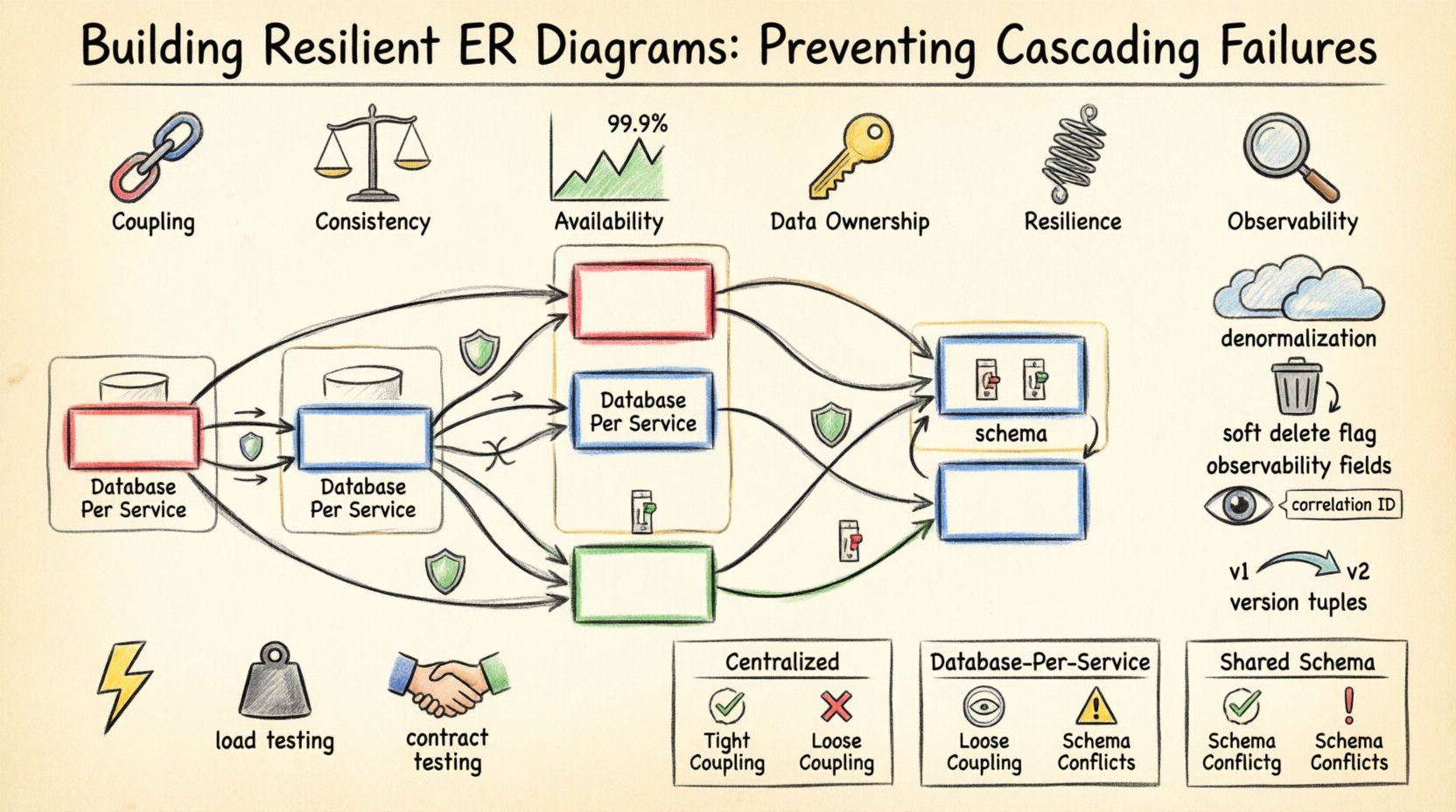
Diagram ER pełni rolę projektu, jak dane są ze sobą powiązane. W architekturze monolitycznej te relacje są ściśle zarządzane w ramach jednej granicy transakcyjnej. Jednak systemy rozproszone rozrywają te granice. Usługi działają niezależnie, często posiadając własne magazyny danych. Gdy połączysz te usługi za pomocą wspólnych modeli danych, wprowadzasz sprzężenie.
Odporność w tym kontekście oznacza projektowanie schematów, które pozwalają na awarię części systemu bez jego całkowitego zatrzymania. Wymaga to zmiany perspektywy: diagram ER nie jest już tylko wizualizacją struktury; jest kontraktem dotyczącym zachowania. Jeśli ograniczenie klucza obcego jest ściśle stosowane przez sieć, tymczasowy podział sieci może wywołać kaskadę błędów. Dlatego projekt musi uwzględniać spójność ostateczną, opóźnienia i częściowe awarie.
🔑 Kluczowe koncepcje do rozważenia
- Sprzężenie: Wysokie sprzężenie między encjami oznacza, że zmiany lub awarie w jednej mają istotny wpływ na drugą.
