











Le passage d’une infrastructure traditionnelle sur site à des environnements cloud-native représente un changement fondamental dans la manière dont les données sont stockées, accédées et gérées. Pour les administrateurs de bases de données (DBA), ce passage exige plus que la simple migration des schémas existants. Il impose une réévaluation des diagrammes Entité-Relation (ERD) afin de les aligner sur les contraintes et les capacités uniques des systèmes distribués. Ce guide offre une vue complète sur la conception de diagrammes ER qui soutiennent l’évolutivité, la résilience et les performances dans les architectures cloud modernes. 📊
Comprendre le changement dans l’architecture des données 🔄
La conception traditionnelle des bases de données privilégie souvent la normalisation stricte et un contrôle centralisé. En revanche, les architectures cloud-native mettent l’accent sur la disponibilité, la tolérance aux partitions et le dimensionnement horizontal. La différence fondamentale réside dans l’hypothèse de défaillance. Dans une architecture monolithique, la base de données est un point de défaillance unique. Dans un environnement cloud-native, les nœuds tombent fréquemment, et le système doit s’adapter instantanément.
Lors de la conception de diagrammes ER pour cet environnement, les DBA doivent tenir compte de :
- Consistance distribuée : Comment les relations résistent-elles lorsque les données sont réparties sur plusieurs régions ?
- Latence : Comment la distance physique entre les nœuds de données affecte-t-elle les performances des requêtes ?
- Coût : Quel est le compromis entre la redondance de stockage et les coûts des transactions ?
- Complexité opérationnelle : Le schéma peut-il être géré sans intervention manuelle constante ?
Ignorer ces facteurs peut conduire à des systèmes difficiles à mettre à l’échelle ou à maintenir. Un diagramme ER bien conçu agit comme un plan directeur du flux de données, garantissant que l’infrastructure sous-jacente peut soutenir la logique métier sans goulets d’étranglement. 🚀
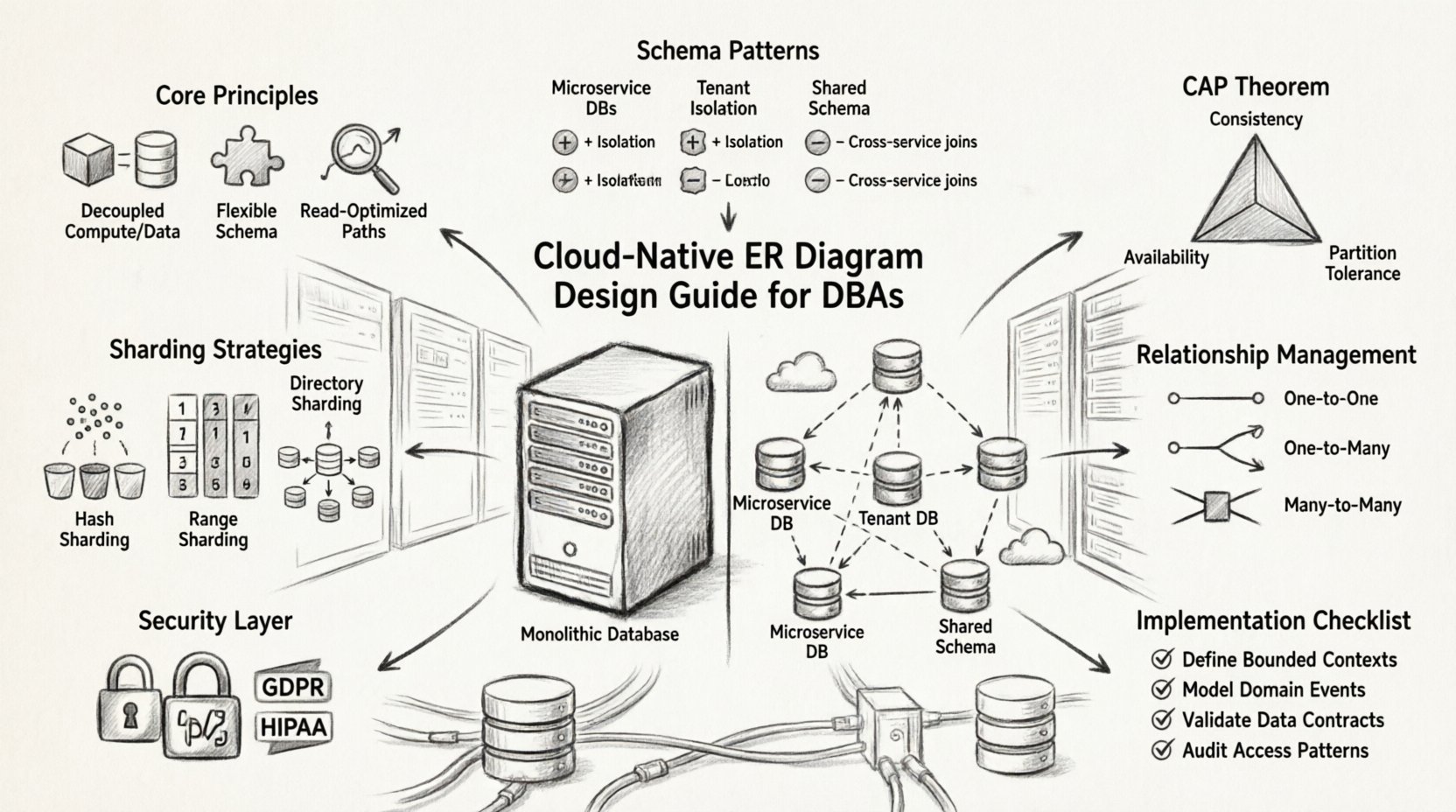
Principes fondamentaux des ERD cloud-native ⚙️
Avant de plonger dans des modèles spécifiques, il est essentiel de comprendre les principes directeurs qui distinguent la modélisation des données cloud-native des approches traditionnelles.
1. Découpler les données du calcul
Dans de nombreux systèmes hérités, le serveur de base de données et le serveur d’application sont étroitement couplés. La conception cloud-native sépare ces préoccupations. Le diagramme ERD doit refléter cela en minimisant les dépendances nécessitant une communication synchrone entre des services distincts.
2. Adopter une flexibilité du schéma
