











データベース構造を設計することはソフトウェア開発の基盤となるステップだが、初心者にとっては難しく感じられることが多い。始めには高価なソフトウェアが必要だと考えがちだが、データモデリングの核心的な論理は特定のアプリケーションに依存せずに存在する。このガイドは、エンティティ関係図(ERD)の基本を扱う。デジタルなごちゃごちゃを排除することで、鉛筆と紙だけでデータのアーキテクチャを理解できる。
手で描くことの学びはER図手で描くことで論理的思考力が磨かれる。コードを1行も書く前に、関係性を明確に定義しなければならない。シンプルな在庫管理システムを設計している場合でも、複雑な電子商取引プラットフォームを設計している場合でも、原則は同じである。このガイドでは、データベーススキーマの構造、関係性のマッピング方法、自動化ツールに頼らずにデータフローを可視化する方法について探求する。
🤔 そもそもER図とは何か?
エンティティ関係図は、システム内のデータの構成方法を視覚的に表現したものです。データベースの設計図として機能します。すぐに行と列を見るのではなく、オブジェクト(エンティティ)とそれらの相互作用(関係)に注目します。この高レベルの視点により、ステークホルダーはデータ構造に埋め込まれたビジネスロジックを理解しやすくなります。
ER図を作成する際、あなたは実質的にすべてのデータに対して3つの根本的な問いに答えることになる。
- 何がデータが説明しているのか?(エンティティ)
- 何がそのオブジェクトを定義するのか?(属性)
- どのようにこのオブジェクトは他のものとどのようにつながるのか?(関係)
これらの視覚的補助がないと、データベース設計はしばしば当てずっぽうのゲームになってしまう。重複するデータや、後でアプリケーションを破綻させる可能性のある接続の欠落が生じる可能性がある。適切に構築された図は、こうした問題が発生する前に防ぐことができる。
