











पारंपरिक स्थानीय इंफ्रास्ट्रक्चर से बादल-स्वामी वातावरण में स्थानांतरण डेटा के भंडारण, पहुंच और प्रबंधन के तरीके में एक मूलभूत परिवर्तन का प्रतिनिधित्व करता है। डेटाबेस प्रशासकों (डीबीएस) के लिए, इस संक्रमण के लिए केवल मौजूदा स्कीमा के स्थानांतरण से अधिक आवश्यकता होती है। वितरित प्रणालियों की विशिष्ट सीमाओं और क्षमताओं के अनुरूप एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) की पुनर्मूल्यांकन की आवश्यकता होती है। यह मार्गदर्शिका आधुनिक बादल वास्तुकला में स्केलेबिलिटी, लचीलापन और प्रदर्शन को समर्थन देने वाले ईआर डायग्राम डिज़ाइन के बारे में व्यापक जानकारी प्रदान करती है। 📊
डेटा वास्तुकला में परिवर्तन को समझना 🔄
पारंपरिक डेटाबेस डिज़ाइन अक्सर सख्त नॉर्मलाइजेशन और केंद्रीकृत नियंत्रण को प्राथमिकता देता है। इसके विपरीत, बादल-स्वामी वास्तुकला उपलब्धता, खंडन सहिष्णुता और क्षैतिज स्केलिंग पर जोर देती है। मुख्य अंतर विफलता की मान्यता में है। एक मोनोलिथिक सेटअप में, डेटाबेस एकल विफलता का बिंदु है। बादल-स्वामी वातावरण में, नोड्स अक्सर विफल होते हैं, और प्रणाली को तुरंत अनुकूलित करने की आवश्यकता होती है।
इस वातावरण के लिए ईआर डायग्राम डिज़ाइन करते समय, डीबीएस को निम्नलिखित बातों पर विचार करना चाहिए:
- वितरित सुसंगतता: जब डेटा क्षेत्रों के बीच विभाजित होता है, तो संबंध कैसे बने रहते हैं?
- लेटेंसी: डेटा नोड्स के बीच भौतिक दूरी का प्रश्न प्रदर्शन पर कैसे प्रभाव डालती है?
- लागत: स्टोरेज रिडंडेंसी और लेनदेन लागत के बीच क्या व्यापार बलिदान है?
- संचालन जटिलता: क्या स्कीमा को निरंतर मैन्युअल हस्तक्षेप के बिना प्रबंधित किया जा सकता है?
इन कारकों को नजरअंदाज करने से ऐसी प्रणालियों का निर्माण हो सकता है जिन्हें स्केल करना या बनाए रखना मुश्किल हो। एक अच्छी तरह से डिज़ाइन किया गया ईआर डायग्राम डेटा प्रवाह के लिए ब्लूप्रिंट के रूप में कार्य करता है, जिससे यह सुनिश्चित होता है कि आधारभूत इंफ्रास्ट्रक्चर बिजनेस लॉजिक को बॉटलनेक के बिना समर्थन कर सके। 🚀