Alors que les bases de données SQL sont rigides, les environnements cloud-native utilisent souvent une persistance polyglotte. Cela signifie que différents types de données peuvent nécessiter des modèles de stockage différents. Le diagramme ER doit visualiser les relations logiques même si les implémentations physiques varient (par exemple, des magasins JSON aux côtés de tables relationnelles).
3. Optimiser pour les charges de travail intensives en lecture
Les applications cloud servent souvent des millions d’utilisateurs simultanément. La conception ER doit soutenir des chemins de lecture efficaces, même si cela implique une certaine redondance. La dénormalisation devient un outil stratégique plutôt qu’un péché.
Modèles de conception de schéma pour l’évolutivité 📈
Choisir le bon modèle de schéma est crucial pour les performances. Voici les approches courantes utilisées dans les systèmes distribués.
Une seule base de données par service
Chaque microservice gère son propre schéma de base de données. Cette isolation empêche les défaillances de service de se propager. Le diagramme ER du système global devient une collection de diagrammes plus petits et indépendants reliés par des références logiques.
Base de données partagée avec séparation des schémas
Plusieurs services partagent une seule instance de base de données tout en maintenant des espaces de noms de schémas distincts. Cela réduit les coûts d’infrastructure, mais introduit des risques de couplage étroit. Cela est généralement déconseillé pour les déploiements cloud à grande échelle.
Base de données par locataire
Dans les applications SaaS multi-locataires, chaque client reçoit une instance de base de données dédiée. La conception du ERD doit rester cohérente sur toutes les instances, garantissant que les migrations et les mises à jour s’appliquent de manière uniforme.
Comparaison des modèles de schémas
| Modèle | Avantages | Inconvénients | Meilleur cas d’utilisation |
|---|---|---|---|
| Base de données unique | Jointures simples, conformité ACID | Point de défaillance unique, limites d’évolutivité | Applications monolithiques, faible trafic |
| Base de données par service | Évolutivité indépendante, isolation des pannes | Transactions complexes, jointures distribuées | Microservices, forte croissance |
| Base de données par locataire | Isolation des données, facilité de conformité | Coût élevé de l’infrastructure, surcharge de gestion | Plateformes SaaS, secteurs réglementés |
| Schéma partagé | Faible coût, requêtes partagées | Verrouillage fournisseur, goulets d’étranglement d’évolutivité | Outils internes, MVPs |
Gestion des relations entre services 🔗
Dans une architecture distribuée, les clés étrangères ne sont pas toujours faisables. L’intégrité référentielle doit être gérée différemment. Le diagramme ER doit représenter clairement ces relations logiques, même si l’application physique se fait au niveau de la couche application ou via des processus asynchrones.