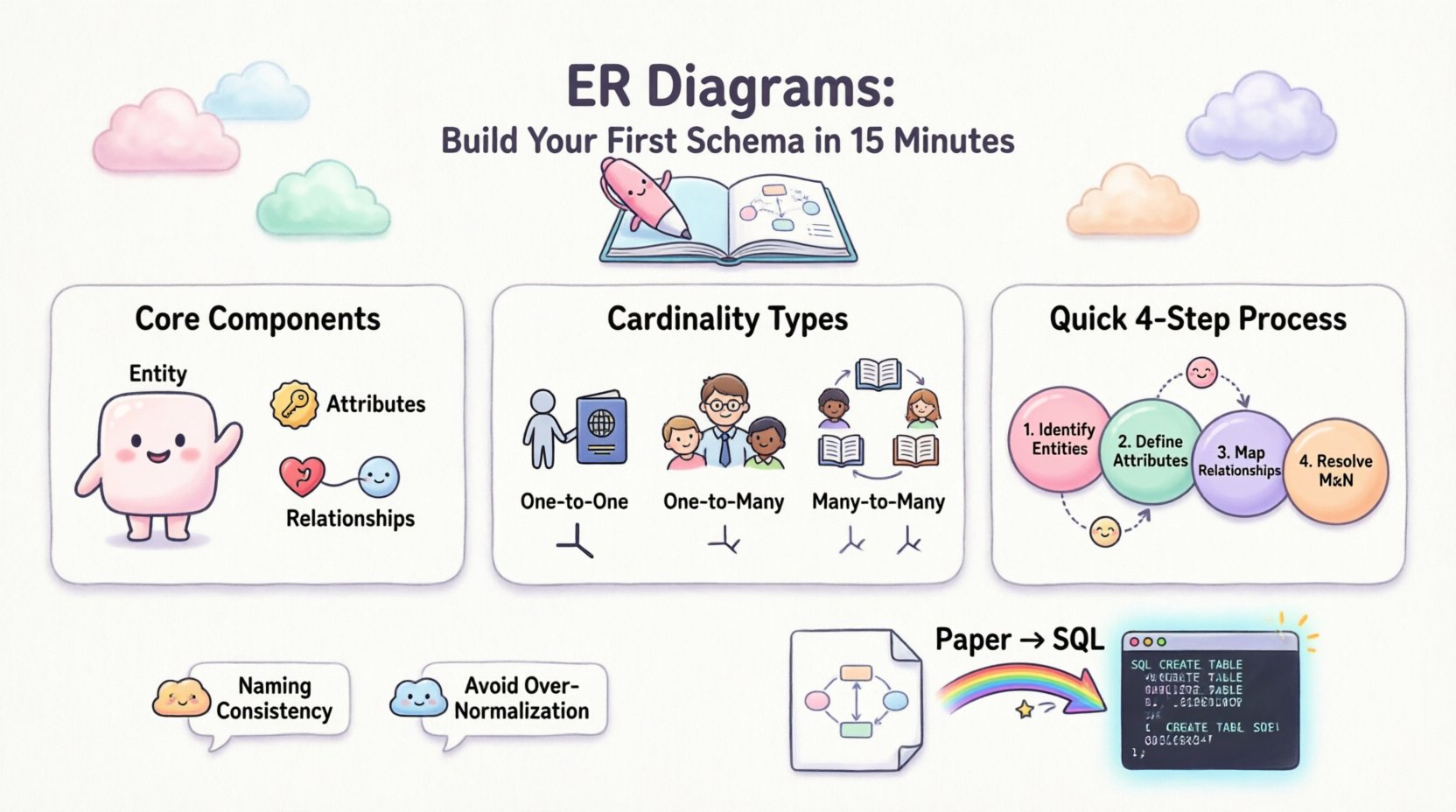
🧱 スキーマの核心的な構成要素
どんな線も引く前に、構成要素を理解する必要がある。すべてのER図は3つの主要な要素で構成される。1つでも見落とすと、モデルは不完全になる。
1. エンティティ
エンティティとは、情報を保存したい現実世界のオブジェクトや概念を表すものである。物理的なデータベースでは、これはテーブルに対応する。図では、通常は長方形で描かれる。
- 例:図書館システムにおいて、書籍, 著者、および会員はすべてエンティティである。
- 例: オンラインショッピングストアでは、商品, 顧客、および注文はエンティティです。
2. 属性
属性とは、エンティティを説明する具体的な情報のことを指します。これらはデータベースのテーブルの列になります。オブジェクトのプロパティを定義します。
- 例: の場合、属性には会員エンティティについて、次の属性が含まれるかもしれません会員ID, 氏名, メールアドレス、および登録日.
- 主キー: 1つの属性は、すべてのレコードに対して一意でなければなりません。これは通常、下線を引くか、明確にマークされます。会員の場合、会員ID会員IDが主キーです。
- 外部キー:別のエンティティの主キーにリンクする属性です。
3. 関係
関係性は、エンティティがどのように相互作用するかを定義します。2つの長方形をつなぐ線は、関係性を示しています。これは、1つのエンティティのデータが、別のエンティティのデータと関連していることを意味します。
- 例: A 会員は多くを借りることができる本.
- 例: A 本は1つの特定の著者.