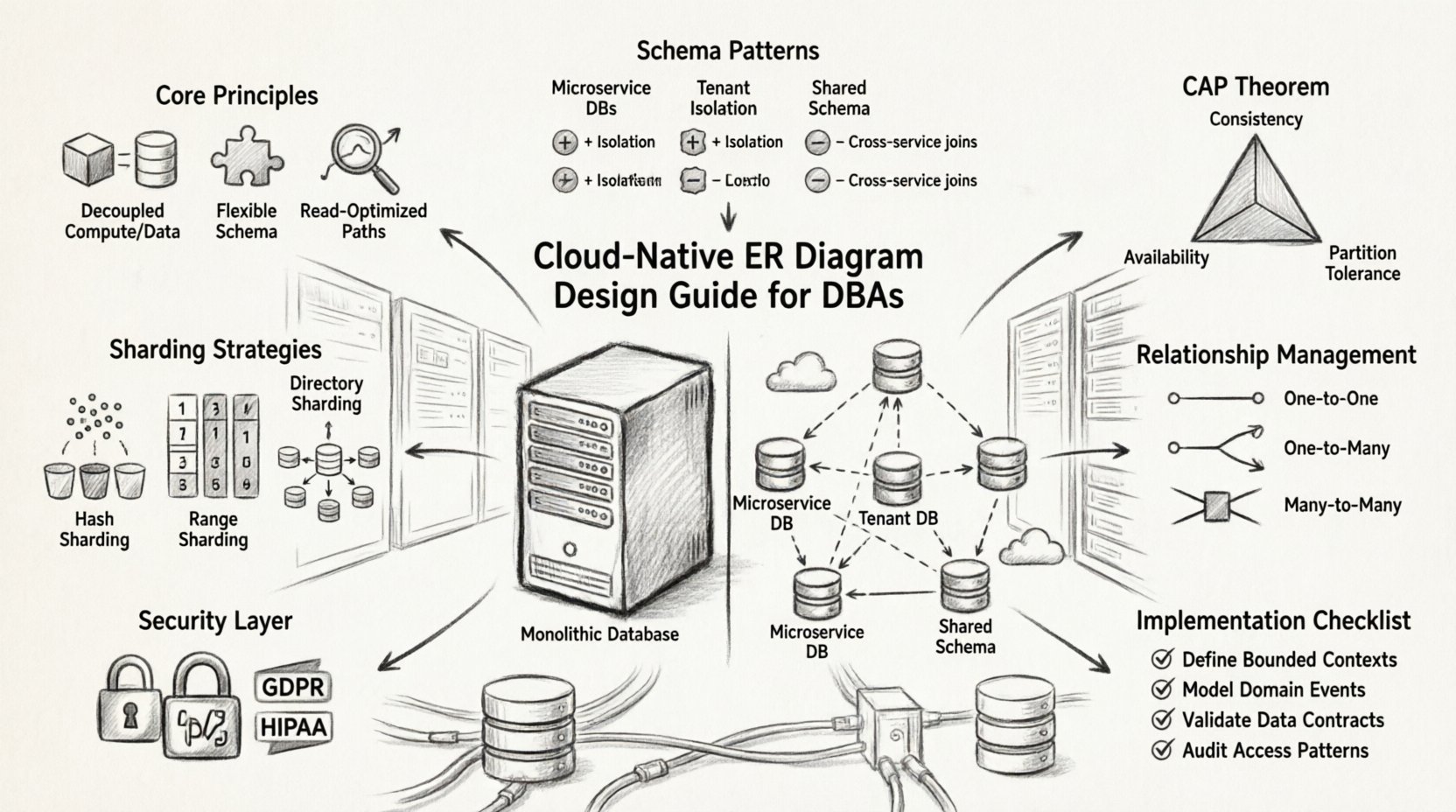
बादल-स्वामी ईआरडी के मूल सिद्धांत ⚙️
विशिष्ट पैटर्न में डूबने से पहले, बादल-स्वामी डेटा मॉडलिंग के पारंपरिक दृष्टिकोण से अंतर रखने वाले मार्गदर्शक सिद्धांतों को समझना आवश्यक है।
1. डेटा को गणना से अलग करना
बहुत से पुराने प्रणालियों में, डेटाबेस सर्वर और एप्लिकेशन सर्वर एक दूसरे से घनिष्ठ रूप से जुड़े होते हैं। बादल-स्वामी डिज़ाइन इन दोनों मुद्दों को अलग करता है। ईआरडी को इस बात को दर्शाना चाहिए कि अलग-अलग सेवाओं के बीच सिंक्रोनस संचार की आवश्यकता वाले निर्भरता को न्यूनतम किया जाए।
2. स्कीमा लचीलापन को अपनाना
जबकि एसक्यूएल डेटाबेस कठोर होते हैं, बादल-स्वामी वातावरण अक्सर पॉलीग्लॉट पर्सिस्टेंस का उपयोग करते हैं। इसका अर्थ है कि अलग-अलग डेटा प्रकारों के लिए अलग-अलग स्टोरेज मॉडल की आवश्यकता हो सकती है। ईआर डायग्राम को तार्किक संबंधों को दर्शाना चाहिए, भले ही भौतिक कार्यान्वयन भिन्न हों (उदाहरण के लिए, रिलेशनल टेबल के साथ जीएसओएन स्टोर)।
3. पढ़ने-पर आधारित कार्यभार के लिए अनुकूलन करना
बादल एप्लिकेशन अक्सर एक साथ मिलियनों उपयोगकर्ताओं को सेवा देते हैं। ईआर डिज़ाइन को प्रभावी पढ़ने के मार्गों का समर्थन करना चाहिए, भले ही इसके लिए कुछ रिडंडेंसी शामिल करनी पड़े। डेनॉर्मलाइजेशन एक रणनीतिक उपकरण बन जाता है, बल्कि एक गुनाह नहीं।
स्केलेबिलिटी के लिए स्कीमा डिज़ाइन पैटर्न 📈
सही स्कीमा पैटर्न का चयन प्रदर्शन के लिए महत्वपूर्ण है। नीचे वितरित प्रणालियों में उपयोग किए जाने वाले सामान्य दृष्टिकोण दिए गए हैं।
प्रत्येक सेवा के लिए एक डेटाबेस
प्रत्येक माइक्रोसर्विस अपने डेटाबेस स्कीमा का प्रबंधन करता है। इस अलगाव से सेवा विफलताओं के कैस्केडिंग को रोका जाता है। संपूर्ण प्रणाली के लिए ईआर डायग्राम छोटे, स्वतंत्र डायग्रामों का संग्रह बन जाता है, जो तार्किक संदर्भों द्वारा जुड़े होते हैं।