Types de relations
- Un à un : Souvent géré en intégrant directement les données pour réduire la latence des jointures.
- Un à plusieurs : Exige une réflexion attentive sur la manière dont les enregistrements enfants sont stockés. Si le parent se déplace, les enfants se déplacent-ils aussi ?
- Plusieurs à plusieurs : Typiquement implémenté via une table d’association. Dans les environnements cloud, cette table pourrait nécessiter un fractionnement indépendant.
Gestion de l’intégrité référentielle
Sans contraintes strictes de clés étrangères, la cohérence des données repose sur la logique de l’application. Les stratégies incluent :
- Suppressions douces :Marquer les enregistrements comme inactifs au lieu de les supprimer pour préserver l’historique.
- Cohérence éventuelle :Utilisation de flux d’événements pour propager les modifications entre les services.
- Transactions compensatoires :Logique d’annulation qui gère les échecs dans les workflows distribués.
Stratégies de partitionnement et de fractionnement (sharding) 🗂️
À mesure que le volume de données augmente, un seul nœud de base de données ne peut plus supporter la charge. Le partitionnement (sharding) divise les données sur plusieurs nœuds. Le diagramme ER doit indiquer comment les données sont réparties afin d’éviter les points de surcharge.
Clés de fractionnement (sharding)
Le choix de la clé de fractionnement détermine la manière dont les requêtes sont acheminées. Une bonne clé répartit les données de manière équilibrée et correspond aux modèles d’accès.
- Basé sur un hachage :Répartit les données de manière aléatoire. Bon pour un accès uniforme, mauvais pour les requêtes sur plage.
- Basé sur une plage :Divise les données par valeur (par exemple, dates ou identifiants). Bon pour les requêtes sur plage, risque de répartition inégale.
- Basé sur un répertoire :Maintient un service de correspondance pour localiser les données. Ajoute une latence mais permet un placement flexible.
Impact sur les diagrammes ER
Lors de la conception du diagramme ER, notez que :
- Les tables fréquemment jointes devraient idéalement être placées ensemble afin de minimiser le trafic réseau.
- Les tables globales (comme les données de configuration) doivent rester non fractionnées.
- Les index doivent être conçus pour fonctionner à l’intérieur des limites des shards.
Modèles de cohérence et théorème CAP ⚖️
Le théorème CAP stipule qu’un système distribué ne peut garantir que deux des trois propriétés suivantes : cohérence, disponibilité et tolérance aux partitions. Les systèmes natifs du cloud privilégient la tolérance aux partitions, ce qui impose un choix entre cohérence et disponibilité.
Choisir le bon modèle
| Modèle | Description | Implication sur le diagramme ER |
|---|---|---|
| Cohérence forte | Tous les nœuds voient les mêmes données en même temps | Exige des écritures synchrones ; limite le débit d’écriture |
| Consistance éventuelle | Les données deviennent cohérentes après un délai | Permet les écritures asynchrones ; nécessite la gestion des lectures obsolètes |
| Consistance causale | Préserve l’ordre des opérations liées causalement | Suivi complexe des dépendances dans le diagramme ER |
Pour les applications financières, une cohérence forte est souvent nécessaire. Pour les flux sociaux, une cohérence éventuelle est acceptable. Le diagramme ER doit indiquer quelles tables nécessitent un ordre strict et lesquelles peuvent tolérer des délais.
Indexation pour les environnements à haut débit 🏷️
Les stratégies d’indexation dans le cloud diffèrent de celles en local en raison des coûts de stockage et de la bande passante réseau. Chaque index consomme des ressources d’écriture et de l’espace de stockage.
Meilleures pratiques pour l’indexation
- Minimisez les index secondaires : Indexez uniquement les colonnes utilisées dans des prédicats de requête fréquents.
- Considérez les index couvrants : Incluez toutes les colonnes nécessaires dans l’index pour éviter les recherches dans la table.
- Surveillez l’utilisation des index : Auditez régulièrement les performances des index pour supprimer les structures inutilisées.
- Index partitionnés : Alignez les structures d’index avec la stratégie de partitionnement des données.
Index globaux vs. index locaux
Les index globaux couvrent toutes les tranches et peuvent être coûteux à maintenir. Les index locaux résident dans une tranche et sont moins chers. Lors de la conception du diagramme ER, précisez quels index sont globaux et quels index sont locaux afin d’orienter l’équipe infrastructure.