- Spójność: Silna spójność (ACID) zapewnia poprawność danych, ale może zmniejszać dostępność podczas problemów z siecią.
- Dostępność: Wysoka dostępność priorytetowo ustawia czas działania, często wymagając rozluźnienia reguł spójności.
- Właściciel danych: Jasne granice określające, która usługa posiada które dane, zapobiegają zależnościom cyklicznym.
🛡️ Strategie modelowania relacji
Sposób definiowania relacji między encjami jest głównym czynnikiem odporności. W środowisku rozproszonym każda relacja to potencjalne wywołanie sieciowe. Minimalizacja tych wywołań i obsługę ich trybów awarii jest kluczowa.
1. Unikanie głębokich łańcuchów połączeń
Głęboko znormalizowane schematy są doskonałe dla integralności danych, ale mogą być katastrofalne dla wydajności w systemach rozproszonych. Jedno zapytanie wymagające pięciu połączeń między różnymi usługami może prowadzić do przekroczenia limitu czasu i kaskadowych awarii. Zamiast tego rozważ denormalizację tam, gdzie zmniejsza to potrzebę synchronicznych wyszukiwań między usługami.
- Replikuj dane do odczytu: Przechowuj często dostępne dane redundantnie, aby uniknąć wywołań zdalnych.
- Denormalizuj dla ścieżek odczytu: Zaakceptuj złożoność zapisu w zamian za szybkość i niezawodność odczytu.
- Buforuj agregacje: Wstępnie obliczaj sumy lub podsumowania, aby zmniejszyć obciążenie przetwarzania w czasie rzeczywistym.
2. Klucze obce jako kontrakty, a nie jako mechanizmy wymuszania
W jednej bazie danych klucz obcy zapobiega istnieniu danych bez rodzica. W systemie rozproszonym wymuszanie tego za pomocą ograniczeń baz danych przez granice sieciowe jest ryzykowne. Jeśli usługa A jest niedostępna, usługa B nie może zweryfikować relacji, co może zablokować operacje.
Często bezpieczniejsze jest zapewnienie integralności referencyjnej na poziomie aplikacji za pomocą logiki weryfikacji lub sprawdzania spójności ostatecznej.
- Sprawdzanie na poziomie aplikacji: Weryfikuj istnienie identyfikatorów przed zapisem, ale zezwalaj na warunki wyścigu.
- Spójność ostateczna: Używaj zadań w tle do czyszczenia orzeczników zamiast blokowania głównej transakcji.
- Miękkie ograniczenia: Traktuj klucze obce jako logiczne linki, a nie jako twarde blokady bazy danych.
🗃️ Zarządzanie modelami spójności danych
Systemy rozproszone muszą radzić sobie z twierdzeniem CAP. Wybór odpowiedniego modelu spójności dla swoich encji jest kluczowy, aby zapobiegać uszkodzeniu danych podczas awarii.
| Model spójności | Przypadek użycia | Wpływ odporności |
|---|---|---|
| Silna spójność | Transakcje finansowe, liczba towarów na magazynie | Wysoka niezawodność, niższa dostępność podczas podziałów |
| Końcowa spójność | Profilu użytkowników, kanały społecznościowe, dzienniki | Wysoka dostępność, tymczasowa rozbieżność danych |
| Czytaj swoje zapisy | Dane sesji, koszyki zakupowe | Zrównoważony doświadczenie użytkownika przy umiarkowanej złożoności |
Podczas projektowania ERD oznacz, które encje wymagają silnej spójności, a które mogą tolerować późniejsze aktualizacje. Ta różnica kieruje sposobem implementacji blokad, transakcji i strategii replikacji.
🔄 Obsługa ewolucji schematu
Systemy się zmieniają. Dodawane są pola, zmieniane są typy, a relacje ulegają zmianie. W architekturze rozproszonej nie możesz po prostu zmienić schematu na wszystkich węzłach jednocześnie. Niespójność między usługą a jej wersją bazy danych może spowodować awarie.
Najlepsze praktyki wersjonowania
- Zgodność wsteczna:Nowe wersje schematu muszą być czytelne dla starych wersji usług.
- Okresy wygaszania: Przechowuj stare pola w bazie danych przez dłuższy czas, nawet jeśli nie są już używane.
- Flagi funkcji: Używaj flag do kontrolowania wdrażania nowych struktur danych.
- Rozszerz i skróć: Najpierw dodaj nowe pole (rozszerz), przeprowadź migrację danych, a następnie usunąć stare pole (skróć).
Dokumentowanie tych zmian w ERD jest kluczowe. Używaj komentarzy lub osobnych schematów, aby pokazać zastarzałe relacje wobec aktywnych. To zapobiega temu, by inżynierowie polegali na przestarzałych strukturach.
🛑 Zapobieganie łańcuchowym awariom
Awaria łańcuchowa występuje, gdy lokalna awaria wywołuje reakcję łańcuchową, która wpływa na całą system. Projektowanie danych odgrywa istotną rolę w ograniczaniu tych zdarzeń.