स्कीमा अलगाव के साथ साझा डेटाबेस
बहुत सेवाएं एक ही डेटाबेस इंस्टेंस को साझा करती हैं, लेकिन अलग-अलग स्कीमा नामस्थान बनाए रखती हैं। इससे इंफ्रास्ट्रक्चर लागत कम होती है, लेकिन टाइट कपलिंग के जोखिम को बढ़ाता है। बड़े पैमाने पर बादल डेप्लॉयमेंट के लिए इसे आमतौर पर निषेध किया जाता है।
प्रत्येक टेंट के लिए डेटाबेस
बहु-टेंट एसएएस एप्लिकेशन में, प्रत्येक ग्राहक को एक निर्दिष्ट डेटाबेस इंस्टेंस मिलता है। ईआरडी डिज़ाइन को सभी इंस्टेंस में संगत रहना चाहिए, ताकि माइग्रेशन और अपडेट समान रूप से लागू हों।
स्कीमा पैटर्न की तुलना
| पैटर्न | लाभ | नुकसान | सर्वोत्तम उपयोग केस |
|---|---|---|---|
| एकल डेटाबेस | सरल जॉइन, ACID संगतता | एकल विफलता का बिंदु, स्केलिंग सीमाएं | मोनोलिथिक एप्लिकेशन, कम ट्रैफिक |
| सेवा प्रति डेटाबेस | स्वतंत्र स्केलिंग, दोष अलगाव | जटिल लेनदेन, वितरित जॉइन | माइक्रोसर्विसेज, उच्च वृद्धि |
| प्रति टेंटेन्ट डेटाबेस | डेटा अलगाव, संगतता में आसानी | उच्च इंफ्रास्ट्रक्चर लागत, प्रबंधन ओवरहेड | SaaS प्लेटफॉर्म, नियमित उद्योग |
| साझा स्कीमा | कम लागत, साझा क्वेरीज | वेंडर लॉक-इन, स्केलिंग बॉटलनेक | आंतरिक उपकरण, MVPs |
सेवाओं के बीच संबंधों का प्रबंधन 🔗
एक वितरित आर्किटेक्चर में, विदेशी कुंजियां हमेशा संभव नहीं होती हैं। संदर्भी अखंडता को अलग तरीके से प्रबंधित करने की आवश्यकता होती है। ईआर आरेख को इन तार्किक संबंधों को स्पष्ट रूप से दर्शाना चाहिए, भले ही भौतिक निर्बलन एप्लिकेशन लेयर या असिंक्रोनस प्रक्रियाओं के माध्यम से हो।
संबंधों के प्रकार
- एक से एक:आमतौर पर डेटा को सीधे एम्बेड करके संभाला जाता है ताकि जॉइन लेटेंसी कम की जा सके।
- एक से बहुत अधिक: बच्चे के रिकॉर्ड को कैसे स्टोर किया जाए, इस पर सावधानी से विचार करने की आवश्यकता होती है। यदि माता-पिता बदलता है, तो बच्चे भी बदलते हैं?