Considérations en matière de sécurité et de conformité 🛡️
La sécurité des données dans le cloud implique le chiffrement, le contrôle d’accès et la conformité aux réglementations telles que le RGPD ou le HIPAA. Le diagramme ER doit refléter les niveaux de sensibilité des données.
Classification des données
Étiquetez les entités de données selon leur sensibilité :
- Public : Aucune protection spéciale requise.
- Interne : Accessible uniquement par les employés.
- Restreint :Exige un chiffrement et une journalisation stricte des accès.
Chiffrement au repos et en transit
Tous les champs sensibles doivent être marqués pour le chiffrement. Le schéma ER ne doit pas stocker de données sensibles en clair. Il doit plutôt faire référence à des colonnes chiffrées ou à des jetons.
Conformité et conservation
Certaines données doivent être conservées pendant des périodes spécifiques ou supprimées entièrement. La conception du schéma ER doit inclure des champs de métadonnées pour les politiques de conservation et les traces d’audit.
Versioning et évolution du schéma 🔄
Dans les environnements natifs cloud, les temps d’arrêt pour les modifications de schéma sont rares. Les migrations doivent être effectuées en ligne. Le schéma ER doit supporter des stratégies de versioning.
Compatibilité descendante
Les nouvelles versions du schéma doivent être compatibles à la baisse avec la logique de l’application. Cela permet un déploiement progressif des modifications.
Modèles de migration
- Ajouter une colonne :Ajouter de nouveaux champs sans modifier les données existantes.
- Écriture double :Écrire dans les anciennes et les nouvelles structures pendant la transition.
- Passage :Passer le trafic lecture et écriture une fois les données migrées.
- Supprimer une colonne :Supprimer les champs inutilisés uniquement après avoir confirmé l’absence de dépendances.
Péchés courants à éviter ⚠️
Même les DBA expérimentés peuvent commettre des erreurs lors de l’adaptation aux conceptions nativement cloud. Voici des erreurs courantes.
- Sur-normalisation :Trop de jointures augmentent la latence dans les systèmes distribués.
- Ignorer les données froides :Ne pas archiver les données historiques peut augmenter les coûts et ralentir les requêtes actives.
- Limites codées en dur :Définir des limites arbitraires de lignes dans l’application qui contournent les contraintes de la base de données.
- Ignorer la latence :Concevoir des requêtes qui supposent un accès local aux données alors que celles-ci sont en réalité distantes.
- Points de défaillance uniques Concevoir un nœud de base de données primaire qui, s’il est perdu, arrête l’ensemble du système.
Liste de contrôle d’implémentation ✅
Avant de déployer un schéma de base de données natif du cloud, consultez la liste de contrôle suivante.
| Tâche | Priorité | Statut |
|---|---|---|
| Définir la stratégie de fractionnement | Élevée | Non commencé |
| Identifier les modèles de lecture/écriture | Élevée | Non commencé |
| Prévoir la cohérence éventuelle | Moyenne | Non commencé |
| Concevoir la sauvegarde et la récupération | Élevée | Non commencé |
| Configurer les alertes de surveillance | Moyenne | Non commencé |
| Examiner les politiques de sécurité | Élevée | Non commencé |
Maintenance et surveillance 🔍
Une base de données native du cloud nécessite une surveillance continue. Le schéma ERN n’est pas un document statique ; il évolue avec l’application.
Indicateurs clés
- Latence des requêtes : Suivre les temps de réponse moyens et le p99.
- Utilisation du pool de connexions : Assurez-vous que l’application peut gérer les pics de charge.
- Croissance du stockage :Prédire les besoins futurs en capacité.
- Taux d’erreurs :Surveiller les échecs des transactions et les annulations.
Automatisation
Utilisez des outils automatisés pour détecter les écarts de schéma et appliquer les normes. Les modifications manuelles des schémas de production doivent être minimisées afin de réduire les erreurs humaines.
Conclusion 🏁
Concevoir des diagrammes ER pour les architectures cloud-native est une tâche complexe qui équilibre les contraintes techniques avec les objectifs commerciaux. En se concentrant sur la scalabilité, les modèles de cohérence et la sécurité, les DBA peuvent construire des systèmes capables de résister à la croissance et aux changements. L’essentiel est de considérer la modélisation des données comme un processus continu plutôt qu’une configuration ponctuelle. Les revues régulières et le respect des bonnes pratiques garantissent que la base de données reste une fondation fiable pour l’application. 🌐