1. Przerywanie obwodów na warstwie danych
Tak jak implementujesz przerywacze obwodów w wywołaniach usług, powinieneś zaprojektować warstwę danych tak, aby obsługiwała timeouty zgodnie z zasadami. Jeśli zapytanie o odczyt zawiesi się, system nie powinien czekać bez końca.
- Ustaw timeouty: Zdefiniuj ściśle określone maksymalne czas trwania transakcji w bazie danych.
- Wartości domyślne: Jeśli dane nie mogą zostać pobrane, zwróć bezpieczną wartość domyślną lub wartość z pamięci podręcznej.
- Ograniczanie szybkości: Zapobiegaj temu, by pojedyncze ciężkie zapytanie zużyło wszystkie zasoby bazy danych.
2. Izolacja danych krytycznych
Oddziel dane krytyczne od danych niekrytycznych. Jeśli usługa profilu użytkownika ulegnie awarii, nie powinna to wpływać na usługę przetwarzania płatności. Ta izolacja odzwierciedla się w Twoim ERD poprzez odrębne schematy lub odrębne bazy danych fizyczne.
- Fragmentacja bazy danych: Podziel dane między wiele serwerów, aby ograniczyć zakres skutków awarii.
- Granica bazy danych usługi: Każda mikrousługa posiada swoją bazę danych wyłącznościowo.
- Rozdzielenie odczytu i zapisu: Używaj odrębnych połączeń do raportowania i pracy transakcyjnej.
📉 Usuwanie miękkie w porównaniu do usuwania twardego
W systemach rozproszonych usuwanie twarde jest ryzykowne. Jeśli jedna usługa usunie rekord, a inna usługa go oczekuje, druga usługa może się zawiesić lub wygenerować błędy. Usuwanie miękkie zapewnia bezpieczeństwo.
Zamiast usuwać wiersz, oznacz go jako usunięty za pomocą znacznika czasu lub flagi. Dzięki temu zachowana zostanie spójność referencyjna do celów audytu i raportowania, jednocześnie wskazując, że dane nie są już aktywne.
- Ślady audytu: Przechowuj dane historyczne w celu zgodności z przepisami i debugowania.
- Odzyskiwanie: Niechciane usunięcia można łatwo cofnąć.
- Wydajność: Unikaj obciążenia związane z usuwaniem wierszy z indeksów, choć zwiększa to potrzebę pamięci.
🔍 Obserwability w projektowaniu danych
Wytrzymałość nie dotyczy tylko zapobiegania, ale także wykrywania. Twój ERD powinien zawierać pola wspierające monitorowanie i debugowanie.
- Identyfikatory korelacji: Uwzględnij unikalny identyfikator, który przechodzi przez wszystkie powiązane jednostki, aby śledzić żądanie.
- Krotki wersji: Przechowuj numery wersji, aby wykrywać odchylenia schematu.
- Flagi stanu: Jawnie oznaczaj rekordy jako oczekujące, aktywne lub nieudane, aby ułatwić rozwiązywanie problemów.
📊 Porównanie wzorców projektowych
| Wzorzec | Zalety | Wady |
|---|---|---|
| Centralizowana baza danych | Proste relacje, łatwa spójność | Jedno miejsce awarii, ograniczenia skalowania |
| Baza danych na usługę | Izolacja, niezależne skalowanie | Złożone transakcje, spójność ostateczna |
| Współdzielony schemat | Łatwe łączenia, zintegrowany widok | Zaangażowanie, koordynacja wdrażania |
🧪 Testowanie Twojego projektu
Po narysowaniu ERD przetestuj go w warunkach awarii. Nie zakładaj, że model wytrzyma. Symuluj podziały sieci i awarie baz danych, aby zobaczyć, jak zachowują się relacje.
- Inżynieria chaosu: Wprowadzaj awarie do węzłów danych, aby obserwować odbudowę.
- Test obciążenia: Przepychaj system, aby sprawdzić, czy relacje ulegną uszkodzeniu pod naprężeniem.
- Test kontraktu: Sprawdź, czy kształty danych są zgodne między usługami.
📝 Ostateczne rozważania nad architekturą danych
Budowanie systemów odpornych wymaga przyznania, że awarie są nieuniknione. Twój diagram ER to pierwsza linia obrony przed chaosem. Poprzez priorytetyzowanie izolacji, jawną zarządzanie spójnością i planowanie ewolucji tworzysz fundament wspierający długoterminową stabilność. Celem nie jest doskonałość, ale łagodne degenerowanie. Gdy komponenty zawiedą, warstwa danych powinna chronić logikę biznesową przed całkowitym zawaleniem.
Przyjmij te strategie, aby upewnić się, że Twoje modele danych przyczyniają się do solidnej infrastruktury. Ciągła analiza Twojego schematu pod kątem rzeczywistych wzorców awarii utrzyma Twoje systemy zdrowe i reaktywne.