- बहुत से बहुत से: आमतौर पर एक संबंध सारणी के माध्यम से कार्यान्वित किया जाता है। क्लाउड वातावरण में, इस सारणी को स्वतंत्र रूप से शेड करने की आवश्यकता हो सकती है।
संदर्भात्मक अखंडता का प्रबंधन
कठोर विदेशी कुंजी प्रतिबंधों के बिना, डेटा सुसंगतता एप्लिकेशन तर्क पर निर्भर करती है। रणनीतियाँ शामिल हैं:
- मृदु डिलीट्स:इतिहास को बरकरार रखने के लिए उन्हें हटाने के बजाय रिकॉर्ड को निष्क्रिय चिह्नित करना।
- अंततः सुसंगतता:सेवाओं के बीच बदलावों के प्रसार के लिए इवेंट स्ट्रीम का उपयोग करना।
- प्रतिकारी लेनदेन:वितरित वर्कफ्लो में विफलताओं का प्रबंधन करने वाली रोलबैक तर्क।
पार्टीशनिंग और शार्डिंग रणनीतियाँ 🗂️
जैसे-जैसे डेटा का आयतन बढ़ता है, एक ही डेटाबेस नोड लोड को संभाल नहीं पाता है। पार्टीशनिंग (शार्डिंग) डेटा को कई नोड्स पर विभाजित करती है। ईआर आरेख में यह दिखाना चाहिए कि डेटा कैसे वितरित किया जाता है ताकि हॉटस्पॉट से बचा जा सके।
शार्डिंग कुंजियाँ
शार्डिंग कुंजी का चयन यह तय करता है कि प्रश्नों को कैसे रूट किया जाता है। एक अच्छी कुंजी डेटा को समान रूप से वितरित करती है और एक्सेस पैटर्न के साथ मेल खाती है।
- हैश-आधारित:डेटा को यादृच्छिक रूप से वितरित करता है। समान एक्सेस के लिए अच्छा, रेंज क्वेरी के लिए बुरा।
- रेंज-आधारित:मान (जैसे तारीखें या आईडी) के आधार पर डेटा को विभाजित करता है। रेंज क्वेरी के लिए अच्छा, असमान वितरण के जोखिम के साथ।
- डायरेक्टरी-आधारित:डेटा को स्थान ज्ञात करने के लिए मैपिंग सेवा बनाए रखता है। लेटेंसी बढ़ाता है लेकिन लचीले स्थानांतरण की अनुमति देता है।
ईआर आरेखों पर प्रभाव
ईआरडी डिजाइन करते समय ध्यान दें कि:
- अक्सर जोड़े जाने वाले तालिकाओं को आदर्श रूप से एक साथ स्थित किया जाना चाहिए ताकि नेटवर्क ट्रैफिक कम किया जा सके।
- ग्लोबल तालिकाएँ (जैसे कॉन्फ़िगरेशन डेटा) को अनशार्ड रखा जाना चाहिए।
- इंडेक्स को शार्ड सीमाओं के भीतर काम करने के लिए डिज़ाइन किया जाना चाहिए।
सुसंगतता मॉडल और कैप थ्योरम ⚖️
कैप थ्योरम कहता है कि एक वितरित प्रणाली केवल तीन में से दो गुणों को गारंटी दे सकती है: सुसंगतता, उपलब्धता, और विभाजन सहिष्णुता। क्लाउड-नेटिव प्रणालियाँ विभाजन सहिष्णुता को प्राथमिकता देती हैं, जिससे सुसंगतता और उपलब्धता के बीच चयन करने के लिए मजबूर किया जाता है।
सही मॉडल का चयन करना
| मॉडल | विवरण | ईआरडी प्रभाव |
|---|---|---|
| ताकतवर सुसंगतता | सभी नोड्स एक ही समय में एक ही डेटा देखते हैं | सिंक्रोनस लेखन की आवश्यकता होती है; लेखन थ्रूपुट को सीमित करता है |
| अंततः सुसंगतता | एक देरी के बाद डेटा सुसंगत हो जाता है | एसिंक्रोनस लेखन की अनुमति देता है; पुराने पढ़ने के साथ निपटने की आवश्यकता होती है |
| कारण संबंधी सुसंगतता | कारण संबंधी क्रियाओं के क्रम को बनाए रखता है | ERD में निर्भरताओं का जटिल ट्रैकिंग |