🔗 関係性と基数の理解
基数はERモデル化において最も重要な概念です。エンティティ間の数的関係を定義します。次の質問に答えます:「エンティティAのインスタンスが、エンティティBの1つのインスタンスと何個関連していますか?」基数を誤解すると、データの重複や孤立レコードが生じます。
あなたが遭遇する主な基数の種類は3つあります:
| 基数の種類 | 説明 | 現実世界の例 |
|---|---|---|
| 1対1(1:1) | テーブルAの1レコードが、テーブルBの正確に1レコードと関連します。 | 個人とそのパスポート。1人の個人が1つのパスポートを持ち、1つのパスポートは1人の個人に属する。 |
| 1対多(1:N) | テーブルAの1レコードが、テーブルBの多くのレコードと関連します。逆は成り立ちません。 | 部署と従業員。1つの部署に多くの従業員が所属しますが、各従業員は1つの部署にのみ所属します。 |
| 多対多(M:N) | テーブルAの多くのレコードが、テーブルBの多くのレコードと関連します。 | 学生と授業。学生は多くの授業を受講し、授業には多くの学生がいます。 |
これらの図を紙に描く際には、線がどのように接続されるかを視覚化する必要があります。多対多の関係では、接続を2つの1対多の関係に分解するために、結合テーブル(または関連エンティティ)が必要になることがよくあります。これは正規化の重要なステップです。
✍️ 表記スタイルの選択
ER図を描くための単一の普遍的な基準は存在しませんが、業界を支配している2つのスタイルがあります。どちらを使うかを知っていると、他の開発者と効果的にコミュニケーションを取ることができます。
1. クラウズフット表記法
これは現代のデータベース設計で最も一般的に使われるスタイルです。関係線の端に記号を用いて、基数を示します。
- 単線:必須参加(存在しなければならない)を示す。
- ダイアモンドまたはフォーク:「複数」を示す。
- ダッシュ:「オプション」(ゼロ)を示す。
この表記法は簡潔で、SQLツールによって広くサポートされています。ホワイトボードでの素早いスケッチに最適です。
2. チェン表記法
概念を提唱したピーター・チェンにちなんで名付けられたこの表記法は、関係にはダイアモンド、属性には楕円を使用します。より冗長ですが、非常に明確です。
- 長方形:エンティティ。
- ダイアモンド:関係。
- 楕円:属性。
チェン表記法は概念の説明に非常に適していますが、必要な図形の数が多くなるため、複雑なスキーマにはあまり実用的ではありません。大多数のプロフェッショナルな環境では、コンパクトさを理由にクラウズフット表記法が好まれます。
📄 ステップバイステップ:最初の手動ER図の作成
描き始めますか?簡略化されたオンライン書店のスキーマを作成する手順を一緒に見ていきましょう。あなたが白紙の紙やホワイトボードを持っていると仮定します。始めるにはソフトウェアは必要ありません。
ステップ1:エンティティを特定する
要件を読みましょう。主な名詞は何ですか?このケースでは、以下のものを追跡する必要があります:
- 顧客(購入する人)
- 注文(取引)
- 商品(販売されるもの)
- カテゴリ(アイテムがどのようにグループ化されるか)
紙に四つの長方形を描き、はっきりとラベルを付けてください。
ステップ2:属性を定義する
各長方形について、必要な詳細をリストアップしてください。今はシンプルに保ってください。
- 顧客:顧客ID、名、姓、メールアドレス、住所。
- 注文:注文ID、注文日、合計金額、配送先住所。
- 製品:製品ID、名前、価格、在庫数量。
- カテゴリ:カテゴリID、カテゴリ名、説明。
主キーを丸で囲み、IDフィールドを下線を引いて目立たせます。
ステップ3:関係をマッピングする
今、ビジネスルールに基づいてエンティティの間に線を引きます。
- 顧客から注文:1人の顧客が多数の注文を行う。(1:N)
- 注文から製品:1つの注文に多数の製品が含まれる。1つの製品は多数の注文に含まれる。(M:N)
- 製品からカテゴリ:1つの製品は1つのカテゴリに属する。1つのカテゴリには多数の製品がある。(1:N)
ステップ4:多対多の解決
あなたは、注文と製品注文と製品には多対多の関係があることがわかりました。ブリッジがなければ、物理的なデータベースではそれらの間に直接線を引くことはできません。新しいエンティティが必要です。
- 「注文項目.
