Database design is the backbone of any robust application. When constructing an Entity Relationship Diagram (ERD), two opposing forces shape the schema: normalization and denormalization. Understanding when to apply each strategy determines the long-term health, performance, and maintainability of your data infrastructure. This guide addresses the most critical questions regarding these concepts, providing a clear path for designing efficient database structures without relying on specific software tools. 🛠️
Data integrity and query speed often pull in opposite directions. Normalization prioritizes integrity by reducing redundancy. Denormalization prioritizes speed by introducing controlled redundancy. Navigating this balance requires a deep understanding of relational theory and practical performance requirements. Let us explore the technical details through a series of targeted questions and answers. 📊
Understanding the Fundamentals: What Are We Dealing With? 🔍
Before diving into specific scenarios, we must define the core mechanisms at play in your ERD design.
What is Normalization? 🔄
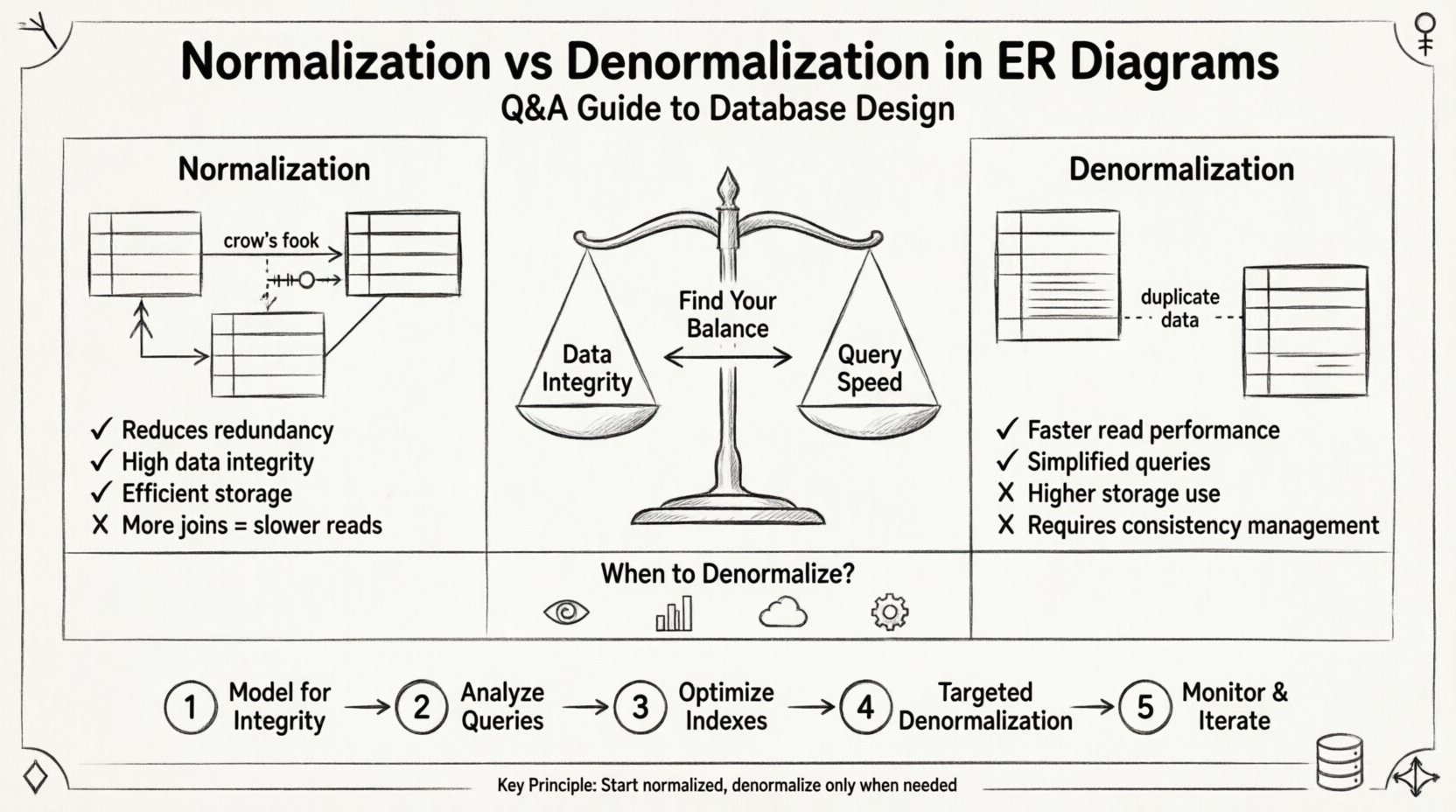
Normalization is a systematic process of organizing data in a database to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, logically connected tables and defining relationships between them. The goal is to ensure that each piece of data is stored in only one place.