वित्तीय एप्लिकेशन के लिए, मजबूत सुसंगतता अक्सर आवश्यक होती है। सोशल फीड के लिए, अंततः सुसंगतता स्वीकार्य है। ER आरेख में उन टेबल्स को नोट करना चाहिए जिन्हें सख्त क्रम आवश्यक है और जिन्हें देरी का सहारा मिल सकता है।
उच्च थ्रूपुट वातावरणों के लिए इंडेक्सिंग 🏷️
स्टोरेज लागत और नेटवर्क बैंडविड्थ के कारण क्लाउड में इंडेक्सिंग रणनीतियाँ ऑन-प्रेमाइज़ से अलग होती हैं। प्रत्येक इंडेक्स लेखन संसाधनों और स्टोरेज स्थान का उपयोग करता है।
इंडेक्सिंग बेस्ट प्रैक्टिसेज
- सेकेंडरी इंडेक्स को कम से कम रखें: केवल उन कॉलम को इंडेक्स करें जो अक्सर क्वेरी प्रीडिकेट में उपयोग किए जाते हैं।
- कवरिंग इंडेक्स के बारे में सोचें: टेबल लुकअप से बचने के लिए इंडेक्स में सभी आवश्यक कॉलम शामिल करें।
- इंडेक्स उपयोग का मॉनिटरिंग करें: अनावश्यक संरचनाओं को हटाने के लिए इंडेक्स प्रदर्शन का नियमित रूप से ऑडिट करें।
- पार्टीशन्ड इंडेक्स: इंडेक्स संरचनाओं को डेटा पार्टीशनिंग रणनीति के साथ मिलाएं।
ग्लोबल बनाम लोकल इंडेक्स
ग्लोबल इंडेक्स सभी शार्ड्स को कवर करते हैं और बनाए रखने में महंगे हो सकते हैं। लोकल इंडेक्स एक शार्ड के भीतर रहते हैं और सस्ते होते हैं। ERD डिजाइन करते समय, यह निर्दिष्ट करें कि कौन से इंडेक्स ग्लोबल हैं और कौन से लोकल हैं ताकि इंफ्रास्ट्रक्चर टीम को मार्गदर्शन मिल सके।
सुरक्षा और संगतता के मामले 🛡️
क्लाउड में डेटा सुरक्षा के लिए एन्क्रिप्शन, एक्सेस कंट्रोल और GDPR या HIPAA जैसे नियमों के अनुपालन शामिल हैं। ER आरेख में डेटा संवेदनशीलता स्तरों को दर्शाना चाहिए।
डेटा वर्गीकरण
संवेदनशीलता के आधार पर डेटा एंटिटीज को टैग करें:
- सार्वजनिक: कोई विशेष सुरक्षा की आवश्यकता नहीं है।
- आंतरिक: केवल कर्मचारियों द्वारा ही पहुंच योग्य।
- सीमित: एन्क्रिप्शन और सख्त पहुंच लॉगिंग की आवश्यकता है।
आराम और पारगमन में एन्क्रिप्शन
सभी संवेदनशील फ़ील्ड को एन्क्रिप्शन के लिए चिह्नित किया जाना चाहिए। ईआरडी में स्पष्ट रूप से संवेदनशील डेटा को स्टोर नहीं किया जाना चाहिए। इसके बजाय, इसे एन्क्रिप्टेड कॉलम या टोकन को संदर्भित करना चाहिए।
संगति और बनाए रखना
कुछ डेटा को निश्चित अवधि तक बनाए रखना या पूरी तरह से हटाना आवश्यक है। ईआर डिज़ाइन में बनाए रखने की नीतियों और ऑडिट ट्रेल के लिए मेटाडेटा फ़ील्ड शामिल होने चाहिए।
संस्करण निर्माण और स्कीमा विकास 🔄
क्लाउड-नेटिव वातावरणों में, स्कीमा परिवर्तन के लिए बंदी दर्जा दुर्लभ है। माइग्रेशन को ऑनलाइन किया जाना चाहिए। ईआरडी को संस्करण निर्माण रणनीतियों का समर्थन करना चाहिए।
पीछे की संगतता
नए स्कीमा संस्करणों को एप्लिकेशन तर्क के साथ पीछे की संगतता होनी चाहिए। इससे बदलावों के धीरे-धीरे लागू करने की अनुमति मिलती है।
माइग्रेशन पैटर्न
- कॉलम जोड़ें: मौजूदा डेटा को बदले बिना नए फ़ील्ड जोड़ें।
- डबल लेखन: संक्रमण के दौरान पुरानी और नई संरचनाओं दोनों में लिखें।