- リンク注文へ注文項目 (1:N)。
- リンク製品へ注文項目 (1:N)。
- に属性を追加する:注文項目:数量、小計。
このステップでは、概念モデルを実装可能な論理モデルに変換します。
🚫 避けるべき一般的な落とし穴
概念をしっかり理解していても、初心者はスキーマを複雑にするようなミスをよく犯します。これらの一般的な問題に注意してください。
1. 名前衝突
「Data1」や「TableA」のような一般的な名前を使うと、図が読みにくくなります。具体的なビジネス名を使用してください。「FK_Customer」の代わりに「CustomerID」を使用してください。命名規則の一貫性は、長期的な保守にとって非常に重要です。
2. 過剰な正規化
正規化は冗長性を減らしますが、テーブルを多すぎるとクエリが遅くなり、複雑になります。関係がほとんどクエリされない場合は、パフォーマンスを考慮してデータを1つのテーブルに保持することを検討してください。整合性と使いやすさのバランスを取ることが重要です。
3. NULL値を無視する
フィールドが空になる可能性があるかどうか常に検討してください。もし顧客登録にはメールアドレスが必要である場合、Not Nullとしてマークしてください。もし製品はまだカテゴリが割り当てられていない場合、NULLを許可してください。この論理は図の制約に含まれるべきです。
4. 循環依存
エンティティAがBに依存し、BがCに依存し、CがAに依存するようなループを作らないようにしてください。これはデータ挿入時に論理的なデッドロックを引き起こします。常にデータの明確な階層構造またはエントリポイントを確保してください。
📈 ペーパーから本番環境へ
手作業で描いた図が完成し承認されたら、データベースに変換する段階です。このプロセスを物理モデリングといいます。
1. SQLに変換する
各長方形はCREATE TABLEステートメントになります。各プライマリキーはPRIMARY KEY制約になります。各関係性の線はFOREIGN KEY制約になります。手書きで記述することも、データベースクライアントを使用することもできます。
2. データ型の検証
図では価格と記載しました。データベースでは、これがINT, FLOAT、またはDECIMALのいずれかに決定する必要があります。通貨の場合は、常にDECIMAL丸め誤差を避けるためです。この決定は図が描かれた後に行われます。
3. ロジックを文書化する
紙の図をプロジェクトのドキュメントに残しておきましょう。新しい開発者を雇った場合、このスケッチはコードのコメントよりもデータ構造をよりよく説明します。特定のテーブルが存在する理由という文脈を提供します。
🎨 効果的なビジュアルデザインのヒント
デジタルツールがなくても、プレゼンテーションは重要です。乱雑な図は読みにくいです。
- 一貫した間隔を使用する:長方形を揃えて配置する。線がランダムに交差しないようにする。
- 線にラベルを付ける:ただ線を引くだけではなく、端に「1」または「Many」を書き、カーディナリティをすぐに明確にする。
- 関連するエンティティをグループ化する:「請求」に関連するテーブルのグループがある場合は、ページ上で近くに配置する。
- 色を使う:マーカーがある場合は、エンティティに一つの色、関係性に別の色を使う。この視覚的な違いにより、理解が早くなります。
🛠️ ツールを使わずに始める理由
すぐに図作成アプリを開きたくなるのは当然ですが、鉛筆と紙から始めるには独自の利点があります。
- スピード:数分でざっくりとしたレイアウトをスケッチできます。画面で図形を移動するのは時間がかかります。
- 集中:ドラッグアンドドロップ機能がないため、外見ではなくロジックに集中できます。
- 柔軟性:紙の間違いを消すのは即座です。デジタル図の再構成は面倒な場合があります。
- 協働:ホワイトボードでの会議は、承認の申請なしにチームがリアルタイムで変更をアイデア出しできます。
ロジックが固まったら、必要に応じてそのコンセプトをデジタルツールにインポートできます。しかし、思考プロセスは常にソフトウェアのインターフェースではなく、データそのものから始めるべきです。
📚 データの旅の次のステップ
手作業でERDを作成できたので、実装に進むことができます。まずローカル開発環境でテーブルを作成し、ダミーデータを挿入するクエリを実行します。関係性が正しいか確認しましょう。
システムが成長するにつれて、図を再確認しましょう。通知やログ用の新しいエンティティを追加し、要件の変更に応じて属性を更新します。データベーススキーマは静的ではなく、アプリケーションと共に進化します。
手作業での設計プロセスを習得することで、データベースアーキテクチャについてより深い理解を得られます。構造を構築するためにウィザードに頼らなくなり、パフォーマンスと整合性を最適化する意図的な意思決定を始めるのです。この基盤は、将来選ぶ技術スタックに関わらず、あなたにとって大きな助けになります。
鉛筆を手に取り、机を片付け、スケッチを始めましょう。将来のアプリケーションのロジックは、ページ上の単なる一線から始まります。