- Goal: Eliminate duplicate data and ensure dependencies make sense.
- Benefit: Simplifies data maintenance and reduces storage requirements.
- Cost: Increases the complexity of queries due to the need for joins.
Normalization is typically achieved through a series of stages known as Normal Forms. Each form builds upon the previous one, addressing specific types of anomalies.
What is Denormalization? ⚖️
Denormalization is the intentional introduction of redundancy into a normalized database. This is done to optimize read performance, specifically in scenarios where query speed is more critical than write speed. It involves merging tables or adding redundant columns to avoid expensive join operations.
- Goal: Reduce the number of joins required for complex queries.
- Benefit: Faster read operations and simplified query logic.
- Cost: Increased storage usage and higher risk of data inconsistency.
Q&A: Deep Dive into Normalization and ERD Design 📝
These questions address the most common friction points encountered when designing relational schemas. They cover the transition from theory to practical implementation.
Q1: Do I need to normalize everything to 3NF? 🤷♂️
The short answer is no. While Third Normal Form (3NF) is a standard benchmark for many applications, it is not a hard rule for every scenario. Normalizing to 3NF eliminates transitive dependencies, ensuring that non-key attributes depend only on the primary key. However, achieving higher forms like Boyce-Codd Normal Form (BCNF) or Fourth Normal Form (4NF) can sometimes complicate the schema without providing significant benefits.
Consider the trade-offs:
- 3NF: Good for general-purpose transactional systems where data integrity is paramount.
- 4NF/5NF: Often overkill unless you are dealing with complex multi-valued dependencies or join dependencies.
- Practical Approach: Design for 3NF first. Evaluate performance bottlenecks before considering denormalization or further normalization.
Q2: How does normalization affect query performance? 🐢
Normalization impacts performance primarily through the requirement of joins. When data is spread across multiple tables, retrieving a complete record requires the database engine to link these tables together. This process consumes CPU and memory resources.
Key factors influencing performance include:
- Join Complexity: More tables mean more join conditions to evaluate.
- Indexing: Foreign keys must be indexed to speed up joins. Without proper indexing, normalization can lead to severe performance degradation.
- Data Volume: As the dataset grows, the cost of scanning and joining increases significantly.
In read-heavy applications, this overhead can become a bottleneck. In write-heavy applications, the overhead is often negligible compared to the benefit of reduced update anomalies.
Q3: When is it appropriate to denormalize? ⚙️
Denormalization should not be the default state. It is a corrective measure applied after identifying specific performance issues. You should consider denormalization in the following situations:
- Read-Heavy Workloads: If the system processes thousands of reads for every write, the cost of joins may outweigh the storage cost.
- Reporting Dashboards: Complex analytical queries often benefit from pre-joined data stored in wide tables.
- Caching Layers: Sometimes denormalization is implemented in a cache layer rather than the primary storage engine.
- Legacy Constraints: Older database engines or specific hardware limitations might struggle with complex joins.
Q4: How do I manage data consistency during denormalization? 🛡️
Introducing redundancy creates the risk of data inconsistency. If you store a customer name in both the Orders table and the Customers table, updating the name in the Customers table requires a cascade update to the Orders table.
Strategies to maintain consistency include:
- Application Logic: Ensure the application code updates all redundant fields within a single transaction.
- Database Triggers: Use triggers to automatically sync redundant columns when the source data changes.
- Periodic Reconciliation: Run scheduled jobs to audit and fix inconsistencies in denormalized data.
- Read-Replica Specialization: Keep the primary database fully normalized and use a denormalized copy for reporting.
Q&A: Advanced Scenarios and Trade-offs ⚖️
Beyond the basics, specific architectural challenges arise when scaling systems. These questions address those nuances.
Q5: Can I mix normalized and denormalized tables in the same ERD? 🧩
Yes, hybrid models are common in production environments. It is standard practice to maintain a core normalized schema for transactional integrity while creating denormalized views or summary tables for specific use cases.