- कटओवर: डेटा माइग्रेट करने के बाद पढ़ने और लिखने के ट्रैफ़िक को बदलें।
- कॉलम हटाएं: अनिर्देशित फ़ील्ड को केवल तभी हटाएं जब यह सुनिश्चित हो कि कोई निर्भरता नहीं है।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी डीबीए भी क्लाउड-नेटिव डिज़ाइन में अनुकूलन करते समय गलतियां कर सकते हैं। यहां सामान्य गलतियां हैं।
- अत्यधिक सामान्यीकरण: बहुत अधिक जॉइन्स वितरित प्रणालियों में लेटेंसी बढ़ाते हैं।
- ठंडे डेटा को नजरअंदाज़ करना: ऐतिहासिक डेटा को आर्काइव करने में असफलता लागत बढ़ा सकती है और सक्रिय प्रश्नों को धीमा कर सकती है।
- कड़े नियम: ऐप में अनियमित पंक्ति सीमाएं सेट करना जो डेटाबेस सीमाओं को बायपास करती हैं।
- लेटेंसी को नजरअंदाज़ करना: प्रश्नों को डिज़ाइन करना जबकि डेटा वास्तव में दूरस्थ है, लेकिन इसमें स्थानीय डेटा पहुंच की अपेक्षा की जाती है।
- एकल विफलता के बिंदु एक मुख्य डेटाबेस नोड का डिज़ाइन करना जिसे खो देने पर पूरी प्रणाली रुक जाती है।
कार्यान्वयन चेकलिस्ट ✅
क्लाउड-नेटिव डेटाबेस स्कीमा डेप्लॉय करने से पहले निम्नलिखित चेकलिस्ट की समीक्षा करें।
| कार्य | प्राथमिकता | स्थिति |
|---|---|---|
| शेडिंग रणनीति को परिभाषित करें | उच्च | शुरू नहीं किया गया |
| पढ़ने/लिखने के पैटर्न की पहचान करें | उच्च | शुरू नहीं किया गया |
| अंततः सुसंगतता के लिए योजना बनाएं | मध्यम | शुरू नहीं किया गया |
| बैकअप और पुनर्स्थापना का डिज़ाइन करें | उच्च | शुरू नहीं किया गया |
| मॉनिटरिंग अलर्ट सेट करें | मध्यम | शुरू नहीं किया गया |
| सुरक्षा नीतियों की समीक्षा करें | उच्च | शुरू नहीं किया गया |
रखरखाव और मॉनिटरिंग 🔍
एक क्लाउड-नेटिव डेटाबेस के लिए निरंतर मॉनिटरिंग की आवश्यकता होती है। ईआरडी एक स्थिर दस्तावेज़ नहीं है; यह एप्लिकेशन के साथ विकसित होता है।
मुख्य मापदंड
- प्रश्न लेटेंसी: औसत और p99 प्रतिक्रिया समय का ट्रैक रखें।
- कनेक्शन पूल उपयोगिता: सुनिश्चित करें कि एप्लिकेशन शीर्ष लोड को संभाल सके।
- स्टोरेज वृद्धि:भविष्य की क्षमता की आवश्यकता का अनुमान लगाएं।
- त्रुटि दरें:लेनदेन विफलताओं और रोलबैक्स को मॉनिटर करें।
स्वचालन
स्कीमा ड्रिफ्ट का पता लगाने और मानकों को लागू करने के लिए स्वचालित उपकरणों का उपयोग करें। इंसानी त्रुटि को कम करने के लिए उत्पादन स्कीमा में मैन्युअल बदलाव को न्यूनतम करना चाहिए।
निष्कर्ष 🏁
क्लाउड-नेटिव आर्किटेक्चर के लिए ईआर डायग्राम डिज़ाइन करना एक जटिल कार्य है जो तकनीकी सीमाओं और व्यापार लक्ष्यों के बीच संतुलन बनाता है। स्केलेबिलिटी, संस्थिरता मॉडल और सुरक्षा पर ध्यान केंद्रित करके डीबीए विकास और परिवर्तन के लिए टिकाऊ प्रणालियां बना सकते हैं। मुख्य बात यह है कि डेटा मॉडलिंग को एक बार के सेटअप के बजाय एक निरंतर प्रक्रिया के रूप में देखना है। नियमित समीक्षा और बेस्ट प्रैक्टिस का पालन करने से यह सुनिश्चित होता है कि डेटाबेस एप्लिकेशन के लिए एक विश्वसनीय आधार बना रहे। 🌐