For example:
- Core Tables: Keep users, products, and orders in 3NF to ensure accurate financial records.
- Reporting Tables: Create a denormalized table that aggregates order totals and customer details for fast dashboard rendering.
- Views: Use SQL views to present a denormalized structure to applications without physically duplicating data.
Q6: Does denormalization violate database theory? 📚
Theoretically, yes. Relational theory advocates for normalization to minimize anomalies. However, practical engineering often requires bending these rules to meet performance SLAs. The violation is intentional and calculated. As long as the redundancy is managed and documented, the design remains valid for its intended purpose.
Q7: How does indexing interact with normalization? 🔖
Indexing is the primary tool for mitigating the performance cost of normalization. When you normalize, you create foreign keys. These foreign keys must be indexed to allow efficient joining.
Consider the following points:
- Foreign Key Indexes: Every foreign key should have an index to speed up joins.
- Composite Indexes: If a query joins on multiple columns, a composite index can cover all join conditions.
- Denormalization Impact: Denormalization often reduces the need for foreign key indexes, potentially reducing write overhead on indexes.
Comparison: Normalization vs. Denormalization 📋
To visualize the trade-offs clearly, refer to the table below. This structure helps in decision-making during the design phase.
| Feature | Normalization | Denormalization |
|---|---|---|
| Data Redundancy | Minimized | Increased |
| Data Integrity | High | Requires Management |
| Storage Space | Efficient | Less Efficient |
| Read Performance | Slower (more joins) | Faster (fewer joins) |
| Write Performance | Faster (less data to update) | Slower (update all copies) |
| Complexity | High (many tables) | High (logic to sync data) |
| Best Use Case | OLTP, Transactional Systems | OLAP, Reporting, Read-Heavy |
Implementation Strategy: A Step-by-Step Approach 🚀
Designing a schema requires a methodical process. Do not rush to denormalize. Follow this structured approach to ensure a stable foundation.
Step 1: Model for Integrity First 🏗️
Start by creating a fully normalized schema. Aim for at least Third Normal Form (3NF). Identify all entities, attributes, and relationships. Ensure that every table has a primary key and that foreign keys are properly defined. This phase ensures your data is accurate and consistent.
Step 2: Analyze Query Patterns 🔎
Before changing the schema, understand how the data will be accessed. Review the application requirements and query logs. Identify which queries are slow or complex. Look for patterns where multiple joins are frequently required.
Step 3: Optimize Indexes ⚡
Before denormalizing, ensure your normalized schema is indexed correctly. Often, adding the right composite indexes resolves performance issues without needing to alter the table structure. Test the queries with the current schema and indexes to establish a baseline.
Step 4: Targeted Denormalization 🎯
If performance is still insufficient, apply denormalization selectively. Do not denormalize the entire database. Focus only on the specific tables or columns causing the bottleneck. Document every change made for future maintenance.
Step 5: Monitor and Iterate 📈
Database design is not static. Monitor the system over time. As data volume grows or usage patterns shift, the balance may need to be adjusted. Regularly review the schema to ensure it still meets the performance and integrity requirements.
Common Pitfalls to Avoid 🚫
Even experienced designers can stumble when dealing with ERD optimization. Watch out for these common errors.
- Over-Normalization: Creating too many tables makes the schema difficult to understand and query. Keep the structure logical and intuitive.
- Under-Normalization: Storing too much data in a single table leads to update anomalies and wasted space.
- Ignoring Data Growth: A design that works with 1,000 records may fail with 1,000,000. Plan for scale.
- Hidden Denormalization: Denormalizing without documentation leads to confusion. Future maintainers may not understand why data is duplicated.
- Assuming All Queries Are Equal: Not all queries have the same performance requirements. Prioritize the most frequent and critical ones.
Final Thoughts on Schema Architecture 🧠
The decision between normalization and denormalization is not binary. It is a spectrum of trade-offs that depends on your specific application needs. A well-designed ERD balances data integrity with query efficiency. By understanding the underlying principles and following a structured approach, you can build systems that are both robust and performant.
Remember that tools and technologies evolve. The principles of relational design, however, remain constant. Focus on the data model itself rather than the capabilities of the database engine. A solid foundation will support your application regardless of the infrastructure changes that come in the future. Keep your schema clean, your documentation clear, and your performance metrics in mind at every step. 🌟

